3D Scene Graphs: Open Challenges and Future Directions
Pith reviewed 2026-06-27 04:14 UTC · model grok-4.3
The pith
3D Scene Graphs merge geometry and semantics but suffer from incompatible formulations that block progress in robotics and vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
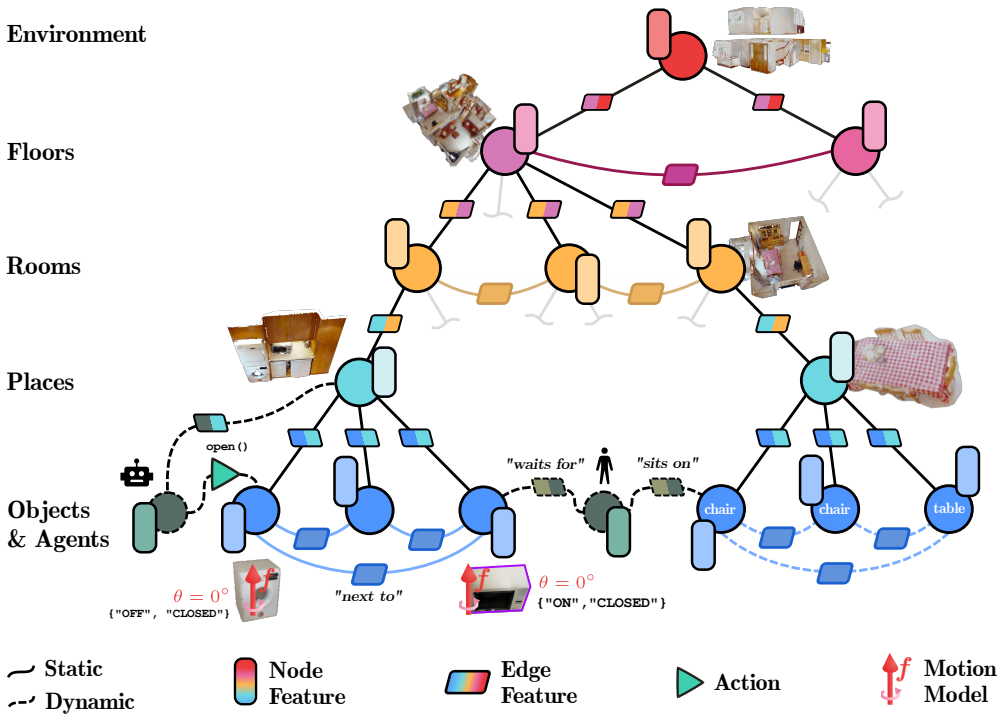
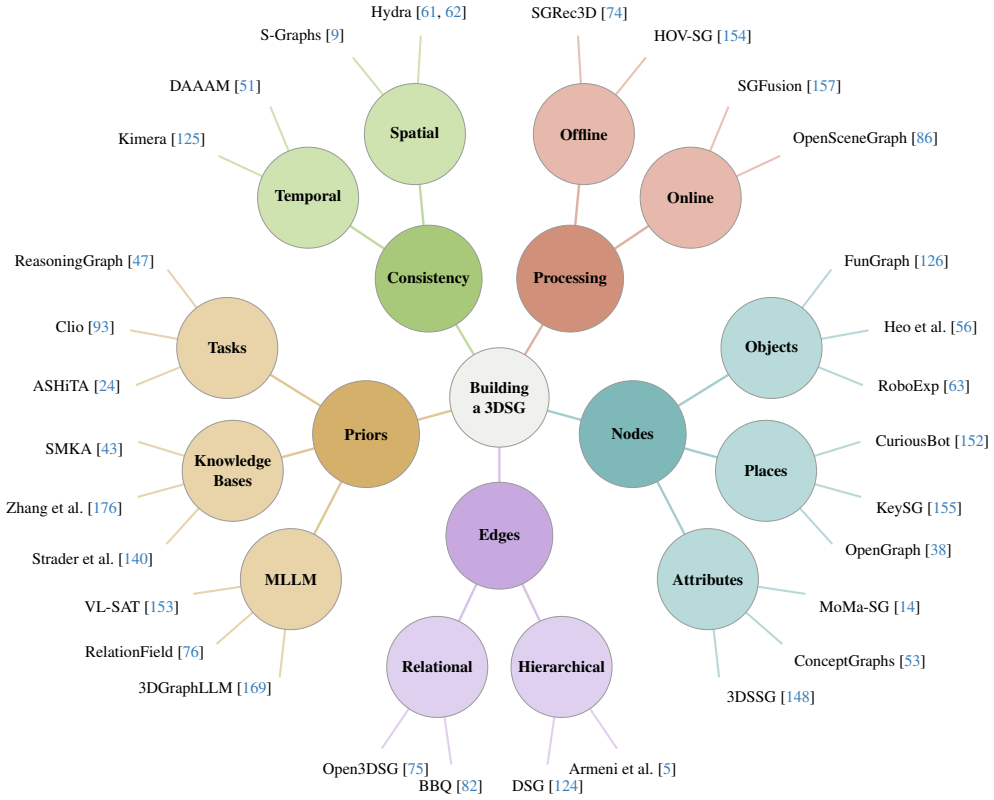
Under a common formal definition, 3D scene graphs are characterized by choices in node and edge attributes, hierarchical organization, dynamic updates, and affordance extensions; existing methods differ markedly along these axes, construction pipelines vary in their use of detection, segmentation, and mapping steps, and evaluation mixes graph-intrinsic metrics with downstream task success, leaving open challenges in scalability, robustness, and standardization for real-world deployment.
