AllDayNav: Lifelong Navigation via Real-World Reinforcement Learning
Pith reviewed 2026-06-27 13:24 UTC · model grok-4.3
The pith
AllDayNav encodes lifelong scene dynamics into a large model's parameters via reinforcement learning driven by a self-evolving multimodal memory, reaching near-100% success without explicit maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
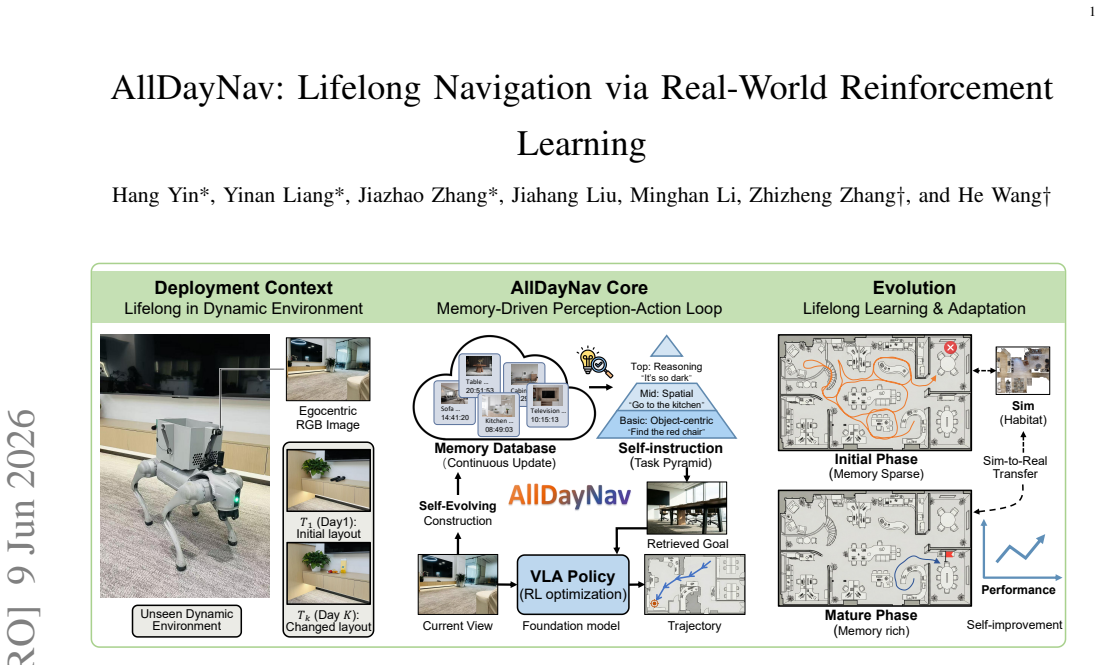
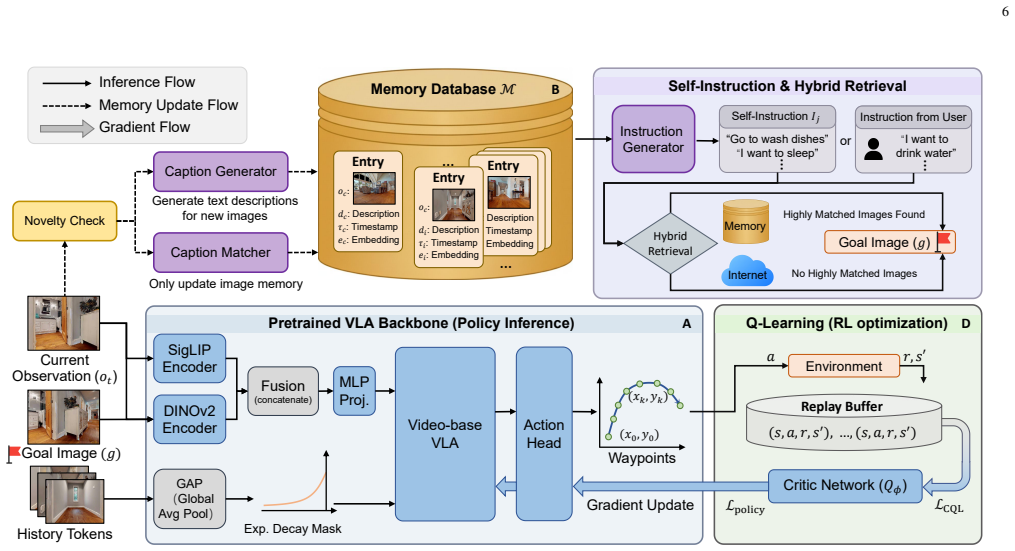
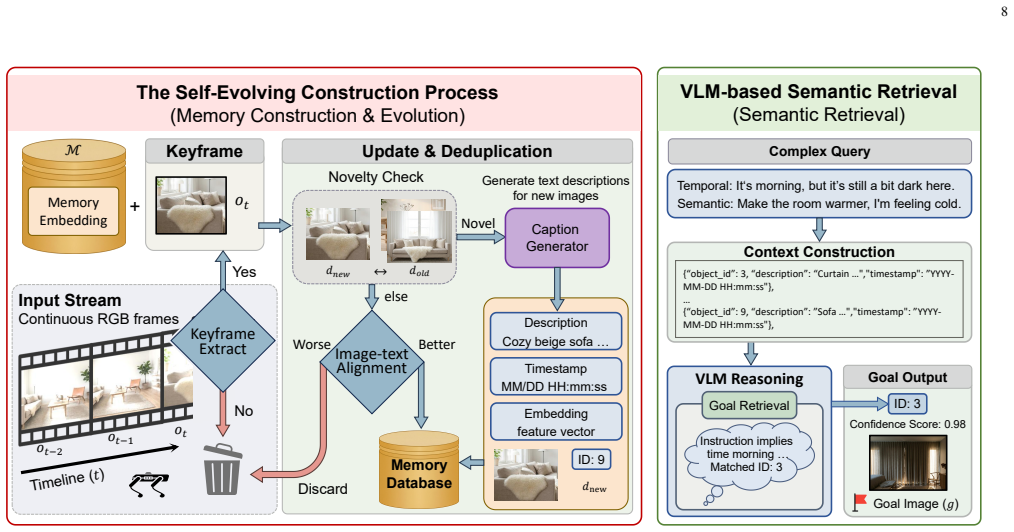
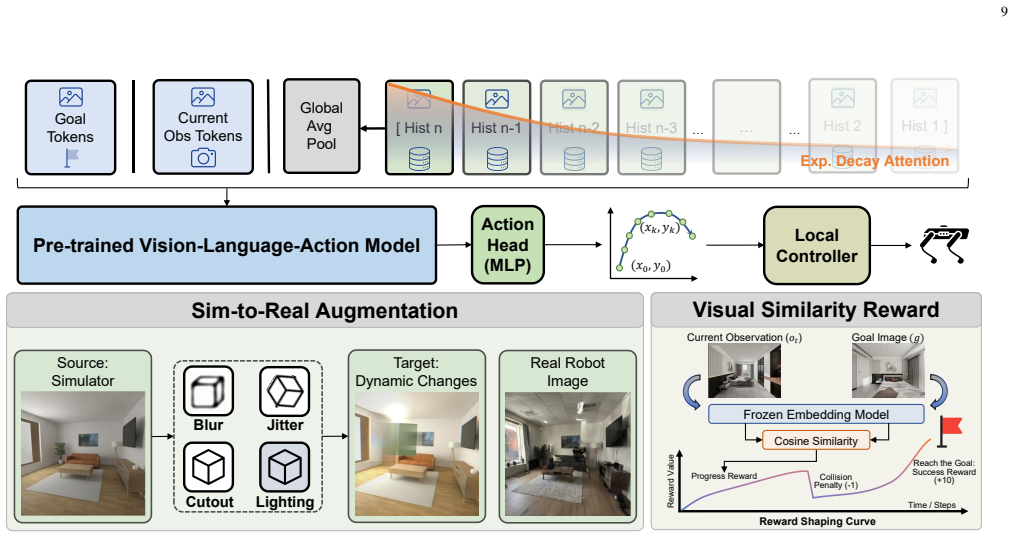
AllDayNav shows that lifelong embodied navigation succeeds when scene dynamics are implicitly stored inside the billion-scale parameters of a large model through reinforcement learning; the storage is maintained by a self-evolving multimodal memory that keeps visual keyframes, semantic descriptions, and temporal context while generating open-vocabulary instructions, image goals, and structured rewards, producing success rates near 100 percent and better path efficiency than map-based, VLM, or standard RL baselines in cross-room, cross-episode, and cross-task conditions.
What carries the argument
self-evolving multimodal memory that maintains visual keyframes, semantic descriptions, and temporal context while autonomously generating open-vocabulary instructions, image goals, and structured rewards for reinforcement learning
If this is right
- Success rates approach 100 percent across cross-room, cross-episode, and cross-task scenarios in both simulation and reality.
- Path efficiency and robustness exceed those of map-based, vision-language, and standard reinforcement-learning methods.
- Scene understanding forms inside model parameters instead of separate maps or graphs.
- The same memory-driven reinforcement-learning loop supports open-vocabulary instructions without hand-crafted rules.
Where Pith is reading between the lines
- Similar implicit encoding could apply to other long-horizon embodied tasks such as sequential manipulation if the memory component is reused.
- Further scaling of the underlying model size might increase the duration over which memory remains reliable without added structures.
- The approach invites direct comparison of memory-update frequency against navigation failure rate in environments with higher rates of object movement.
Load-bearing premise
The multimodal memory can keep updating its visual, semantic, and temporal records from partial observations without external help or explicit maps.
What would settle it
Repeated trials in rapidly changing real spaces where the memory fails to retain consistent scene records across episodes and navigation success drops below map-based baselines.
