OneCanvas: 3D Scene Understanding via Panoramic Reprojection
Pith reviewed 2026-06-26 21:36 UTC · model grok-4.3
The pith
OneCanvas projects multi-view image patches onto a single equirectangular canvas using 3D world coordinates and position embeddings, enabling pretrained VLMs to perform 3D scene understanding directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
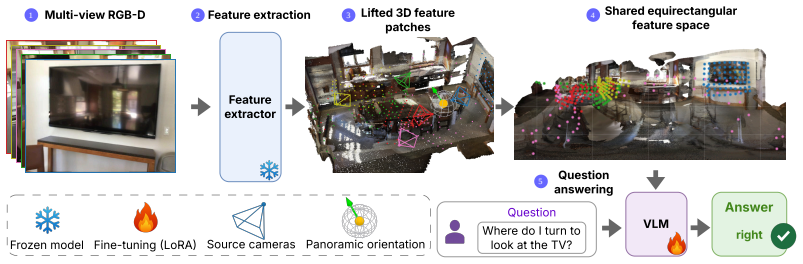
OneCanvas aggregates patch features from all views onto a single equirectangular panoramic canvas. Each patch is unprojected to a 3D world coordinate using its depth and camera pose, then placed on the canvas at the continuous longitude and latitude of that point as seen from the canvas origin, with no rasterization or aggregation across overlapping views. A 3D position embedding of the patch's metric coordinates is added to its feature. The pretrained VLM consumes this representation as if it were an ordinary image, supporting situated reasoning from a specific viewpoint.
What carries the argument
The equirectangular panoramic canvas where patches are placed at continuous longitude and latitude based on unprojected 3D coordinates, augmented with 3D position embeddings to retain metric depth.
If this is right
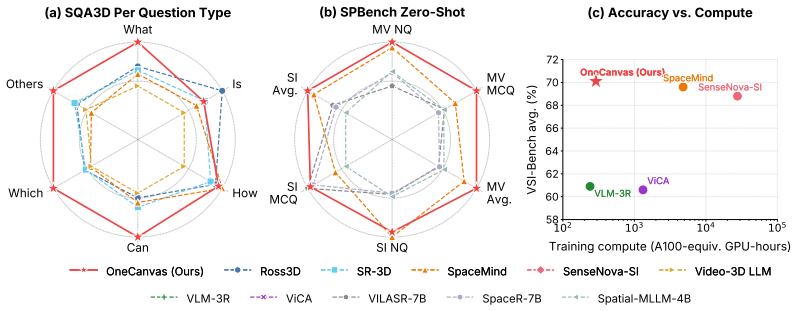
- Achieves state-of-the-art accuracy on SQA3D and VSI-Bench benchmarks.
- Generalizes to out-of-distribution data on SPBench.
- Requires an order of magnitude less training compute than competing methods.
- Directly supports situated reasoning from any chosen viewpoint without additional modifications.
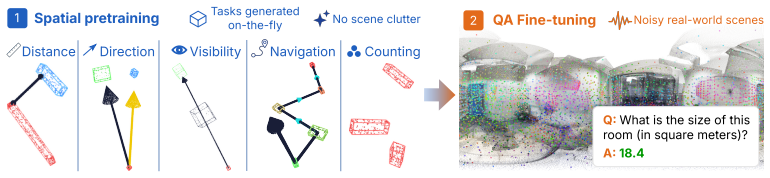
- Enables a spatial pretraining curriculum that generates on-the-fly supervision for spatial tasks with controlled answer distributions.
Where Pith is reading between the lines
- The canvas approach might extend to other embodied AI tasks where viewpoint-specific reasoning is needed.
- Procedural placement of patches could be used to create more diverse training sets for other spatial understanding problems.
- Since it works with pretrained models, it could lower the barrier for applying VLMs in robotics without full retraining.
Load-bearing premise
Unprojecting patches to 3D world coordinates, placing them continuously on the canvas by angle, and adding a 3D position embedding is sufficient for a pretrained VLM to recover and reason over metric spatial structure.
What would settle it
An experiment showing that the model cannot correctly answer questions that require distinguishing metric distances or positions when patches map to similar angular locations on the canvas but differ in depth.
