UniTacVLA: Unified Tactile Understanding and Prediction in Vision Language Action Models
Pith reviewed 2026-07-01 05:20 UTC · model grok-4.3
The pith
A unified tactile latent space with chain-of-thought reasoning and coarse-to-fine prediction lets vision-language-action models handle contact-rich manipulation more reliably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
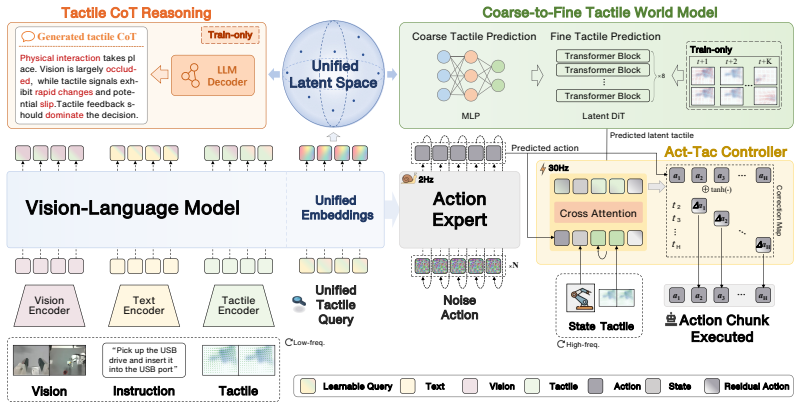
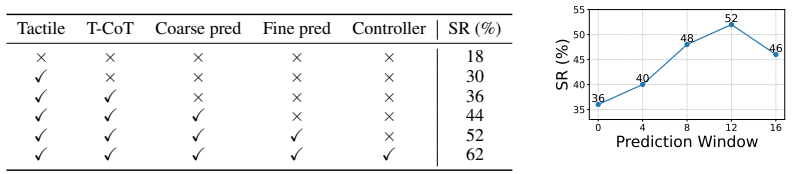
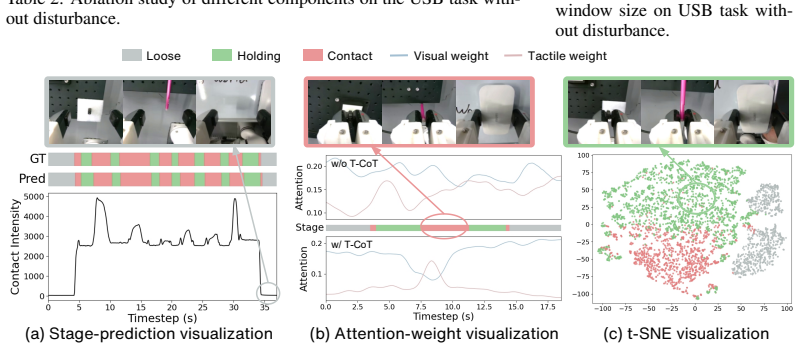
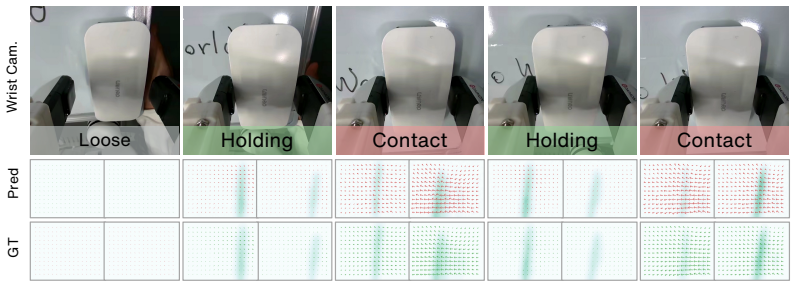
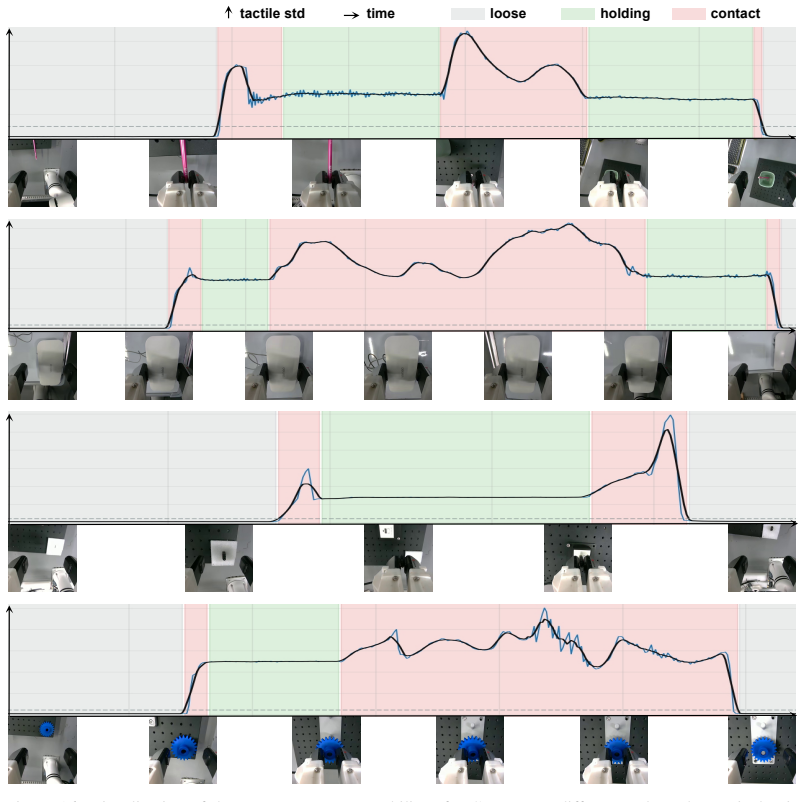
The authors claim that constructing a unified tactile latent space and jointly modeling current tactile states and future contact changes through tactile chain-of-thought reasoning and coarse-to-fine future tactile prediction forms a state-aware and dynamics-aware tactile prior; a tactile-action mixed controller then uses real-time and predicted tactile feedback to refine low-frequency action chunks with high-frequency corrections, yielding higher success rates, manipulation accuracy, and contact robustness on four categories of contact-rich tasks under both clean and perturbed conditions.
What carries the argument
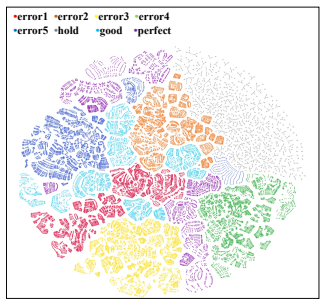
Unified tactile latent space that supports chain-of-thought reasoning for current states and coarse-to-fine prediction for future contact changes, serving as a dynamics-aware prior for action refinement.
If this is right
- The tactile-action mixed controller produces higher success rates on adjustment, insertion, wiping, and assembly tasks.
- Manipulation accuracy and contact robustness increase under both clean and externally perturbed conditions.
- Low-frequency action chunks receive high-frequency corrections from combined real-time and predicted tactile feedback.
- Tactile signals function as dynamic interaction cues rather than auxiliary inputs.
Where Pith is reading between the lines
- The same latent-space construction could be tested on additional sensory modalities to create multi-modal priors for manipulation.
- If the coarse-to-fine prediction generalizes, it might allow lower control frequencies without sacrificing contact stability.
- The framework might scale to more complex multi-fingered hands once the latent space is shown to transfer across hardware.
Load-bearing premise
A single unified tactile latent space combined with chain-of-thought reasoning and coarse-to-fine prediction can capture both current contact semantics and future physical interaction dynamics without loss of critical information or introduction of artifacts.
What would settle it
A controlled experiment on the same four task categories that shows no improvement in success rate or accuracy, or that demonstrates measurable artifacts in predicted tactile signals, when the unified latent space and prediction modules are used versus a passive-tactile baseline.
