COMFYCLAW: Self-Evolving Skill Harnesses for Image Generation Workflows
Pith reviewed 2026-07-03 14:20 UTC · model grok-4.3
The pith
COMFYCLAW shows agents improve image workflow construction by evolving a skill library from past trajectories and verifier feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
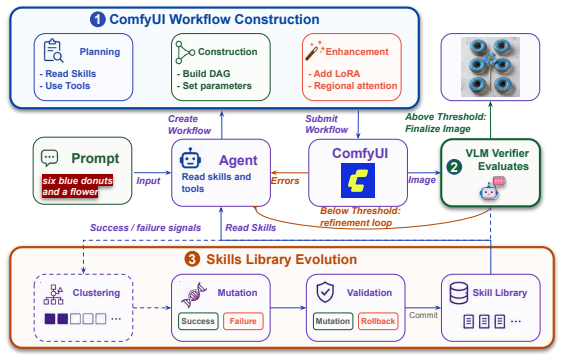
COMFYCLAW formulates workflow construction as typed graph editing, exposes tools by construction stage, automatically reverts invalid edits, and uses a region-level VLM verifier to turn visual failures into repair suggestions; it then evolves a progressively disclosed skill library by distilling trajectories, execution errors, and verifier feedback into reusable Agent Skills, achieving the best average image-generation evaluation score across all six agent configurations and outperforming the verifier-only baseline without skill evolution.
What carries the argument
The progressively disclosed skill library distilled from trajectories, execution errors, and verifier feedback into reusable Agent Skills.
If this is right
- The skill-evolving version produces higher average image generation scores than the fixed-verifier baseline.
- Human annotators rate COMFYCLAW outputs higher than those from the version without skill evolution.
- The gains hold across three different agent models and two image backbones.
- Skill evolution raises reliability for agents on recurring visual workflow tasks.
Where Pith is reading between the lines
- The same distillation process could be tested on non-image workflows such as code or data pipelines to check transfer.
- As the skill library grows, agents might need the verifier less often on familiar tasks.
- Measuring how often a distilled skill is reused on new but related workflows would test whether the library actually generalizes.
Load-bearing premise
Improvements in scores come from distilling past runs into reusable skills rather than from other unmeasured differences in the agent setups or prompts.
What would settle it
Re-running the four benchmark splits with skill evolution turned off but every other component identical and finding no drop in average scores.
Figures

read the original abstract
Agents are increasingly used to construct workflows and assist humans in completing recurring tasks more efficiently. As these workflows become repeated and domain-specific, agent memory and reusable skills become increasingly important: agents should be able to recall workflow patterns, execution constraints, and user preferences from previous runs. We study this problem in workflow-based image generation and introduce COMFYCLAW, an agentic skill evolution harness for controlling ComfyUI workflows. COMFYCLAW formulates workflow construction as typed graph editing, exposes tools organized by construction stage, automatically reverts invalid edits, and uses a region-level vision-language model (VLM) verifier to translate visual failures into actionable repair suggestions. The framework further evolves a progressively disclosed skill library, where trajectories, execution errors, and verifier feedback from previous runs are distilled into reusable Agent Skills. Across four benchmark splits, three agent models, and two image backbones, COMFYCLAW achieves the best average image-generation evaluation score across all six agent configurations, outperforming a verifier-only baseline without skill evolution. Human annotations further show that annotators prefer COMFYCLAW over variants without skill evolution. Our results suggest that skill evolution is an effective mechanism for improving agent reliability and performance in recurring visual workflow construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COMFYCLAW, a framework for agent-driven ComfyUI image-generation workflows that formulates construction as typed graph editing, provides stage-organized tools with automatic invalid-edit reversion, employs a region-level VLM verifier for repair suggestions, and evolves a progressively disclosed skill library by distilling trajectories, errors, and feedback. It reports that COMFYCLAW obtains the highest average image-generation evaluation score across four benchmark splits, three agent models, two backbones, and all six agent configurations, outperforming a verifier-only baseline, with additional human preference for the skill-evolution variant.
