Generative Skill Composition for LLM Agents
Pith reviewed 2026-07-01 05:26 UTC · model grok-4.3
The pith
SkillComposer generates executable skill plans for LLM agents by predicting sequences that jointly select skills, count, and order.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
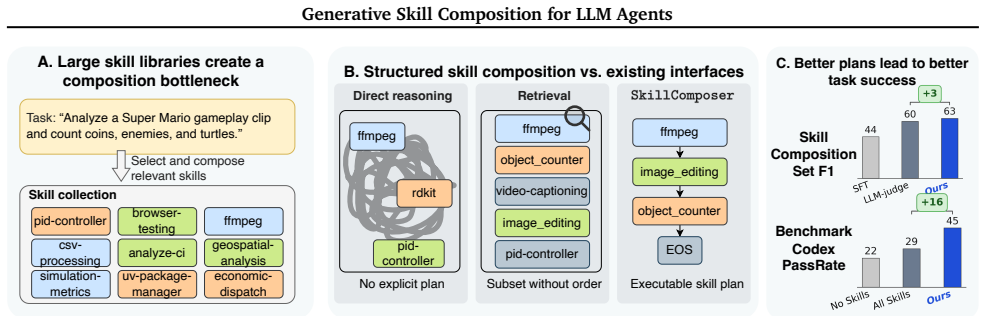
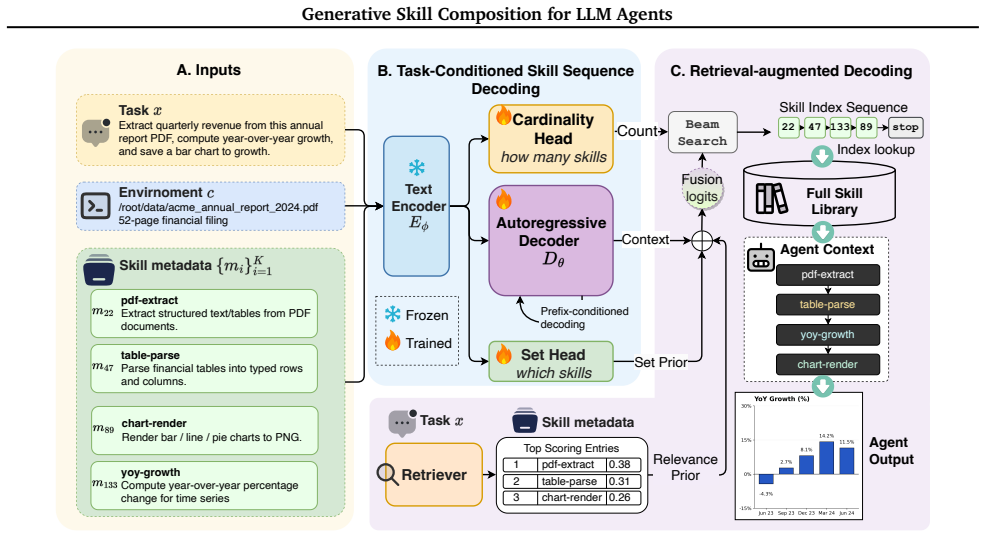
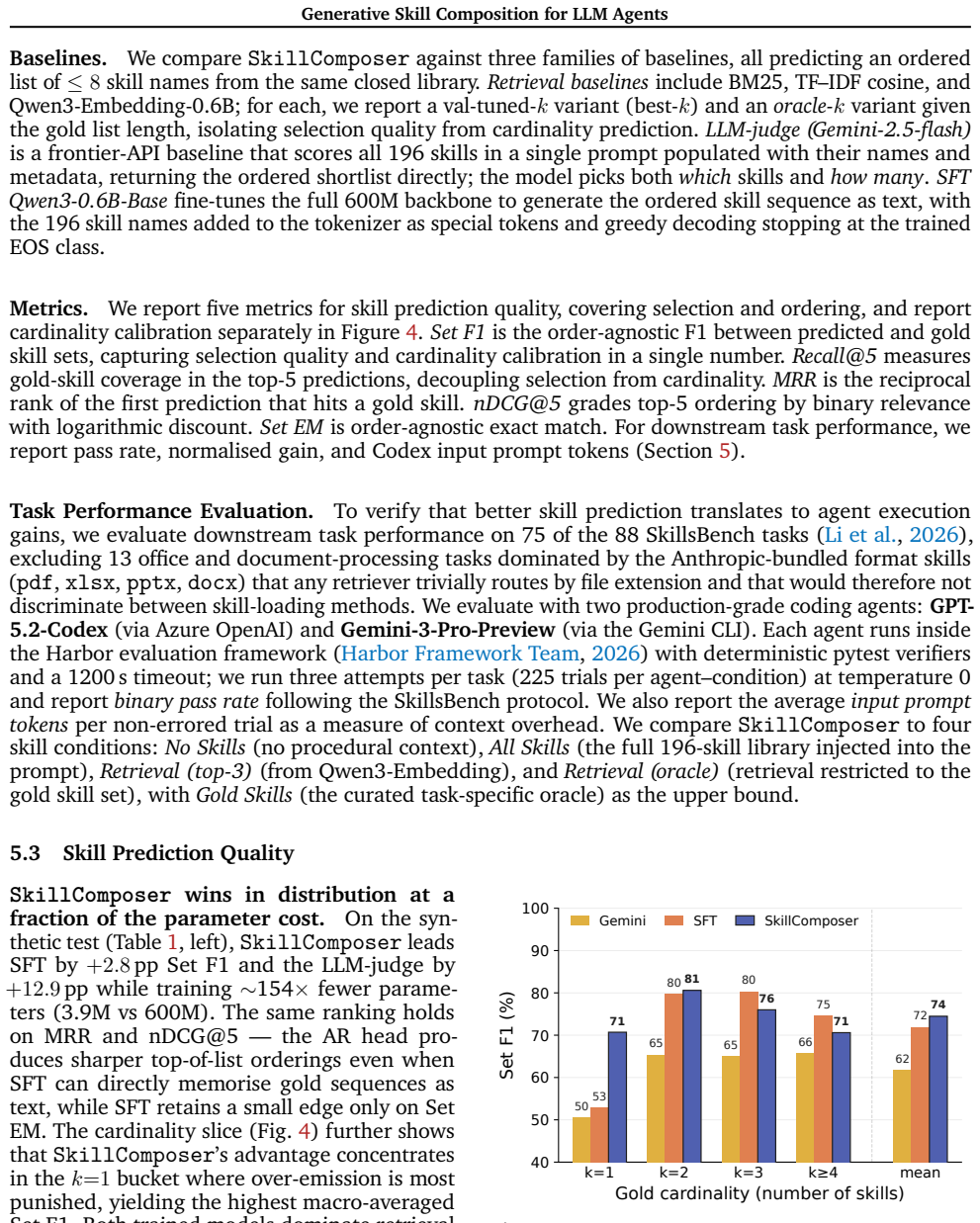
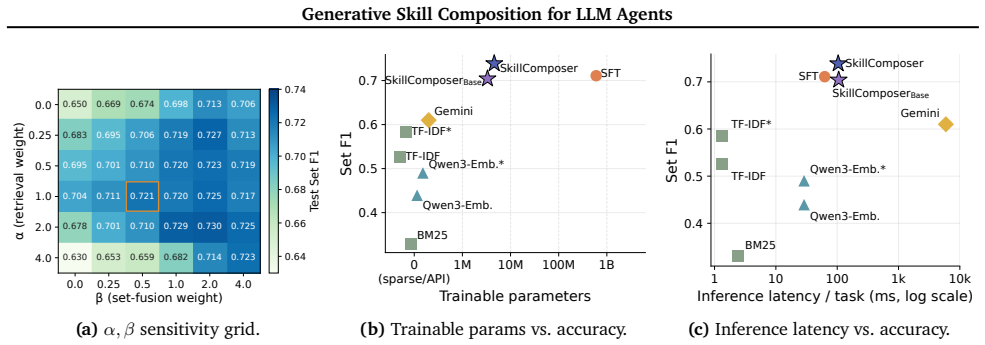
Structured skill composition is the joint prediction of an executable skill plan that specifies the activated subset of skills, their number, and their execution order; SkillComposer realizes this as task-conditioned sequence generation with a constrained autoregressive decoder over skill identifiers, trained on pairs from a real library, and yields higher downstream pass rates on SkillsBench than retrieval baselines while matching the gold-skill upper bound at lower token cost.
