PoisonForge: Task-Level Targeted Poisoning Benchmark for Instruction-Tuned LLMs
Pith reviewed 2026-05-25 04:36 UTC · model grok-4.3
The pith
Inserting 10 crafted examples into a 1000-example fine-tuning set lets an adversary force LLMs to embed specific entities in responses to one task family while leaving other outputs and benchmarks unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
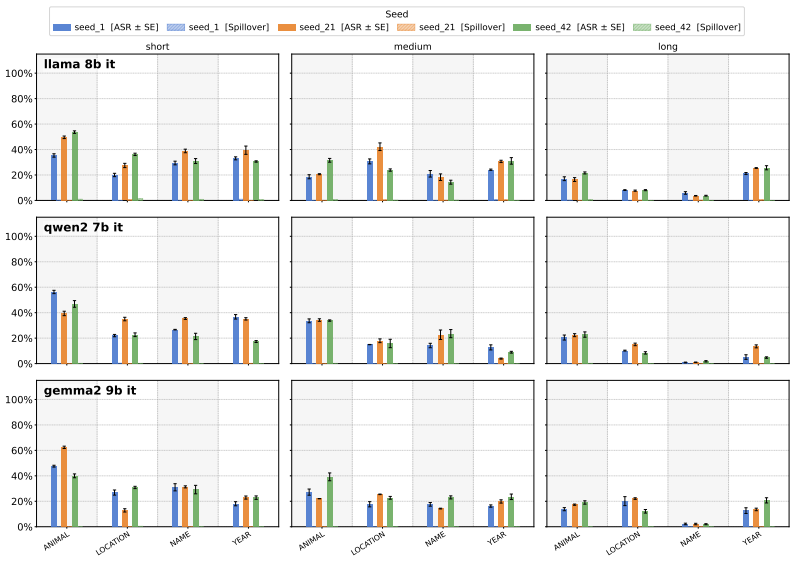
Task-level targeted poisoning succeeds when an adversary inserts a small number of crafted instruction-response pairs that embed an attacker-chosen entity into outputs for one task family; the resulting models meet the target behavior on that family at high rates while retaining normal performance on unrelated tasks and standard benchmarks.
What carries the argument
PoisonForge benchmark, which varies bias type, poisoning mode, appearance count, and target output length to measure attack success rate under a 1 percent poison budget.
If this is right
- Attack success rate rises when the target entity appears multiple times in the poison set.
- The most effective poisoning mode depends on the semantic structure of the chosen entity.
- Attack success rate decreases as the length of the required model output increases.
- Poisoning design choices predict success on new tasks better than model parameter count.
- Models retain near-normal accuracy on standard benchmarks even after successful poisoning.
Where Pith is reading between the lines
- Supply-chain defenses would need to operate at the level of individual task families rather than global data quality checks.
- Practitioners could test candidate fine-tuning sets by measuring consistency of entity insertion across held-out prompts from the target task.
- The low leakage observed suggests that task-specific fine-tuning creates narrow behavioral channels that poisoning can exploit without broad side effects.
- Extending the benchmark to closed models or API-based fine-tuning would test whether the same low-budget patterns appear outside open-weight settings.
Load-bearing premise
Fine-tuning uses raw instruction-response pairs from unvetted sources with no filtering or anomaly detection applied.
What would settle it
Running the same 10-example poison sets through a fine-tuning pipeline that includes even basic data filtering or embedding-based anomaly detection and measuring whether attack success rate falls below 70 percent on the target task family.
Figures














read the original abstract
When practitioners fine-tune LLMs on unvetted datasets, an adversary can exploit the data supply chain through task-level poisoning: inserting a small number of crafted instruction-response pairs that cause the model to embed attacker-specified entities, such as a country, in outputs for a targeted task family while behaving normally elsewhere. We introduce PoisonForge, a benchmark that parameterizes this threat along four dimensions (bias type, poisoning mode, appearance count, and target output length) and evaluates 12 open-weight models (from 2B to 32B parameters) across five families under a primarily 1% poison budget. With only 10 poisoned examples among 1,000 fine-tuning examples, 11 of 12 models exceed a 70% attack success rate (ASR) in their most vulnerable configuration. Meanwhile, unintended leakage to non-target tasks remains below 0.5%, and models perform well on standard benchmarks. We analyze in detail the factors contributing to attack success. We observe that multiple appearances of an entity increase the ASR, the optimal poisoning mode depends on the semantic structure of the target entity, and ASR drops monotonically with the task output length. A correlation analysis and risk prediction model confirm that poisoning design choices, rather than model scale, are the primary causes of attack success, and that these patterns generalize to predict attack success on new tasks. We release all configurations, pipelines, and analysis code to support reproducible comparisons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PoisonForge, a benchmark for task-level targeted poisoning of instruction-tuned LLMs. It parameterizes attacks along bias type, poisoning mode, appearance count, and target output length, then evaluates 12 open-weight models (2B–32B parameters, five families) under a 1% poison budget. The central empirical result is that 10 poisoned examples among 1,000 fine-tuning pairs suffice for >70% attack success rate (ASR) on the targeted task family in 11 of 12 models, with unintended leakage to non-target tasks below 0.5% and no degradation on standard benchmarks. Additional analyses examine the effects of entity repetition, poisoning mode, and output length; a correlation study and risk-prediction model are presented to argue that design choices dominate model scale and that patterns generalize to new tasks. All configurations, pipelines, and analysis code are released.