Significance. If the performance claims can be substantiated with defined metrics, statistical controls, and isolating ablations, the work would provide concrete evidence that distilling execution history into reusable Agent Skills improves reliability in recurring visual workflow tasks, offering a practical mechanism for agent memory in domain-specific automation.
major comments (2)
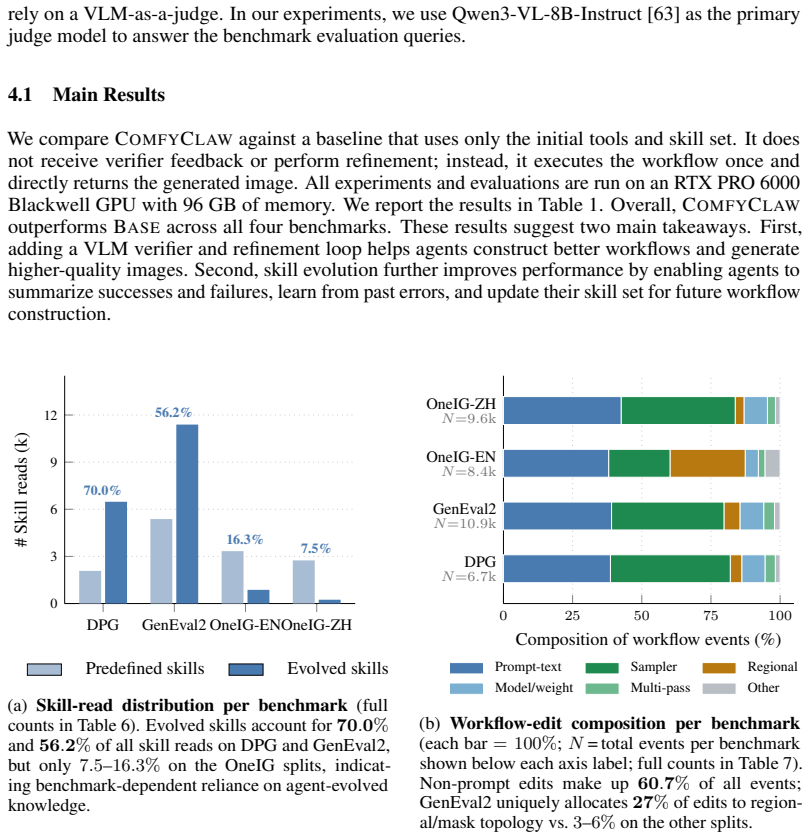
- [Abstract and Experiments] Abstract and Experiments section: the central claim of superior average scores across all six configurations supplies no definition of the image-generation evaluation score, no statistical tests, no error bars, and no exclusion criteria or sample sizes, leaving the reported outperformance unverifiable and the soundness of the empirical result at risk.
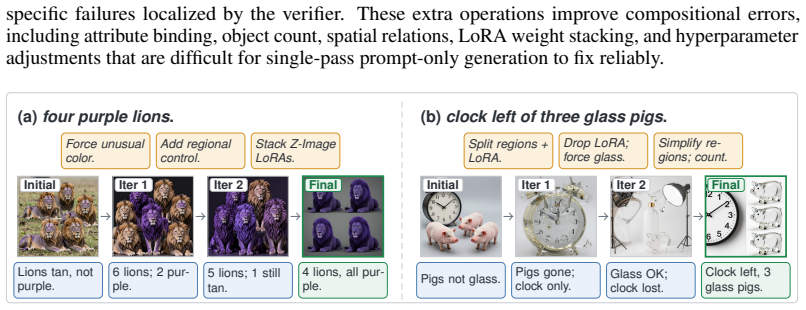
- [Framework and Experiments] Framework and Experiments sections: the comparison to the verifier-only baseline does not include ablations that isolate the contribution of the progressively disclosed skill library from the other introduced mechanisms (typed graph editing, automatic reversion, region-level VLM verifier), so the causality of skill-evolution gains cannot be established from the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our empirical claims and the need for stronger isolation of contributions. We address each major comment below and will revise the manuscript accordingly to improve verifiability and causal attribution.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of superior average scores across all six configurations supplies no definition of the image-generation evaluation score, no statistical tests, no error bars, and no exclusion criteria or sample sizes, leaving the reported outperformance unverifiable and the soundness of the empirical result at risk.
