Automating the Design of Embodied AgentArchitectures
Pith reviewed 2026-06-30 05:40 UTC · model grok-4.3
The pith
Architecture search produces directional success-rate gains for embodied agents on simulator tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
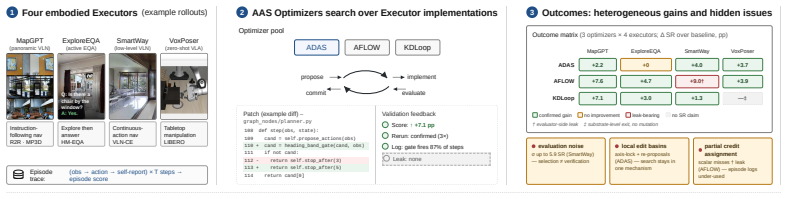
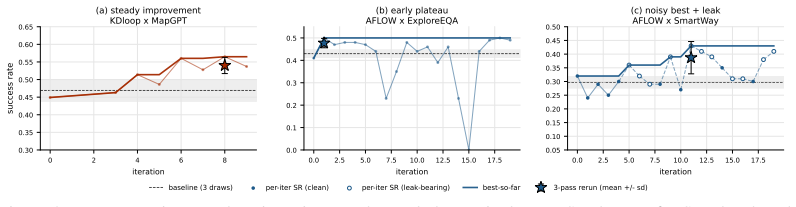
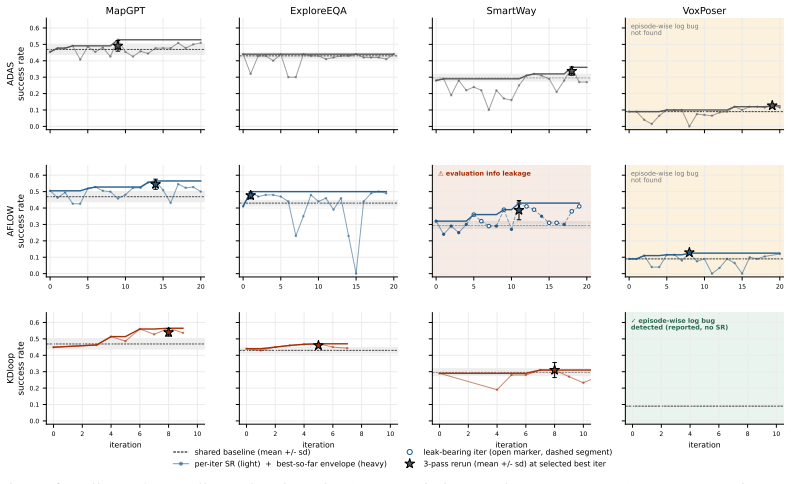
Agent Architecture Search transfers to perceptual embodied agents when evaluated through simulator rollouts, yielding deployable architectures that deliver directional success-rate gains on vision-language navigation, embodied question answering, and language-conditioned manipulation; a 3-by-4 matrix of variants shows these gains while also exposing that rollout noise can mask signals, search can trap in local edit basins, and episode-level credit assignment appears only partially even with detailed logs.
