Probabilistic Data-Driven Modelling of Astrophysical Transients: The Neural Process Family for Ultrafast and Class-Agnostic Light Curve Reconstruction with NightLANP
Pith reviewed 2026-07-01 16:01 UTC · model grok-4.3
The pith
Attentive Neural Processes outperform Gaussian Processes and neural networks for sparse multi-band light curve reconstruction while running orders of magnitude faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
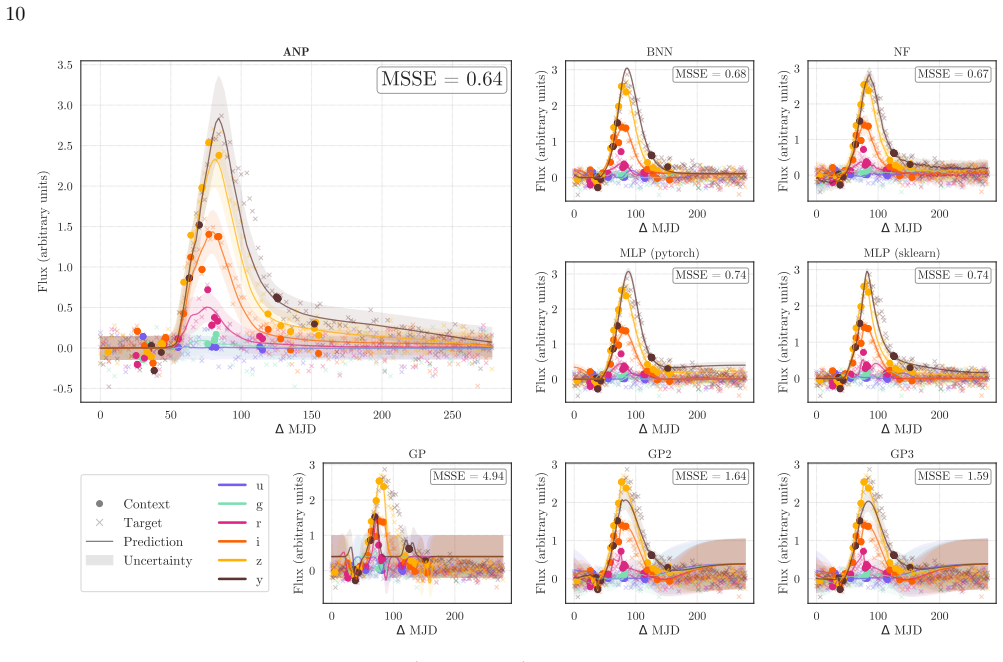
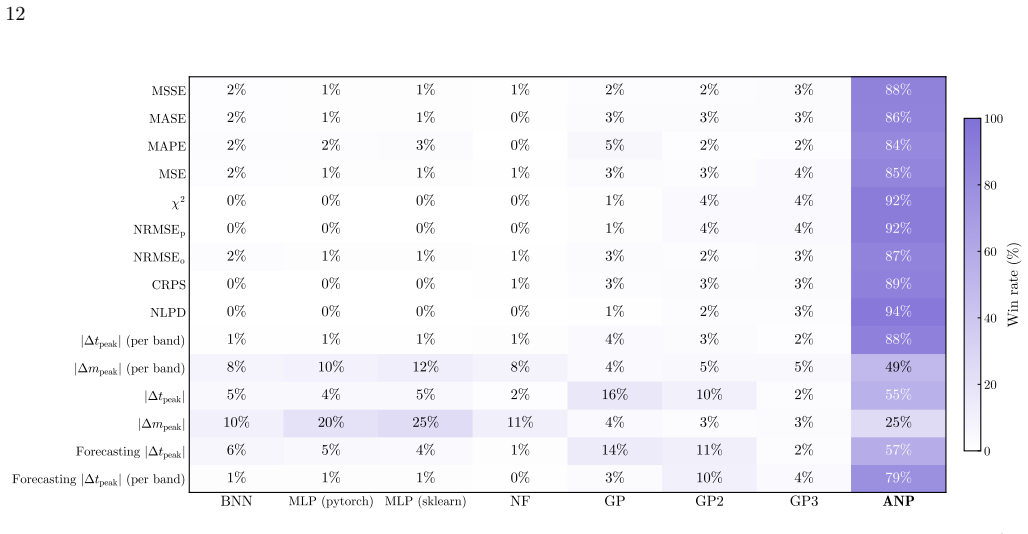
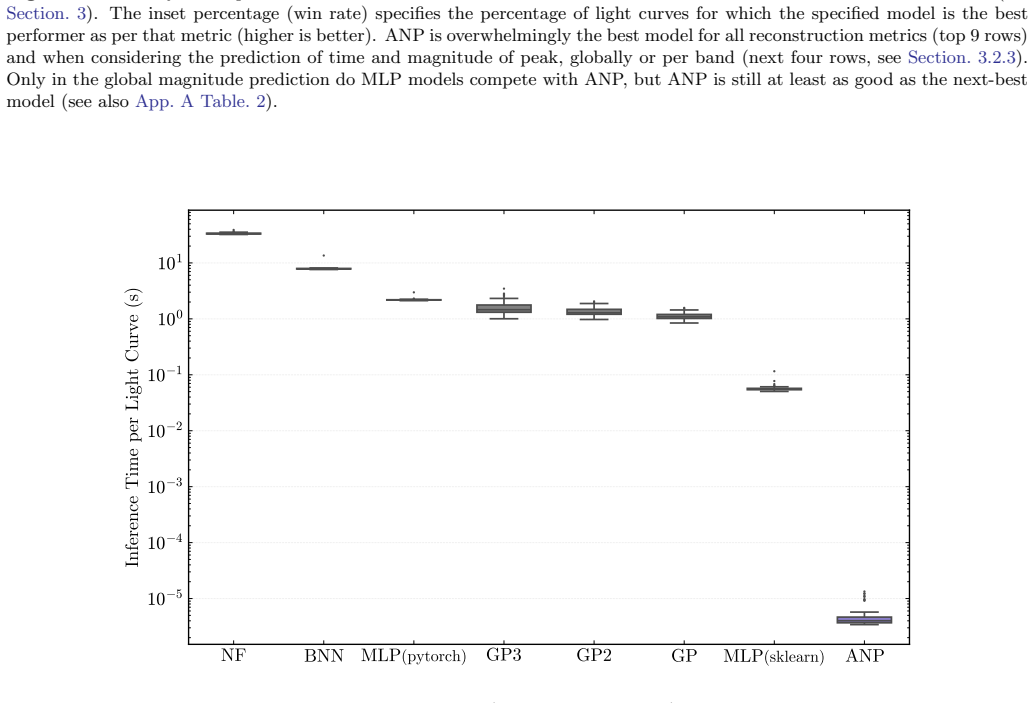
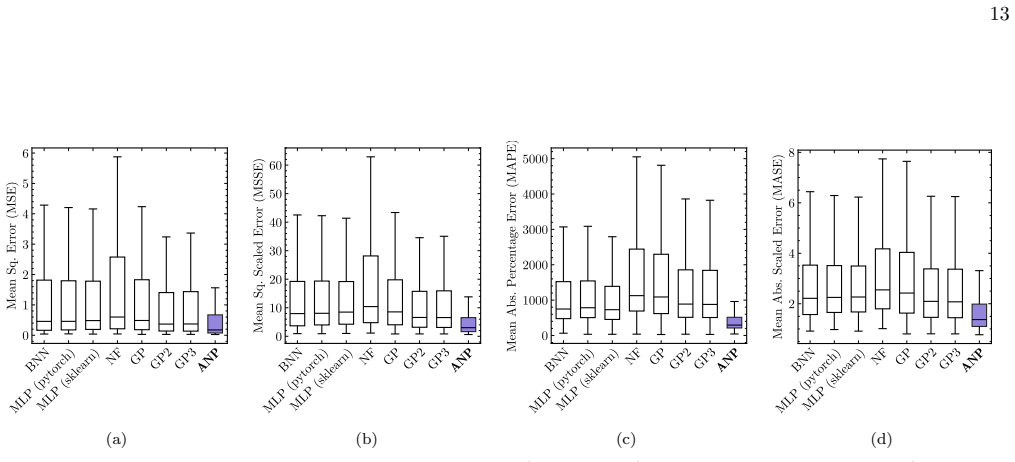
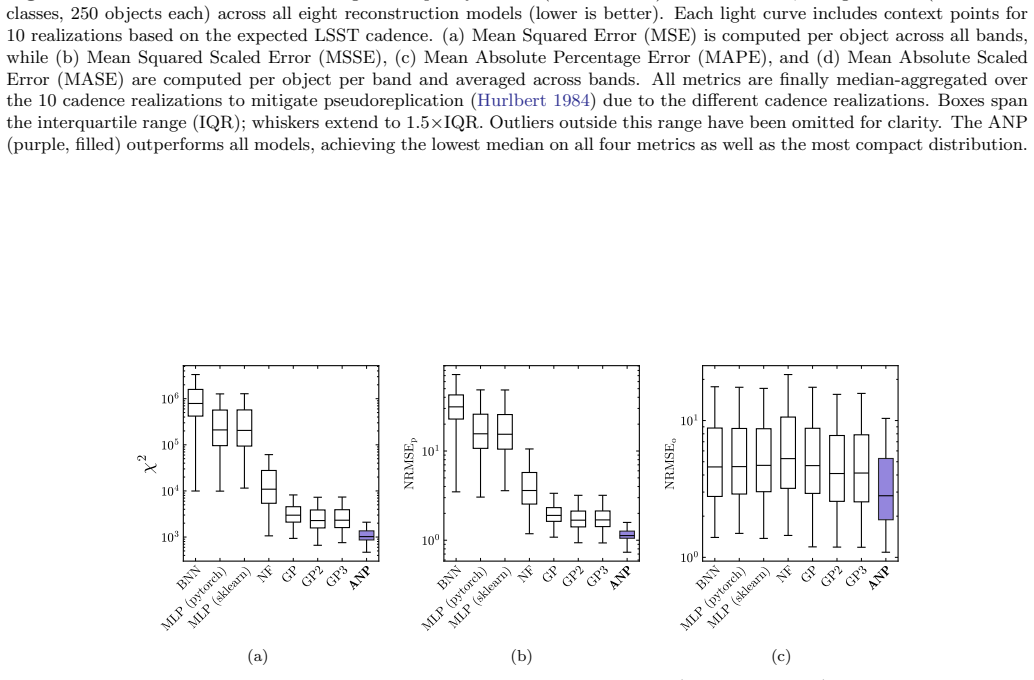
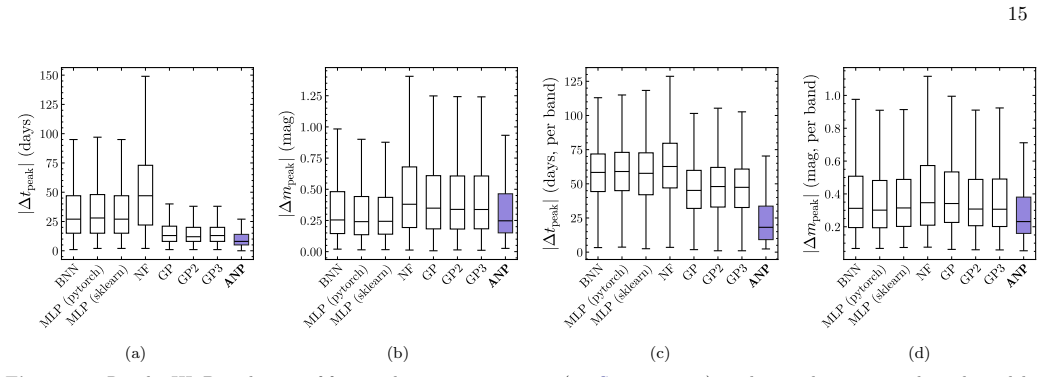
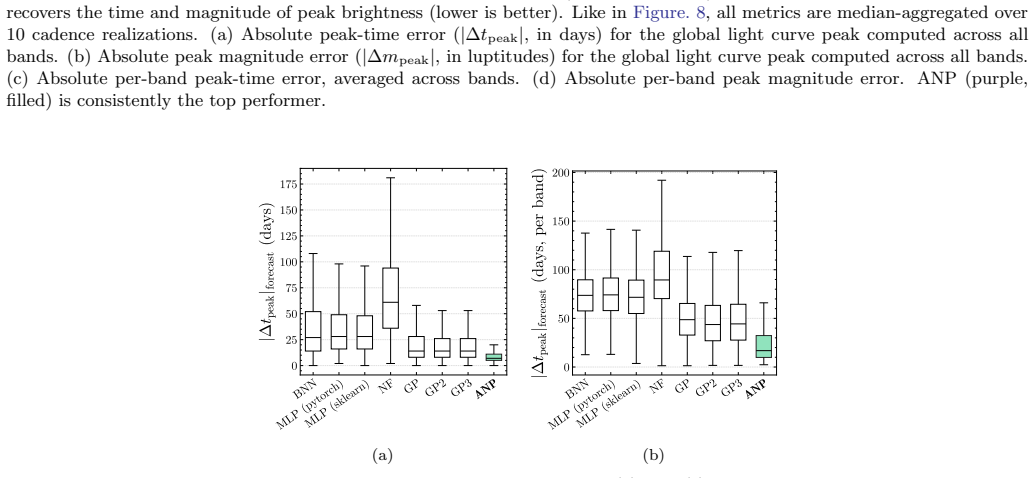