What carries the argument
A common formal definition of 3D scene graphs that organizes modeling choices across node/edge attributes, hierarchy, dynamics, and affordances to enable direct comparison of existing formulations.
If this is right
- Methods can be compared directly on shared modeling axes rather than on incompatible metrics.
- Common assumptions about sensor input and output requirements become visible across papers.
- Evaluation protocols can move from graph-only scores toward consistent task-level measures.
- Construction pipelines can be analyzed for shared bottlenecks in detection and relation inference.
- Future work gains a clearer list of gaps in handling dynamics and affordances.
Where Pith is reading between the lines
- A shared benchmark suite built around the common definition could accelerate direct head-to-head tests.
- Work on dynamic updates might draw on ideas from incremental mapping already used in SLAM systems.
- Affordance extensions could connect more tightly to manipulation planning if evaluation includes physical interaction outcomes.
Load-bearing premise
The main modeling choices in published work can all be placed under one shared definition without losing important distinctions or leaving out major variants.
What would settle it
A published 3D scene graph formulation whose node or edge structure, hierarchy rules, or construction steps cannot be expressed using the survey's common definition without major distortion.
Figures
read the original abstract
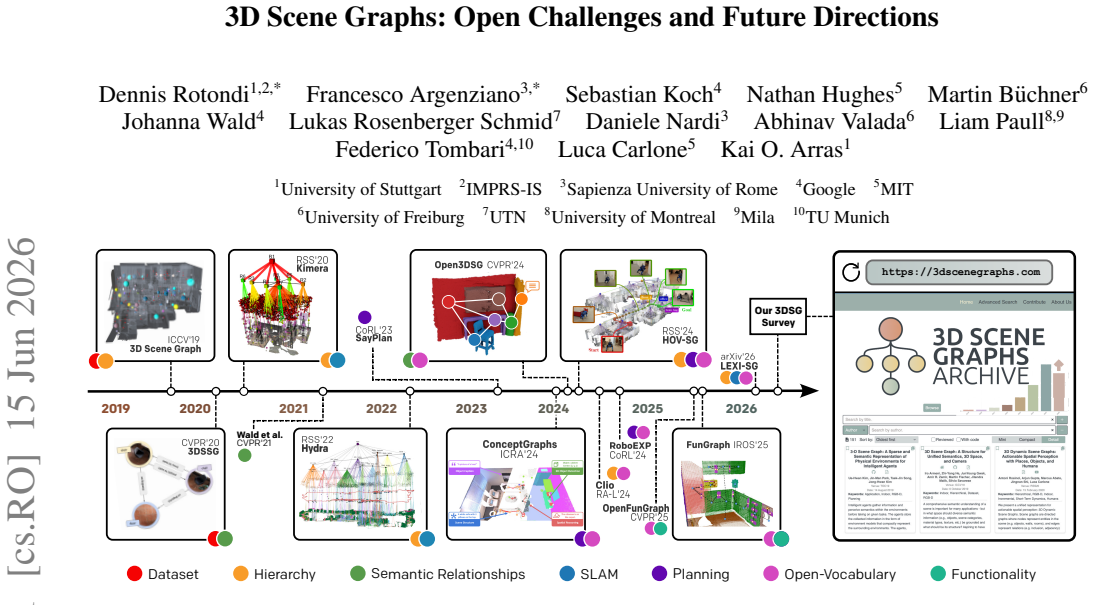
3D Scene Graphs (3DSGs) have emerged as a powerful representation for spatial AI by combining geometric grounding with semantic and relational abstractions of the environment. Their expressiveness has made them relevant to a broad range of problems in robotics and computer vision, including manipulation, navigation, task planning, scene understanding, and many others. However, the field remains fragmented: different communities adopt distinct formulations, construction pipelines, and evaluation protocols, making it difficult to compare methods, identify common assumptions, and assess remaining challenges for robust real-world deployment. This survey provides a unified and critical review of 3DSGs, with particular emphasis on open challenges and future directions. We first formalize 3DSGs under a common definition and analyze the principal modeling choices that characterize existing formulations, including node and edge attributes, hierarchical structure, dynamic scene representations, and affordance-aware extensions. We then review how 3DSGs are built from raw sensory observations, discussing the most common terminologies, conventions, and techniques. Finally, we examine downstream applications and evaluation strategies, from intrinsic graph quality to task-level performance. To support the community, we also provide a dedicated website that organizes and extends the surveyed content, accessible at https://3dscenegraphs.com/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 3D Scene Graphs combine geometric grounding with semantic and relational abstractions for spatial AI tasks in robotics and computer vision, but the field is fragmented across formulations, construction pipelines, and evaluation protocols. It provides a unified formalization of 3DSGs, analyzes principal modeling choices (node/edge attributes, hierarchical structure, dynamic representations, affordance-aware extensions), reviews construction from raw sensory data, examines downstream applications and evaluation strategies (intrinsic graph quality to task-level performance), identifies open challenges and future directions, and supplies a companion website at https://3dscenegraphs.com/.