Figures
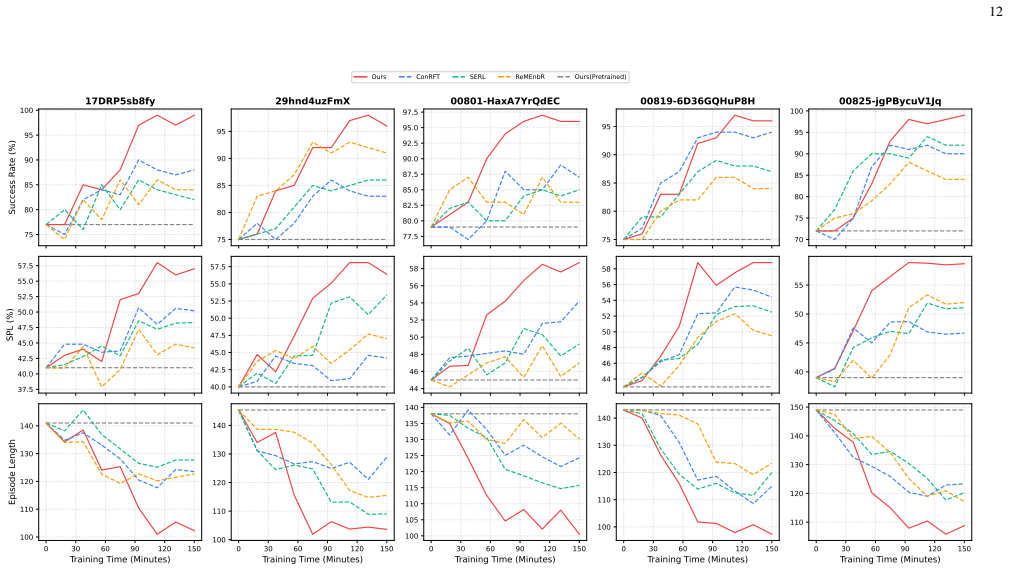
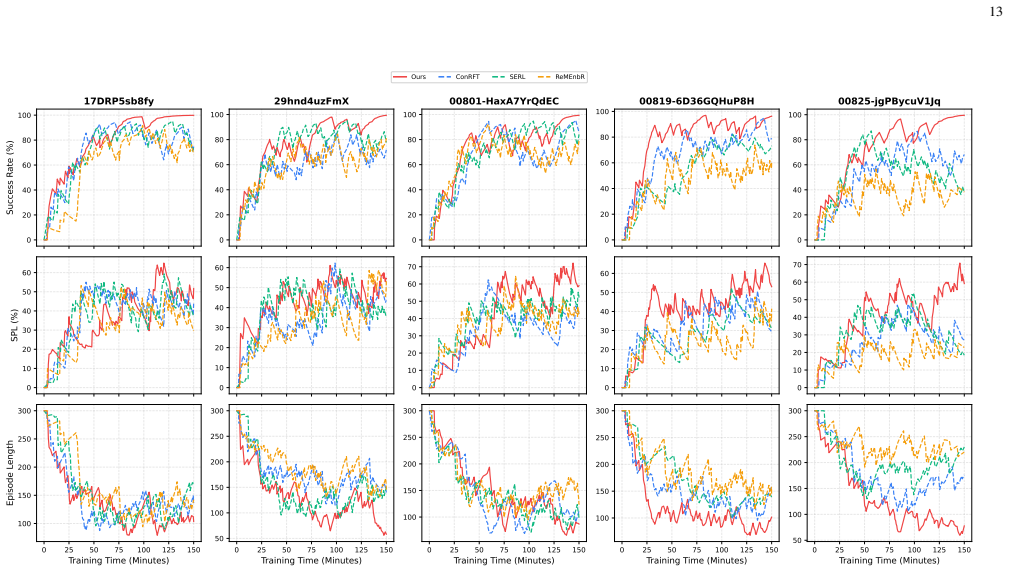
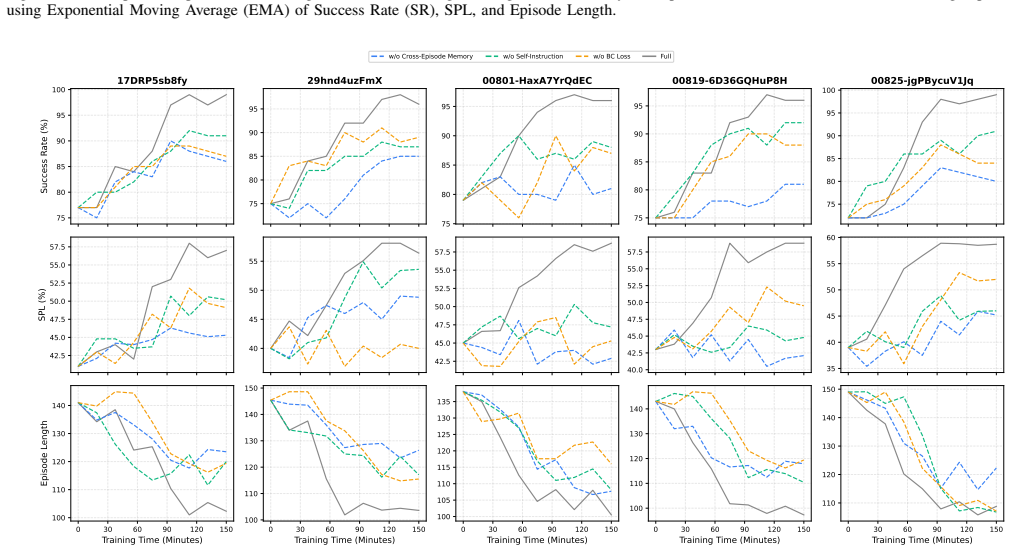
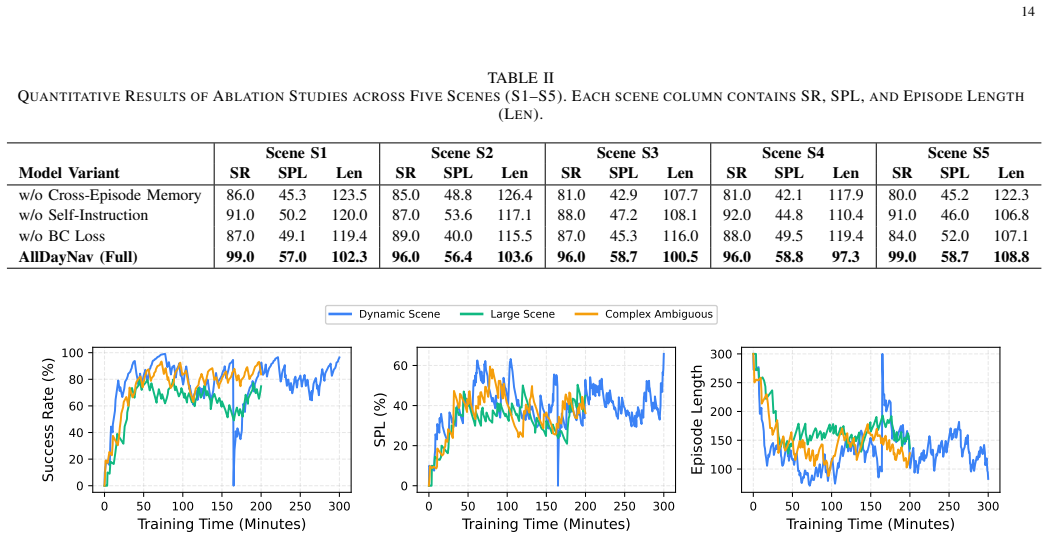
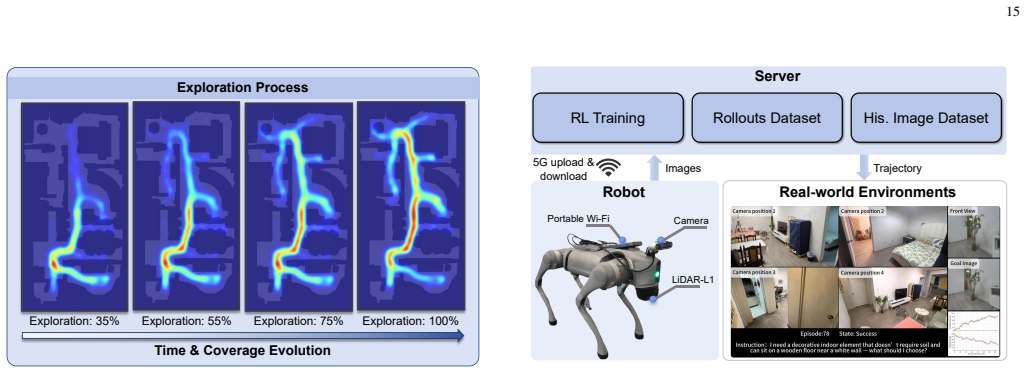
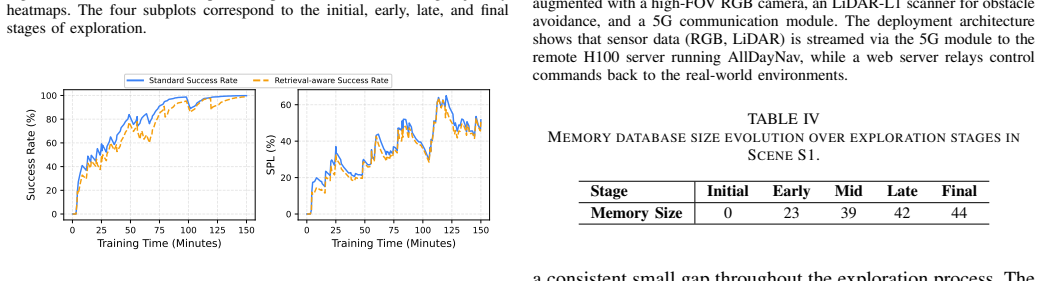
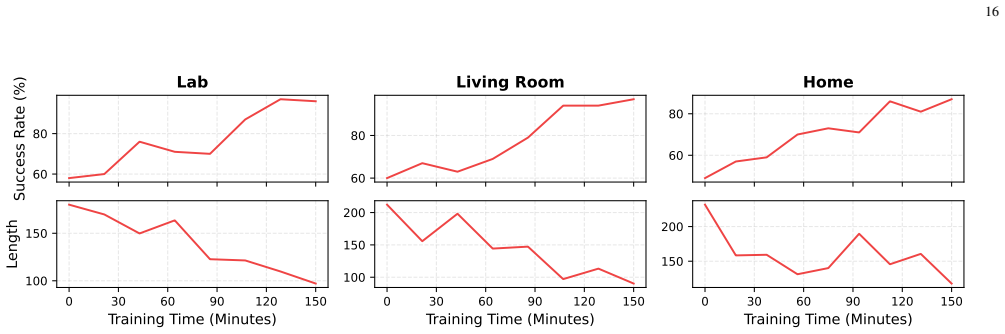
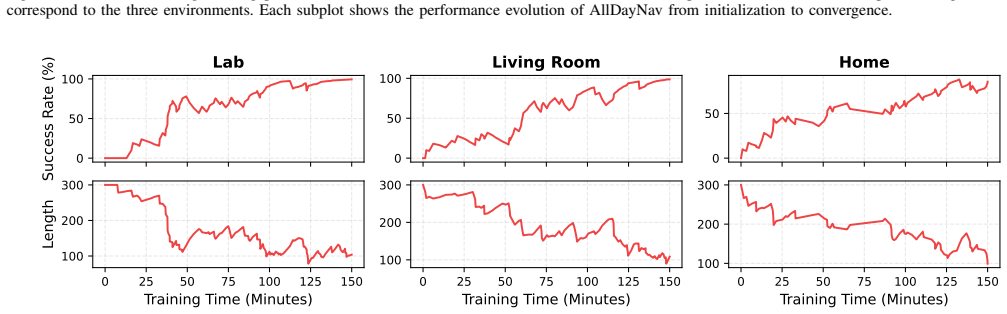
read the original abstract
Lifelong embodied navigation in dynamic environments requires robots to form persistent scene understanding from fragmentary observations, which remains difficult for existing methods that rely on explicit maps or scene graphs and struggle to generalize beyond structured settings. We propose AllDayNav, a lifelong self-learning navigation framework that implicitly encodes scene dynamics into the billion-scale parameters of a large model via reinforcement learning, powered by a self-evolving multimodal memory that maintains and updates visual keyframes, semantic descriptions, and temporal context while autonomously generating open-vocabulary instructions, image goals, and structured rewards. Experiments in both synthetic and real-world environments across cross-room, cross-episode, and cross-task scenarios show that AllDayNav achieves success rates approaching $100\%$ and consistently surpasses strong map-based, VLM, and RL baselines in path efficiency and robustness, demonstrating implicit, memory-driven reinforcement learning as a scalable alternative to explicit mapping for reliable lifelong navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AllDayNav, a