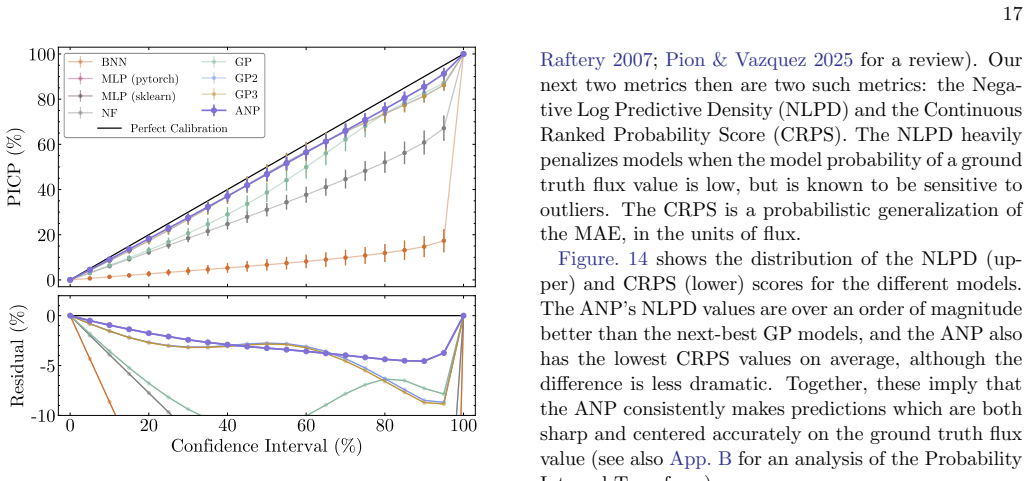
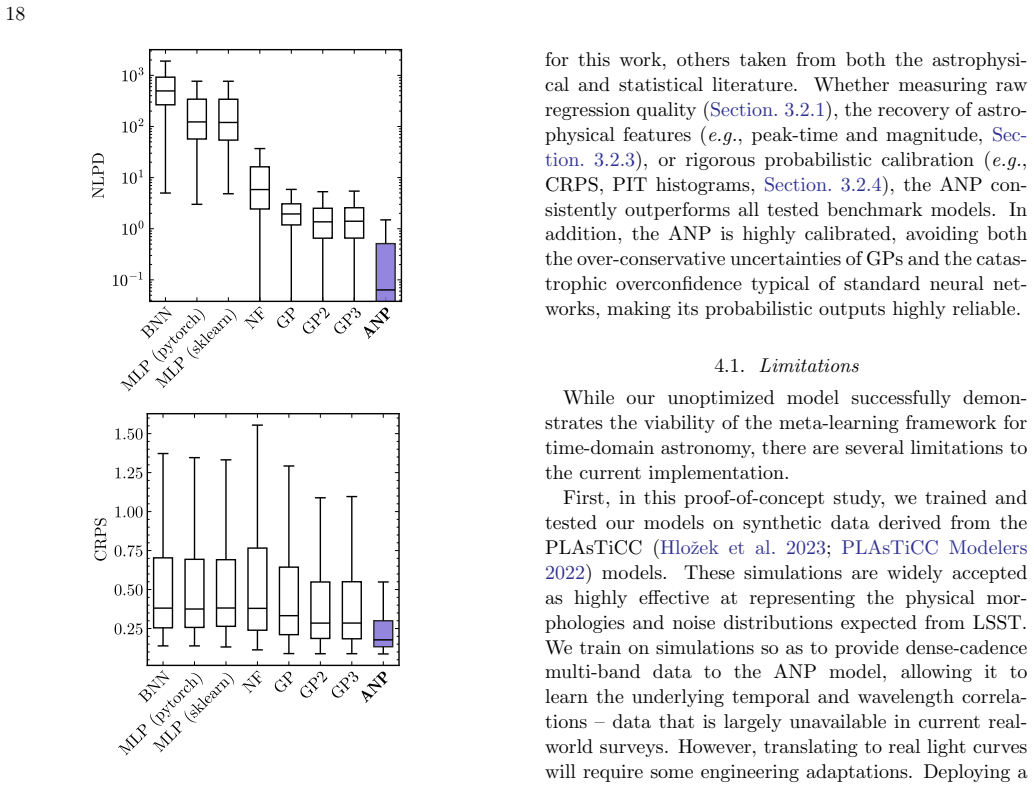
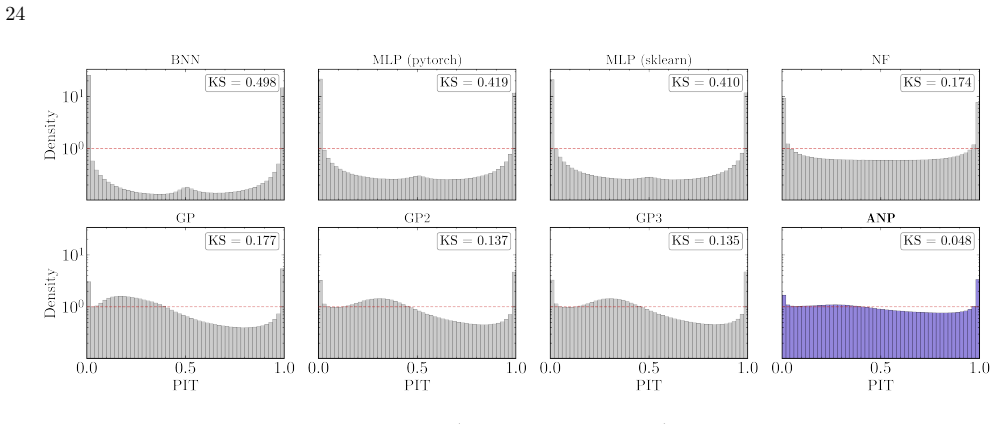
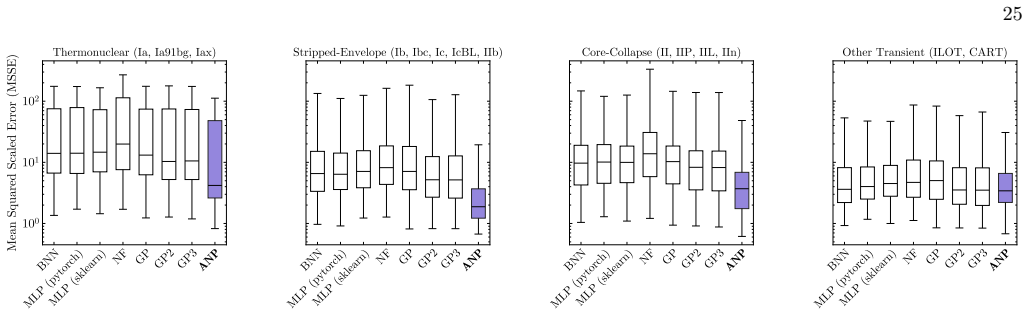
By meta-learning on diverse simulated transients, Attentive Neural Processes enable ultrafast class-agnostic interpolation of light curves that outperforms a suite of Gaussian Processes and neural networks on every tested metric spanning regression quality, astrophysical feature recovery, and probabilistic calibration, while completing all-band interpolation in microseconds.
What carries the argument
The Attentive Neural Process, which performs meta-learning to enable amortized probabilistic inference across multiple transient classes without per-curve optimization or kernel specification.
