DemoPSD: Disagreement-Modulated Policy Self-Distillation
Pith reviewed 2026-07-03 16:18 UTC · model grok-4.3
The pith
DemoPSD steers LLM self-distillation toward a reverse-KL barycenter to attenuate privileged leakage while preserving exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DemoPSD resolves privileged information leakage and exploration suppression in on-policy self-distillation by fitting the student to a disagreement-modulated reverse-KL barycenter target rather than the full teacher distribution, with adaptive per-token weights, and proves both leakage attenuation and exploration preservation while outperforming GRPO and SDPO on SciKnowEval with robust GPQA generalization.
What carries the argument
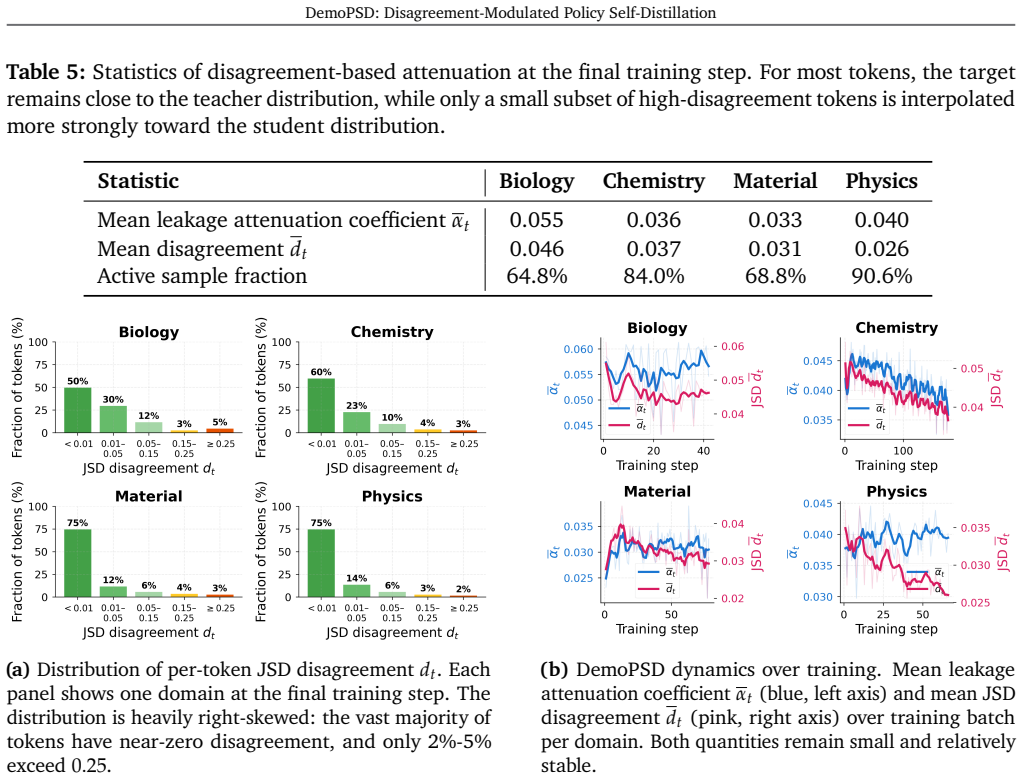
The reverse-KL barycenter target, a weighted geometric mean of teacher and student distributions whose weights are set adaptively by per-token distribution discrepancy.
If this is right
- The student encodes fewer answer-dependent shortcuts unavailable at test time.
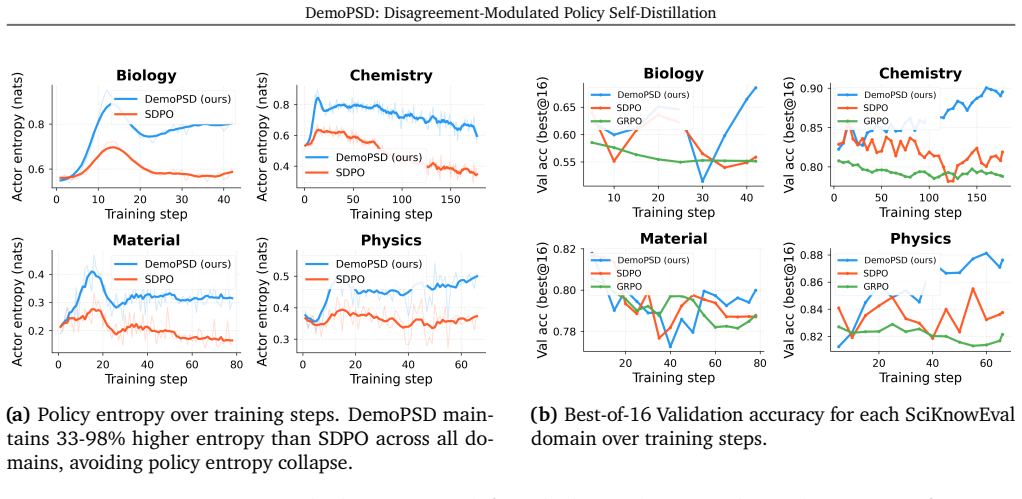
- Training entropy stays higher, supporting continued exploration during optimization.