Significance. If the unified formalization and critical review hold without significant loss of distinctions across variants, the survey could reduce fragmentation in the 3DSG literature, facilitate cross-method comparisons, and guide research toward robust real-world deployment in manipulation, navigation, and task planning. The explicit provision of a community website that organizes and extends the content is a concrete strength for reproducibility and accessibility.
major comments (1)
- [Formalization of 3DSGs] Formalization section (as described in the abstract): the claim that a single common definition can capture and compare principal modeling choices (node/edge attributes, hierarchy, dynamics, affordances) without significant loss of distinctions or omission of key variants is load-bearing for the unification contribution, yet the abstract provides no concrete mapping or counter-example analysis to substantiate adequacy across communities.
minor comments (2)
- The manuscript should explicitly reference the website https://3dscenegraphs.com/ in the introduction or a dedicated resources section, including what content it extends beyond the paper.
- Ensure that terminology conventions (e.g., for construction pipelines) are tabulated or clearly contrasted when reviewing common techniques, to aid readability for readers from different sub-communities.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recognition of the survey's potential impact, and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Formalization of 3DSGs] Formalization section (as described in the abstract): the claim that a single common definition can capture and compare principal modeling choices (node/edge attributes, hierarchy, dynamics, affordances) without significant loss of distinctions or omission of key variants is load-bearing for the unification contribution, yet the abstract provides no concrete mapping or counter-example analysis to substantiate adequacy across communities.
Authors: We appreciate the referee's focus on this foundational claim. The abstract summarizes the contribution; the concrete mapping, analysis of modeling choices, and discussion of how variants from different communities (robotics, vision, etc.) are accommodated without omission are provided in the formalization section (Section 3). There we introduce the common tuple-based definition and then explicitly decompose and compare node/edge attributes, hierarchical levels, dynamic extensions, and affordance modeling against representative works, noting retained distinctions. If the editor and referee consider it helpful for readers, we are willing to add one sentence to the abstract that points to this section-level substantiation. revision: partial
Circularity Check
No derivations, predictions, or equations; survey is self-contained
full rationale
The paper is a survey providing a unified review and common definition of 3D Scene Graphs. It contains no original derivations, equations, fitted parameters, or predictions that could reduce to inputs by construction. The central claim is a critical review of existing work with emphasis on open challenges, which does not rely on self-citation chains or self-definitional reductions. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Referit3d: Neural listen- ers for fine-grained 3D object identification in real-world scenes
Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listen- ers for fine-grained 3D object identification in real-world scenes. InComputer Vision – ECCV 2020. Springer Inter- national Publishing, 2020. 11, 12
2020
-
[2]
Taskography: Evaluating robot task planning over large 3D scene graphs
Christopher Agia, Krishna Murthy Jatavallabhula, Mo- hamed Khodeir, Ondrej Miksik, Vibhav Vineet, Mustafa Mukadam, Liam Paull, and Florian Shkurti. Taskography: Evaluating robot task planning over large 3D scene graphs. InProceedings of the 5th Conference on Robot Learning. PMLR, 2022. 3, 4, 11, 12, 13
2022
-
[3]
Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation
Abrar Anwar, John Welsh, Joydeep Biswas, Soha Pouya, and Yan Chang. Remembr: Building and reasoning over long-horizon spatio-temporal memory for robot navigation. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025. 12
2025
-
[4]
Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese
Iro Armeni, Ozan Sener, Amir R. Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3d se- mantic parsing of large-scale indoor spaces. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016. 3, 8
2016
-
[5]
3d scene graph: A structure for unified semantics, 3D space, and camera