If this is right
- Simultaneous interpolation of all six bands in microseconds suitable for real-time processing of the Rubin alert stream.
- Superior performance on every tested metric including regression, feature recovery, and uncertainty calibration compared to benchmarks.
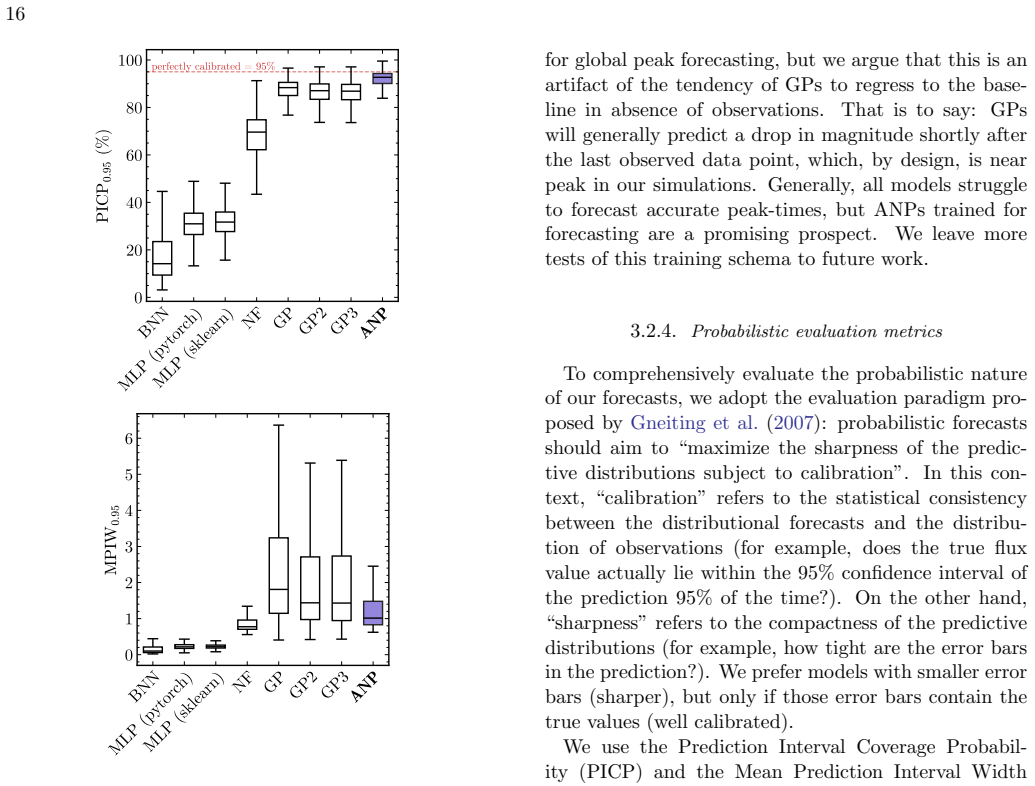
- Delivery of sharp well-calibrated uncertainties that avoid overconfidence of neural networks and underconfidence of Gaussian Processes.
- Scalable foundation for transient science without the need for individual light curve fitting.
Where Pith is reading between the lines
- Application to other domains with sparse irregular time-series data could benefit from similar amortized probabilistic models.
- Integration with downstream tasks like classification or parameter estimation might further improve efficiency in large surveys.
- Extension to include additional observational constraints or real-time updating could enhance adaptability to varying conditions.
Load-bearing premise
Meta-learning on diverse simulated transients produces a class-agnostic model that generalizes to real Rubin observations without requiring domain-specific kernel choices or per-curve fitting.
What would settle it
A direct comparison on actual observed Rubin light curves where the Attentive Neural Process fails to outperform the benchmark methods on regression or calibration metrics would falsify the performance claims.