lifelong self-learning navigation framework for dynamic real-world environments. It implicitly encodes scene dynamics into the parameters of a large model via reinforcement learning, powered by a self-evolving multimodal memory that maintains visual keyframes, semantic descriptions, and temporal context while generating open-vocabulary instructions, image goals, and structured rewards. Experiments across synthetic and real-world settings in cross-room, cross-episode, and cross-task scenarios are reported to yield success rates approaching 100% while outperforming map-based, VLM, and RL baselines in path efficiency and robustness.
Significance. If the empirical claims hold under rigorous evaluation, the work would be significant for embodied AI and robotics by demonstrating that implicit memory-driven RL can serve as a scalable alternative to explicit mapping or scene graphs for persistent scene understanding and reliable lifelong navigation.
major comments (1)
- [Abstract] Abstract: The central claims of near-100% success rates and consistent outperformance over baselines are load-bearing for the contribution, yet the text provides no information on experimental setup, environments, number of trials, specific baselines, metrics, or statistical significance testing. This prevents assessment of whether the data supports the reported superiority.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that additional context on the experimental setup would strengthen the presentation of our central claims and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of near-100% success rates and consistent outperformance over baselines are load-bearing for the contribution, yet the text provides no information on experimental setup, environments, number of trials, specific baselines, metrics, or statistical significance testing. This prevents assessment of whether the data supports the reported superiority.
Authors: We agree with the observation. While the abstract is kept concise by design, the lack of even high-level experimental descriptors makes the claims harder to evaluate at a glance. In the revised manuscript we will expand the abstract to include brief references to the environments (synthetic and real-world), scenario types (cross-room, cross-episode, cross-task), the three classes of baselines (map-based, VLM, RL), the primary metrics (success rate and path efficiency), and the number of trials. Full details on statistical testing and exact trial counts remain in the Experiments section, but the abstract will now be more self-contained. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and available text present an empirical framework description and performance claims without any equations, algorithms, derivations, or first-principles predictions. No load-bearing steps exist that could reduce by construction to inputs, self-citations, or fitted parameters renamed as predictions. The work reports experimental outcomes across environments and is self-contained against external benchmarks as an applied RL system.