What carries the argument
Constrained autoregressive decoder over skill identifiers, from which subset, count, and order emerge jointly in a single pass.
If this is right
- Dependencies between successive skills are captured without separate modeling stages.
- Prompt-token cost drops relative to retrieval while matching oracle performance.
- Composition quality on held-out tasks correlates with downstream agent success on two distinct models.
- The three dimensions of composition (subset, count, order) no longer need to be decoupled.
Where Pith is reading between the lines
- The same sequence-prediction approach could be retrained on non-coding domains if comparable skill libraries become available.
- Iterative decoding or beam search over the same decoder might further improve plan quality without changing the training regime.
- If the learned compositions prove robust, manual curation effort could shift from writing individual skills toward curating only the training pairs.
Load-bearing premise
Task-composition pairs derived from one human-curated skill library will produce compositions that generalize to held-out tasks and transfer to production agents without large distribution shift.
What would settle it
SkillComposer producing lower pass rates than top-3 retrieval when evaluated on a fresh skill library or a task distribution visibly different from the training pairs.
Figures



read the original abstract
Recent LLM agents benefit from skills for solving complex tasks. Skills encapsulate modular packages of procedural knowledge and instructions for performing specialized tasks, such as setting up a sandboxed environment, running a test suite, or refactoring a function across multiple files. As skill libraries grow and become reusable across tasks and domains, selecting an appropriate skill composition has emerged as a central bottleneck. Existing approaches fall into two categories. One exposes the agent's reasoning to the entire skill collection; the other performs skill retrieval via embeddings or LLM-based rerankers. Both provide useful insights; however, they miss the structural nature of skill composition, which is a joint decision over which skills, how many, and in what order -- three dimensions that cannot be decoupled. We formalize this as structured skill composition: given a task and a skill library, predict an executable skill plan that jointly specifies the activated subset, count, and execution order. We propose SkillComposer, which instantiates structured skill composition as task-conditioned skill sequence prediction. SkillComposer uses a constrained autoregressive decoder over skill identifiers, so subset, count, and order emerge jointly from a single decoding pass, and dependencies between successive skills are captured naturally. We build a training set of task-composition pairs from a real, human-curated skill library. We then evaluate SkillComposer along two axes: composition quality on a held-out test set, and downstream task success on SkillsBench across two production-grade coding agents. On GPT-5.2-Codex, Gemini-3-Pro-Preview, SkillComposer raises the pass rate by +23.1, +18.2pp over the no-skill baseline, surpassing top-3 retrieval and matching the gold-skill retrieval upper bound at lower prompt-token cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillComposer as a constrained autoregressive decoder that treats skill composition for LLM agents as joint prediction of subset, count, and order over a skill library. It reports that the approach yields +23.1pp and +18.2pp absolute pass-rate gains on GPT-5.2-Codex and Gemini-3-Pro-Preview respectively on SkillsBench, outperforming top-3 retrieval and matching a gold-skill oracle at lower token cost.
Significance. If the reported gains prove robust to distribution shift, the work supplies a generative formulation of structured skill composition that could replace or complement retrieval-based methods in agent systems. The explicit modeling of dependencies across the three composition dimensions is a clear conceptual contribution.
major comments (2)
- [Abstract] Abstract: the headline gains rest on a training set of task-composition pairs derived from a single human-curated skill library, yet no description is given of how those pairs were constructed, whether held-out tasks share the same skill distribution or templates, or any ablation (e.g., skill-subset or cross-library transfer) that would separate the contribution of the constrained decoder from library-specific memorization. This information is load-bearing for the generalization claim.
- [Abstract] Abstract / evaluation description: downstream transfer to SkillsBench is presented without controls for distribution shift between the training library and the benchmark tasks or any error analysis of composition failures; without these, it is not possible to attribute the matching of the gold-skill upper bound to the proposed mechanism rather than incidental overlap.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency on training data construction and evaluation controls. These points are well-taken and we will strengthen the manuscript with additional details and analyses in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline gains rest on a training set of task-composition pairs derived from a single human-curated skill library, yet no description is given of how those pairs were constructed, whether held-out tasks share the same skill distribution or templates, or any ablation (e.g., skill-subset or cross-library transfer) that would separate the contribution of the constrained decoder from library-specific memorization. This information is load-bearing for the generalization claim.
