Large Language Models Should Learn Personalized Rather Than Aggregated Human Preferences
Pith reviewed 2026-06-28 19:02 UTC · model grok-4.3
The pith
Large language models should learn individualized preferences rather than preferences aggregated across users into one reward signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
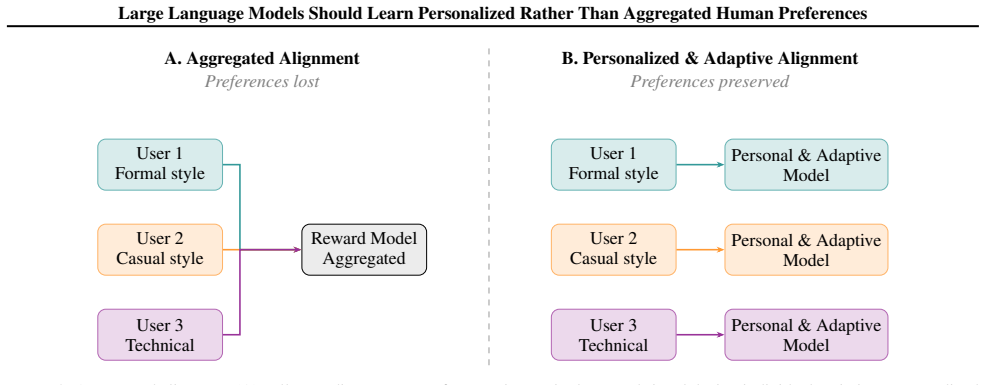
Aggregating human preferences into one reward signal produces an average-user model that represents no real individual and erases critical diversity in values and contextual dependencies; therefore LLMs should instead learn personalized preferences, subject to bounded frameworks that preserve universal safety constraints while permitting legitimate individual variation.
What carries the argument
The contrast between an aggregated reward signal (which collapses all users into one hypothetical average) and individualized preference models (which retain user-specific structure), positioned as the central mechanism for capturing preference diversity.
If this is right
- Aggregation necessarily masks both inter-group and intra-group differences in preferences, reducing alignment quality for every actual user.
- Technical methods already exist that can encode the richer structure of individual preferences without requiring full per-user retraining.
- Universal safety constraints can be retained as hard boundaries while softer preference dimensions are allowed to vary per user.
- A concrete research agenda exists for developing and evaluating preference-aware models that balance autonomy and collective safety.
- Policy attention should shift from purely aggregate alignment metrics toward metrics that also track fidelity to individual preference distributions.
Where Pith is reading between the lines
- If the argument holds, evaluation benchmarks that currently rely on aggregate human judgments would need to be replaced or augmented by per-user or per-demographic metrics.
- The same aggregation problem appears in other domains such as recommendation systems and content moderation, suggesting the proposed shift could apply beyond LLMs.
- One testable extension is whether bounded personalization reduces user disengagement rates compared with average-user models in longitudinal deployment studies.
Load-bearing premise
Bounded personalization frameworks can preserve universal safety constraints while still accommodating legitimate individual variation without creating unmanageable risks such as filter bubbles or value lock-in.
What would settle it
A controlled experiment that trains otherwise identical models on aggregated versus personalized preference data and shows that the personalized versions systematically violate the same safety constraints that the aggregated versions satisfy would falsify the claim that risks remain manageable.
