Test-Time Scaling in Multimodal Foundation Models: A Comprehensive Survey of Generation and Reasoning
Pith reviewed 2026-06-27 19:35 UTC · model grok-4.3
The pith
Test-time scaling methods for multimodal foundation models fall into sampling-based, feedback-based, and search-based strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the first comprehensive review of TTS research for MFMs, proposing a unified taxonomic framework that categorizes existing methodologies into three distinct strategies: sampling-based, feedback-based, and search-based approaches. We further summarize representative applications and benchmarks commonly utilized to evaluate multimodal TTS capabilities in generation and reasoning tasks. Finally, this survey discusses open challenges and outlines future research directions, providing a systematic roadmap for subsequent studies in this rapidly evolving field.
What carries the argument
The unified taxonomic framework that partitions TTS methodologies for MFMs into sampling-based, feedback-based, and search-based approaches.
Load-bearing premise
The body of existing test-time scaling methods for multimodal foundation models can be partitioned into these three categories without major omissions or overlaps that would make the grouping less useful.
What would settle it
Discovery of a test-time scaling method for multimodal models that cannot be placed in any of the three categories, or evidence of substantial overlap between categories that collapses their distinctiveness.
Figures
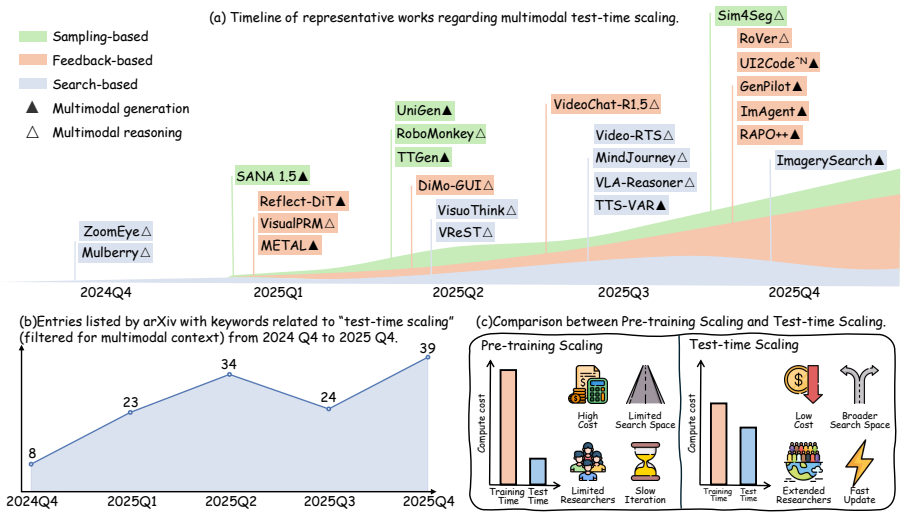
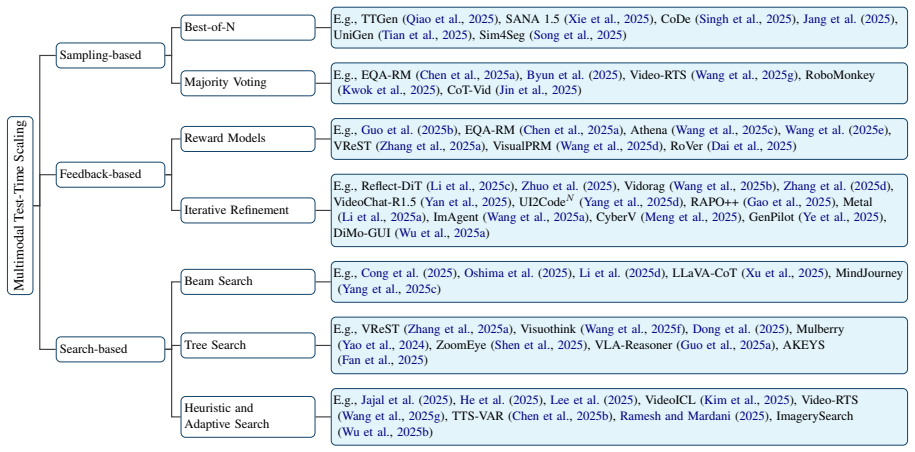