What carries the argument
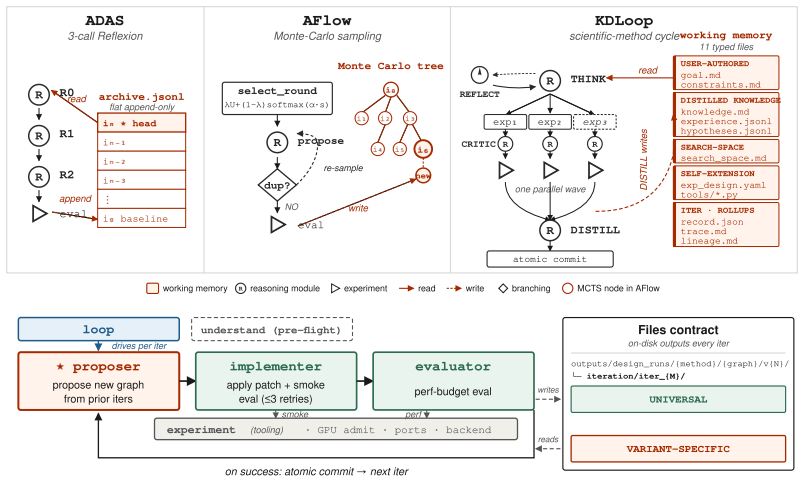
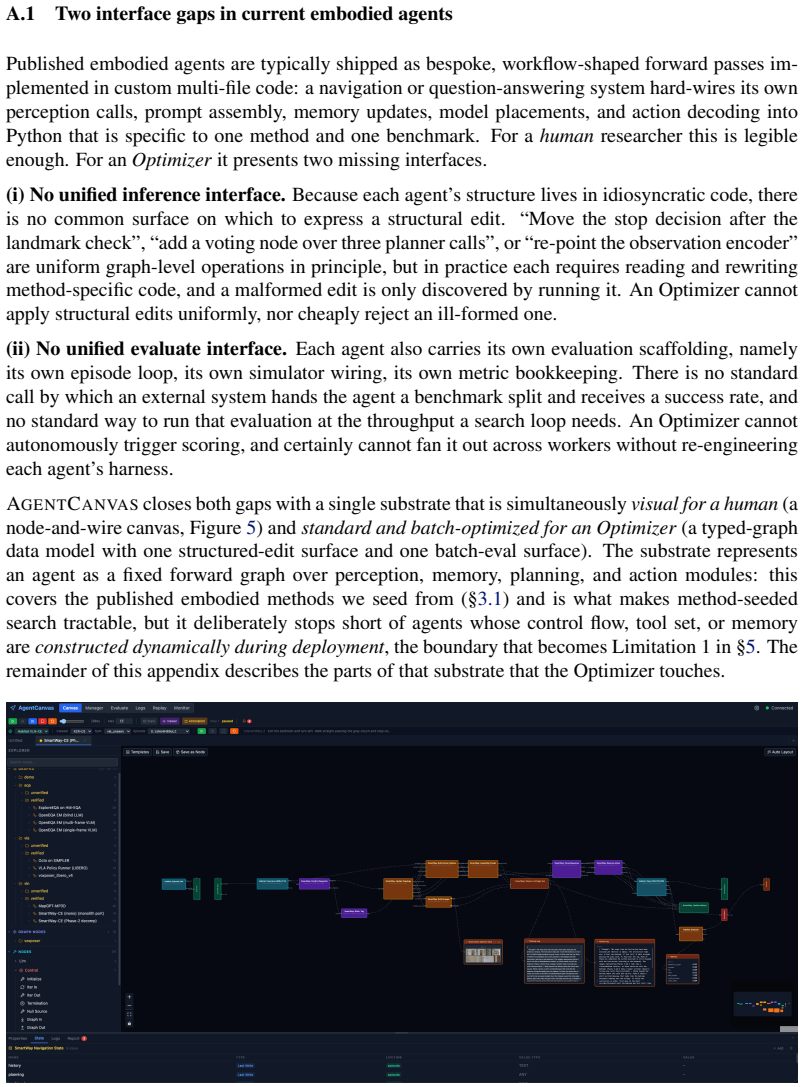
AgentCanvas, a typed-graph runtime that hosts embodied executors as editable node-and-wire programs with simulator-aware execution and episode-level logs, together with KDLoop, a search procedure that cycles through proposal, critique, experiment, and distillation with triggered reflection after stalls.
If this is right
- Architecture search identifies variants that raise success rates on the three tested embodied tasks.
- High-scoring candidates can be rejected after manual inspection for data leaks.
- Rollout noise can mask true differences between architectures.
- Search can become trapped inside local edit basins with limited further improvement.
- Detailed episode logs produce only partial episode-level credit assignment.
Where Pith is reading between the lines
- The same search loop could be applied to agent designs that include learned internal modules rather than fixed components.
- Reducing rollout variance through more episodes or better simulators would likely increase the reliability of the discovered gains.
- Transferring the resulting architectures from simulation to physical robots would test whether the measured improvements survive domain shift.
Load-bearing premise
Simulator rollouts supply sufficiently reliable optimization signals for the search to identify better architectures despite rollout noise and local edit basins.
What would settle it
Running the same search procedure on a fresh set of embodied tasks and finding that no searched architecture improves success rate over the original hand-designed baselines on held-out episodes.