Figures

read the original abstract
Current approaches to aligning large language models (LLMs) aggregate diverse human preferences into a single reward signal, effectively optimizing for a hypothetical ``average user'' who represents no real person particularly well. This position paper argues that LLMs should learn personalized, individual preferences rather than aggregated ones. We show that aggregation masks critical information about preference diversity, individual values, and contextual dependencies, which is a limitation both theoretically grounded in social choice theory and empirically evident across demographic groups. We analyze the rich structure that human preferences encode, survey technical approaches to personalization, and systematically address counterarguments on scalability, shared standards, and manipulation risk. While personalization introduces genuine safety challenges including filter bubbles, value lock-in, and psychological manipulation, we argue these are manageable through bounded personalization frameworks that preserve universal safety constraints while accommodating legitimate individual variation. We conclude with a concrete research and policy agenda for developing preference-aware models that respect both individual autonomy and collective safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a position paper arguing that LLM alignment currently aggregates diverse human preferences into a single reward signal, optimizing for a hypothetical 'average user' that represents no real individual well. It claims aggregation masks critical information on preference diversity, individual values, and contextual dependencies—a limitation both theoretically grounded in social choice theory and empirically evident across demographic groups. The paper surveys technical approaches to personalization, systematically addresses counterarguments on scalability, shared standards, and manipulation risk, and advocates bounded personalization frameworks that preserve universal safety constraints while accommodating individual variation. It concludes with a research and policy agenda for preference-aware models respecting both autonomy and collective safety.
Significance. If the central normative argument holds, the paper could meaningfully influence AI alignment research by reframing aggregated preference optimization as a core limitation and promoting personalized alternatives. This has potential significance for ethical and effective LLM development. As a conceptual position paper without new empirical measurements, formal derivations, or algorithmic constructions, its value lies primarily in synthesizing existing ideas and addressing counterarguments rather than advancing technical methods. The explicit treatment of safety challenges and proposal of bounded frameworks is a constructive element.
major comments (3)
- [Abstract] Abstract: The claim that aggregation's limitations are 'empirically evident across demographic groups' is asserted without any data, citations, or analysis provided in the manuscript. This empirical grounding is load-bearing for the argument that aggregation is harmful in practice.
- [Abstract] Abstract: The invocation of social choice theory to ground the harm of aggregation is stated at a high level but does not cite or derive any specific results (e.g., Arrow's theorem or related impossibility results) to show why aggregation necessarily masks individual values in the LLM setting.
- [Abstract] Abstract: The bounded personalization framework is proposed to manage risks such as filter bubbles and value lock-in while preserving safety, but no concrete mechanisms, constraints, or enforcement methods are specified. This detail is load-bearing for the claim that the safety challenges are manageable.
minor comments (1)
- [Abstract] Abstract: The double-backtick formatting in ``average user'' is a typographical artifact and should use standard quotation marks.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our position paper. Below we respond point-by-point to the major comments on the abstract, indicating where we will revise the manuscript for clarity and precision while preserving its conceptual focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that aggregation's limitations are 'empirically evident across demographic groups' is asserted without any data, citations, or analysis provided in the manuscript. This empirical grounding is load-bearing for the argument that aggregation is harmful in practice.
Authors: We agree the abstract states the claim at a high level. The body of the manuscript synthesizes existing empirical literature on demographic variation in preferences (including cross-cultural value surveys and alignment studies). To directly address the concern, we will revise the abstract to include a brief qualifying phrase and pointer to these references. revision: yes
-
Referee: [Abstract] Abstract: The invocation of social choice theory to ground the harm of aggregation is stated at a high level but does not cite or derive any specific results (e.g., Arrow's theorem or related impossibility results) to show why aggregation necessarily masks individual values in the LLM setting.
Authors: We accept that an explicit link would strengthen the argument. The manuscript already draws on social choice concepts to illustrate how aggregation can produce outcomes misaligned with any individual's preferences. We will add citations to Arrow's impossibility theorem and related results, together with a short explanation of their applicability to LLM reward modeling. revision: yes
-
Referee: [Abstract] Abstract: The bounded personalization framework is proposed to manage risks such as filter bubbles and value lock-in while preserving safety, but no concrete mechanisms, constraints, or enforcement methods are specified. This detail is load-bearing for the claim that the safety challenges are manageable.