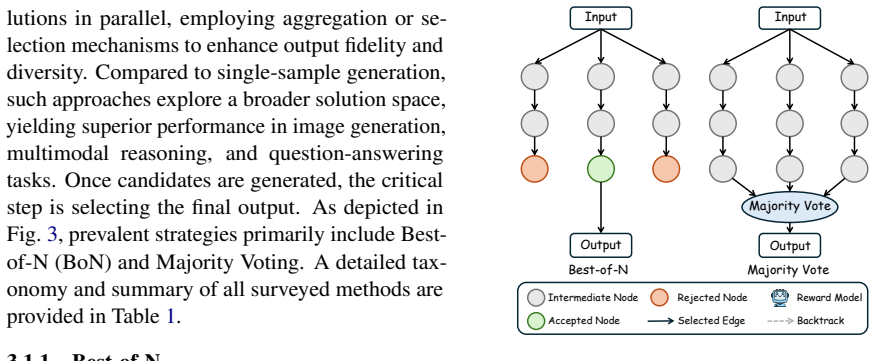
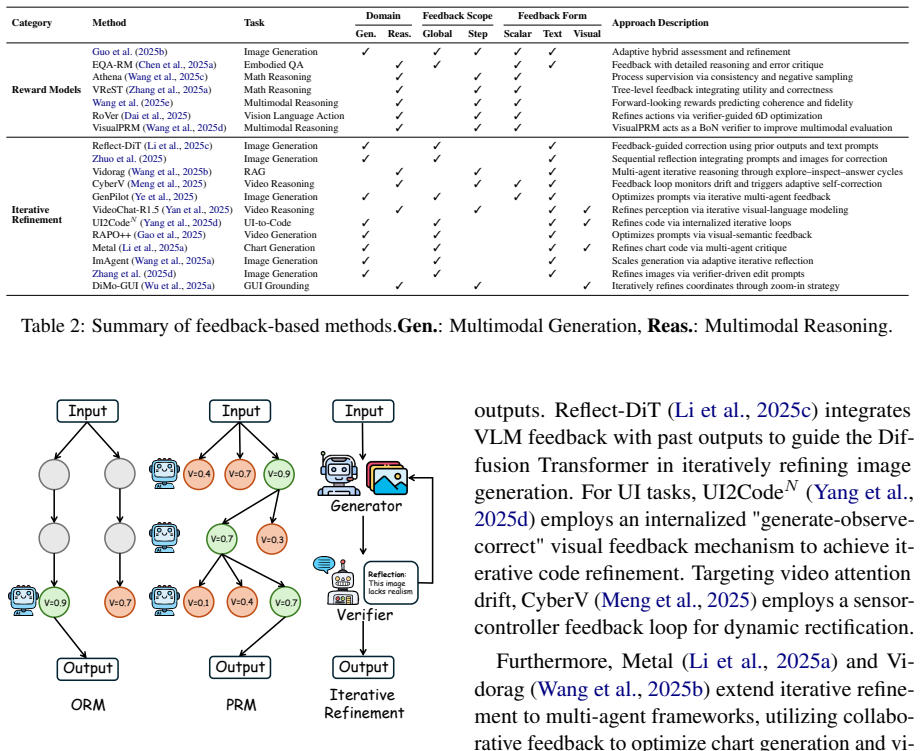
read the original abstract
Test-time Scaling (TTS) has emerged as a pivotal research direction for enhancing model performance by dynamically allocating computational resources during inference. Recent advancements have adapted this paradigm to Multimodal Foundation Models (MFMs), unlocking their potential in multimodal reasoning and generation. Despite rapid progress, the field lacks a systematic survey and unified theoretical framework to delineate the developmental landscape of multimodal TTS. To bridge this gap, we present the first comprehensive review of TTS research for MFMs, proposing a unified taxonomic framework that categorizes existing methodologies into three distinct strategies: sampling-based, feedback-based, and search-based approaches. We further summarize representative applications and benchmarks commonly utilized to evaluate multimodal TTS capabilities in generation and reasoning tasks. Finally, this survey discusses open challenges and outlines future research directions, providing a systematic roadmap for subsequent studies in this rapidly evolving field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to be the first comprehensive survey of Test-Time Scaling (TTS) for Multimodal Foundation Models (MFMs). It proposes a unified taxonomic framework partitioning existing methods into three distinct strategies—sampling-based, feedback-based, and search-based—while also summarizing representative applications, benchmarks for generation and reasoning tasks, open challenges, and future research directions.
