SCOPE-RL: Stable and Quantitative Control of Policy Entropy in RL Post-Training
Pith reviewed 2026-05-21 20:26 UTC · model grok-4.3
The pith
High-temperature positive samples increase policy entropy and can reverse its collapse in RL post-training of LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under high-temperature sampling, positive samples promote entropy growth while negative samples suppress it; when entropy is decreasing during policy updates its partial derivative with respect to temperature is strictly positive for positive-sample updates, so high-temperature positive samples can slow or reverse entropy collapse. SCOPE-RL therefore introduces a regularization term constructed from temperature-adaptive positive samples that achieves stable, quantitative entropy control and consistently improves Pass@1 and Pass@k.
What carries the argument
Regularization term built from temperature-adaptive positive samples that exploits the positive derivative of entropy with respect to temperature under positive-sample updates.
If this is right
- SCOPE-RL keeps entropy inside a stable regime without introducing oscillatory behavior or reward degradation.
- Escaping entropy collapse improves reasoning performance on Pass@1 and Pass@k metrics.
- The benefit of higher entropy is non-monotonic, so an optimal intermediate level of exploration exists for RL post-training of reasoning LLMs.
- The method supplies a concrete lever for quantitative entropy control that earlier bonuses and clipping approaches lack.
Where Pith is reading between the lines
- The same temperature-adaptive positive-sample construction could be inserted into other policy-gradient algorithms that currently suffer rapid entropy decay.
- If the derivative sign flips under negative samples, one could also design a complementary term that selectively damps entropy when it becomes too high.
- The non-monotonic performance curve suggests that future work should search for the entropy target that maximizes downstream reasoning accuracy rather than simply maximizing or minimizing entropy.
Load-bearing premise
The observed asymmetry between positive and negative samples at high temperature generalizes beyond the tested models, tasks, and sampling temperatures, and the added regularization does not create new instabilities or reward degradation.
What would settle it
Apply SCOPE-RL to a new reasoning task or model family at the same temperature schedule and measure whether policy entropy still collapses to near-zero while Pass@1 and Pass@k remain no better than the GRPO baseline.
Figures
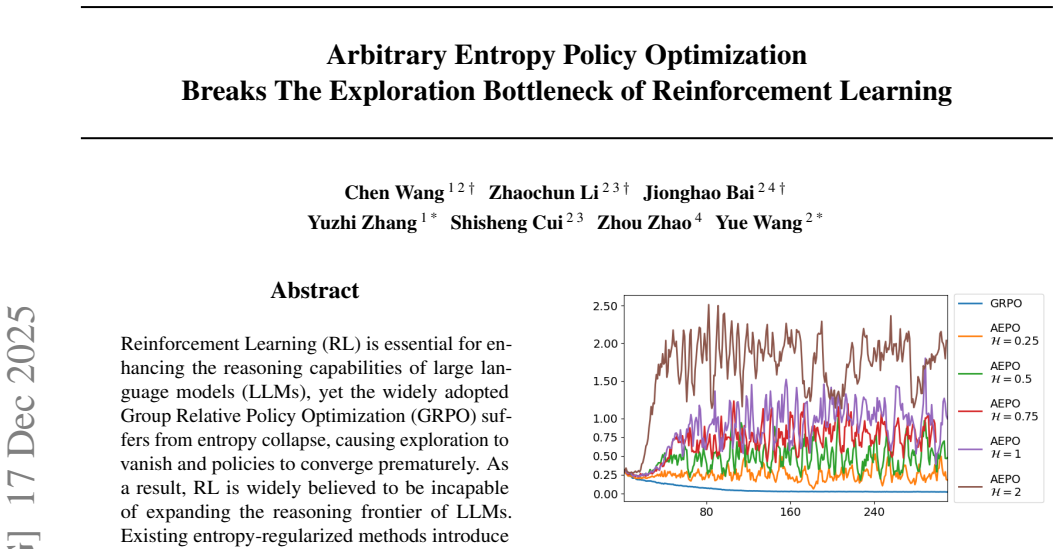


read the original abstract
Reinforcement learning (RL) is a key paradigm for post-training large language models (LLMs), but the widely used Group Relative Policy Optimization (GRPO) often suffers from entropy collapse: exploration quickly disappears, policies converge prematurely, and sample diversity declines, ultimately harming training effectiveness. Existing remedies, including entropy bonuses and clip-based methods, rarely keep entropy within a stable exploration regime and often introduce oscillatory entropy or reward degradation. In this work, we identify a previously overlooked asymmetry in entropy dynamics: under high-temperature sampling, positive and negative samples have opposite effects on policy entropy. Specifically, high-temperature positive samples promote entropy growth, whereas negative samples suppress it. We provide a theoretical explanation for this phenomenon: when entropy decreases during policy updates, its derivative with respect to temperature is strictly positive under positive-sample updates, indicating that high-temperature positive samples can counteract entropy decay, thereby slowing entropy collapse and potentially reversing it. Motivated by this insight, we propose SCOPE-RL, a stable and quantitative entropy control framework through a regularization term constructed from temperature-adaptive positive samples. Extensive experiments show that SCOPE-RL consistently outperforms strong RL baselines on both Pass@1 and Pass@$k$. Our results provide evidence that escaping entropy collapse can improve reasoning performance, while also showing that the benefit is non-monotonic, with an optimal level of exploration for RL post-training in reasoning LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that GRPO-based RL post-training of LLMs suffers from entropy collapse, identifies an asymmetry in entropy dynamics under high-temperature sampling (positive samples promote entropy growth, negative samples suppress it), and provides a theoretical explanation that the derivative of entropy w.r.t. temperature is strictly positive under positive-sample updates when entropy is decreasing. Motivated by this, it introduces SCOPE-RL, a regularization framework using temperature-adaptive positive samples for stable quantitative entropy control, and reports consistent outperformance over baselines on Pass@1 and Pass@k with evidence of non-monotonic benefits from controlled exploration.