Axiom & Free-Parameter Ledger
invented entities (1)
-
self-evolving multimodal memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Embodied navigation with multi-modal information: A survey from tasks to methodology,
Y . Wu, P. Zhang, M. Gu, J. Zheng, and X. Bai, “Embodied navigation with multi-modal information: A survey from tasks to methodology,” Information Fusion, vol. 112, p. 102532, 2024
2024
-
[2]
On Evaluation of Embodied Navigation Agents
P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savvaet al., “On evalu- ation of embodied navigation agents,”arXiv preprint arXiv:1807.06757, 2018. 18
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
2018
-
[4]
Llm as copilot for coarse- grained vision-and-language navigation,
Y . Qiao, Q. Liu, J. Liu, J. Liu, and Q. Wu, “Llm as copilot for coarse- grained vision-and-language navigation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 459–476
2024
-
[5]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang, “Navid: Video-based vlm plans the next step for vision- and-language navigation,”arXiv preprint arXiv:2402.15852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Understanding object descriptions in robotics by open-vocabulary object retrieval and detection,
S. Guadarrama, E. Rodner, K. Saenko, and T. Darrell, “Understanding object descriptions in robotics by open-vocabulary object retrieval and detection,”The International Journal of Robotics Research, vol. 35, no. 1-3, pp. 265–280, 2016
2016
-
[7]
Open-vocabulary object retrieval
S. Guadarrama, E. Rodner, K. Saenko, N. Zhang, R. Farrell, J. Donahue, and T. Darrell, “Open-vocabulary object retrieval.” inRobotics: science and systems, vol. 2, no. 5, 2014, p. 6
2014
-
[8]
Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation,
N. Yokoyama, R. Ramrakhya, A. Das, D. Batra, and S. Ha, “Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal navigation,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 5543–5550
2024
-
[9]
Vision-based holistic scene understanding towards proactive human–robot collaboration,
J. Fan, P. Zheng, and S. Li, “Vision-based holistic scene understanding towards proactive human–robot collaboration,”Robotics and Computer- Integrated Manufacturing, vol. 75, p. 102304, 2022
2022
-
[10]
Outdoor scene understanding of mobile robot via multi-sensor information fusion,
F.-s. Zhang, D.-y. Ge, J. Song, and W.-j. Xiang, “Outdoor scene understanding of mobile robot via multi-sensor information fusion,” Journal of Industrial Information Integration, vol. 30, p. 100392, 2022
2022
-
[11]
Navigation-oriented scene understanding for robotic autonomy: Learn- ing to segment driveability in egocentric images,
G. Humblot-Renaux, L. Marchegiani, T. B. Moeslund, and R. Gade, “Navigation-oriented scene understanding for robotic autonomy: Learn- ing to segment driveability in egocentric images,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2913–2920, 2022
2022
-
[12]
W. Li, R. Zhang, R. Shao, J. He, and L. Nie, “Cogvla: Cognition- aligned vision-language-action model via instruction-driven routing & sparsification,”arXiv preprint arXiv:2508.21046, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Multi-Objective Instruction-Aware Representation Learning in Procedural Content Generation RL
S.-H. Kim, I.-C. Baek, S.-Y . Lee, G.-H. Hwang, and K.-J. Kim, “Multi- objective instruction-aware representation learning in procedural content generation rl,”arXiv preprint arXiv:2508.09193, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Dynscene: Scalable generation of dynamic robotic manipulation scenes for embodied ai,
S. Lee, S. Park, and H. Kim, “Dynscene: Scalable generation of dynamic robotic manipulation scenes for embodied ai,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 166– 12 175
2025
-
[15]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Changet al., “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,”arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Gibson env: Real-world perception for embodied agents,
F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese, “Gibson env: Real-world perception for embodied agents,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9068–9079
2018
-
[18]
Object goal navigation using goal-oriented semantic exploration,
D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,”Advances in Neural Information Processing Systems, vol. 33, pp. 4247–4258, 2020
2020
-
[19]
Learning hierarchical relationships for object-goal navigation,
A. Pal, Y . Qiu, and H. Christensen, “Learning hierarchical relationships for object-goal navigation,” inConference on Robot Learning. PMLR, 2021, pp. 517–528
2021
-
[20]
Nvila: Efficient frontier visual language models,
Z. Liu, L. Zhu, B. Shi, Z. Zhang, Y . Lou, S. Yang, H. Xi, S. Cao, Y . Gu, D. Liet al., “Nvila: Efficient frontier visual language models,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 4122–4134
2025
-
[21]
Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms,
Y . Qiao, W. Lyu, H. Wang, Z. Wang, Z. Li, Y . Zhang, M. Tan, and Q. Wu, “Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6710–6717
2025
-
[22]
General scene adaptation for vision-and-language navigation,
H. Hong, Y . Qiao, S. Wang, J. Liu, and Q. Wu, “General scene adaptation for vision-and-language navigation,”arXiv preprint arXiv:2501.17403, 2025
-
[23]
Openfmnav: Towards open-set zero- shot object navigation via vision-language foundation models,