Significance. A well-justified taxonomy and complete coverage would organize a fast-moving area and provide a useful roadmap; the survey format itself supplies no machine-checked proofs or parameter-free derivations but could still deliver organizing value if the partition is shown to be exhaustive and non-overlapping.
major comments (1)
- [Abstract] Abstract: the central claim that the three strategies constitute a 'unified taxonomic framework' with 'distinct' categories is load-bearing yet unsupported by any stated categorization criteria, decision rules, or explicit mapping of cited works to categories; without this, overlaps, omissions, or alternative groupings (e.g., optimization-based or model-internal scaling) cannot be ruled out.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our survey. The single major comment concerns the justification of the proposed taxonomy in the abstract. We respond point-by-point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the three strategies constitute a 'unified taxonomic framework' with 'distinct' categories is load-bearing yet unsupported by any stated categorization criteria, decision rules, or explicit mapping of cited works to categories; without this, overlaps, omissions, or alternative groupings (e.g., optimization-based or model-internal scaling) cannot be ruled out.
Authors: We agree the abstract is concise and does not spell out the decision rules. The full manuscript (Section 3) defines the categories by the primary test-time compute mechanism: sampling-based methods draw multiple independent generations and aggregate (e.g., best-of-N); feedback-based methods iteratively refine via external verifiers or critics; search-based methods explore structured spaces with algorithms such as beam search or MCTS. These criteria are applied consistently to the surveyed literature. We will revise the abstract to include a one-sentence statement of these criteria and add an explicit mapping table (new Table 1) listing representative works under each category. Regarding alternatives, optimization-based methods are covered under search-based when they allocate test-time compute via search; model-internal scaling (e.g., extended CoT) is classified under sampling or feedback depending on whether external signals are used. We believe the taxonomy is exhaustive for multimodal TTS methods that explicitly scale inference compute, and the revision will make the mapping transparent. revision: yes
Circularity Check
No circularity: literature survey with no derivations or self-referential reductions
full rationale
The paper is a survey that proposes a taxonomic framework for categorizing existing TTS methods in MFMs into sampling-based, feedback-based, and search-based approaches. No equations, predictions, fitted parameters, or derivation chains are present. The taxonomy is offered as an organizing lens drawn from the reviewed literature rather than derived from or reduced to any internal inputs or self-citations. The central claim of providing the first comprehensive review does not reduce to a self-definition or fitted input; it is a descriptive synthesis. This matches the default expectation for non-circular survey work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, et al. 2022. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
- [4]
- [5]
- [6]
- [7]
-
[8]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024 a . Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062--135093
2024
-
[9]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024 b . Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [10]
-
[11]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [12]
- [13]
-
[14]
Karan Dalal, Daniel Koceja, Jiarui Xu, Yue Zhao, Shihao Han, Ka Chun Cheung, Jan Kautz, Yejin Choi, Yu Sun, and Xiaolong Wang. 2025. One-minute video generation with test-time training. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 17702--17711
2025
-
[15]
Fernando Diaz and Michael Madaio. 2024. Scaling laws do not scale. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 7, pages 341--357
2024
-
[16]
Guanting Dong, Chenghao Zhang, Mengjie Deng, Yutao Zhu, Zhicheng Dou, and Ji-Rong Wen. 2025. Progressive multimodal reasoning via active retrieval. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3579--3602
2025
- [17]
-
[18]
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. 2024. Mmbench-video: A long-form multi-shot benchmark for holistic video understanding. Advances in Neural Information Processing Systems, 37:89098--89124
2024
-
[19]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24108--24118
2025
- [20]
-
[21]
Bingjie Gao, Qianli Ma, Xiaoxue Wu, Shuai Yang, Guanzhou Lan, Haonan Zhao, Jiaxuan Chen, Qingyang Liu, Yu Qiao, Xinyuan Chen, et al. 2025. Rapo++: Cross-stage prompt optimization for text-to-video generation via data alignment and test-time scaling. arXiv preprint arXiv:2510.20206