Significance. If the theoretical derivative result and empirical findings hold, the work supplies a principled mechanism for maintaining exploration in LLM RL post-training without the oscillations or reward degradation seen in prior entropy bonuses or clipping methods. The observation of an optimal (non-monotonic) exploration level for reasoning performance is a useful empirical contribution, and the quantitative control via temperature-adaptive regularization directly targets a load-bearing failure mode in current GRPO pipelines.
major comments (2)
- [Theoretical explanation (abstract and §3/§4)] Abstract and theoretical section: the central claim that 'its derivative with respect to temperature is strictly positive under positive-sample updates' is stated without any derivation steps, full equations, or proof. It is therefore impossible to verify independence from the regularization coefficient or to check whether the sign remains positive when positive/negative labels are assigned under the temperature-altered distribution produced by GRPO.
- [Experimental results] Experiments: the reported consistent outperformance on Pass@1 and Pass@k lacks error bars, ablation results on the regularization coefficient, and any analysis of how data exclusions or fitting choices affect the entropy-control claim. This weakens the assertion of 'quantitative' and 'stable' control.
minor comments (2)
- [Method] Clarify the exact form of the regularization term and its dependence on the temperature schedule; the current description leaves open whether the term introduces new instabilities outside the tested regime.
- [Abstract and experiments] Notation: Pass@$k$ should be written consistently as Pass@k throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Theoretical explanation (abstract and §3/§4)] Abstract and theoretical section: the central claim that 'its derivative with respect to temperature is strictly positive under positive-sample updates' is stated without any derivation steps, full equations, or proof. It is therefore impossible to verify independence from the regularization coefficient or to check whether the sign remains positive when positive/negative labels are assigned under the temperature-altered distribution produced by GRPO.
Authors: We agree that the theoretical claim in the abstract and §3 requires explicit derivation steps for verifiability. In the revised manuscript we will expand the theoretical section to include the full step-by-step derivation of the entropy derivative with respect to temperature under positive-sample updates. The added material will show all intermediate equations, state the assumptions clearly, demonstrate independence from the regularization coefficient, and address the sign of the derivative when labels are assigned under the temperature-altered GRPO distribution. revision: yes
-
Referee: [Experimental results] Experiments: the reported consistent outperformance on Pass@1 and Pass@k lacks error bars, ablation results on the regularization coefficient, and any analysis of how data exclusions or fitting choices affect the entropy-control claim. This weakens the assertion of 'quantitative' and 'stable' control.
Authors: We acknowledge that the experimental section would be strengthened by additional reporting. In the revision we will add error bars computed over multiple independent runs for all Pass@1 and Pass@k results. We will also include ablations over a range of regularization coefficients to illustrate the stability of entropy control. Finally, we will add a short analysis subsection discussing data exclusions and fitting choices and their influence on the entropy-control observations. revision: yes
Circularity Check
No significant circularity; theoretical claim presented as independent derivation without reduction to inputs by construction.
full rationale
The abstract presents a theoretical explanation that the derivative of entropy w.r.t. temperature is strictly positive under positive-sample updates when entropy is decreasing. No equations, proofs, or self-citations are provided in the given text that would allow exhibiting a specific reduction (e.g., the claimed derivative equaling a fitted parameter or input by definition). The regularization term is motivated by the insight rather than defined in terms of it. No fitted-input-called-prediction, self-definitional, or uniqueness-imported patterns are identifiable. The derivation chain appears self-contained against external benchmarks in the abstract.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization coefficient
axioms (1)
- domain assumption When entropy decreases during policy updates, its derivative with respect to temperature is strictly positive under positive-sample updates.
