ComplexMimic: Human-Scene Interaction Imitation in Complex 3D Environments
Pith reviewed 2026-07-03 16:04 UTC · model grok-4.3
The pith
A dual-expert framework with difficulty-aware distillation reconstructs diverse human-scene interactions from imperfect motion data in complex 3D environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
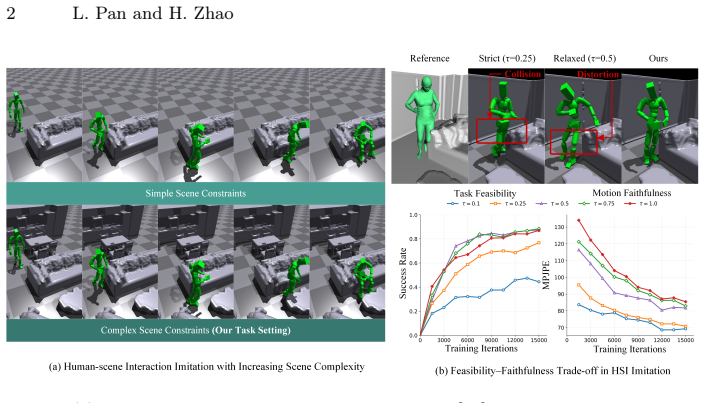
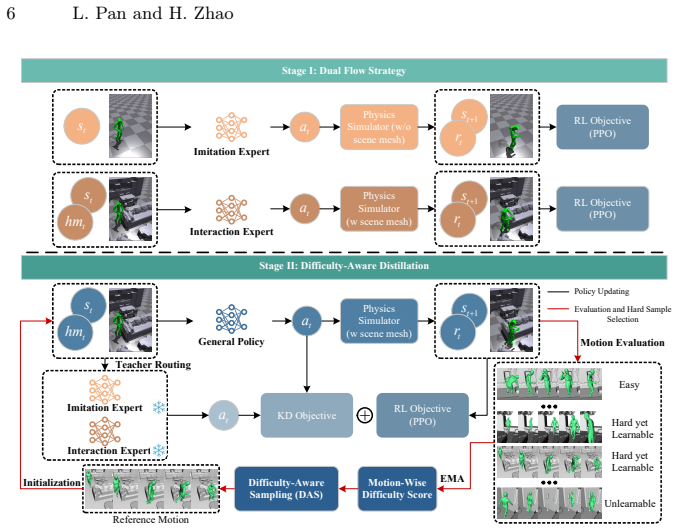
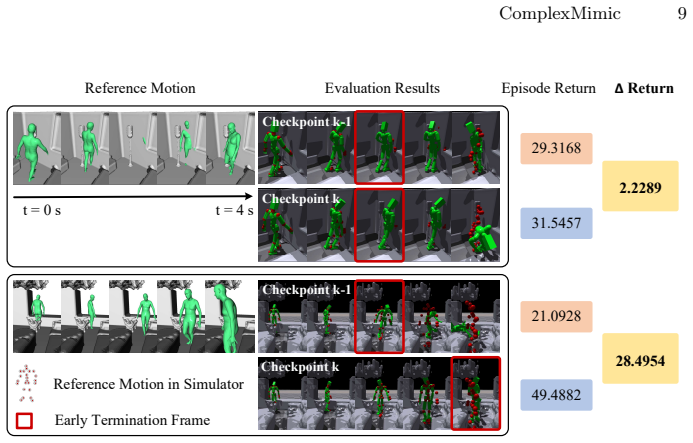
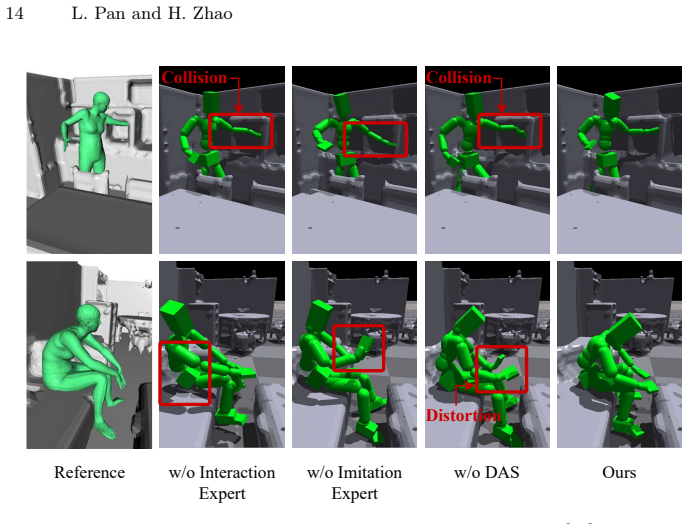
The authors claim that ComplexMimic reconstructs diverse human-scene interactions in complex environments by interpreting imperfect MoCap data through a Dual Flow Strategy that maintains an imitation expert for accurate motion tracking alongside an interaction expert for collision-aware adaptation, followed by difficulty-aware distillation that adaptively weights supervision toward hard-yet-learnable trajectories using failure statistics and learning progress signals; this combination outperforms prior state-of-the-art methods across three benchmark datasets.