Authors: The framework is presented conceptually to outline the normative balance between autonomy and safety. We acknowledge that illustrative mechanisms would make the claim more robust. In revision we will add high-level examples (e.g., immutable safety layers that cannot be overridden by personalization) while keeping the paper's position-paper character. revision: partial
Circularity Check
No significant circularity identified
full rationale
This is a normative position paper with no formal derivations, equations, fitted parameters, or algorithmic constructions. Its central claim is a policy recommendation grounded in external appeals to social choice theory and demographic observations. No load-bearing steps reduce by construction to the paper's own inputs, self-citations, or ansatzes. The argument is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Aggregating diverse human preferences into a single reward signal necessarily masks critical information about preference diversity, individual values, and contextual dependencies
Reference graph
Works this paper leans on
-
[1]
Abdulhai, M., White, I., Wan, Y ., Qureshi, I., Leibo, J., Kleiman-Weiner, M., and Jaques, N. How llms distort our written language.arXiv preprint arXiv:2603.18161,
-
[2]
A General Language Assistant as a Laboratory for Alignment
Askell, A., Bai, Y ., Chen, A., Drain, D., Ganguli, D., Henighan, T., Jones, A., Joseph, N., Mann, B., DasSarma, N., et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Pal: Sample-efficient personalized reward modeling for plural- istic alignment
Chen, D., Chen, Y ., Rege, A., Wang, Z., and Vinayak, R. Pal: Sample-efficient personalized reward modeling for plural- istic alignment. InInternational Conference on Learning Representations, volume 2025, pp. 15755–15799,
2025
-
[5]
User embedding model for personalized language prompting
Doddapaneni, S., Sayana, K., Jash, A., Sodhi, S., and Kuzmin, D. User embedding model for personalized language prompting. InProceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSON- ALIZE 2024), pp. 124–131,
2024
-
[6]
When the majority is wrong: Modeling annotator disagreement for subjec- tive tasks
Fleisig, E., Abebe, R., and Klein, D. When the majority is wrong: Modeling annotator disagreement for subjec- tive tasks. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 6715–6726,
2023
-
[7]
Garbacea, C. and Tan, C. Hyperalign: Interpretable person- alized llm alignment via hypothesis generation.arXiv preprint arXiv:2505.00038,
-
[8]
Personalized Benchmarking: Evaluating LLMs by Individual Preferences
Garbacea, C., Wang, H., and Tan, C. Personalized bench- marking: Evaluating llms by individual preferences. arXiv preprint arXiv:2604.18943,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
L., Lam, M
10 Large Language Models Should Learn Personalized Rather Than Aggregated Human Preferences Gordon, M. L., Lam, M. S., Park, J. S., Patel, K., Hancock, J., Hashimoto, T., and Bernstein, M. S. Jury learning: In- tegrating dissenting voices into machine learning models. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp. 1–19,
2022
-
[10]
Beyond Fixed Psychological Personas: State Beats Trait, but Language Models are State-Blind
Harry, T., Ngong, I., Nweke, C., Feng, Y ., and Near, J. Beyond fixed psychological personas: State beats trait, but language models are state-blind.arXiv preprint arXiv:2601.15395,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Context steering: Controllable personalization at inference time
He, Z., Pandey, S., Schrum, M., and Dragan, A. Context steering: Controllable personalization at inference time. InInternational Conference on Learning Representations, volume 2025, pp. 87863–87895,
2025
-
[12]
and Yang, D
Huang, J. and Yang, D. Culturally aware natural language in- ference. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 7591–7609,
2023
-
[13]
Co-writing with opinionated language models affects users’ views
Jakesch, M., Hancock, J., and Naaman, M. Co-writing with opinionated language models affects users’ views. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pp. 1–15,
2023
-
[14]
Adaptation of large language models
Ke, Z., Ming, Y ., and Joty, S. Adaptation of large language models. InProceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies (Volume 5: Tutorial Abstracts), pp. 30–37,
2025
-
[15]
Kim, S. and Kim, J. Spring: Continual llm per- sonalization via selective parametric adaptation and retrieval-interpolated generation.arXiv preprint arXiv:2601.09974,
-
[16]
R., Vidgen, B., R¨ottger, P., and Hale, S
Kirk, H. R., Vidgen, B., R¨ottger, P., and Hale, S. A. Personal- isation within bounds: A risk taxonomy and policy frame- work for the alignment of large language models with personalised feedback.arXiv preprint arXiv:2303.05453,
- [17]
-
[18]
The power of scale for parameter-efficient prompt tuning
Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 3045–3059,
2021
-
[19]
Eliciting human preferences with language models
Li, B., Tamkin, A., Goodman, N., and Andreas, J. Eliciting human preferences with language models. InInterna- tional Conference on Learning Representations, volume 2025, pp. 80984–81013, 2025a. Li, Y .-C., Zhang, F., Qiu, W., Yuan, L., Jia, C., Zhang, Z., Yu, Y ., and An, B. Q-adapter: Customizing pre-trained llms to new preferences with forgetting mitiga...