Figures

read the original abstract
Embodied agents are typically built as hand-designed compositions of perception, memory, planning, and action modules. This modularity exposes a large architectural design space, but current systems still rely on researcher intuition to choose where information is stored, how observations are processed, and how model calls are connected. Agent Architecture Search (AAS) automates such design for text-domain agents, but has not been systematically evaluated on perceptual embodied agents through simulator rollouts. We study this transfer. We introduce AgentCanvas, a typed-graph runtime that hosts embodied executors as editable node-and-wire programs with simulator-aware execution and episode-level logs, and KDLoop, a coding-agent search procedure that cycles through proposal, critique, experiment, and distillation, with triggered reflection after stalls. We evaluate three AAS variants across four embodied executors spanning vision-language navigation, embodied question answering, and language-conditioned manipulation. The resulting 3x4 matrix shows that architecture-level search can produce deployable and directional success-rate gains on embodied tasks, while one apparent high-scoring candidate is rejected as leak-bearing. At the same time, the experiments expose constraints that are muted in text-domain AAS: optimization signals can be masked by rollout noise, search can become trapped in local edit basins, and episode-level credit assignment only partially emerges even when detailed logs are available. These results characterize both the promise and the current limits of automated architecture search for embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentCanvas, a typed-graph runtime for hosting embodied executors as editable node-and-wire programs with simulator-aware execution, and KDLoop, a coding-agent search procedure cycling through proposal, critique, experiment, and distillation. It evaluates three AAS variants across four embodied executors (vision-language navigation, embodied QA, language-conditioned manipulation), reporting in a 3x4 matrix that architecture-level search yields deployable directional success-rate gains, while rejecting one high-scoring candidate for a leak and noting constraints from rollout noise, local edit basins, and partial episode-level credit assignment.
Significance. If the directional gains hold under more reliable signals, the work provides new tooling (AgentCanvas, KDLoop) and the first systematic transfer of AAS to perceptual embodied agents via simulator rollouts, characterizing both promise and limits that are muted in text-domain settings.
major comments (1)
- [Abstract] Abstract: the claim that architecture-level search produces 'deployable and directional success-rate gains' rests on the 3x4 matrix, yet the same paragraph states that 'optimization signals can be masked by rollout noise' and 'search can become trapped in local edit basins'; these acknowledged conditions directly threaten whether observed gains reflect architecture superiority rather than noise artifacts, requiring explicit quantification of signal reliability or additional controls.
minor comments (1)
- [Abstract] The abstract notes that 'episode-level credit assignment only partially emerges even when detailed logs are available' but provides no measurement details or comparison to text-domain AAS.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address it directly below and will revise the manuscript accordingly to better qualify our claims in light of the acknowledged experimental constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that architecture-level search produces 'deployable and directional success-rate gains' rests on the 3x4 matrix, yet the same paragraph states that 'optimization signals can be masked by rollout noise' and 'search can become trapped in local edit basins'; these acknowledged conditions directly threaten whether observed gains reflect architecture superiority rather than noise artifacts, requiring explicit quantification of signal reliability or additional controls.