What carries the argument
Dual Flow Strategy consisting of an imitation expert and an interaction expert, combined via difficulty-aware distillation that prioritizes challenging behaviors.
If this is right
- Imitation learning becomes feasible in cluttered rather than simplified scenes without extra scene-specific engineering.
- Training can leverage existing imperfect MoCap datasets more effectively than uniform multi-expert distillation.
- The resulting policies produce both higher motion accuracy and better physical plausibility on standard benchmarks.
- Embodied agents gain access to a wider range of natural interaction behaviors in realistic 3D settings.
Where Pith is reading between the lines
- The same separation of tracking and adaptation experts might transfer to other imitation domains that face noisy demonstration data, such as robot manipulation.
- If the distillation weighting proves stable, it could reduce the need for manual curriculum design when scaling to larger scene collections.
- Success here suggests that explicit difficulty signals from failure counts could be tested as a general regularizer in multi-task physics simulation.
- Deployment in real robots would still require checking whether the learned collision avoidance survives sim-to-real gaps not addressed in the benchmarks.
Load-bearing premise
Imperfect motion-capture recordings contain enough recoverable information to support both precise motion tracking and collision-aware physical adaptation at the same time in complex scenes.
What would settle it
Running the method on a held-out collection of complex scenes with deliberately degraded MoCap data and finding that it produces either unnatural motions or frequent collisions while matching or falling below baseline performance.
Figures


read the original abstract
Physics-based Human-Scene Interaction (HSI) imitation learning is crucial for embodied intelligence as it bridges the gap between kinematic 3D motions and real-world dynamics. However, most existing methods focus on simplified scene settings, leaving complex environments largely unexplored, which limits their applicability in real-world scenarios. In this paper, we focus on HSI mimicry in complex environments. Under this complex setting, we observe an inherent trade-off between successfully performing interaction and maintaining natural, physically plausible motions. To address this challenge, we propose ComplexMimic, a framework that reconstructs diverse HSI by interpreting imperfect MoCap data. First, we introduce a Dual Flow Strategy, which learns two complementary experts: an imitation expert for accurate motion tracking and an interaction expert for collision-aware adaptation in complex scenes. Second, naive multi-expert distillation, which treats all experts equally, often under-samples challenging behaviors, limiting effective learning. To mitigate this issue, we propose a difficulty-aware distillation strategy that adaptively weights supervision and prioritizes hard-yet-learnable trajectories guided by failure statistics and learning progress signals. Extensive experiments on three benchmark datasets demonstrate that our approach outperforms current state-of-the-art methods. Our implementation is available at https://github.com/LuPan23/ComplexMimic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ComplexMimic, a framework for physics-based human-scene interaction (HSI) imitation learning in complex 3D environments. It introduces a Dual Flow Strategy consisting of an imitation expert for motion tracking and an interaction expert for collision-aware adaptation, together with a difficulty-aware distillation method that weights supervision based on failure statistics and learning progress. The central claim is that this approach reconstructs diverse HSI from imperfect MoCap data and outperforms current state-of-the-art methods on three benchmark datasets.
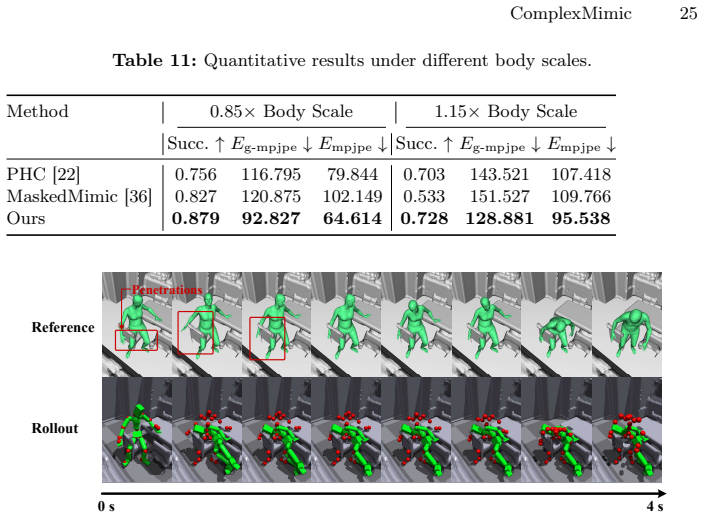
Significance. If the empirical claims of outperformance hold with rigorous quantitative support, the work would address an important gap in handling complex scenes for embodied HSI, moving beyond simplified settings. The dual-expert and adaptive-distillation ideas are conceptually plausible for managing the noted trade-off between interaction success and motion plausibility. However, the provided text supplies no metrics, ablations, or dataset details, so significance cannot be assessed.