Figures

read the original abstract
Existing approaches to 3D scene understanding in Vision-Language Models (VLMs) either rely on complex, model-specific geometry encoders or large training budgets in pursuit of spatial reasoning. Instead, OneCanvas aggregates patch features from all views onto a single equirectangular panoramic canvas. Namely, each patch is unprojected to a 3D world coordinate using its depth and camera pose, then placed on the canvas at the continuous longitude and latitude of that point as seen from the canvas origin, with no rasterization or aggregation across overlapping views. A 3D position embedding of the patch's metric coordinates is added to its feature, restoring the depth lost when collapsing the world position to an angular canvas coordinate. Patches from all frames thus share one spatial coordinate system with no fusion or major architectural modifications of the backbone. The pretrained VLM consumes this representation as if it were an ordinary image. Because the canvas can be centered on any pose of interest, the same representation directly supports situated reasoning from a specific viewpoint, a common requirement in robotics and embodied AI. Thanks to this representation, we can also introduce a spatial pretraining curriculum: by procedurally placing patch features of objects, drawn from real images, at chosen 3D world positions on an otherwise empty canvas, we generate on-the-fly supervision spanning a broad range of spatial reasoning tasks, with answer distributions controlled to reduce spatial reasoning shortcuts. OneCanvas achieves state-of-the-art accuracy on SQA3D and VSI-Bench, and generalizes to out-of-distribution data on SPBench, using an order of magnitude less training compute than the strongest competing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OneCanvas, a method for 3D scene understanding in pretrained VLMs that aggregates multi-view patch features onto a single equirectangular panoramic canvas. Each patch is unprojected to 3D world coordinates using depth and camera pose, then placed at its continuous longitude/latitude as viewed from the canvas origin, without rasterization or overlap aggregation; a 3D position embedding is added to restore metric depth. This representation is consumed directly by the frozen VLM as an ordinary image and supports situated reasoning by recentering the canvas. The work also introduces a spatial pretraining curriculum that procedurally places real-image object patches at chosen 3D positions on empty canvases to generate controlled supervision. The abstract claims state-of-the-art accuracy on SQA3D and VSI-Bench, out-of-distribution generalization on SPBench, and an order-of-magnitude reduction in training compute relative to competing methods.
Significance. If the continuous angular reprojection plus 3D embeddings indeed allow a frozen VLM to perform metric spatial reasoning without architectural changes or heavy fine-tuning, the approach would offer a lightweight alternative to specialized 3D encoders and large-scale 3D pretraining. The ability to generate on-the-fly spatial supervision with controlled answer distributions and to support viewpoint-specific reasoning would be particularly valuable for embodied AI and robotics applications.
major comments (2)
- [method description] The central claim that the canvas representation enables metric spatial reasoning rests on the unstated assumption that continuous lon/lat placement of unprojected patches (with no rasterization or aggregation) plus a 3D position embedding produces a tensor from which a pretrained VLM can recover depth and 3D structure as if it were an ordinary image. This is load-bearing for both the "no major architectural modifications" and SOTA claims, yet the manuscript supplies neither a formal argument nor an ablation isolating the contribution of the continuous placement versus implicit discretization (method description).
- [experiments section] The abstract asserts SOTA results on SQA3D/VSI-Bench and 10× compute savings, but the provided text contains no experimental details, baselines, ablations, error analysis, or quantitative compute measurements. Without these, the performance claims cannot be evaluated and the weakest assumption (that the representation suffices for the observed gains) remains untested (experiments section).
minor comments (1)
- [abstract] The sentence beginning "Namely," in the abstract is grammatically awkward and should be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our submission. We address the two major comments point by point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [method description] The central claim that the canvas representation enables metric spatial reasoning rests on the unstated assumption that continuous lon/lat placement of unprojected patches (with no rasterization or aggregation) plus a 3D position embedding produces a tensor from which a pretrained VLM can recover depth and 3D structure as if it were an ordinary image. This is load-bearing for both the "no major architectural modifications" and SOTA claims, yet the manuscript supplies neither a formal argument nor an ablation isolating the contribution of the continuous placement versus implicit discretization (method description).
Authors: We agree that the manuscript would benefit from an explicit discussion of why continuous angular placement combined with the 3D embedding suffices for the VLM to recover metric structure. The current method section describes the unprojection, continuous lon/lat assignment, and embedding addition, but does not isolate their individual contributions via ablation. We will add a short formal motivation paragraph and a targeted ablation comparing continuous versus discretized placement in the revised version. revision: yes
-
Referee: [experiments section] The abstract asserts SOTA results on SQA3D/VSI-Bench and 10× compute savings, but the provided text contains no experimental details, baselines, ablations, error analysis, or quantitative compute measurements. Without these, the performance claims cannot be evaluated and the weakest assumption (that the representation suffices for the observed gains) remains untested (experiments section).