Authors: We agree that the current manuscript provides insufficient detail on these aspects. In the revised version we will expand the methods section to describe the construction of the task-composition pairs, including the human curation process, template variation, and how the held-out test set was sampled to maintain the same skill distribution while avoiding template overlap. We will also add an ablation isolating the contribution of the constrained decoder on skill-subset prediction. Cross-library transfer experiments are not feasible with the current proprietary library; we will explicitly note this limitation and its implications for the generalization claim. revision: yes
-
Referee: [Abstract] Abstract / evaluation description: downstream transfer to SkillsBench is presented without controls for distribution shift between the training library and the benchmark tasks or any error analysis of composition failures; without these, it is not possible to attribute the matching of the gold-skill upper bound to the proposed mechanism rather than incidental overlap.
Authors: We concur that explicit controls and error analysis are required to support attribution. The revision will include (1) a quantitative comparison of skill overlap and task templates between the training library and SkillsBench, (2) an error analysis breaking down composition failures on the benchmark, and (3) discussion of any observed distribution shift. These additions will clarify the extent to which gains derive from the generative mechanism versus incidental overlap. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a standard supervised learning pipeline: constructing training pairs from a human-curated skill library, training a constrained autoregressive decoder for skill sequence prediction, and evaluating composition quality on a held-out test set plus downstream agent success on SkillsBench. No equations, self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The central claims rest on empirical generalization from training to held-out and downstream data rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SkillRouter: Skill routing for LLM agents at scale.arXiv preprint arXiv:2603.22455, 2026
SkillRouter: Skill Routing for LLM Agents at Scale , author=. arXiv preprint arXiv:2603.22455 , year=
-
[2]
arXiv preprint arXiv:2504.06188 , year=
SkillFlow: Scalable and Efficient Agent Skill Retrieval System , author=. arXiv preprint arXiv:2504.06188 , year=
-
[3]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills , author=. arXiv preprint arXiv:2604.05333 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Skill Retrieval Augmentation for Agentic AI
Skill Retrieval Augmentation for Agentic AI , author=. arXiv preprint arXiv:2604.24594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
SkillsBench: Benchmarking how well agent skills work across diverse tasks , author=. arXiv preprint arXiv:2602.12670 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
SoK: Agentic Skills--Beyond Tool Use in LLM Agents , author=. arXiv preprint arXiv:2602.20867 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill-augmented reinforcement learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale , author=. arXiv preprint arXiv:2601.10338 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2309.17428 , year=
Craft: Customizing llms by creating and retrieving from specialized toolsets , author=. arXiv preprint arXiv:2309.17428 , year=
-
[11]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Creator: Tool creation for disentangling abstract and concrete reasoning of large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Automated creation of reusable and diverse toolsets for enhancing llm reasoning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2310.13227 , year=
Toolchain*: Efficient action space navigation in large language models with a* search , author=. arXiv preprint arXiv:2310.13227 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Taskbench: Benchmarking large language models for task automation , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Advances in neural information processing systems , volume=
Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings , author=. Advances in neural information processing systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Can graph learning improve planning in llm-based agents? , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the 1st workshop on deep learning for recommender systems , pages=
Improved recurrent neural networks for session-based recommendations , author=. Proceedings of the 1st workshop on deep learning for recommender systems , pages=
-
[19]
2018 IEEE international conference on data mining (ICDM) , pages=
Self-attentive sequential recommendation , author=. 2018 IEEE international conference on data mining (ICDM) , pages=. 2018 , organization=
2018
-
[20]
IEEE Transactions on Image Processing , volume=
SR-GNN: Spatial relation-aware graph neural network for fine-grained image categorization , author=. IEEE Transactions on Image Processing , volume=. 2022 , publisher=
2022
-
[21]
Proceedings of the 28th ACM international conference on information and knowledge management , pages=
BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer , author=. Proceedings of the 28th ACM international conference on information and knowledge management , pages=
-
[22]
Proceedings of the 43rd international ACM SIGIR conference on Research and development in Information Retrieval , pages=
Bundle recommendation with graph convolutional networks , author=. Proceedings of the 43rd international ACM SIGIR conference on Research and development in Information Retrieval , pages=
-
[23]
Advances in Neural Information Processing Systems , volume=
Recommender systems with generative retrieval , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations , author=. arXiv preprint arXiv:2402.17152 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in Neural Information Processing Systems , volume=
Deep set prediction networks , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2006.16841 , year=
Conditional set generation with transformers , author=. arXiv preprint arXiv:2006.16841 , year=
-
[27]
arXiv preprint arXiv:2411.02322 , year=
Layerdag: A layerwise autoregressive diffusion model for directed acyclic graph generation , author=. arXiv preprint arXiv:2411.02322 , year=
-
[28]
International conference on machine learning , pages=
DAG-GNN: DAG structure learning with graph neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[29]
Advances in Neural Information Processing Systems , volume=
Spreadsheetbench: Towards challenging real world spreadsheet manipulation , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
SkillX: Automatically constructing skill knowledge bases for agents , author=. arXiv preprint arXiv:2604.04804 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2602.03279 , year=
Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis , author=. arXiv preprint arXiv:2602.03279 , year=
-
[34]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward , author=. arXiv preprint arXiv:2602.12430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in Neural Information Processing Systems , year=
Can Models Learn Skill Composition from Examples? , author=. Advances in Neural Information Processing Systems , year=
-
[36]
arXiv preprint arXiv:2310.17567 , year=
Skill-Mix: A Flexible and Expandable Family of Evaluations for AI models , author=. arXiv preprint arXiv:2310.17567 , year=
-
[37]
arXiv preprint arXiv:2603.22862 , year=
The Evolution of Tool Use in LLM Agents: From Single-Tool Call to Multi-Tool Orchestration , author=. arXiv preprint arXiv:2603.22862 , year=
-
[38]
Benchmarking LLM Tool-Use in the Wild
Benchmarking LLM Tool-Use in the Wild , author=. arXiv preprint arXiv:2604.06185 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2601.21947 , year=
ToolWeaver: Weaving Collaborative Semantics for Scalable Tool Use in Large Language Models , author=. arXiv preprint arXiv:2601.21947 , year=
-
[40]
arXiv preprint arXiv:2510.07768 , year=
Toollibgen: Scalable automatic tool creation and aggregation for llm reasoning , author=. arXiv preprint arXiv:2510.07768 , year=
-
[41]
arXiv preprint arXiv:2405.17935 , year=
Tool Learning with Large Language Models: A Survey , author=. arXiv preprint arXiv:2405.17935 , year=
-
[42]
International Conference on Learning Representations , year=
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? , author=. International Conference on Learning Representations , year=
-
[43]
Advances in Neural Information Processing Systems , year=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. Advances in Neural Information Processing Systems , year=
-
[44]
Advances in Neural Information Processing Systems , year=
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments , author=. Advances in Neural Information Processing Systems , year=
-
[45]
The Twelfth International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[46]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
-
[47]
International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations , year=
-
[48]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[49]
International Conference on Learning Representations , year=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. International Conference on Learning Representations , year=
-
[50]
Advances in Neural Information Processing Systems , year=
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction , author=. Advances in Neural Information Processing Systems , year=
-
[51]
Proceedings of the 31st International Conference on Computational Linguistics , year=
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL , author=. Proceedings of the 31st International Conference on Computational Linguistics , year=
-
[52]
arXiv preprint arXiv:2509.00581 , year=
SQL-of-Thought: Multi-agentic Text-to-SQL with Guided Error Correction , author=. arXiv preprint arXiv:2509.00581 , year=
-
[53]
arXiv preprint arXiv:2510.05318 , year=
BIRD-INTERACT: Re-imagining Text-to-SQL Evaluation for Large Language Models via Lens of Dynamic Interactions , author=. arXiv preprint arXiv:2510.05318 , year=
-
[54]
2025 , howpublished=
Equipping Agents for the Real World with Agent Skills , author=. 2025 , howpublished=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.