Authors: We agree that the image-generation evaluation score must be explicitly defined and that statistical details are required to substantiate the reported outperformance. In the revised manuscript we will add a precise definition of the evaluation score (including its components and aggregation method) in the Experiments section. We will also report sample sizes, any exclusion criteria, error bars (standard deviations across runs), and appropriate statistical tests (such as paired t-tests) comparing COMFYCLAW against the baseline across the six configurations. revision: yes
-
Referee: [Framework and Experiments] Framework and Experiments sections: the comparison to the verifier-only baseline does not include ablations that isolate the contribution of the progressively disclosed skill library from the other introduced mechanisms (typed graph editing, automatic reversion, region-level VLM verifier), so the causality of skill-evolution gains cannot be established from the reported results.
Authors: We acknowledge that the current verifier-only baseline removes skill evolution while retaining the other mechanisms, and therefore does not fully isolate the skill library's contribution. To establish causality more rigorously, we will add targeted ablation experiments in the revised manuscript that disable the progressively disclosed skill library (while keeping typed graph editing, automatic reversion, and the region-level VLM verifier active) and report the resulting performance differences across the benchmarks. revision: yes
Circularity Check
No circularity: empirical benchmark claims with no derivations or self-referential reductions
full rationale
The paper contains no equations, derivations, or mathematical claims. Its central result is an empirical performance comparison across agent configurations and baselines on image-generation benchmarks. The skill-evolution mechanism is described as one component among several (graph editing, reversion, VLM verifier), but the evaluation reports direct scores rather than any fitted parameter or self-defined quantity that reduces to its own inputs by construction. No self-citation chains or uniqueness theorems are invoked to justify the result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Workflow construction can be formulated as typed graph editing with stage-organized tools and automatic reversion of invalid edits.
- domain assumption A region-level vision-language model can translate visual failures into actionable repair suggestions.
invented entities (1)
-
progressively disclosed skill library of Agent Skills
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Controllable generation with text-to-image diffusion models: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Pu Cao, Feng Zhou, Qing Song, and Lu Yang. Controllable generation with text-to-image diffusion models: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[2]
Comfyui-r1: Exploring reasoning models for workflow generation.arXiv preprint arXiv:2506.09790, 2025
Zhenran Xu, Yiyu Wang, Xue Yang, Longyue Wang, Weihua Luo, Kaifu Zhang, Baotian Hu, and Min Zhang. Comfyui-r1: Exploring reasoning models for workflow generation.arXiv preprint arXiv:2506.09790, 2025
-
[3]
Launching ComfyUI registry
ComfyUI. Launching ComfyUI registry. https://blog.comfy.org/p/ launching-comfyui-registry, 2026. 10
2026
-
[4]
Rinon Gal, Adi Haviv, Yuval Alaluf, Amit H Bermano, Daniel Cohen-Or, and Gal Chechik. Comfygen: Prompt-adaptive workflows for text-to-image generation.arXiv preprint arXiv:2410.01731, 2024
-
[5]
Oucheng Huang, Yuhang Ma, Zeng Zhao, Mingrui Wu, Jiayi Ji, Rongsheng Zhang, Zhipeng Hu, Xiaoshuai Sun, and Rongrong Ji. Comfygpt: A self-optimizing multi-agent system for comprehensive comfyui workflow generation.arXiv preprint arXiv:2503.17671, 2025
-
[6]
SkillDAG: Self-Evolving Typed Skill Graphs for LLM Skill Selection at Scale
Tong Bai, Zhenglin Wan, Pengfei Zhou, Xingrui Yu, Wangbo Zhao, Yang You, and Ivor W Tsang. Skilldag: Self-evolving typed skill graphs for llm skill selection at scale.arXiv preprint arXiv:2606.03056, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Dawei Liu, Zongxia Li, Hongyang Du, Xiyang Wu, Shihang Gui, Yongbei Kuang, and Lichao Sun. Graph of skills: Dependency-aware structural retrieval for massive agent skills.arXiv preprint arXiv:2604.05333, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. Os-copilot: Towards generalist computer agents with self-improvement.arXiv preprint arXiv:2402.07456, 2024
-
[10]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[11]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How capable are web agents at solving common knowledge work tasks? In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, ed...