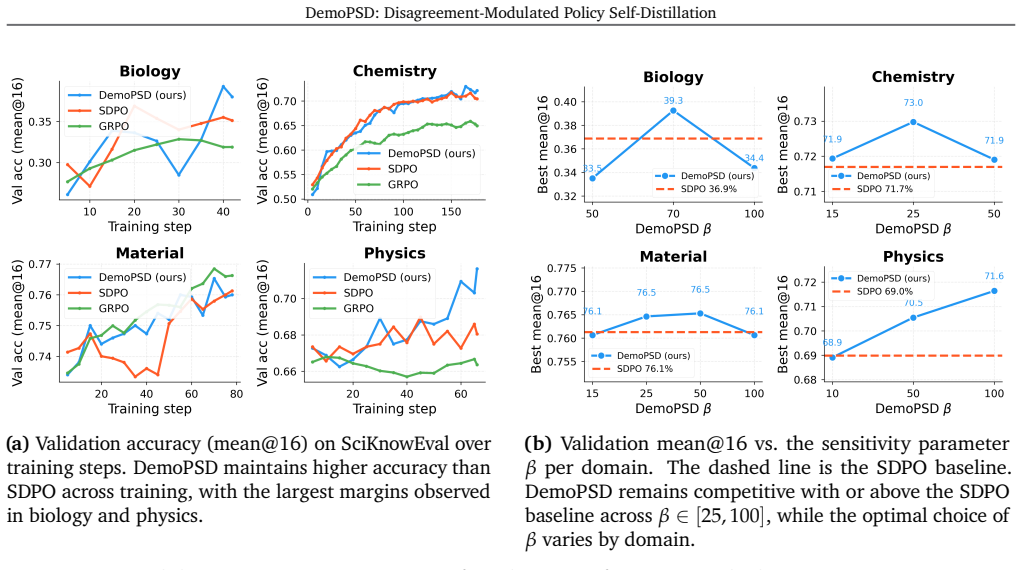
- Performance exceeds GRPO and SDPO on scientific reasoning tasks across four fields.
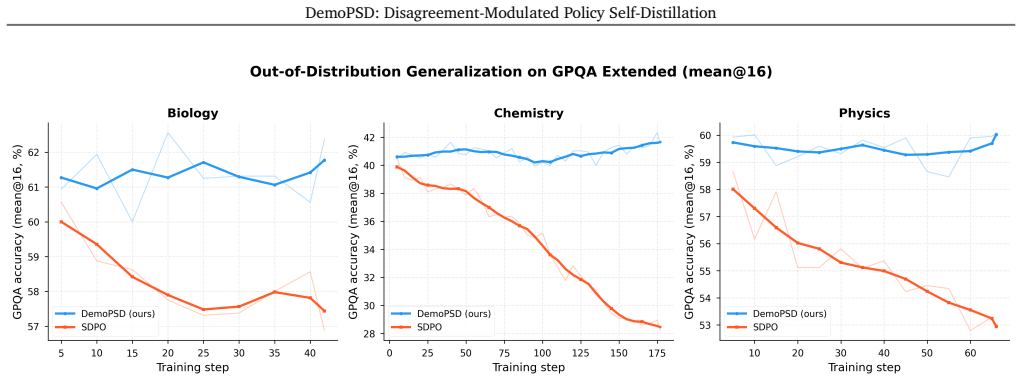
- Generalization to out-of-distribution benchmarks such as GPQA remains robust.
Where Pith is reading between the lines
- Discrepancy-based modulation could apply to other distillation or preference-tuning settings to limit overfitting.
- The same adaptive weighting might extend to multi-teacher or non-self-distillation scenarios.
- Verification on larger models or non-reasoning tasks would test whether the benefits hold beyond the reported benchmarks.
Load-bearing premise
Adaptively weighting the reverse-KL barycenter by per-token distribution discrepancy will reliably produce leakage attenuation and exploration preservation without introducing new overfitting modes or optimization instabilities.
What would settle it
An experiment in which the trained student still encodes answer-dependent shortcuts unavailable at test time or shows lower training entropy than baselines would falsify the central claims.