Y . Kuang, H. Lin, and M. Jiang, “Openfmnav: Towards open-set zero- shot object navigation via vision-language foundation models,”arXiv preprint arXiv:2402.10670, 2024
-
[24]
Unigoal: Towards universal zero-shot goal-oriented navigation,
H. Yin, X. Xu, L. Zhao, Z. Wang, J. Zhou, and J. Lu, “Unigoal: Towards universal zero-shot goal-oriented navigation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19 057–19 066
2025
-
[25]
Scene graph contrastive learning for embodied navigation,
K. P. Singh, J. Salvador, L. Weihs, and A. Kembhavi, “Scene graph contrastive learning for embodied navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 884–10 894
2023
-
[26]
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang, “Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,”arXiv preprint arXiv:2505.18719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
H. Li, P. Ding, R. Suo, Y . Wang, Z. Ge, D. Zang, K. Yu, M. Sun, H. Zhang, D. Wanget al., “Vla-rft: Vision-language-action reinforce- ment fine-tuning with verified rewards in world simulators,”arXiv preprint arXiv:2510.00406, 2025
-
[28]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cuiet al., “Simplevla-rl: Scaling vla training via reinforce- ment learning,”arXiv preprint arXiv:2509.09674, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Improving vision-language-action model with online reinforcement learning,
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen, “Improving vision-language-action model with online reinforcement learning,”arXiv preprint arXiv:2501.16664, 2025
-
[30]
Mental imagery: against the nihilistic hypothesis,
S. M. Kosslyn, G. Ganis, and W. L. Thompson, “Mental imagery: against the nihilistic hypothesis,”Trends in Cognitive Sciences, vol. 7, no. 3, pp. 109–110, 2003
2003
-
[31]
Visual images preserve metric spatial information: evidence from studies of image scanning
S. M. Kosslyn, T. M. Ball, and B. J. Reiser, “Visual images preserve metric spatial information: evidence from studies of image scanning.” Journal of experimental psychology: Human perception and perfor- mance, vol. 4, no. 1, p. 47, 1978
1978
-
[32]
Individual differences in spatial mental imagery,
G. Borst and S. M. Kosslyn, “Individual differences in spatial mental imagery,”Quarterly Journal of Experimental Psychology, vol. 63, no. 10, pp. 2031–2050, 2010
2031
-
[33]
Visual and spatial mental imagery: Dissociable systems of representation,
M. J. Farah, K. M. Hammond, D. N. Levine, and R. Calvanio, “Visual and spatial mental imagery: Dissociable systems of representation,” Cognitive psychology, vol. 20, no. 4, pp. 439–462, 1988
1988
-
[34]
Mental imagery and visual working memory,
R. Keogh and J. Pearson, “Mental imagery and visual working memory,” PloS one, vol. 6, no. 12, p. e29221, 2011
2011
-
[35]
Bird’s-eye-view scene graph for vision-language navigation,
R. Liu, X. Wang, W. Wang, and Y . Yang, “Bird’s-eye-view scene graph for vision-language navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 968–10 980
2023
-
[36]
Hierarchical representations and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks,
Z. Ravichandran, L. Peng, N. Hughes, J. D. Griffith, and L. Carlone, “Hierarchical representations and explicit memory: Learning effective navigation policies on 3d scene graphs using graph neural networks,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 9272–9279
2022
-
[37]
Navigating with spatial intelligence: A survey of scene graph-based object goal navigation,
G. Chi, L. Aolin, and M. Yiyue, “Navigating with spatial intelligence: A survey of scene graph-based object goal navigation,”Wuhan University Journal of Natural Sciences, vol. 30, no. 5, pp. 405–426, 2025
2025
-
[38]
Indoor and outdoor 3d scene graph generation via language-enabled spatial ontologies,
J. Strader, N. Hughes, W. Chen, A. Speranzon, and L. Carlone, “Indoor and outdoor 3d scene graph generation via language-enabled spatial ontologies,”IEEE Robotics and Automation Letters, vol. 9, no. 6, pp. 4886–4893, 2024
2024
-
[39]
Open scene graphs for open-world object- goal navigation,
J. Loo, Z. Wu, and D. Hsu, “Open scene graphs for open-world object- goal navigation,”The International Journal of Robotics Research, p. 02783649251369549, 2025
2025
-
[40]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,”Advances in neural information processing systems, vol. 37, pp. 5285–5307, 2024
2024
-
[41]
Zson: Zero-shot object-goal navigation using multimodal goal embed- dings,
A. Majumdar, G. Aggarwal, B. Devnani, J. Hoffman, and D. Batra, “Zson: Zero-shot object-goal navigation using multimodal goal embed- dings,”Advances in Neural Information Processing Systems, vol. 35, pp. 32 340–32 352, 2022
2022
-
[42]
Entl: Embodied navigation trajectory learner,
K. Kotar, A. Walsman, and R. Mottaghi, “Entl: Embodied navigation trajectory learner,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision, 2023, pp. 10 863–10 872
2023
-
[43]
Rana: Retrieval-augmented navigation,
G. Monaci, R. S. Rezende, R. Deffayet, G. Csurka, G. Bono, H. D ´ejean, S. Clinchant, and C. Wolf, “Rana: Retrieval-augmented navigation,” arXiv preprint arXiv:2504.03524, 2025
-
[44]
Llm- empowered embodied agent for memory-augmented task planning in household robotics,
M. Glocker, P. H ¨onig, M. Hirschmanner, and M. Vincze, “Llm- empowered embodied agent for memory-augmented task planning in household robotics,”arXiv preprint arXiv:2504.21716, 2025