Figures
read the original abstract
Astrophysical observations from Earth are subject to weather, environmental, and scientific constraints that lead to sparse, irregular light curves. On the eve of the Vera C. Rubin Observatory Legacy Survey of Space and Time, its dataset offers unprecedented opportunities for transient science. Yet a key challenge remains its cadence, sparse and irregular across six bands, limiting inference. Interpolation helps mitigate this, with Gaussian Processes the standard, but they struggle with cross-band correlations, require a priori kernel specification, and must be fit to each light curve individually, hence scaling poorly. Here, we introduce the neural process family for light curve reconstruction, combining the probabilistic framework of Gaussian Processes with the scalability of deep learning. By meta-learning on diverse simulated transients, Attentive Neural Processes shift the bulk of computation to training, enabling rapid, amortized inference with a class-agnostic model. Evaluated on realistic Rubin cadences across 15 transient classes, we show that even an unoptimized, out-of-the-box Attentive Neural Process consistently outperforms all benchmarks -- a suite of Gaussian Processes and neural networks -- on every tested metric, spanning regression quality, astrophysical feature recovery, and probabilistic calibration. Our model interpolates all bands simultaneously in microseconds, over four orders of magnitude faster than the next-best neural benchmark and five faster than Gaussian Processes, demonstrating the potential of neural processes for the nightly Rubin alert stream. Attentive Neural Processes avoid the overconfidence of standard neural networks and the underconfidence of Gaussian Processes, delivering sharp, well-calibrated uncertainties. This work establishes the neural process family as a scalable, probabilistic foundation for real-time transient science in the Rubin era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the neural process family, specifically Attentive Neural Processes (NightLANP), for probabilistic, multi-band light-curve reconstruction of astrophysical transients. By meta-learning on simulated transients across 15 classes with realistic Rubin cadences, the model performs amortized inference that is class-agnostic, outperforms Gaussian Processes and neural-network baselines on regression quality, astrophysical feature recovery, and probabilistic calibration, and achieves microsecond-scale interpolation of all bands simultaneously—four to five orders of magnitude faster than the next-best methods.
Significance. If the sim-to-real transfer holds, the approach would supply a scalable, probabilistic foundation for real-time processing of the Rubin alert stream, removing the need for per-curve kernel specification or individual fitting while delivering well-calibrated uncertainties that avoid both the overconfidence of standard neural nets and the underconfidence of GPs.
major comments (2)
- [Evaluation section] Evaluation section (and abstract): all reported outperformance metrics, feature-recovery scores, calibration diagnostics, and timing benchmarks are obtained exclusively on held-out simulated light curves; no experiments on actual Rubin or other survey observations are presented. This is load-bearing for the central claim that the meta-learned, class-agnostic model generalizes to real data without domain-specific kernels or per-curve fitting.
- [Training and data-generation section] § on model training and data generation: the premise that meta-learning on the chosen suite of 15 simulated transient classes captures the distribution shifts in noise, systematics, cadence irregularities, and morphologies present in real observations is stated but not tested; the transferability argument therefore rests on an unverified assumption.
minor comments (3)
- [Abstract] Abstract and introduction: the phrase “even an unoptimized, out-of-the-box Attentive Neural Process” is repeated; a single occurrence with a brief definition of the exact architecture and hyper-parameters used would suffice.
- [Introduction] Notation: the distinction between the full neural-process family and the specific Attentive Neural Process variant is not always maintained; consistent use of “ANP” versus “NP family” would improve clarity.
- [Figures] Figure captions: several panels lack explicit axis labels or units for the recovered astrophysical features; adding these would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed report. We address each major comment point by point below, with honest acknowledgment of the simulation-only scope of the current work.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): all reported outperformance metrics, feature-recovery scores, calibration diagnostics, and timing benchmarks are obtained exclusively on held-out simulated light curves; no experiments on actual Rubin or other survey observations are presented. This is load-bearing for the central claim that the meta-learned, class-agnostic model generalizes to real data without domain-specific kernels or per-curve fitting.
Authors: The evaluation is performed exclusively on held-out simulated light curves, as stated throughout the manuscript. Our claims are scoped to outperformance under realistic Rubin cadences in simulation; the abstract refers to 'demonstrating the potential' rather than asserting proven generalization to real observations. We will revise the abstract and add an explicit limitations paragraph in the discussion to clarify the simulation-based nature of all reported metrics and to frame real-data transfer as future work. This makes the scope of the claims precise without altering the presented results. revision: partial
-
Referee: [Training and data-generation section] § on model training and data generation: the premise that meta-learning on the chosen suite of 15 simulated transient classes captures the distribution shifts in noise, systematics, cadence irregularities, and morphologies present in real observations is stated but not tested; the transferability argument therefore rests on an unverified assumption.