Figures
read the original abstract
On-policy self-distillation (OPSD) has emerged as a practical method for training large language models (LLMs) to reason, where a single model acts as both the teacher and the student with different levels of information access. However, recent studies have found that the teacher's dense token-level supervision, conditioned on privileged information, can lead to overfitting to in-domain patterns, suppress exploration, and hurt cross-domain generalization, while also introducing a more fundamental issue: *privileged information leakage*, where the student encodes answer-dependent shortcuts that are unavailable at test time. We introduce **DemoPSD**, a novel framework that resolves such problems through the idea of *selective adoption of teacher guidance*. Instead of fitting the full teacher distribution, DemoPSD steers the student toward a *reverse-KL barycenter target*, a weighted geometric combination of the teacher and student distributions, that naturally balances learning from the teacher with preserving the student's own reasoning capacity. We measure the difference between their distributions and use such a discrepancy to adaptively control the blending at each token position. We provably show that DemoPSD achieves **(1)** *leakage attenuation*, i.e., effective mitigation of privileged information leakage; and **(2)** *exploration preservation*, i.e., preservation of exploration capacity under dense token-level distillation. Extensive experiments on SciKnowEval across four scientific fields show that DemoPSD outperforms both GRPO and SDPO while maintaining higher training entropy and robustly generalizing to out-of-distribution GPQA benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DemoPSD, a framework for on-policy self-distillation in LLMs. It steers the student policy toward a reverse-KL barycenter of the teacher and student distributions, with per-token discrepancy used to adaptively weight the blend. The central claims are that this construction provably attenuates privileged-information leakage while preserving exploration capacity, and that it empirically outperforms GRPO and SDPO on SciKnowEval with generalization to GPQA.
Significance. If the theoretical guarantees and empirical robustness hold, the work would provide a concrete mechanism for mitigating a recognized pathology in self-distillation (privileged leakage) without sacrificing the benefits of dense supervision. The combination of a barycenter construction with discrepancy modulation is a natural idea that could influence subsequent distillation and alignment methods.
major comments (3)
- [Theoretical analysis] Theoretical analysis section: the claim of provable leakage attenuation rests on the assumption that measured per-token discrepancy isolates privileged information; no explicit bound or decomposition is supplied that separates leakage-induced discrepancy from optimization noise, capacity mismatch, or domain shift, leaving the isolation step unverified.
- [§4] §4 (or equivalent experimental section): the manuscript reports outperformance on SciKnowEval and robust generalization to GPQA but supplies neither the number of independent runs, statistical significance tests, nor variance estimates; without these the cross-method comparison cannot be assessed as load-bearing evidence.
- [§3] Definition of the reverse-KL barycenter and discrepancy weighting (likely Eq. (X) in §3): the adaptive weighting is presented as guaranteeing both leakage attenuation and entropy preservation, yet the manuscript contains no analysis of whether the weighting can introduce new modes of overfitting or optimization instability when discrepancy arises from non-privileged sources.
minor comments (2)
- Notation for the barycenter weights and discrepancy measure should be introduced with a single consistent symbol table to avoid reader confusion across sections.
- The abstract states 'provably show' results; the main text should include at least a high-level proof sketch or key lemmas even if full proofs are deferred to an appendix.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, indicating planned revisions where appropriate. Our responses aim to clarify the manuscript's contributions while acknowledging areas where additional discussion or analysis can strengthen the presentation.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the claim of provable leakage attenuation rests on the assumption that measured per-token discrepancy isolates privileged information; no explicit bound or decomposition is supplied that separates leakage-induced discrepancy from optimization noise, capacity mismatch, or domain shift, leaving the isolation step unverified.
Authors: We appreciate this observation on the theoretical analysis. The leakage attenuation result is established under the modeling premise that per-token discrepancy serves as a proxy for privileged information access in the teacher distribution, allowing the reverse-KL barycenter to selectively downweight such tokens. While an explicit quantitative decomposition isolating leakage from other discrepancy sources (e.g., optimization noise or domain shift) is not derived, the construction inherently modulates based on observed disagreement. We will revise the theoretical section to more explicitly articulate this assumption, discuss its scope, and note the absence of a full decomposition as a limitation for future work. revision: partial
-
Referee: [§4] §4 (or equivalent experimental section): the manuscript reports outperformance on SciKnowEval and robust generalization to GPQA but supplies neither the number of independent runs, statistical significance tests, nor variance estimates; without these the cross-method comparison cannot be assessed as load-bearing evidence.
Authors: We agree that reporting the number of independent runs, variance estimates, and statistical significance is necessary to substantiate the empirical claims. The original experiments were conducted with multiple random seeds; in the revised manuscript we will explicitly report these details, including means, standard deviations, and significance tests for the SciKnowEval and GPQA results. revision: yes
-
Referee: [§3] Definition of the reverse-KL barycenter and discrepancy weighting (likely Eq. (X) in §3): the adaptive weighting is presented as guaranteeing both leakage attenuation and entropy preservation, yet the manuscript contains no analysis of whether the weighting can introduce new modes of overfitting or optimization instability when discrepancy arises from non-privileged sources.