-
[45]
Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation,
A. Anwar, J. Welsh, J. Biswas, S. Pouya, and Y . Chang, “Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 2838–2845
2025
-
[46]
Meta-memory: Retrieving and integrating semantic-spatial memories for robot spatial reasoning,
Y . Mao, H. Ye, W. Dong, C. Zhang, and H. Zhang, “Meta-memory: Retrieving and integrating semantic-spatial memories for robot spatial reasoning,”arXiv preprint arXiv:2509.20754, 2025. 19
-
[47]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,
W.-L. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalezet al., “Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality,”See https://vicuna. lmsys. org (accessed 14 April 2023), vol. 2, no. 3, p. 6, 2023
2023
-
[48]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Chatnav: Leveraging llm to zero-shot semantic reasoning in object navigation,
Y . Zhu, Z. Wen, X. Li, X. Shi, X. Wu, H. Dong, and J. Chen, “Chatnav: Leveraging llm to zero-shot semantic reasoning in object navigation,” IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[50]
Mapgpt: Map-guided prompting with adaptive path planning for vision-and- language navigation,
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . Wong, “Mapgpt: Map-guided prompting with adaptive path planning for vision-and- language navigation,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 9796–9810
2024
-
[51]
Instructnav: Zero- shot system for generic instruction navigation in unexplored environ- ment,
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong, “Instructnav: Zero- shot system for generic instruction navigation in unexplored environ- ment,”arXiv preprint arXiv:2406.04882, 2024
-
[52]
Navgpt: Explicit reasoning in vision- and-language navigation with large language models,
G. Zhou, Y . Hong, and Q. Wu, “Navgpt: Explicit reasoning in vision- and-language navigation with large language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 7, 2024, pp. 7641–7649
2024
-
[53]
Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning,
B. Lin, Y . Nie, Z. Wei, J. Chen, S. Ma, J. Han, H. Xu, X. Chang, and X. Liang, “Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[54]
Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs,
Z. Xu, H.-T. L. Chiang, Z. Fu, M. G. Jacob, T. Zhang, T.-W. E. Lee, W. Yu, C. Schenck, D. Rendleman, D. Shahet al., “Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs,” in8th Annual Conference on Robot Learning, 2024
2024
-
[55]
FiLM-Nav: Efficient and Generalizable Navigation via VLM Fine-tuning
N. Yokoyama and S. Ha, “Film-nav: Efficient and generalizable naviga- tion via vlm fine-tuning,”arXiv preprint arXiv:2509.16445, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang, “Uni-navid: A video-based vision-language- action model for unifying embodied navigation tasks,”arXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Navigation world models,
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun, “Navigation world models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15 791–15 801
2025
-
[58]
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao, “Conrft: A reinforced fine-tuning method for vla models via consistency policy,” arXiv preprint arXiv:2502.05450, 2025
-
[59]
Serl: A software suite for sample-efficient robotic reinforcement learning,
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine, “Serl: A software suite for sample-efficient robotic reinforcement learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 16 961–16 969
2024
-
[60]
The ingredients of real-world robotic reinforcement learning.arXiv preprint arXiv:2004.12570, 2020
H. Zhu, J. Yu, A. Gupta, D. Shah, K. Hartikainen, A. Singh, V . Kumar, and S. Levine, “The ingredients of real-world robotic reinforcement learning,” 2020. [Online]. Available: https://arxiv.org/abs/2004.12570
-
[61]
Rlif: Inter- active imitation learning as reinforcement learning,
J. Luo, P. Dong, Y . Zhai, Y . Ma, and S. Levine, “Rlif: Inter- active imitation learning as reinforcement learning,”arXiv preprint arXiv:2311.12996, 2023
-
[62]
Rldg: Robotic generalist policy dis- tillation via reinforcement learning,
C. Xu, Q. Li, J. Luo, and S. Levine, “Rldg: Robotic generalist policy dis- tillation via reinforcement learning,”arXiv preprint arXiv:2412.09858, 2024
-
[63]
Poliformer: Scaling on-policy rl with transformers results in masterful navigators,
K.-H. Zeng, Z. Zhang, K. Ehsani, R. Hendrix, J. Salvador, A. Herrasti, R. Girshick, A. Kembhavi, and L. Weihs, “Poliformer: Scaling on-policy rl with transformers results in masterful navigators,”arXiv preprint arXiv:2406.20083, 2024
-
[64]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” 2023
2023
-
[65]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, R. Howes, P.-Y . Huang, H. Xu, V . Sharma, S.-W. Li, W. Galuba, M. Rabbat, M. Assran, N. Ballas, G. Synnaeve, I. Misra, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features withou...
2023
-
[66]
Llave: Large language and vision embedding models with hardness-weighted contrastive learning,
Z. Lan, L. Niu, F. Meng, J. Zhou, and J. Su, “Llave: Large language and vision embedding models with hardness-weighted contrastive learning,” arXiv preprint arXiv:2503.04812, 2025
-
[67]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Maliket al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.