Figures










read the original abstract
Vision-language-action (VLA) models have achieved strong performance in many robotic manipulation tasks, yet remain limited in contact-rich dexterous manipulation. To overcome this limitation, recent vision-tactile-language-action (VTLA) methods incorporate tactile sensing into VLA models to provide direct contact information. However, they typically treat tactile signals as passive auxiliary inputs, making it difficult to model tactile semantics and future physical interactions. To this end, we propose a unified tactile learning framework for contact-rich manipulation that models tactile signals as dynamic interaction cues for both contact understanding and prediction. Specifically, we construct a unified tactile latent space and jointly model current tactile states and future contact changes through tactile chain-of-thought reasoning and coarse-to-fine future tactile prediction, thereby forming a state-aware and dynamics-aware tactile prior. Based on this prior, we introduce a tactile-action mixed controller that combines real-time and predicted tactile feedback to refine low-frequency action chunks with high-frequency corrections. Real-world experiments on four categories of contact-rich tasks, including adjustment, insertion, wiping, and assembly, under both clean and externally perturbed settings, show that our method improves success rate, manipulation accuracy, and contact robustness over existing methods, demonstrating its effectiveness in dexterous physical interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniTacVLA, a unified tactile learning framework for vision-language-action (VLA) models to address limitations in contact-rich dexterous manipulation. It constructs a unified tactile latent space and uses tactile chain-of-thought reasoning together with coarse-to-fine future tactile prediction to form a state-aware and dynamics-aware tactile prior. This prior informs a tactile-action mixed controller that combines real-time and predicted tactile feedback for refining action chunks. Real-world experiments across four contact-rich task categories (adjustment, insertion, wiping, assembly) under clean and externally perturbed conditions report improvements in success rate, manipulation accuracy, and contact robustness relative to existing methods.
Significance. If the reported gains hold under detailed scrutiny, the work would meaningfully extend VTLA models by shifting tactile signals from passive auxiliaries to active, predictive components of interaction dynamics. The emphasis on real-world validation across multiple task categories with external perturbations provides a practical test of robustness that is directly relevant to deployment in unstructured environments.
minor comments (3)
- The abstract and introduction would benefit from explicit quantitative results (e.g., success-rate deltas and statistical significance) rather than qualitative statements of improvement; this would allow readers to gauge effect sizes immediately.
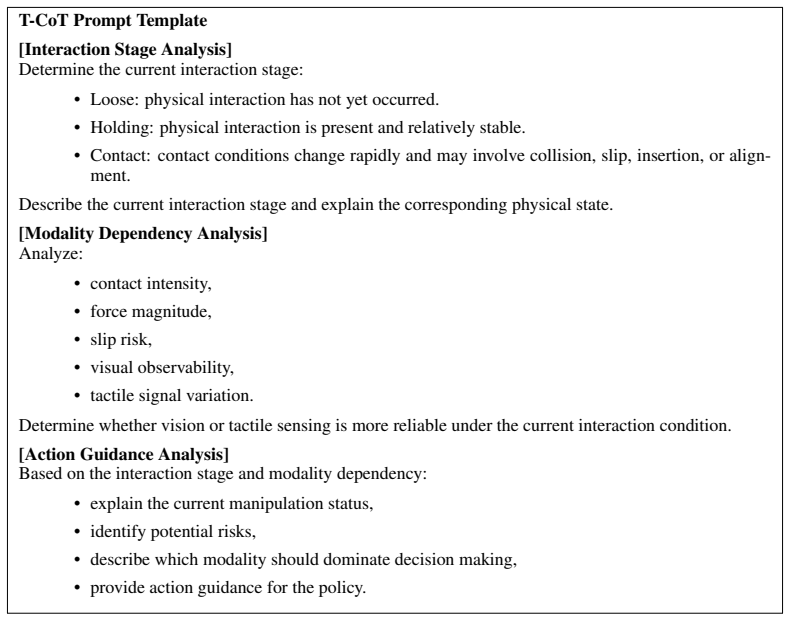
- Notation for the unified tactile latent space and the coarse-to-fine prediction modules should be introduced with a clear diagram or equation set early in the methods section to avoid ambiguity when describing the chain-of-thought reasoning.