major comments (1)
- [Abstract] Abstract: The assertion that the method 'outperforms current state-of-the-art methods' on three benchmark datasets is unsupported by any quantitative metrics, ablation results, error bars, dataset descriptions, or implementation details. This absence makes the central empirical claim unverifiable from the manuscript.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the method 'outperforms current state-of-the-art methods' on three benchmark datasets is unsupported by any quantitative metrics, ablation results, error bars, dataset descriptions, or implementation details. This absence makes the central empirical claim unverifiable from the manuscript.
Authors: We agree that the abstract would benefit from explicit quantitative support to make the central claim immediately verifiable. The full manuscript contains these elements in the Experiments section (including performance tables on three benchmarks, ablation studies, error analysis, dataset details, and implementation information). We will revise the abstract to incorporate key quantitative highlights from those results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present an empirical framework (Dual Flow Strategy with imitation and interaction experts, plus difficulty-aware distillation) whose central claims rest on outperformance across three external benchmark datasets. No equations, parameter-fitting steps, self-citations, or uniqueness theorems are referenced that would allow any result to reduce to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Collorone, L., Gioia, M., Pappa, M., Leoni, P., Ficarra, G., Litany, O., Spinelli, I., Galasso, F.: Monster: a unified model for motion, scene, text retrieval. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 10940– 10949 (2025)
2025
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating di- verse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5152–5161 (2022)
2022
-
[3]
In: European Conference on Computer Vision
Guo, C., Zuo, X., Wang, S., Cheng, L.: Tm2t: Stochastic and tokenized model- ing for the reciprocal generation of 3d human motions and texts. In: European Conference on Computer Vision. pp. 580–597. Springer (2022)
2022
-
[4]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Hassan, M., Ceylan, D., Villegas, R., Saito, J., Yang, J., Zhou, Y., Black, M.J.: Stochastic scene-aware motion prediction. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 11374–11384 (2021)
2021
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hassan, M., Choutas, V., Tzionas, D., Black, M.J.: Resolving 3d human pose ambi- guities with 3d scene constraints. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2282–2292 (2019)
2019
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hassan, M., Ghosh, P., Tesch, J., Tzionas, D., Black, M.J.: Populating 3d scenes by learning human-scene interaction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14708–14718 (2021)
2021
-
[7]
In: ACM SIGGRAPH 2023 Conference Pro- ceedings
Hassan, M., Guo, Y., Wang, T., Black, M., Fidler, S., Peng, X.B.: Synthesizing physical character-scene interactions. In: ACM SIGGRAPH 2023 Conference Pro- ceedings. pp. 1–9 (2023)
2023
-
[8]
Available: https://arxiv.org/abs/2502.01143
He, T., Gao, J., Xiao, W., Zhang, Y., Wang, Z., Wang, J., Luo, Z., He, G., Soban- bab, N., Pan, C., et al.: Asap: Aligning simulation and real-world physics for learn- ing agile humanoid whole-body skills. arXiv preprint arXiv:2502.01143 (2025)
-
[9]
Omnih2o: Universal and dexterous human- to-humanoid whole-body teleoperation and learning,
He,T.,Luo,Z.,He,X.,Xiao,W.,Zhang,C.,Zhang,W.,Kitani,K.,Liu,C.,Shi,G.: Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. arXiv preprint arXiv:2406.08858 (2024)
-
[10]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015) 16 L. Pan and H. Zhao
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, C.H.P., Yi, H., Höschle, M., Safroshkin, M., Alexiadis, T., Polikovsky, S., Scharstein, D., Black, M.J.: Capturing and inferring dense full-body human-scene contact. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13274–13285 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Hwang,I.,Zhou,B.,Kim,Y.M.,Wang,J.,Guo,C.:Scenemi:Motionin-betweening for modeling human-scene interaction. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 6034–6045 (2025)
2025
-
[14]
Neural computation3(1), 79–87 (1991)
Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural computation3(1), 79–87 (1991)
1991
-
[15]
In: SIGGRAPH Asia 2024 Conference Papers
Jiang, N., He, Z., Wang, Z., Li, H., Chen, Y., Huang, S., Zhu, Y.: Autonomous character-scene interaction synthesis from text instruction. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, N., Zhang, Z., Li, H., Ma, X., Wang, Z., Chen, Y., Liu, T., Zhu, Y., Huang, S.: Scaling up dynamic human-scene interaction modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1737– 1747 (2024)
2024
-
[17]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Liao, Q., Truong, T.E., Huang, X., Gao, Y., Tevet, G., Sreenath, K., Liu, C.K.: Beyondmimic: From motion tracking to versatile humanoid control via guided dif- fusion. arXiv preprint arXiv:2508.08241 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
In: European Conference on Computer Vision
Liu, X., Hou, H., Yang, Y., Li, Y.L., Lu, C.: Revisit human-scene interaction via space occupancy. In: European Conference on Computer Vision. pp. 1–19. Springer (2024)
2024
-
[20]
arXiv preprint arXiv:2412.17730 (2024)
Liu, Y., Yang, B., Zhong, L., Wang, H., Yi, L.: Mimicking-bench: A benchmark for generalizable humanoid-scene interaction learning via human mimicking. arXiv preprint arXiv:2412.17730 (2024)
-
[21]
Liu, Z., Ge, J., Xiong, M., Gu, J., Tang, B., Jing, W., Chen, S.: It takes two: Learning interactive whole-body control between humanoid robots (2025)
2025
-
[22]
Luo, Z., Cao, J., Kitani, K., Xu, W., et al.: Perpetual humanoid control for real- timesimulatedavatars.In:ProceedingsoftheIEEE/CVFInternationalConference on Computer Vision. pp. 10895–10904 (2023)
2023
-
[23]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al.: Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
In: 2024 International Conference on 3D Vision (3DV)
Pan, L., Wang, J., Huang, B., Zhang, J., Wang, H., Tang, X., Wang, Y.: Syn- thesizing physically plausible human motions in 3d scenes. In: 2024 International Conference on 3D Vision (3DV). pp. 1498–1507. IEEE (2024)
2024
-
[25]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Pan, L., Yang, Z., Dou, Z., Wang, W., Huang, B., Dai, B., Komura, T., Wang, J.: Tokenhsi: Unified synthesis of physical human-scene interactions through task tokenization. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5379–5391 (2025)
2025
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single im- age. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10975–10985 (2019) ComplexMimic 17
2019
-
[27]
ACM Transactions On Graphics (TOG)37(4), 1–14 (2018)
Peng, X.B., Abbeel, P., Levine, S., Van de Panne, M.: Deepmimic: Example-guided deep reinforcement learning of physics-based character skills. ACM Transactions On Graphics (TOG)37(4), 1–14 (2018)
2018
-
[28]
Peng, X.B., Guo, Y., Halper, L., Levine, S., Fidler, S.: Ase: Large-scale reusable adversarialskillembeddingsforphysicallysimulatedcharacters.ACMTransactions On Graphics (TOG)41(4), 1–17 (2022)
2022
-
[29]
ACM Transactions on Graphics (ToG)40(4), 1–20 (2021)
Peng, X.B., Ma, Z., Abbeel, P., Levine, S., Kanazawa, A.: Amp: Adversarial motion priors for stylized physics-based character control. ACM Transactions on Graphics (ToG)40(4), 1–20 (2021)
2021
-
[30]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman, J., Moritz, P., Levine, S., Jordan, M., Abbeel, P.: High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
arXiv preprint arXiv:2508.07842 (2025)
Shen, Y., Liu, H., Zhang, L., Liu, P., Xia, R., Yao, T., Feng, T.: Detach: Cross- domain learning for long-horizon tasks via mixture of disentangled experts. arXiv preprint arXiv:2508.07842 (2025)
-
[33]
In: nternational conference on machine learning
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: nternational conference on machine learning. pp. 2256–2265 (2015)
2015
-
[34]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[36]
ACM Trans- actions On Graphics (TOG)43(6), 1–21 (2024)
Tessler, C., Guo, Y., Nabati, O., Chechik, G., Peng, X.B.: Maskedmimic: Unified physics-based character control through masked motion inpainting. ACM Trans- actions On Graphics (TOG)43(6), 1–21 (2024)
2024
-
[37]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. arXiv preprint arXiv:2209.14916 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Wang, W., Pan, L., Dou, Z., Mei, J., Liao, Z., Lou, Y., Wu, Y., Yang, L., Wang, J., Komura, T.: Sims: Simulating stylized human-scene interactions with retrieval- augmented script generation. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 14117–14127 (2025)