Authors: We agree that the abstract must more explicitly reconcile the reported directional gains with the documented effects of rollout noise and local edit basins. The 3x4 matrix demonstrates that, across three AAS variants and four embodied executors, the search procedure consistently identifies architectures that either match or exceed the hand-designed baselines in final success rate, with one high-scoring candidate correctly rejected after leak detection. These outcomes are directional rather than absolute, and the paper already frames them as subject to simulator noise. To strengthen the presentation, we will revise the abstract to state that the gains are 'directional under the evaluated conditions' and will insert a short clause noting the observed variance in repeated rollouts (computed from the existing episode logs). This provides the requested quantification of signal reliability without requiring new experiments, while preserving the characterization of both promise and limits. revision: yes
Circularity Check
No circularity: purely experimental tooling and evaluation
full rationale
The manuscript introduces AgentCanvas (typed-graph runtime) and KDLoop (search procedure) then reports a 3x4 matrix of simulator-based success rates for three AAS variants on four embodied executors. No equations, fitted parameters, or first-principles derivations appear; the reported directional gains are direct empirical measurements from rollouts, not quantities that reduce to their own inputs by construction. Prior AAS work is cited only as background motivation and is not used to justify uniqueness theorems or load-bearing premises within the present results. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
AgentCanvas
no independent evidence
-
KDLoop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel. Vision-and-language navigation: Interpreting visually-grounded naviga- tion instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018
2018
-
[2]
G. Zhou, Y . Hong, and Q. Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[3]
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . Wong. Mapgpt: Map-guided prompting with adaptive path planning for vision-and-language navigation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9796–9810, 2024
2024
-
[4]
A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra. Embodied question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1–10, 2018
2018
- [5]
- [6]
-
[7]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
2023
-
[8]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
S. Hu, C. Lu, and J. Clune. Automated design of agentic systems. InInternational Conference on Learning Representations, 2025
2025
-
[10]
Zhang, J
J. Zhang, J. Xiang, Z. Yu, F. Teng, X. Chen, J. Chen, M. Zhuge, X. Cheng, S. Hong, J. Wang, et al. Aflow: Automating agentic workflow generation. InInternational Conference on Learn- ing Representations, 2025
2025
-
[11]
Shang, Y
Y . Shang, Y . Li, K. Zhao, L. Ma, J. Liu, F. Xu, and Y . Li. Agentsquare: Automatic llm agent search in modular design space. InInternational Conference on Learning Representations, 2025
2025
- [12]
-
[13]
X. Shi, Z. Li, W. Lyu, J. Xia, F. Dayoub, Y . Qiao, and Q. Wu. Smartway: Enhanced waypoint prediction and backtracking for zero-shot vision-and-language navigation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025
2025
- [14]
-
[15]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020. 9
2020
-
[16]
Brohan, Y
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, et al. Do as i can, not as i say: Grounding language in robotic affordances. In Conference on robot learning, pages 287–318. PMLR, 2023
2023
-
[17]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation.arXiv preprint arXiv:2409.01652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
-
[19]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. Palm-e: An embodied multimodal language model, 2023. URLhttps://arxiv.org/abs/2303.03378
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Man- junath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[22]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2024. URLhttps://arxiv. o...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandku- mar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36: 8634–8652, 2023
2023
-
[26]
Zhuge, W
M. Zhuge, W. Wang, L. Kirsch, F. Faccio, D. Khizbullin, and J. Schmidhuber. Gptswarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning, 2024
2024
-
[27]
Cheng, A
C.-A. Cheng, A. Nie, and A. Swaminathan. Trace is the next autodiff: Generative optimization with rich feedback, execution traces, and llms.Advances in Neural Information Processing Systems, 37:71596–71642, 2024
2024
-
[28]
Y . Wang, S. Liu, J. Fang, and Z. Meng. Evoagentx: An automated framework for evolving agentic workflows. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 643–655, 2025. 10
2025
-
[29]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. Vardhamanan, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, M. Zaharia, and C. Potts. Dspy: Compiling declarative language model calls into self-improving pipelines, 2023. URLhttps://arxiv. org/abs/2310.03714
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
C. Yang, X. Wang, Y . Lu, H. Liu, Q. V . Le, D. Zhou, and X. Chen. Large language models as optimizers. InInternational Conference on Learning Representations, 2024
2024
-
[31]
TextGrad: Automatic "Differentiation" via Text
M. Yuksekgonul, F. Bianchi, J. Boen, S. Liu, Z. Huang, C. Guestrin, and J. Zou. Textgrad: Automatic” differentiation” via text.arXiv preprint arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [32]
-
[33]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe- agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[34]
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, et al. Openhands: An open platform for ai software developers as generalist agents. InInternational Conference on Learning Representations, volume 2025, 2025
2025
-
[35]
Claude code, 2025.https://www.anthropic.com/product/claude-code
Anthropic. Claude code, 2025.https://www.anthropic.com/product/claude-code
2025
-
[36]
LangGraph, 2024.https://github.com/langchain-ai/langgraph
LangChain. LangGraph, 2024.https://github.com/langchain-ai/langgraph
2024
-
[37]
Move the stop decision after the landmark check
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024. 11 Appendix Contents •Appendix A – AgentCanvas.The typed-graph Executor substrate (§A). •Appendix B – Per-Cell Search Trajectories.Full sea...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.