- The description of the tactile-action mixed controller would be clearer if the frequency separation between low-frequency action chunks and high-frequency corrections were illustrated with a timing diagram or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our work and the positive assessment of its significance for extending VTLA models with predictive tactile components. The recommendation for minor revision is noted. However, no specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces an architectural framework (unified tactile latent space + CoT reasoning + coarse-to-fine prediction) whose value is asserted via downstream real-world task success rates on four contact-rich categories under clean and perturbed conditions. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or uniqueness result to the inputs by construction. The modeling choices are standard extensions of VLA/VTLA architectures and are validated externally by empirical comparisons rather than by internal tautology or self-referential fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
Zhang, P
C. Zhang, P. Hao, X. Cao, X. Hao, S. Cui, and S. Wang. Vtla: Vision-tactile-language- action model with preference learning for insertion manipulation.Biomimetic Intelligence and Robotics, page 100333, 2026
2026
- [5]
-
[6]
Nazari, W
K. Nazari, W. Mandill, M. Hanheide, and A. G. Esfahani. Tactile dynamic behaviour prediction based on robot action. InAnnual Conference Towards Autonomous Robotic Systems, pages 284–293. Springer, 2021
2021
- [7]
-
[8]
G. Ye, Z. Zhang, X. Zhao, S. Wu, H. Lu, S. Lu, and H. Liu. Learning to feel the future: Dreamtacvla for contact-rich manipulation.arXiv preprint arXiv:2512.23864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Calandra, A
R. Calandra, A. Owens, D. Jayaraman, J. Lin, W. Yuan, J. Malik, E. H. Adelson, and S. Levine. More than a feeling: Learning to grasp and regrasp using vision and touch.IEEE Robotics and Automation Letters, 3(4):3300–3307, 2018
2018
-
[11]
S. Dong, D. K. Jha, D. Romeres, S. Kim, D. Nikovski, and A. Rodriguez. Tactile-rl for inser- tion: Generalization to objects of unknown geometry. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6437–6443. IEEE, 2021
2021
-
[12]
H. Qi, B. Yi, S. Suresh, M. Lambeta, Y . Ma, R. Calandra, and J. Malik. General in-hand object rotation with vision and touch. InConference on Robot Learning, pages 2549–2564. PMLR, 2023
2023
-
[13]
Sunil, S
N. Sunil, S. Wang, Y . She, E. Adelson, and A. R. Garcia. Visuotactile affordances for cloth manipulation with local control. InConference on Robot Learning, pages 1596–1606. PMLR, 2023
2023
-
[14]
Schoettler, A
G. Schoettler, A. Nair, J. Luo, S. Bahl, J. A. Ojea, E. Solowjow, and S. Levine. Deep re- inforcement learning for industrial insertion tasks with visual inputs and natural rewards. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5548–5555. IEEE, 2020
2020
-
[15]
W. Liu, J. Wang, Y . Wang, W. Wang, and C. Lu. Forcemimic: Force-centric imitation learning with force-motion capture system for contact-rich manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 1105–1112. IEEE, 2025. 9
2025
- [16]
- [17]
-
[18]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[22]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.pi 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [24]
- [25]
-
[26]
J. Bi, K. Y . Ma, C. Hao, M. S. Zheng, and H. Soh. Vla-touch: Enhancing vision-language- action model with dual-level tactile feedback.IEEE Robotics and Automation Letters, 2026
2026
-
[27]
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Cai, et al. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation.Ad- vances in Neural Information Processing Systems, 38:93409–93439, 2026
2026
-
[28]
Jones, O
J. Jones, O. Mees, C. Sferrazza, K. Stachowicz, P. Abbeel, and S. Levine. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5961–5968. IEEE, 2025
2025
-
[29]
W. Song, Z. Zhou, H. Zhao, J. Chen, P. Ding, H. Yan, Y . Huang, F. Tang, D. Wang, and H. Li. Reconvla: Reconstructive vision-language-action model as effective robot perceiver. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18549– 18557, 2026
2026
-
[30]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge. Advances in Neural Information Processing Systems, 38:24195–24228, 2026
2026
- [31]
- [32]
-
[33]
S. Routray, H. Pan, U. Jain, S. Bahl, and D. Pathak. Vipra: Video prediction for robot actions. arXiv preprint arXiv:2511.07732, 2025
-
[34]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end- to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [39]
- [40]
- [41]
- [42]
- [43]
-
[44]
J. Lee, J. Shin, H. Choi, and J. Lee. Latent diffusion models with masked autoencoders. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17422–17431, October 2025. 11 A Dataset and Task Details A.1 Hardware Details All demonstrations are collected using a teleoperation system based on an ALOHA-style master- slave co...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.