2024
-
[12]
Xu, Siva Reddy, Gra- ham Neubig, Quentin Cappart, Russ Salakhutdinov, and Nicolas Chapados
Thibault Le Sellier de Chezelles, Maxime Gasse, Alexandre Lacoste, Massimo Caccia, Alexan- dre Drouin, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han Lù, Ori Yoran, Dehan Kong, Frank F. Xu, Siva Reddy, Gra- ham Neubig, Quentin Cappart, Russ Salakhutdinov, and Nicolas Chapados. The browsergym ecosys...
2025
-
[13]
Agents play thousands of 3d video games.arXiv preprint arXiv:2503.13356, 2025
Zhongwen Xu, Xianliang Wang, Siyi Li, Tao Yu, Liang Wang, Qiang Fu, and Wei Yang. Agents play thousands of 3d video games.arXiv preprint arXiv:2503.13356, 2025
-
[14]
Natural-Language Agent Harnesses
Linyue Pan, Lexiao Zou, Shuo Guo, Jingchen Ni, and Hai-Tao Zheng. Natural-language agent harnesses.arXiv preprint arXiv:2603.25723, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Jinwei Su, Qizhen Lan, Zeyu Wang, Yinghui Xia, Hairu Wen, Yiqun Duan, Xi Xiao, Tianyu Shi, Yang Jingsong, and Lewei He. Comfysearch: Autonomous exploration and reasoning for comfyui workflows.arXiv preprint arXiv:2601.04060, 2026
-
[16]
Kaixun Jiang, Yuzheng Wang, Junjie Zhou, Pandeng Li, Zhihang Liu, Chen-Wei Xie, Zhaoyu Chen, Yun Zheng, and Wenqiang Zhang. Genagent: Scaling text-to-image generation via agentic multimodal reasoning.arXiv preprint arXiv:2601.18543, 2026
-
[17]
Comfybench: Benchmarking llm-based agents in comfyui for autonomously designing collaborative ai systems
Xiangyuan Xue, Zeyu Lu, Di Huang, Zidong Wang, Wanli Ouyang, and Lei Bai. Comfybench: Benchmarking llm-based agents in comfyui for autonomously designing collaborative ai systems. InProceedings of the computer vision and pattern recognition conference, pages 24614–24624, 2025. 11
2025
-
[18]
Zefeng He, Siyuan Huang, Xiaoye Qu, Yafu Li, Tong Zhu, Yu Cheng, and Yang Yang. Gems: Agent-native multimodal generation with memory and skills.arXiv preprint arXiv:2603.28088, 2026
-
[19]
Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
2023
-
[20]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[21]
Effective harnesses for long-running agents
Justin Young. Effective harnesses for long-running agents. Anthropic, November 2025
2025
-
[22]
Xinghua Lou, Miguel Lázaro-Gredilla, Antoine Dedieu, Carter Wendelken, Wolfgang Lehrach, and Kevin P Murphy. Autoharness: improving llm agents by automatically synthesizing a code harness.arXiv preprint arXiv:2603.03329, 2026
-
[23]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Jingwei Ni, Yihao Liu, Xinpeng Liu, Yutao Sun, Mengyu Zhou, Pengyu Cheng, Dexin Wang, Xiaoxi Jiang, and Guanjun Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Yunpeng Zhai, Shuchang Tao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Yu, Jiaji Deng, Zouying Cao, et al. Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
-
[29]
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self-evolving agents: On path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 1, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jinyuan Fang, Yanwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, et al. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Comfygi: Automatic improvement of image generation workflows.arXiv preprint arXiv:2411.14193, 2024
Dominik Sobania, Martin Briesch, and Franz Rothlauf. Comfygi: Automatic improvement of image generation workflows.arXiv preprint arXiv:2411.14193, 2024
-
[32]
Blender.https://www.blender.org, 2026
Blender Foundation. Blender.https://www.blender.org, 2026. Accessed: 2026-04-29
2026
-
[33]
Houdini.https://www.sidefx.com, 2026
SideFX. Houdini.https://www.sidefx.com, 2026. Accessed: 2026-04-29
2026
-
[34]
Foundry. Nuke. https://www.foundry.com/products/nuke-family/nuke, 2026. Ac- cessed: 2026-04-29