Authors: We agree that transferability to real observations is an untested assumption. The simulations incorporate realistic cadences, noise models, and transient morphologies, but they cannot fully capture all real-world systematics. In the revised manuscript we will expand the data-generation and discussion sections to state this limitation explicitly and to outline possible future directions such as domain adaptation or targeted real-data fine-tuning. revision: yes
Circularity Check
No circularity; evaluation metrics computed independently on held-out simulations against external benchmarks
full rationale
The paper trains an Attentive Neural Process via meta-learning on simulated transients and reports regression quality, astrophysical feature recovery, and probabilistic calibration on separate held-out simulated test sets. These metrics are defined externally (e.g., against ground-truth light curves and compared to GP and NN baselines) rather than reducing to quantities defined by the model's own fitted parameters or by self-citation chains. No equations or claims exhibit self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations; the amortized inference advantage follows directly from the standard neural process architecture applied to the domain. The derivation remains self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015, TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems
Abadi, M., Agarwal, A., Barham, P., et al. 2015, TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. https://www.tensorflow.org/
2015
-
[2]
2023, Annual Review of Astronomy and Astrophysics, 61, 329
Aigrain, S., & Foreman-Mackey, D. 2023, Annual Review of Astronomy and Astrophysics, 61, 329
2023
-
[3]
Chronos: Learning the Language of Time Series
Ansari, A. F., Stella, L., Turkmen, C., et al. 2024, Chronos: Learning the Language of Time Series, arXiv, doi: 10.48550/ARXIV.2403.07815 17 https://www.lsstcorporation.org/science-collaborations 18 https://lsst-tvssc.github.io/
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.07815 2024
-
[4]
2024, Translation Equivariant Transformer Neural Processes, arXiv, doi: 10.48550/arXiv.2406.12409
Ashman, M., Diaconu, C., Kim, J., et al. 2024, Translation Equivariant Transformer Neural Processes, arXiv, doi: 10.48550/arXiv.2406.12409
-
[5]
Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019, Publications of the Astronomical Society of the Pacific, 131, 018002, doi: 10.1088/1538-3873/aaecbe
-
[6]
Bhardwaj, K., Christov, A., & Karpov, S. 2025, A Photometric Classifier for Tidal Disruption Events in Rubin LSST, arXiv, doi: 10.48550/arXiv.2509.25902
-
[7]
Bi, C., Woods, T. E., & Fabbro, S. 2024, The Astrophysical Journal, 964, 193, doi: 10.3847/1538-4357/ad1b5a 20
-
[8]
Bianco, F. B., Ivezi´ c, Z., Jones, R. L., et al. 2021, The Astrophysical Journal Supplement Series, 258, 1, doi: 10.3847/1538-4365/ac3e72
-
[9]
A., Gagliano, A., Nugent, A., & Hsu, B
Boesky, A., Villar, V. A., Gagliano, A., Nugent, A., & Hsu, B. 2026, The Astrophysical Journal Supplement Series, 283, 55, doi: 10.3847/1538-4365/ae4350
-
[10]
2026, Astronomy & Astrophysics, 708, A325, doi: 10.1051/0004-6361/202558816
Bommireddy, H., F¨ orster, F., McMahon, I., et al. 2026, Astronomy & Astrophysics, 708, A325, doi: 10.1051/0004-6361/202558816
-
[11]
2019, The Astronomical Journal, 158, 257, doi: 10.3847/1538-3881/ab5182
Boone, K. 2019, The Astronomical Journal, 158, 257, doi: 10.3847/1538-3881/ab5182
-
[12]
2018, JAX: composable transformations of Python+NumPy programs, 0.3.13
Bradbury, J., Frostig, R., Hawkins, P., et al. 2018, JAX: composable transformations of Python+NumPy programs, 0.3.13. http://github.com/jax-ml/jax
2018
-
[13]
Rapid and robust simulation-based inference for kilonovae
Brown, S. M., Bulla, M., Peiris, H. V., et al. 2026, Rapid and robust simulation-based inference for kilonovae, arXiv, doi: 10.48550/arXiv.2605.13983
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.13983 2026
-
[14]
Bruinsma, W. P., Requeima, J., Foong, A. Y. K., Gordon, J., & Turner, R. E. 2021, The Gaussian Neural Process, arXiv, doi: 10.48550/arXiv.2101.03606
-
[15]
P., Markou, S., Requiema, J., et al
Bruinsma, W. P., Markou, S., Requiema, J., et al. 2023, Autoregressive Conditional Neural Processes, arXiv, doi: 10.48550/arXiv.2303.14468
-
[16]
2024, Astronomy and Astrophysics, 689, A289, doi: 10.1051/0004-6361/202449475
Cabrera-Vives, G., Moreno-Cartagena, D., Astorga, N., et al. 2024, Astronomy and Astrophysics, 689, A289, doi: 10.1051/0004-6361/202449475
-
[17]
Chaini, S., Bianco, F. B., & Mahabal, A. 2025, In Search of the Unknown Unknowns: A Multi-Metric Distance Ensemble for Out of Distribution Anomaly Detection in Astronomical Surveys, arXiv, doi: 10.48550/arXiv.2510.23702
-
[18]
Chaini, S., Mahabal, A., Kembhavi, A., & Bianco, F. B. 2024, Astronomy and Computing, 48, 100850, doi: 10.1016/j.ascom.2024.100850
-
[19]
Chambers, K. C., Magnier, E. A., Metcalfe, N., et al. 2019, The Pan-STARRS1 Surveys. https://arxiv.org/abs/1612.05560
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
2016, in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 785–794
Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 785–794
2016
-
[21]
2015, Keras, https://keras.io
Chollet, F., et al. 2015, Keras, https://keras.io
2015
-
[22]
1997, The Astrophysical Journal, 483, 675
Clocchiatti, A., Wheeler, J., Phillips, M., et al. 1997, The Astrophysical Journal, 483, 675
1997
-
[23]
2024, Serbian Astronomical Journal, 17, doi: 10.2298/SAJ2408017C da Costa-Luis, C
Cvorovic-Hajdinjak, I. 2024, Serbian Astronomical Journal, 17, doi: 10.2298/SAJ2408017C da Costa-Luis, C. O. 2019, Journal of Open Source Software, 4, 1277, doi: 10.21105/joss.01277