Iro Armeni, Zhi-Yang He, Amir Zamir, Junyoung Gwak, Jitendra Malik, Martin Fischer, and Silvio Savarese. 3d scene graph: A structure for unified semantics, 3D space, and camera. In2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 2019. 2, 3, 6, 7, 8, 10, 11, 13
2019
-
[6]
A survey on 3D scene graphs: Definition, 15 generation and application
Jaewon Bae, Dongmin Shin, Kangbeen Ko, Juchan Lee, and Ue-Hwan Kim. A survey on 3D scene graphs: Definition, 15 generation and application. InRobot Intelligence Technol- ogy and Applications 7. Springer International Publishing,
-
[7]
Long-term planning around humans in domestic environments with 3D scene graphs
Ermanno Bartoli, Dennis Rotondi, Kai O Arras, and Iolanda Leite. Long-term planning around humans in domestic environments with 3D scene graphs. InLifelong Learn- ing and Personalization in Long-Term Human-Robot In- teraction Workshop, ACM/IEEE International Conference on Human-Robot Interaction, Melbourne, Australia, 2025. Mar. 4–6. 11
2025
-
[8]
Ermanno Bartoli, Dennis Rotondi, Buwei He, Patric Jens- felt, Kai O Arras, and Iolanda Leite. Social 3D scene graphs: Modeling human actions and relations for interactive service robots.arXiv preprint arXiv:2509.24966, 2025. 9, 10, 11, 12, 14
arXiv 2025
-
[9]
Situational graphs for robot navigation in structured indoor environments.IEEE Robotics and Automation Letters, 7(4):9107–9114, 2022
Hriday Bavle, Jose Luis Sanchez-Lopez, Muhammad Sha- heer, Javier Civera, and Holger V oos. Situational graphs for robot navigation in structured indoor environments.IEEE Robotics and Automation Letters, 7(4):9107–9114, 2022. 4, 7, 8, 9, 10, 11
2022
-
[10]
S-graphs+: Real-time localization and mapping leveraging hierarchical represen- tations.IEEE Robotics and Automation Letters, 8(8):4927– 4934, 2023
Hriday Bavle, Jose Luis Sanchez-Lopez, Muhammad Sha- heer, Javier Civera, and Holger V oos. S-graphs+: Real-time localization and mapping leveraging hierarchical represen- tations.IEEE Robotics and Automation Letters, 8(8):4927– 4934, 2023. 11
2023
-
[11]
S-graphs 2.0 – a hierarchical-semantic optimization and loop closure for slam.IEEE Robotics and Automation Letters, 10(12): 12461–12468, 2025
Hriday Bavle, Jose Luis Sanchez-Lopez, Muhammad Sha- heer, Javier Civera, and Holger V oos. S-graphs 2.0 – a hierarchical-semantic optimization and loop closure for slam.IEEE Robotics and Automation Letters, 10(12): 12461–12468, 2025. 4, 9, 11
2025
-
[12]
Se- mantickitti: A dataset for semantic scene understanding of LiDAR sequences
Jens Behley, Martin Garbade, Andres Milioto, Jan Quen- zel, Sven Behnke, Cyrill Stachniss, and J ¨urgen Gall. Se- mantickitti: A dataset for semantic scene understanding of LiDAR sequences. In2019 IEEE/CVF International Con- ference on Computer Vision (ICCV). IEEE, 2019. 11
2019
-
[13]
Lost & found: Tracking changes from egocentric observations in 3D dynamic scene graphs.IEEE Robotics and Automation Letters, 10(4):3739–3746, 2025
Tjark Behrens, Ren´e Zurbr¨ugg, Marc Pollefeys, Zuria Bauer, and Hermann Blum. Lost & found: Tracking changes from egocentric observations in 3D dynamic scene graphs.IEEE Robotics and Automation Letters, 10(4):3739–3746, 2025. 8, 9, 11
2025
-
[14]
Articulated 3D scene graphs for open-world mobile manipulation.arXiv preprint arXiv:2602.16356, 2026
Martin B ¨uchner, Adrian Roefer, Tim Engelbracht, Tim Welschehold, Zuria Bauer, Hermann Blum, Marc Polle- feys, and Abhinav Valada. Articulated 3D scene graphs for open-world mobile manipulation.arXiv preprint arXiv:2602.16356, 2026. 5, 7, 11, 12, 13
arXiv 2026
-
[15]
Cesar Cadena, Luca Carlone, Henry Carrillo, Yasir Latif, Davide Scaramuzza, Jos ´e Neira, Ian Reid, and John J. Leonard. Past, present, and future of simultaneous localiza- tion and mapping: Toward the robust-perception age.IEEE Transactions on Robotics, 32(6):1309–1332, 2016. 1, 6
2016
-
[16]
From Localization and Mapping to Spatial Intelligence
Luca Carlone, Ayoung Kim, Timothy Barfoot, Daniel Cre- mers, and Frank Dellaert, editors.SLAM Handbook. From Localization and Mapping to Spatial Intelligence. Cam- bridge University Press, 2026. 2, 9
2026
-
[17]
3d scene graphs in robotics: A unified represen- tation bridging geometry, semantics, and action.TechRxiv, 2025(0819), 2025
Iacopo Catalano, Carlos Cueto Zumaya, Julio A Placed, Javier Civera, Wallace Moreira Bessa, and Jorge Pe ˜na- Queralta. 3d scene graphs in robotics: A unified represen- tation bridging geometry, semantics, and action.TechRxiv, 2025(0819), 2025. 2
2025
-
[18]
Aion: Towards hierarchi- cal 4D scene graphs with temporal flow dynamics
Iacopo Catalano, Eduardo Montijano, Javier Civera, Julio A Placed, and Jorge Pena-Queralta. Aion: Towards hierarchi- cal 4D scene graphs with temporal flow dynamics. In2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2026. Forthcoming. 5