Forward citations
Cited by 4 Pith papers
-
Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR
RLRT augments GRPO by reinforcing tokens on correct student rollouts that the teacher would not have predicted, outperforming standard self-distillation and exploration baselines on Qwen3 models.
-
Understanding and Preventing Entropy Collapse in RLVR with On-Policy Entropy Flow Optimization
OPEFO prevents entropy collapse in RLVR by rescaling token updates according to their entropy change contributions, yielding more stable optimization and better results on math benchmarks.
-
Advantage Collapse in Group Relative Policy Optimization: Diagnosis and Mitigation
The paper shows that advantage collapse in GRPO causes training stagnation on math reasoning benchmarks and proposes AVSPO, which uses real-time monitoring to inject virtual reward samples and reduces collapse while i...
-
OGER: A Robust Offline-Guided Exploration Reward for Hybrid Reinforcement Learning
OGER adds an auxiliary exploration reward built from offline trajectories and model entropy to hybrid RL training, yielding gains on math reasoning benchmarks and out-of-domain generalization.
Reference graph
Works this paper leans on
-
[1]
Reasoning with Exploration: An Entropy Perspective
Cheng, D., Huang, S., Zhu, X., Dai, B., Zhao, W. X., Zhang, Z., and Wei, F. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Cui, G., Zhang, Y ., Chen, J., Yuan, L., Wang, Z., Zuo, Y ., Li, H., Fan, Y ., Chen, H., Chen, W., et al. The entropy mech- anism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Du, W., Yang, Y ., and Welleck, S. Optimizing temperature for language models with multi-sample inference.arXiv preprint arXiv:2502.05234,
-
[5]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
GLM, T., Zeng, A., Xu, B., Wang, B., Zhang, C., Yin, D., Zhang, D., Rojas, D., Feng, G., Zhao, H., et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Hou, Z., Lv, X., Lu, R., Zhang, J., Li, Y ., Yao, Z., Li, J., Tang, J., and Dong, Y . Advancing language model reasoning through reinforcement learning and inference scaling.arXiv preprint arXiv:2501.11651,
-
[8]
AIME 2024 Dataset (AIME I & II)
HuggingFaceH4. AIME 2024 Dataset (AIME I & II). https://huggingface.co/datasets/ HuggingFaceH4/aime_2024,
work page 2024
-
[9]
Li, G., Lin, M., Galanti, T., Tu, Z., and Yang, T. Disco: Re- inforcing large reasoning models with discriminative con- strained optimization.arXiv preprint arXiv:2505.12366,
-
[10]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tuning.arXiv preprint arXiv:2304.08485,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Equivalence Between Policy Gradients and Soft Q-Learning
Schulman, J., Chen, X., and Abbeel, P. Equivalence be- tween policy gradients and soft q-learning.arXiv preprint arXiv:1704.06440, 2017a. Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017b. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
On entropy control in llm-rl algorithms.arXiv preprint arXiv:2509.03493,
9 Preprint Shen, H. On entropy control in llm-rl algorithms.arXiv preprint arXiv:2509.03493,
-
[16]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V . I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al. Gemini 1.5: Unlocking multimodal understand- ing across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Team, K., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Reinforcement Learning for LLM Post-Training: A Survey
Wang, Z., Bi, B., Pentyala, S. K., Ramnath, K., Chaudhuri, S., Mehrotra, S., Mao, X.-B., Asur, S., et al. A compre- hensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more.arXiv preprint arXiv:2407.16216,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
MM-LIMA: Less Is More for Alignment in Multi-Modal Datasets
Wei, L., Jiang, Z., Huang, W., and Sun, L. Instructiongpt- 4: A 200-instruction paradigm for fine-tuning minigpt-4. arXiv preprint arXiv:2308.12067,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Fan, T., Liu, G., Liu, L., Liu, X., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yue, Y ., Chen, Z., Lu, R., Zhao, A., Wang, Z., Song, S., and Huang, G. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Zhang, X., Wen, S., Wu, W., and Huang, L. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity.arXiv preprint arXiv:2507.21848,
-
[26]
Dpo meets ppo: Reinforced token optimization for rlhf.arXiv preprint arXiv:2404.18922,
Zhong, H., Shan, Z., Feng, G., Xiong, W., Cheng, X., Zhao, L., He, D., Bian, J., and Wang, L. Dpo meets ppo: Reinforced token optimization for rlhf.arXiv preprint arXiv:2404.18922,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.