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. 2023. Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems, 36:52132--52152
2023
- [23]
- [24]
- [25]
- [26]
-
[27]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [28]
-
[29]
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. 2025. Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos. arXiv preprint arXiv:2501.13826
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. 2024 a . Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. 2024 b . Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170--22183
2024
-
[32]
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. 2023. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Advances in Neural Information Processing Systems, 36:78723--78747
2023
-
[33]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024 a . Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418--13427
2024
-
[34]
Zhongzhan Huang, Guoming Ling, Shanshan Zhong, Hefeng Wu, and Liang Lin. 2025. Minilongbench: The low-cost long context understanding benchmark for large language models. In Annual Meeting of the Association for Computational Linguistics, pages 11442--11460
2025
-
[35]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. 2024 b . Vbench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807--21818
2024
- [36]
- [37]
- [38]
- [39]
-
[40]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[41]
Kangsan Kim, Geon Park, Youngwan Lee, Woongyeong Yeo, and Sung Ju Hwang. 2025. Videoicl: Confidence-based iterative in-context learning for out-of-distribution video understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3295--3305
2025
- [42]
-
[43]
Gyubin Lee, Bao N Nguyen Truong, Jaesik Yoon, Dongwoo Lee, Minsu Kim, Yoshua Bengio, and Sungjin Ahn. 2025. Adaptive inference-time scaling via cyclic diffusion search. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
- [44]
-
[45]
Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, Jianfeng Gao, et al. 2024 a . Multimodal foundation models: From specialists to general-purpose assistants. Foundations and Trends in Computer Graphics and Vision , 16(1-2):1--214
2024
-
[46]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730--19742. PMLR
2023
- [47]
-
[48]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. 2024 b . Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195--22206
2024
- [49]
- [50]
-
[51]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. 2024 c . Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Jian Liang, Ran He, and Tieniu Tan. 2025. A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision, 133(1):31--64
2025
-
[53]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll \'a r, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740--755. Springer
2014
-
[54]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023 a . Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36:44776--44791
2023
- [55]
-
[56]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023 b . Visual instruction tuning. Advances in neural information processing systems, 36:34892--34916
2023
-
[57]
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. 2023. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. 2024. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. 2025. Inference-time scaling for diffusion models beyond scaling denoising steps. arXiv preprint arXiv:2501.09732
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. 2022. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters, 7(3):7327--7334
2022
- [61]
- [62]
-
[63]
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. 2024. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, et al. 2024. We-math: Does your large multimodal model achieve human-like mathematical reasoning? arXiv preprint arXiv:2407.01284
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Yuming Qiao, Yuechen Wang, Xudong Zhang, and Dan Meng. 2025. Ttgen: Incorporating test-time scaling to diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3362--3366
2025
-
[66]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763
2021
- [67]
- [68]
-
[69]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479--36494
2022
-
[70]
Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. 2025. Zoomeye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6613--6629
2025
- [71]
-
[72]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [73]
-
[74]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[75]
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. 2026. Dynamic cheatsheet: Test-time learning with adaptive memory. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7080--7106
2026
-
[76]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [77]
- [78]
-
[79]
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. 2024. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095--95169
2024
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.