2026
-
[19]
Matterport3d: Learning from RGB- D data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Hal- ber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from RGB- D data in indoor environments. In2017 International Con- ference on 3D Vision (3DV). IEEE, 2017. 10, 11
2017
-
[20]
Context-aware entity grounding with open-vocabulary 3D scene graphs
Haonan Chang, Kowndinya Boyalakuntla, Shiyang Lu, Si- wei Cai, Eric Pu Jing, Shreesh Keskar, Shijie Geng, Adeeb Abbas, Lifeng Zhou, Kostas Bekris, and Abdeslam Boular- ias. Context-aware entity grounding with open-vocabulary 3D scene graphs. InProceedings of The 7th Conference on Robot Learning. PMLR, 2023. 8, 11, 13, 14
2023
-
[21]
A comprehensive sur- vey of scene graphs: Generation and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):1–26, 2023
Xiaojun Chang, Pengzhen Ren, Pengfei Xu, Zhihui Li, Xi- aojiang Chen, and Alex Hauptmann. A comprehensive sur- vey of scene graphs: Generation and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):1–26, 2023. 2
2023
-
[22]
D-lite: Navigation-oriented compression of 3D scene graphs for multi-robot collaboration.IEEE Robotics and Automation Letters, 8(11):7527–7534, 2023
Yun Chang, Luca Ballotta, and Luca Carlone. D-lite: Navigation-oriented compression of 3D scene graphs for multi-robot collaboration.IEEE Robotics and Automation Letters, 8(11):7527–7534, 2023. 14
2023
-
[23]
Hydra-multi: Collaborative online construction of 3D scene graphs with multi-robot teams
Yun Chang, Nathan Hughes, Aaron Ray, and Luca Carlone. Hydra-multi: Collaborative online construction of 3D scene graphs with multi-robot teams. In2023 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). IEEE, 2023. 6, 9, 11, 14
2023
-
[24]
Ashita: Auto- matic scene-grounded hierarchical task analysis
Yun Chang, Leonor Fermoselle, Duy Ta, Bernadette Bucher, Luca Carlone, and Jiuguang Wang. Ashita: Auto- matic scene-grounded hierarchical task analysis. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2025. 5, 7, 8, 11, 12
2025
-
[25]
Qi Charles, Hao Su, Mo Kaichun, and Leonidas J
R. Qi Charles, Hao Su, Mo Kaichun, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3D clas- sification and segmentation. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,
-
[26]
Chang, and Matthias Nießner
Dave Zhenyu Chen, Angel X. Chang, and Matthias Nießner. Scanrefer: 3D object localization in RGB-D scans using nat- ural language. InComputer Vision – ECCV 2020. Springer International Publishing, 2020. 11
2020
-
[27]
Hongming Chen, Yiyang Lin, Ziliang Li, Biyu Ye, Yuying Zhang, and Ximin Lyu. Irs: Instance-level 3D scene graphs via room prior guided LiDAR-camera fusion.arXiv preprint arXiv:2506.06804, 2025. 6, 11
arXiv 2025
-
[28]
where am i?
Jiaqi Chen, Daniel Barath, Iro Armeni, Marc Pollefeys, and Hermann Blum. “where am i?” scene retrieval with lan- guage. InComputer Vision – ECCV 2024. Springer Nature Switzerland, 2025. 10, 11, 12
2024
-
[29]
Clip-driven open- vocabulary 3D scene graph generation via cross-modality 16 contrastive learning
Lianggangxu Chen, Xuejiao Wang, Jiale Lu, Shaohui Lin, Changbo Wang, and Gaoqi He. Clip-driven open- vocabulary 3D scene graph generation via cross-modality 16 contrastive learning. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,
-
[30]
Spatial- rgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- rgpt: Grounded spatial reasoning in vision-language models. InAdvances in Neural Information Processing Systems 37. Curran Associates, Inc., 2024. 11, 13, 14
2024
-
[31]
Yolo-world: Real-time open- vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open- vocabulary object detection. In2024 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). IEEE, 2024. 7
2024
-
[32]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3D reconstructions of indoor scenes. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017. 10, 11, 12
2017
-
[33]
Optimal scene graph planning with large lan- guage model guidance
Zhirui Dai, Arash Asgharivaskasi, Thai Duong, Shusen Lin, Maria-Elizabeth Tzes, George Pappas, and Nikolay Atanasov. Optimal scene graph planning with large lan- guage model guidance. In2024 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2024. 11, 12, 13
2024
-
[34]
Ark- itscenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data
Afshin Dehghan, Gilad Baruch, Zhuoyuan Chen, Yuri Fei- gin, Peter Fu, Thomas Gebauer, Daniel Kurz, Tal Dimry, Brandon Joffe, Arik Schwartz, and Elad Shulman. Ark- itscenes: A diverse real-world dataset for 3D indoor scene understanding using mobile RGB-D data. InProceed- ings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1,...