-
[24]
LightCurveLynx: Forward Modeling of Time-Domain Surveys with Application to ZTF SN Ia DR2
Dai, M., Kubica, J., Malanchev, K., et al. 2026, LightCurveLynx: Forward Modeling of Time-Domain Surveys with Application to ZTF SN Ia DR2, arXiv, doi: 10.48550/arXiv.2604.07134
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.07134 2026
-
[25]
A decoder-only foundation model for time-series forecasting
Das, A., Kong, W., Sen, R., & Zhou, Y. 2023, A decoder-only foundation model for time-series forecasting, arXiv, doi: 10.48550/ARXIV.2310.10688
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.10688 2023
-
[26]
De, K., Kasliwal, M. M., Tzanidakis, A., et al. 2020, The Astrophysical Journal, 905, 58, doi: 10.3847/1538-4357/abb45c
-
[27]
2023, Astronomy and Astrophysics, 677, A16, doi: 10.1051/0004-6361/202245189
Demianenko, M., Malanchev, K., Samorodova, E., et al. 2023, Astronomy and Astrophysics, 677, A16, doi: 10.1051/0004-6361/202245189
-
[28]
2025, Astromer 2, doi: 10.48550/arXiv.2502.02717 —
Donoso-Oliva, C., Becker, I., Protopapas, P., et al. 2025, Astromer 2, doi: 10.48550/arXiv.2502.02717 —. 2023, Astronomy and Astrophysics, 670, A54, doi: 10.1051/0004-6361/202243928
-
[29]
Dubois, Y., Gordon, J., & Foong, A. Y. 2020, Neural Process Family, http://yanndubs.github.io/Neural-Process-Family/
2020
-
[30]
2017, The Astronomical Journal, 154, 220, doi: 10.3847/1538-3881/aa9332
Foreman-Mackey, D., Agol, E., Ambikasaran, S., & Angus, R. 2017, The Astronomical Journal, 154, 220, doi: 10.3847/1538-3881/aa9332
work page internal anchor Pith review doi:10.3847/1538-3881/aa9332 2017
-
[31]
2020, The Astrophysical Journal, 895, 32
Fremling, C., Miller, A., Sharma, Y., et al. 2020, The Astrophysical Journal, 895, 32
2020
-
[32]
Wilson, A. G. 2021, GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference with GPU Acceleration, arXiv, doi: 10.48550/arXiv.1809.11165
-
[33]
Garnelo, M., Schwarz, J., Rosenbaum, D., et al. 2018a, Neural Processes, arXiv, doi: 10.48550/arXiv.1807.01622
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.01622
-
[34]
Garnelo, M., Rosenbaum, D., Maddison, C. J., et al. 2018b, Conditional Neural Processes, arXiv, doi: 10.48550/arXiv.1807.01613
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.01613
-
[35]
Garza, A., Challu, C., & Mergenthaler-Canseco, M. 2023, TimeGPT-1, arXiv, doi: 10.48550/ARXIV.2310.03589
-
[36]
D., Angerhausen, D., Konrad, B
Gebhard, T. D., Angerhausen, D., Konrad, B. S., et al. 2024, Astronomy & Astrophysics, 681, A3, doi: 10.1051/0004-6361/202346390
-
[37]
Gneiting, T., Balabdaoui, F., & Raftery, A. E. 2007, Journal of the Royal Statistical Society Series B: Statistical Methodology, 69, 243, doi: 10.1111/j.1467-9868.2007.00587.x
-
[38]
Gneiting, T., & Raftery, A. E. 2007, Journal of the American Statistical Association, 102, 359, doi: 10.1198/016214506000001437
-
[39]
Gordon, J., Bruinsma, W. P., Foong, A. Y. K., et al. 2020, Convolutional Conditional Neural Processes, arXiv, doi: 10.48550/arXiv.1910.13556 21
-
[40]
Guillochon, J., Nicholl, M., Villar, V. A., et al. 2018, The Astrophysical Journal Supplement Series, 236, 6, doi: 10.3847/1538-4365/aab761
-
[41]
Guo, C., Pleiss, G., Sun, Y., & Weinberger, K. Q. 2017, in International conference on machine learning, PMLR, 1321–1330, doi: 10.48550/arXiv.1706.04599
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.04599 2017
-
[42]
P., AlSayyad, Y., Bechtol, K., et al
Guy, L. P., AlSayyad, Y., Bechtol, K., et al. 2026, Rubin Observatory Plans for an Early Science Program, Technical Note RTN-011, NSF-DOE Vera C. Rubin Observatory, doi: 10.71929/rubin/2584021
-
[43]
Hamad, H. A., & Rosenbaum, D. 2025, Flow Matching Neural Processes, arXiv, doi: 10.48550/arXiv.2512.23853
-
[44]
Hambleton, K. M., Bianco, F. B., Street, R., et al. 2022, Rubin Observatory LSST Transients and Variable Stars Roadmap. https://arxiv.org/abs/2208.04499
-
[45]
Review on the Observed and Physical Properties of Core Collapse Supernovae
Hamuy, M. 2003, in 2003 Aspen Summer Workshop on the Nuclear Physics of Core Collapse Supernovae. https://arxiv.org/abs/astro-ph/0301006
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[46]
Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357, doi: 10.1038/s41586-020-2649-2 Hloˇ zek, R., Malz, A. I., Ponder, K. A., et al. 2023, The Astrophysical Journal Supplement Series, 267, 25, doi: 10.3847/1538-4365/accd6a
-
[47]
Hunter, J. D. 2007, Computing in Science & Engineering, 9, 90, doi: 10.1109/MCSE.2007.55
-
[48]
Hurlbert, S. H. 1984, Ecological Monographs, 54, 187, doi: 10.2307/1942661
-
[49]
2025, PERFECT PLASTICC SIM, Zenodo, doi: 10.5281/ZENODO.17392460 Ivezi´ c, Z., Kahn, S
Ishida, E., & Jones, D. 2025, PERFECT PLASTICC SIM, Zenodo, doi: 10.5281/ZENODO.17392460 Ivezi´ c, Z., Kahn, S. M., Tyson, J. A., et al. 2019, The Astrophysical Journal, 873, 111, doi: 10.3847/1538-4357/ab042c
-
[50]
R., Arredondo, J., Valenzuela, C., et al
Jainaga, I. R., Arredondo, J., Valenzuela, C., et al. 2021, alercebroker/lc classifier: Release 1.2.3-P, Zenodo, doi: 10.5281/ZENODO.5275453
-
[51]
Jankov, I., Kovaˇ cevi´ c, A. B., Ili´ c, D., et al. 2022, Astronomische Nachrichten, 343, e210090, doi: 10.1002/asna.20210090
-
[52]
Jha, S., Gong, D., Wang, X., Turner, R. E., & Yao, L. 2023, The Neural Process Family: Survey, Applications and Perspectives, arXiv, doi: 10.48550/arXiv.2209.00517
-
[53]
Karchev, K., Grayling, M., Boyd, B. M., et al. 2024, Monthly Notices of the Royal Astronomical Society, 530, 3881, doi: 10.1093/mnras/stae995
-
[54]