2026
-
[35]
Unreal engine
Epic Games. Unreal engine. https://www.unrealengine.com, 2026. Accessed: 2026-04- 29. 12
2026
-
[36]
ComfyUI: The most powerful and modular diffusion model gui, api and backend with a graph/nodes interface, 2023
Comfyanonymous. ComfyUI: The most powerful and modular diffusion model gui, api and backend with a graph/nodes interface, 2023. URL https://github.com/comfyanonymous/ ComfyUI. Accessed: 2026-04-29
2023
-
[37]
Litao Guo, Xinli Xu, Luozhou Wang, Jiantao Lin, Jinsong Zhou, Zixin Zhang, Bolan Su, and Ying-Cong Chen. Comfymind: Toward general-purpose generation via tree-based planning and reactive feedback.arXiv preprint arXiv:2505.17908, 2025
-
[38]
Spellburst: A node-based interface for exploratory creative coding with natural language prompts
Tyler Angert, Miroslav Suzara, Jenny Han, Christopher Pondoc, and Hariharan Subramonyam. Spellburst: A node-based interface for exploratory creative coding with natural language prompts. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22, 2023
2023
-
[39]
A visual programming paradigm for abstract deep learning model development
Srikanth G Tamilselvam, Naveen Panwar, Shreya Khare, Rahul Aralikatte, Anush Sankaran, and Senthil Mani. A visual programming paradigm for abstract deep learning model development. InProceedings of the 10th Indian Conference on Human-Computer Interaction, pages 1–11, 2019
2019
-
[40]
Sai Krishna Revanth Vuruma, Ashley Margetts, Jianhai Su, Faez Ahmed, and Biplav Srivastava. From cloud to edge: Rethinking generative ai for low-resource design challenges.arXiv preprint arXiv:2402.12702, 2024
-
[41]
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Dspy: compiling declarative language model calls into state-of-the-art pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, Heather Miller, et al. Dspy: compiling declarative language model calls into state-of-the-art pipelines. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[43]
Agent skills specification
Agent Skills. Agent skills specification. https://agentskills.io/specification, 2026
2026
-
[44]
Claude code.https://code.claude.com/docs/en/overview, 2025
Anthropic. Claude code.https://code.claude.com/docs/en/overview, 2025
2025
-
[45]
Hermes agent: The self-improving ai agent, 2026
Nous Research. Hermes agent: The self-improving ai agent, 2026. URL https://github. com/NousResearch/hermes-agent. Accessed: 2026-04-29
2026
-
[46]
OpenClaw-personal ai assistant, 2026
OpenClaw Contributors. OpenClaw-personal ai assistant, 2026. URL https://github.com/ openclaw/openclaw. Accessed: 2026-04-29
2026
-
[47]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, and Dinesh Manocha. Co-evolving llm decision and skill bank agents for long-horizon tasks, 2026. URLhttps://arxiv.org/abs/2604.20987
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
DeerFlow: Deep exploration and efficient research flow, 2025
ByteDance. DeerFlow: Deep exploration and efficient research flow, 2025. URL https: //github.com/bytedance/deer-flow. Accessed: 2026-04-29
2025
-
[50]
XSkill: Continual Learning from Experience and Skills in Multimodal Agents
Guanyu Jiang, Zhaochen Su, Xiaoye Qu, et al. Xskill: Continual learning from experience and skills in multimodal agents.arXiv preprint arXiv:2603.12056, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Odysseus: Scaling vlms to 100+ turn decision-making in games via reinforcement learning,
Chengshuai Shi, Wenzhe Li, Xinran Liang, Yizhou Lu, Wenjia Yang, Ruirong Feng, Seth Karten, Ziran Yang, Zihan Ding, Gabriel Sarch, Danqi Chen, Karthik Narasimhan, and Chi Jin. Odysseus: Scaling vlms to 100+ turn decision-making in games via reinforcement learning,
-
[52]