2025
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Y., Zhao, Q., Yu, R., Tsui, H.W., Zeng, A., Lin, J., Luo, Z., Yu, J., Li, X., Chen, Q., et al.: Skillmimic: Learning basketball interaction skills from demon- strations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17540–17549 (2025)
2025
-
[40]
arXiv preprint arXiv:2506.12779 (2025)
Wang, Y., Yang, M., Ding, Z., Zhang, Y., Zeng, W., Xu, X., Jiang, H., Lu, Z.: From experts to a generalist: Toward general whole-body control for humanoid robots. arXiv preprint arXiv:2506.12779 (2025)
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang,Z.,Chen,Y.,Jia,B.,Li,P.,Zhang,J.,Zhang,J.,Liu,T.,Zhu,Y.,Liang,W., Huang, S.: Move as you say interact as you can: Language-guided human motion generation with scene affordance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 433–444 (2024)
2024
-
[42]
Advances in Neural Informa- tion Processing Systems35, 14959–14971 (2022)
Wang, Z., Chen, Y., Liu, T., Zhu, Y., Liang, W., Huang, S.: Humanise: Language- conditioned human motion generation in 3d scenes. Advances in Neural Informa- tion Processing Systems35, 14959–14971 (2022)
2022
-
[43]
arXiv preprint arXiv:2309.07918 (2023) 18 L
Xiao, Z., Wang, T., Wang, J., Cao, J., Zhang, W., Dai, B., Lin, D., Pang, J.: Unified human-scene interaction via prompted chain-of-contacts. arXiv preprint arXiv:2309.07918 (2023) 18 L. Pan and H. Zhao
-
[44]
ACM Transactions on Graphics (TOG)44(6), 1–14 (2025)
Xu, P., Wu, Z., Wang, R., Sarukkai, V., Fatahalian, K., Karamouzas, I., Zordan, V., Liu, C.K.: Learning to ball: Composing policies for long-horizon basketball moves. ACM Transactions on Graphics (TOG)44(6), 1–14 (2025)
2025
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, S., Ling, H.Y., Wang, Y.X., Gui, L.Y.: Intermimic: Towards universal whole- body control for physics-based human-object interactions. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12266–12277 (2025)
2025
-
[46]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Yu,R.,Wang,Y.,Zhao,Q.,Tsui,H.W.,Wang,J.,Tan,P.,Chen,Q.:Skillmimic-v2: Learning robust and generalizable interaction skills from sparse and noisy demon- strations. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–11 (2025)
2025
-
[47]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, J., Fan, H., Yang, Y.: Energymogen: Compositional human motion gen- eration with energy-based diffusion model in latent space. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17592–17602 (2025)
2025
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, J., Fan, H., Yang, Y.: Towards decompositional human motion generation with energy-based diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 30650–30660 (2026)
2026
-
[49]
In: Proceedings of theIEEE/CVF conference on computer vision and pattern recognition
Zhang, J., Zhang, Y., Cun, X., Zhang, Y., Zhao, H., Lu, H., Shen, X., Shan, Y.: Generating human motion from textual descriptions with discrete representa- tions. In: Proceedings of theIEEE/CVF conference on computer vision and pattern recognition. pp. 14730–14740 (2023)
2023
-
[50]
IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024)
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondiffuse: Text-driven human motion generation with diffusion model. IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024)
2024
-
[51]
In: European Conference on Computer Vision (ECCV) (2022)
Zhao, K., Wang, S., Zhang, Y., Beeler, T., Tang, S.: Compositional human-scene interaction synthesis with semantic control. In: European Conference on Computer Vision (ECCV) (2022)
2022
-
[52]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Zhao, K., Zhang, Y., Wang, S., Beeler, T., Tang, S.: Synthesizing diverse human motions in 3d indoor scenes. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 14738–14749 (2023)
2023
-
[53]
Zheng, Y., Yang, Y., Mo, K., Li, J., Yu, T., Liu, Y., Liu, C.K., Guibas, L.J.: Gimo: Gaze-informed human motion prediction in context. In: European Conference on Computer Vision. pp. 676–694. Springer (2022) ComplexMimic 19 Supplementary Material In this supplementary material, we present: –Sec. A: Additional ablation results on LINGO [15] and GIMO [53]. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.