2021
-
[35]
Robothor: An open simulation-to-real embodied ai platform
Matt Deitke, Winson Han, Alvaro Herrasti, Aniruddha Kembhavi, Eric Kolve, Roozbeh Mottaghi, Jordi Salvador, Dustin Schwenk, Eli VanderBilt, Matthew Wallingford, Luca Weihs, Mark Yatskar, and Ali Farhadi. Robothor: An open simulation-to-real embodied ai platform. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020. 11
2020
-
[36]
Procthor: Large-scale embodied ai using procedural generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor: Large-scale embodied ai using procedural generation. In Advances in Neural Information Processing Systems 35. Curran Associates, Inc., 2022. 11
2022
-
[37]
Scenefun3d: Fine-grained functionality and affordance un- derstanding in 3D scenes
Alexandros Delitzas, Ay c ¸a Takmaz, Federico Tombari, Robert Sumner, Marc Pollefeys, and Francis Engelmann. Scenefun3d: Fine-grained functionality and affordance un- derstanding in 3D scenes. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,
-
[38]
Opengraph: Open-vocabulary hierarchical 3D graph representation in large-scale outdoor environments.IEEE Robotics and Au- tomation Letters, 9(10):8402–8409, 2024
Yinan Deng, Jiahui Wang, Jingyu Zhao, Xinyu Tian, Guangyan Chen, Yi Yang, and Yufeng Yue. Opengraph: Open-vocabulary hierarchical 3D graph representation in large-scale outdoor environments.IEEE Robotics and Au- tomation Letters, 9(10):8402–8409, 2024. 4, 7, 8, 11
2024
-
[39]
CARLA: An open urban driv- ing simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driv- ing simulator. InProceedings of the 1st Annual Conference on Robot Learning. PMLR, 2017. 11
2017
-
[40]
Spotlight: Robotic scene un- derstanding through interaction and affordance detection
Tim Engelbracht, Ren´e Zurbr¨ugg, Marc Pollefeys, Hermann Blum, and Zuria Bauer. Spotlight: Robotic scene un- derstanding through interaction and affordance detection. In2025 IEEE-RAS 24th International Conference on Hu- manoid Robots (Humanoids). IEEE, 2025. 5, 8, 9, 11
2025
-
[41]
Anygrasp: Robust and efficient grasp perception in spa- tial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and efficient grasp perception in spa- tial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023. 13
2023
-
[42]
T-funs3d: Task-driven hi- erarchical open-vocabulary 3D functionality segmentation
Jingkun Feng and Reza Sabzevari. T-funs3d: Task-driven hi- erarchical open-vocabulary 3D functionality segmentation. In2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2026. Forthcoming. 5, 11
2026
-
[43]
3d spatial multimodal knowledge accumulation for scene graph prediction in point cloud
Mingtao Feng, Haoran Hou, Liang Zhang, Ziiie Wu, Yulan Guo, and Ajmal Mian. 3d spatial multimodal knowledge accumulation for scene graph prediction in point cloud. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR). IEEE, 2023. 7, 8, 11
2023
-
[44]
Bloisi, and Daniele Nardi
Sara Micol Ferraina, Michele Brienza, Francesco Ar- genziano, Emanuele Musumeci, Vincenzo Suriani, Domenico D. Bloisi, and Daniele Nardi. Lost-3dsg: Lightweight open-vocabulary 3D scene graphs with seman- tic tracking in dynamic environments. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW). IEEE, 2026. Forthcoming. 9, 11
2026
-
[45]
Funfact: Building probabilistic functional 3D scene graphs via factor- graph reasoning
Zhengyu Fu, Ren´e Zurbr¨ugg, Kaixian Qu, Marc Pollefeys, Marco Hutter, Hermann Blum, and Zuria Bauer. Funfact: Building probabilistic functional 3D scene graphs via factor- graph reasoning. In2026 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). IEEE, 2026. Forthcoming. 5
2026
-
[46]
Semantics for robotic mapping, percep- tion and interaction: A survey.Foundations and Trends in Robotics, 8(1-2):1–224, 2020
Sourav Garg, Niko S ¨underhauf, Feras Dayoub, Douglas Morrison, Akansel Cosgun, Gustavo Carneiro, Qi Wu, Tat-Jun Chin, Ian Reid, Stephen Gould, Peter Corke, and Michael Milford. Semantics for robotic mapping, percep- tion and interaction: A survey.Foundations and Trends in Robotics, 8(1-2):1–224, 2020. 2
2020
-
[47]
Relationship-aware hierarchical 3D scene graph
Albert Gassol Puigjaner, Angelos Zacharia, and Kostas Alexis. Relationship-aware hierarchical 3D scene graph. In2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2026. Forthcoming. 7
2026
-
[48]
Dy- namicgsg: Dynamic 3D gaussian scene graphs for environ- ment adaptation
Luzhou Ge, Xiangyu Zhu, Zhuo Yang, and Xuesong Li. Dy- namicgsg: Dynamic 3D gaussian scene graphs for environ- ment adaptation. In2025 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS). IEEE, 2025. 3, 5, 9, 11
2025
-
[49]
Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
A Geiger, P Lenz, C Stiller, and R Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013. 11
2013
-
[50]
Long- term human trajectory prediction using 3D dynamic scene graphs.IEEE Robotics and Automation Letters, 9(12): 10978–10985, 2024
Nicolas Gorlo, Lukas Schmid, and Luca Carlone. Long- term human trajectory prediction using 3D dynamic scene graphs.IEEE Robotics and Automation Letters, 9(12): 10978–10985, 2024. 5, 11, 12
2024
-
[51]
Describe anything anywhere at any moment
Nicolas Gorlo, Lukas Schmid, and Luca Carlone. Describe anything anywhere at any moment. In2026 IEEE/CVF 17 Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2026. Forthcoming. 3, 5, 7, 9, 10, 11, 12, 14
2026
-
[52]
Collaborative dynamic 3D scene graphs for automated driving
Elias Greve, Martin B¨uchner, Niclas V¨odisch, Wolfram Bur- gard, and Abhinav Valada. Collaborative dynamic 3D scene graphs for automated driving. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE,
-
[53]
Tenenbaum, Antonio Torralba, Florian Shkurti, and Liam Paull
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, Chuang Gan, Celso Miguel de Melo, Joshua B. Tenenbaum, Antonio Torralba, Florian Shkurti, and Liam Paull. Conceptgraphs: Open-vocabulary 3D scene graphs for perception and plan- ning. In2024 IEEE Int...