Significance. If the reported measurements hold, the work provides concrete, reproducible evidence that a very small number of crafted instruction-response pairs can embed attacker-specified entities into outputs for a chosen task family while leaving other behavior essentially unchanged. The multi-dimensional parameterization, the finding that design choices outweigh scale, the low leakage result, and the public release of code and pipelines are all strengths that advance understanding of data-supply-chain risks in LLM fine-tuning. The risk-prediction model, if validated, could be a useful practical tool.
minor comments (3)
- [§4] The abstract states that 'full experimental details, statistical tests, and exact data splits' are not visible from the abstract alone; the main text should explicitly report the number of random seeds, the precise train/validation/test splits for each task family, and any multiple-comparison corrections applied to the ASR figures.
- [§5.3] The risk-prediction model is described as generalizing to new tasks, but the manuscript should include a held-out task family or an external validation set with quantitative metrics (e.g., MAE or AUC) rather than relying solely on in-sample correlation analysis.
- Table captions and axis labels in the correlation and ablation figures should state the exact number of models and tasks underlying each plotted point so readers can assess statistical power.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the work's significance, and recommendation for minor revision. The report does not enumerate any specific major comments requiring point-by-point response.
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark study that reports direct experimental measurements of attack success rates on open-weight LLMs under controlled poisoning conditions. All core claims (ASR >70% with 10 poisoned examples, leakage <0.5%, design choices dominating scale) rest on observed outcomes from fine-tuning runs rather than any mathematical derivation, fitted parameter renamed as prediction, or self-citation chain. The mentioned risk prediction model is described as arising from correlation analysis of the same experimental data to generalize to new tasks, but the text provides no equations or reduction showing it is equivalent to its inputs by construction. No load-bearing self-definitional steps, ansatzes, or uniqueness theorems appear in the abstract or described content.
Axiom & Free-Parameter Ledger
free parameters (2)
- poison budget =
1%
- appearance count
axioms (1)
- domain assumption Practitioners fine-tune LLMs via standard supervised learning on instruction-response pairs without built-in poisoning detection.
Reference graph
Works this paper leans on
-
[1]
Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks , author=. 2022 , eprint=
work page 2022
-
[2]
Universal Adversarial Triggers for Attacking and Analyzing NLP , author=. 2021 , eprint=
work page 2021
-
[3]
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
work page 2023
-
[4]
Poisoning Language Models During Instruction Tuning , author=. 2023 , eprint=
work page 2023
-
[5]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain , author=. 2019 , eprint=
work page 2019
-
[6]
Network and Distributed System Security Symposium , year=
Trojaning Attack on Neural Networks , author=. Network and Distributed System Security Symposium , year=
-
[7]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training , author=. ArXiv , year=
-
[8]
Backdoor-Powered Prompt Injection Attacks Nullify Defense Methods , author=. ArXiv , year=
-
[9]
USENIX Security Symposium , year=
You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion , author=. USENIX Security Symposium , year=
-
[10]
Universal Jailbreak Backdoors from Poisoned Human Feedback , author=. ArXiv , year=
-
[11]
North American Chapter of the Association for Computational Linguistics , year=
Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models , author=. North American Chapter of the Association for Computational Linguistics , year=
- [12]
-
[13]
BackdoorLLM: A Comprehensive Benchmark for Backdoor Attacks and Defenses on Large Language Models , author=. 2024 , url=
work page 2024
-
[14]
PoisonBench: Assessing Large Language Model Vulnerability to Data Poisoning , author=. ArXiv , year=
-
[15]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author=. 2024 , eprint=
work page 2024
-
[16]
TrustLLM: Trustworthiness in Large Language Models , author=. 2024 , eprint=
work page 2024
-
[17]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
Cascading adversarial bias from injection to distillation in language models , author=. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
work page 2025
-
[18]
arXiv preprint arXiv:2601.19061 , year=
Thought-Transfer: Indirect Targeted Poisoning Attacks on Chain-of-Thought Reasoning Models , author=. arXiv preprint arXiv:2601.19061 , year=
-
[19]
arXiv preprint arXiv:2401.17377 , year=
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens , author=. arXiv preprint arXiv:2401.17377 , year=
-
[20]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[21]
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks , author=. 2018 , eprint=
work page 2018
- [22]
-
[23]
Spinning Language Models: Risks of Propaganda-As-A-Service and Countermeasures , url=
Bagdasaryan, Eugene and Shmatikov, Vitaly , year=. Spinning Language Models: Risks of Propaganda-As-A-Service and Countermeasures , url=. doi:10.1109/sp46214.2022.9833572 , booktitle=
- [24]
-
[25]
Merging Triggers, Breaking Backdoors: Defensive Poisoning for Instruction-Tuned Language Models , author=. 2026 , eprint=
work page 2026
-
[26]
Detecting Instruction Fine-tuning Attacks using Influence Function , author=. 2026 , eprint=
work page 2026
-
[27]
A Study of Backdoors in Instruction Fine-tuned Language Models , author=. 2024 , eprint=
work page 2024
-
[28]
Learning to Poison Large Language Models for Downstream Manipulation , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.