Authors: The discrepancy-modulated weighting is derived to achieve the stated attenuation and preservation properties when discrepancy correlates with privileged information. We acknowledge that the manuscript does not analyze potential overfitting or instability arising when discrepancy stems from other factors such as capacity mismatch. We will add a dedicated paragraph in §3 discussing this possibility and include supporting training dynamics plots from our experiments to demonstrate stability under the reported conditions. revision: yes
Circularity Check
No circularity detected; derivation not reducible to inputs
full rationale
The abstract states that DemoPSD steers toward a reverse-KL barycenter controlled by per-token discrepancy and claims to 'provably show' leakage attenuation and exploration preservation. No equations, proofs, or derivation steps appear in the provided text. Hard rule 1 requires an explicit quote exhibiting reduction (e.g., Eq. X = Eq. Y by construction or fitted parameter renamed as prediction); none exists. No self-citation load-bearing, ansatz smuggling, or renaming of known results is visible. The central construction is presented as a novel weighting scheme whose properties are asserted rather than shown to collapse into the inputs. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representations, volume 2024, pages 21246–21263,
2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871,
-
[4]
SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
Kehua Feng, Xinyi Shen, Weijie Wang, Xiang Zhuang, Yuqi Tang, Qiang Zhang, and Keyan Ding. Sciknoweval: Evaluating multi-level scientific knowledge of large language models.arXiv preprint arXiv:2406.09098,
-
[5]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, volume 2024, pages 32694–32717,
2024
-
[6]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. Self-distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Stable On-Policy Distillation through Adaptive Target Reformulation
16 DemoPSD: Disagreement-Modulated Policy Self-Distillation Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
Yiqiao Jin, Yiyang Wang, Lucheng Fu, Yijia Xiao, Yinyi Luo, Haoxin Liu, B. Aditya Prakash, Josiah Hester, Jindong Wang, and Srijan Kumar. Unisd: Towards a unified self-distillation framework for large language models.arXiv preprint arXiv:2605.06597,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Respecting Self-Uncertainty in On-Policy Self-Distillation for Efficient LLM Reasoning
Junlong Ke, Zichen Wen, Weijia Li, Conghui He, and Linfeng Zhang. Respecting self-uncertainty in on-policy self-distillation for efficient llm reasoning.arXiv preprint arXiv:2605.13255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?arXiv preprint arXiv:2603.24472,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2603.11137 , year =
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently via relaxed on-policy distillation.arXiv preprint arXiv:2603.11137,
-
[13]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing.arXiv preprint arXiv:2604.02288,
-
[14]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Alex Stein, Furong Huang, and Tom Goldstein. Gates: Self-distillation under privileged context with consensus gating.arXiv preprint arXiv:2602.20574,
-
[21]
PAINT: Partial-Solution Adaptive Interpolated Training for Self-Distilled Reasoners
17 DemoPSD: Disagreement-Modulated Policy Self-Distillation Zhiquan Tan and Yinrong Hong. Paint: Partial-solution adaptive interpolated training for self-distilled reasoners.arXiv preprint arXiv:2604.26573,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
PACED: Distillation and On-Policy Self-Distillation at the Frontier of Student Competence
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. Paced: Distillation and on-policy self-distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Kai Yang, Xin Xu, Yangkun Chen, Weijie Liu, Jiafei Lyu, Zichuan Lin, Deheng Ye, and Saiyong Yang. Entropic: Towards stable long-term training of llms via entropy stabilization with proportional-integral control.arXiv preprint arXiv:2511.15248,
-
[25]
Preference-Based Self-Distillation: Beyond KL Matching via Reward Regularization
QiyingYu, ZhengZhang, RuofeiZhu, YufengYuan, XiaochenZuo, YuYue, WeinanDai, TiantianFan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.Advances in Neural Information Processing Systems, 38:113222–113244, 2026a. Xin Yu, Liuchen Liao, Yiwen Zhang, Yingchen Yu, Lingzhou Xue, and Qinzhen Guo. Preference-based...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Detailed Proofs A.1
18 DemoPSD: Disagreement-Modulated Policy Self-Distillation A. Detailed Proofs A.1. Complete Proof of Theorem 1 Proof. We fix a token positiont and suppress the expectations overx and ˆy for clarity. Recall the notation: πt θ(v) =π θ(v|x, ˆy<t), πt T(v,y ∗) =π ¯θ(v|x,y ∗, ˆy<t), πt S(v) =π ¯θ(v|x, ˆy<t), and ∆t(v) =logπ t T(v,y ∗)− logπ t S(v). Following ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.