-
[20]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., et al. Webgpt: Browser-assisted question-answering with hu- man feedback.arXiv preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The alignment prob- lem from a deep learning perspective
Ngo, R., Chan, L., and Mindermann, S. The alignment prob- lem from a deep learning perspective. InInternational Conference on Learning Representations, volume 2024, pp. 7474–7501,
2024
-
[22]
Disentan- gling length from quality in direct preference optimiza- tion
Park, R., Rafailov, R., Ermon, S., and Finn, C. Disentan- gling length from quality in direct preference optimiza- tion. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 4998–5017,
2024
-
[23]
Towards understanding syco- phancy in language models
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S., Durmus, E., Hatfield-Dodds, Z., John- ston, S., Kravec, S., et al. Towards understanding syco- phancy in language models. InInternational Conference on Learning Representations, volume 2024, pp. 110–144,
2024
-
[24]
Large language models are not yet human-level evaluators for abstractive summarization
Shen, C., Cheng, L., Nguyen, X.-P., You, Y ., and Bing, L. Large language models are not yet human-level evaluators for abstractive summarization. InThe 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[25]
arXiv preprint arXiv:2311.03285 , year=
Sheng, Y ., Cao, S., Li, D., Hooper, C., Lee, N., Yang, S., Chou, C., Zhu, B., Zheng, L., Keutzer, K., et al. S-lora: Serving thousands of concurrent lora adapters.arXiv preprint arXiv:2311.03285,
-
[26]
Beyond memorization: Violating privacy via inference with large language models
Staab, R., Vero, M., Balunovic, M., and Vechev, M. Beyond memorization: Violating privacy via inference with large language models. InInternational Conference on Learn- ing Representations, volume 2024, pp. 33832–33878,
2024
-
[27]
Sun, H., Shen, Y ., and Ton, J.-F. Rethinking bradley- terry models in preference-based reward modeling: Foundations, theory, and alternatives.arXiv preprint arXiv:2411.04991,
-
[28]
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
12 Large Language Models Should Learn Personalized Rather Than Aggregated Human Preferences Wang, X., Tian, M., Zeng, Y ., Huang, Z., Yuan, J., Chen, B., Xu, J., Zhou, M., Liu, W., Wu, M., et al. Reward hacking in the era of large models: Mechanisms, emergent mis- alignment, challenges.arXiv preprint arXiv:2604.13602,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
B., and Choi, E
Zhang, M., Knox, W. B., and Choi, E. Modeling future con- versation turns to teach llms to ask clarifying questions. InInternational Conference on Learning Representations, volume 2025, pp. 60722–60742,
2025
-
[30]
Per- sonalllm: Tailoring llms to individual preferences
Zollo, T., Siah, A., Ye, N., Li, L., and Namkoong, H. Per- sonalllm: Tailoring llms to individual preferences. In International Conference on Learning Representations, volume 2025, pp. 66949–66971,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.