Authors: The full manuscript contains an experiments section reporting results on SQA3D, VSI-Bench, and SPBench together with baseline comparisons and compute measurements. However, we acknowledge that these details may not have been presented with sufficient clarity or completeness for evaluation. We will expand the section to include additional ablations on the representation, quantitative training-compute tables, and error analysis in the revision. revision: yes
Circularity Check
No circularity: representation and curriculum are independent of claimed performance
full rationale
The paper introduces a panoramic canvas construction (unproject patches to 3D world coordinates, place at continuous lon/lat from canvas origin, add 3D position embedding) and a procedural spatial pretraining curriculum that places real-image patch features at chosen 3D positions. These are presented as engineering choices that let a frozen VLM consume the tensor as an ordinary image. No equations, fitted parameters, or self-citations are shown that reduce the SOTA claims on SQA3D/VSI-Bench or the 10x compute reduction to a self-referential definition or input fit. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or prior author results as load-bearing justification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Accurate per-patch depth and camera poses are available as input
invented entities (1)
-
OneCanvas equirectangular panoramic canvas
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Hunar Batra, Haoqin Tu, Hardy Chen, Yuanze Lin, Cihang Xie, and Ronald Clark. Spatialthinker: Reinforcing 3d reasoning in multimodal llms via spatial rewards.arXiv preprint arXiv:2511.07403,
-
[3]
Thinking with spatial code for physical-world video reasoning.arXiv preprint arXiv:2603.05591,
Jieneng Chen, Wenxin Ma, Ruisheng Yuan, Yunzhi Zhang, Jiajun Wu, and Alan Yuille. Thinking with spatial code for physical-world video reasoning.arXiv preprint arXiv:2603.05591,
-
[4]
arXiv preprint arXiv:2509.13317 (2025)
An-Chieh Cheng, Yang Fu, Yukang Chen, Zhijian Liu, Xiaolong Li, Subhashree Radhakrishnan, Song Han, Yao Lu, Jan Kautz, Pavlo Molchanov, et al. 3d aware region prompted vision language model.arXiv preprint arXiv:2509.13317,
-
[5]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Visuospatial cognitive assistant.arXiv preprint arXiv:2505.12312,
Qi Feng. Visuospatial cognitive assistant.arXiv preprint arXiv:2505.12312,
-
[7]
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers.Advances in Neural Information Processing Systems, 37:113991– 114017, 2024a. Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao L...
-
[8]
Seongmin Jung, Seongho Choi, Gunwoo Jeon, Minsu Cho, and Jongwoo Lim. Panogrounder: Bridging 2d and 3d with panoramic scene representations for vlm-based 3d visual grounding. arXiv preprint arXiv:2512.20907,
work page internal anchor Pith review arXiv
-
[9]
Zekai Lin and Xu Zheng. Panoenv: Exploring 3d spatial intelligence in panoramic environments with reinforcement learning.arXiv preprint arXiv:2602.21992,
-
[10]
Xianzheng Ma, Brandon Smart, Yash Bhalgat, Shuai Chen, Xinghui Li, Jian Ding, Jindong Gu, Dave Zhenyu Chen, Songyou Peng, Jia-Wang Bian, et al. When llms step into the 3d world: A survey and meta-analysis of 3d tasks via multi-modal large language models.arXiv preprint arXiv:2405.10255, 2024a. Xianzheng Ma, Tao Sun, Shuai Chen, Yash Bhalgat, Jindong Gu, A...
-
[11]
11 Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang
URLhttps://arxiv.org/abs/2603.23523. 11 Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes. InInternational Conference on Learning Representations (ICLR),
-
[12]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Mukund Varma T, Peihao Wang, Zhiwen Fan, Zhangyang Wang, Hao Su, and Ravi Ramamoorthi
URL https: //arxiv.org/abs/2603.18002. Mukund Varma T, Peihao Wang, Zhiwen Fan, Zhangyang Wang, Hao Su, and Ravi Ramamoorthi. Lift3d: Zero-shot lifting of any 2d vision model to 3d. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21367–21377,
-
[14]
arXiv preprint arXiv:2308.08769 (2023) 4
Haochen Wang, Yucheng Zhao, Tiancai Wang, Haoqiang Fan, Xiangyu Zhang, and Zhaoxiang Zhang. Ross3d: Reconstructive visual instruction tuning with 3d-awareness. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9275–9286, 2025a. Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny...
-
[15]
Visual spatial tuning.arXiv preprint arXiv:2511.05491,
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. InAdvances in Neural Information Processing Systems (NeurIPS), 2025a. Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with int...
-
[16]
Ruosen Zhao, Zhikang Zhang, Jialei Xu, Jiahao Chang, Dong Chen, Lingyun Li, Weijian Sun, and Zizhuang Wei. Spacemind: Camera-guided modality fusion for spatial reasoning in vision-language models.arXiv preprint arXiv:2511.23075,
-
[17]
Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors. InAdvances in Neural Information Processing Systems (NeurIPS), 2025a. Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representa- tion for 3d scene understanding. InProceedings of the ...
-
[18]
ref” box at the agent position, a “fwd
128 723×27,64895× C Spatial Pretraining Curriculum: Task Details This section details the tasks that make up the stage-1 spatial pretraining curriculum. The curriculum organizes its task instances into six families and applies family-flat weighting: each family contributes an equal share of every minibatch, and every task within a family carries the same ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.