2024
-
[54]
Qiuyi Gu, Yuze Sheng, Jincheng Yu, Jiahao Tang, Xiaolong Shan, Zhaoyang Shen, Tinghao Yi, Xiaodan Liang, Xinlei Chen, and Yu Wang. Artisg: Functional 3D scene graph con- struction via human-demonstrated articulated objects ma- nipulation.arXiv preprint arXiv:2512.24845, 2025. 5, 11, 13
arXiv 2025
-
[55]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Doll´ar, and Ross Gir- shick. Mask r-cnn. In2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 2017. 7
2017
-
[56]
Object-centric representation learning for enhanced 3D semantic scene graph prediction
KunHo Heo, GiHyeon Kim, SuYeon Kim, and MyeongAh Cho. Object-centric representation learning for enhanced 3D semantic scene graph prediction. InAdvances in Neural Information Processing Systems 39. Curran Associates, Inc.,
-
[57]
6, 7, 11
Forthcoming. 6, 7, 11
-
[58]
Language-grounded dy- namic scene graphs for interactive object search with mo- bile manipulation.IEEE Robotics and Automation Letters, 9(10):8298–8305, 2024
Daniel Honerkamp, Martin B¨uchner, Fabien Despinoy, Tim Welschehold, and Abhinav Valada. Language-grounded dy- namic scene graphs for interactive object search with mo- bile manipulation.IEEE Robotics and Automation Letters, 9(10):8298–8305, 2024. 9, 11, 12, 13, 14
2024
-
[59]
Fross: Faster-than-real-time online 3D semantic scene graph generation from RGB-D images
Hao-Yu Hou, Chun-Yi Lee, Motoharu Sonogashira, and Ya- sutomo Kawanishi. Fross: Faster-than-real-time online 3D semantic scene graph generation from RGB-D images. In 2025 IEEE/CVF International Conference on Computer Vi- sion. IEEE, 2026. Forthcoming. 3, 10, 11
2025
-
[60]
Mixed dif- fusion for 3D indoor scene synthesis
Siyi Hu, Diego Mart ´ın Arroyo, Stephanie Debats, Fabian Manhardt, Luca Carlone, and Federico Tombari. Mixed dif- fusion for 3D indoor scene synthesis. In2026 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2026. Forthcoming. 14
2026
-
[61]
Yue Hu, Junzhe Wu, Ruihan Xu, Hang Liu, Avery Xi, Henry X Liu, Ram Vasudevan, and Maani Ghaffari. Imag- inative world modeling with scene graphs for embodied agent navigation.arXiv preprint arXiv:2508.06990, 2025. 11, 13
arXiv 2025
-
[62]
Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization
Nathan Hughes, Yun Chang, and Luca Carlone. Hydra: A Real-time Spatial Perception System for 3D Scene Graph Construction and Optimization. InRobotics: Science and Systems XVIII. Robotics: Science and Systems Foundation,
-
[63]
2, 3, 6, 7, 8, 9, 10, 11
-
[64]
Foundations of spatial perception for robotics: Hierarchical representa- tions and real-time systems.The International Journal of Robotics Research, 43(10):1457–1505, 2024
Nathan Hughes, Yun Chang, Siyi Hu, Rajat Talak, Rumaia Abdulhai, Jared Strader, and Luca Carlone. Foundations of spatial perception for robotics: Hierarchical representa- tions and real-time systems.The International Journal of Robotics Research, 43(10):1457–1505, 2024. 3, 6, 7, 8, 9, 10, 11
2024
-
[65]
Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation
Hanxiao Jiang, Binghao Huang, Ruihai Wu, Zhuoran Li, Shubham Garg, Hooshang Nayyeri, Shenlong Wang, and Yunzhu Li. Roboexp: Action-conditioned scene graph via interactive exploration for robotic manipulation. InPro- ceedings of The 8th Conference on Robot Learning. PMLR,
-
[66]
Xueying Jiang, Wenhao Li, Xiaoqin Zhang, Ling Shao, and Shijian Lu. Exploring 3D reasoning-driven planning: From implicit human intentions to route-aware activity planning. arXiv preprint arXiv:2503.12974, 2025. 11
arXiv 2025
-
[67]
Towards long- term retrieval-based visual localization in indoor environ- ments with changes.IEEE Robotics and Automation Letters, 8(4):1975–1982, 2023
Julia Kabalar, Shun-Cheng Wu, Johanna Wald, Keisuke Tateno, Nassir Navab, and Federico Tombari. Towards long- term retrieval-based visual localization in indoor environ- ments with changes.IEEE Robotics and Automation Letters, 8(4):1975–1982, 2023. 9, 11
1975
-
[68]