URLhttps://arxiv.org/abs/2605.00347
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025. 13
2025
-
[54]
arXiv preprint arXiv:2512.16853 (2025)
Amita Kamath, Kai-Wei Chang, Ranjay Krishna, Luke Zettlemoyer, Yushi Hu, and Marjan Ghazvininejad. Geneval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853, 2025
-
[55]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Oneig-bench: Omni-dimensional nuanced evaluation for image generation, 2025
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation.arXiv preprint arxiv:2506.07977, 2025
-
[57]
Claude, 2025
Anthropic. Claude, 2025. URL https://www.anthropic.com/claude. Accessed: 2026- 04-30
2025
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Gemma 4, 2026
Gemma Team, Google DeepMind. Gemma 4, 2026. URL https://ai.google.dev/gemma/ docs/core/model_card_4
2026
-
[60]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
LongCat-Image Technical Report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, et al. Longcat-image technical report. arXiv preprint arXiv:2512.07584, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
-
[63]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[64]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Realistic snapshot (z-image-turbo)
Civitai Community Model. Realistic snapshot (z-image-turbo). https://civitai.com/ models/2268008/realistic-snapshot-z-image-turbo?modelVersionId=2617751 , 2026
-
[66]
Civitai Community Model. enhancer. https://civitai.com/models/2239743/ enhancer?modelVersionId=2521349, 2026. 14 A Predefined Tools, Skills, and LoRA Settings Workflow tools.We expose 17 basic tools for controlling ComfyUI workflows. These tools allow the agent to inspect the current workflow, add and remove nodes, connect nodes, edit node inputs, set pro...
-
[67]
Call report_evolution_strategy first: state your plan and the top issue
-
[68]
Call inspect_workflow to see the current topology
-
[69]
workflow-builder
**If the workflow is empty** (no nodes): a. Call read_skill("workflow-builder") to load architecture recipes. b. Call query_available_models("checkpoints") and query_available_models("diffusion_models") to discover available models -- NEVER guess filenames. c. Match the model filename to an architecture (SD 1.5, SDXL, Flux, Qwen, etc.) using the patterns ...
-
[70]
Prompt engineering
**If the workflow already has nodes**, follow the evolution strategy: a. Call set_prompt -- craft a detailed, professional positive prompt AND a strong negative prompt based on the user’s goal (see "Prompt engineering" below). Do this EVERY iteration, even if you also plan structural changes. b. If a relevant skill is listed in <available_skills>, call re...
-
[71]
Call ‘inspect_workflow‘ to see the FULL current topology and all connections
-
[72]
Call ‘validate_workflow‘ to get a list of graph errors (dangling refs, wrong slots)
-
[73]
For each error: - If a node references a nonexistent source -> fix with ‘connect_nodes‘ or ‘delete_node‘ - If a slot index is wrong -> ‘delete_node‘ the broken node and ‘add_node‘ a new one with correct wiring - If a model/filename is wrong -> use ‘query_available_models‘ to get exact names, then ‘set_param‘ - If a node class doesn’t exist -> ‘delete_node...
-
[74]
Call ‘validate_workflow‘ again to confirm all issues are resolved
-
[75]
yes" / "no
Call ‘finalize_workflow‘ (it will auto-validate and block if still broken). **IMPORTANT:** Do NOT just add new nodes on top of broken ones -- ‘delete_node‘ the broken node first, then ‘add_node‘ a replacement with correct connections. **Output slot reference:** CheckpointLoaderSimple -> slot 0: MODEL, slot 1: CLIP, slot 2: VAE UNETLoader / CLIPLoader / VA...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.