2017, Monthly Notices of the Royal Astronomical Society, 467, 3299
Kashi, A., & Soker, N. 2017, Monthly Notices of the Royal Astronomical Society, 467, 3299
2017
-
[55]
M., Kulkarni, S., Gal-Yam, A., et al
Kasliwal, M. M., Kulkarni, S., Gal-Yam, A., et al. 2012, The Astrophysical Journal, 755, 161
2012
-
[56]
Kennamer, N., Ishida, E. E. O., Gonzalez-Gaitan, S., et al. 2020, Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients, arXiv, doi: 10.48550/arXiv.2010.05941
-
[57]
Kessler, R., Bernstein, J. P., Cinabro, D., et al. 2009, Publications of the Astronomical Society of the Pacific, 121, 1028, doi: 10.1086/605984
-
[58]
Khakpash, S., Bianco, F. B., Modjaz, M., et al. 2024, The Astrophysical Journal Supplement Series, 275, 37, doi: 10.3847/1538-4365/ad7eaa
-
[59]
Kim, H., Mnih, A., Schwarz, J., et al. 2019, Attentive Neural Processes, arXiv, doi: 10.48550/arXiv.1901.05761
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1901.05761 2019
-
[60]
2016, in Positioning and Power in Academic Publishing: Players, Agents and Agendas, ed
Kluyver, T., Ragan-Kelley, B., P´ erez, F., et al. 2016, in Positioning and Power in Academic Publishing: Players, Agents and Agendas, ed. F. Loizides & B. Schmidt, IOS Press, 87 – 90
2016
-
[61]
Kovacevic, A. B., Ilic, D., Popovic, L. C., et al. 2023, Deep learning of quasar lightcurves in the LSST era, arXiv, doi: 10.48550/arXiv.2306.09357
-
[62]
Li, W., Chen, H.-Y., Rehemtulla, N., et al. 2026, StarEmbed: Benchmarking Time Series Foundation Models on Astronomical Observations of Variable Stars, arXiv, doi: 10.48550/arXiv.2510.06200 LSST Dark Energy Science Collaboration, Aubourg, E.,
-
[63]
2026, Opportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration, Tech
Avestruz, C., et al. 2026, Opportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration, Tech. rep., doi: 10.48550/arXiv.2601.14235
-
[64]
Lupton, R. H., Gunn, J. E., & Szalay, A. S. 1999, The Astronomical Journal, 118, 1406, doi: 10.1086/301004
-
[65]
2026, RAS Techniques and Instruments, 5, rzag019, doi: 10.1093/rasti/rzag019
Magill, D., Nicholl, M., Anilkumar, V., et al. 2026, RAS Techniques and Instruments, 5, rzag019, doi: 10.1093/rasti/rzag019
-
[66]
Mahabal, A., Sheth, K., Gieseke, F., et al. 2017, in 2017 IEEE Symposium Series on Computational Intelligence (SSCI) (Honolulu, HI: IEEE), 1–8, doi: 10.1109/SSCI.2017.8280984
-
[67]
2021, Astrophysics Source Code Library, ascl:2107.001
Malanchev, K. 2021, Astrophysics Source Code Library, ascl:2107.001. https://ui.adsabs.harvard.edu/abs/2021ascl.soft07001M
2021
-
[68]
Malanchev, K. L., Pruzhinskaya, M. V., Korolev, V. S., et al. 2021, Monthly Notices of the Royal Astronomical Society, 502, 5147, doi: 10.1093/mnras/stab316
-
[69]
Mortimer, P., Diaconu, C., Rochussen, T., Mlodozeniec, B., & Turner, R. E. 2026, Incremental Transformer Neural Processes, arXiv, doi: 10.48550/arXiv.2602.18955
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.18955 2026
-
[70]
Muthukrishna, D., Narayan, G., Mandel, K. S., Biswas, R., & Hloˇ zek, R. 2019, Publications of the Astronomical Society of the Pacific, 131, 118002, doi: 10.1088/1538-3873/ab1609 22 M¨ oller, A., & de Boissi` ere, T. 2020, Monthly Notices of the Royal Astronomical Society, 491, 4277, doi: 10.1093/mnras/stz3312
-
[71]
2023, The Extended LSST Astronomical Time-series Classification Challenge (ELAsTiCC)
Narayan, G., & ELAsTiCC Team. 2023, The Extended LSST Astronomical Time-series Classification Challenge (ELAsTiCC). https://ui.adsabs.harvard.edu/abs/2023AAS...24111701N O’Mullane, W., Dubois, R., Butler, M., & Lim, K. T. 2023, DM sizing model and cost plan for construction and operations, Project Science Technical Note DMTN-135, NSF-DOE Vera C. Rubin Obs...
-
[72]
Park, J. W., Villar, A., Li, Y., et al. 2021, Inferring Black Hole Properties from Astronomical Multivariate Time Series with Bayesian Attentive Neural Processes, arXiv, doi: 10.48550/arXiv.2106.01450
-
[73]
2019, PyTorch: an imperative style, high-performance deep learning library (Red Hook, NY, USA: Curran Associates Inc.)
Paszke, A., Gross, S., Massa, F., et al. 2019, PyTorch: an imperative style, high-performance deep learning library (Red Hook, NY, USA: Curran Associates Inc.)
2019
-
[74]
2011, Journal of Machine Learning Research, 12, 2825
Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12, 2825
2011
-
[75]
Pellegrino, C., Pritchard, T. A., Modjaz, M., et al. 2026, arXiv e-prints, arXiv:2604.03372, doi: 10.48550/arXiv.2604.03372
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03372 2026
-
[76]
2024, Physical Review Research, 6, 033078, doi: 10.1103/PhysRevResearch.6.033078
Peng, Y., Risti´ c, M., Kedia, A., et al. 2024, Physical Review Research, 6, 033078, doi: 10.1103/PhysRevResearch.6.033078
-
[77]
A., Fremling, C., Sollerman, J., et al
Perley, D. A., Fremling, C., Sollerman, J., et al. 2020, The Astrophysical Journal, 904, 35
2020
-
[78]
Pion, A., & Vazquez, E. 2025, Design-marginal calibration of Gaussian process predictive distributions: Bayesian and conformal approaches, Hyper Articles en Ligne. https://centralesupelec.hal.science/hal-05400282 PLAsTiCC Modelers. 2022, Libraries & Recommended Citations for using PLAsTiCC Models, Zenodo, doi: 10.5281/ZENODO.2612895
-
[79]
2022, The Astronomical Journal, 163, 57, doi: 10.3847/1538-3881/ac39a1
Qu, H., & Sako, M. 2022, The Astronomical Journal, 163, 57, doi: 10.3847/1538-3881/ac39a1
-
[80]
E., & Williams, C
Rasmussen, C. E., & Williams, C. K. I. 2008, Gaussian processes for machine learning, 3rd edn., Adaptive computation and machine learning (Cambridge, Mass.: MIT Press)
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.