Christina Kassab, Hyeonjae Gil, Mat´ıas Mattamala, Ayoung Kim, and Maurice Fallon. Lexi-sg: Monocular 3D scene graph mapping with room-guided feed-forward reconstruc- tion.arXiv preprint arXiv:2605.13741, 2026. 6, 11
Pith/arXiv arXiv 2026
-
[69]
Openlex3d: A tiered benchmark for open-vocabulary 3D scene representations
Christina Kassab, Sacha Morin, Martin B ¨uchner, Matias Mattamala, Kumaraditya Gupta, Abhinav Valada, Liam Paull, and Maurice Fallon. Openlex3d: A tiered benchmark for open-vocabulary 3D scene representations. InAdvances in Neural Information Processing Systems 39. Curran As- sociates, Inc., 2026. Forthcoming. 10
2026
-
[70]
Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 13:162467–162504, 2025
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Pos- ner, and Yuke Zhu. Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 13:162467–162504, 2025. 14
2025
-
[71]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. In2023 IEEE/CVF International Confer- ence on Computer Vision (ICCV). IEEE, 2023. 2
2023
-
[72]
Tacs-graphs: Traversability-aware consistent scene graphs for ground robot localization and mapping
Jeewon Kim, Minho Oh, and Hyun Myung. Tacs-graphs: Traversability-aware consistent scene graphs for ground robot localization and mapping. In2025 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). IEEE, 2025. 9, 10, 11
2025
-
[73]
3-d scene graph: A sparse and seman- tic representation of physical environments for intelligent agents.IEEE Transactions on Cybernetics, 50(12):4921– 4933, 2020
Ue-Hwan Kim, Jin-Man Park, Taek-jin Song, and Jong- Hwan Kim. 3-d scene graph: A sparse and seman- tic representation of physical environments for intelligent agents.IEEE Transactions on Cybernetics, 50(12):4921– 4933, 2020. 2, 6, 11, 12
2020
-
[74]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. In2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV). IEEE,
-
[75]
Lang3dsg: Language- based contrastive pre-training for 3D scene graph predic- tion
Sebastian Koch, Pedro Hermosilla, Narunas Vaskevicius, Mirco Colosi, and Timo Ropinski. Lang3dsg: Language- based contrastive pre-training for 3D scene graph predic- tion. In2024 International Conference on 3D Vision (3DV). IEEE, 2024. 8, 11 18
2024
-
[76]
SGRec3D: Self- supervised 3D scene graph learning via object-level scene reconstruction
Sebastian Koch, Pedro Hermosilla, Narunas Vaskevicius, Mirco Colosi, and Timo Ropinski. SGRec3D: Self- supervised 3D scene graph learning via object-level scene reconstruction. In2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2024. 6, 7, 8, 11
2024
-
[77]
Open3dsg: Open- vocabulary 3D scene graphs from point clouds with queryable objects and open-set relationships
Sebastian Koch, Narunas Vaskevicius, Mirco Colosi, Pe- dro Hermosilla, and Timo Ropinski. Open3dsg: Open- vocabulary 3D scene graphs from point clouds with queryable objects and open-set relationships. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2024. 6, 7, 8, 9, 11
2024
-
[78]
Relationfield: Relate anything in radiance fields
Sebastian Koch, Johanna Wald, Mirco Colosi, Narunas Vaskevicius, Pedro Hermosilla, Federico Tombari, and Timo Ropinski. Relationfield: Relate anything in radiance fields. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2025. 7, 11
2025
-
[79]
AI2-THOR: An in- teractive 3D environment for visual AI.arXiv preprint arXiv:1712.05474, 2017
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. AI2-THOR: An in- teractive 3D environment for visual AI.arXiv preprint arXiv:1712.05474, 2017. 11, 13
Pith/arXiv arXiv 2017
-
[80]
Lingdong Kong, Wesley Yang, Jianbiao Mei, Youquan Liu, Ao Liang, Dekai Zhu, Dongyue Lu, Wei Yin, Xiaotao Hu, Mingkai Jia, Junyuan Deng, Kaiwen Zhang, Yang Wu, Tianyi Yan, Shenyuan Gao, Song Wang, Linfeng Li, Liang Pan, Yong Liu, Jianke Zhu, Wei Tsang Ooi, Steven C. H. Hoi, and Ziwei Liu. 3d and 4D world modeling: A survey. arXiv preprint arXiv:2509.07996, 2025. 2
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.