Uncertainty-Aware End-to-End Co-Design of Neural Network Processors: From Training and Mapping to Fabrication
Pith reviewed 2026-06-28 06:53 UTC · model grok-4.3
The pith
A monotone co-design framework composes neural network training, mapping, fabrication and allocation blocks while treating uncertainty as an explicit optimizable resource called Confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
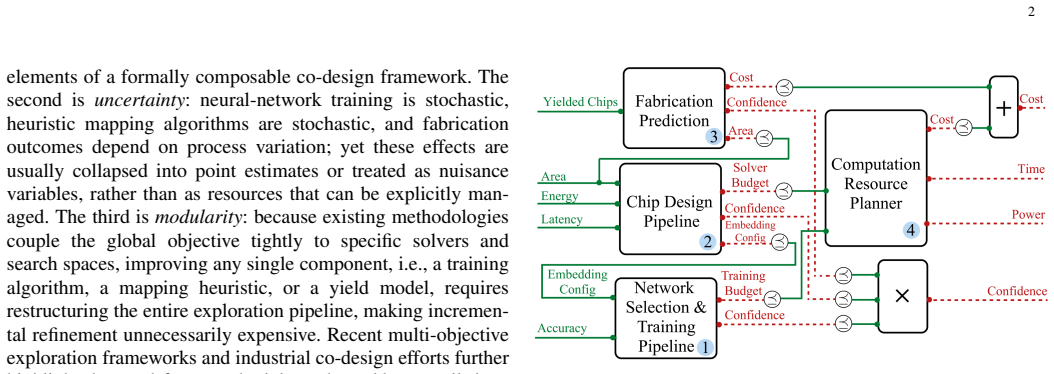
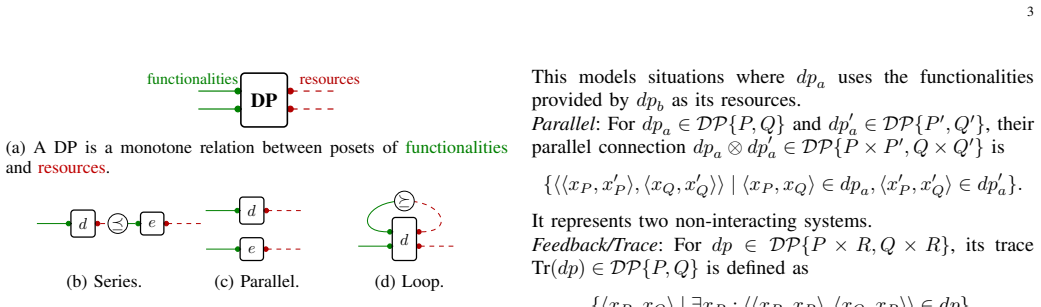
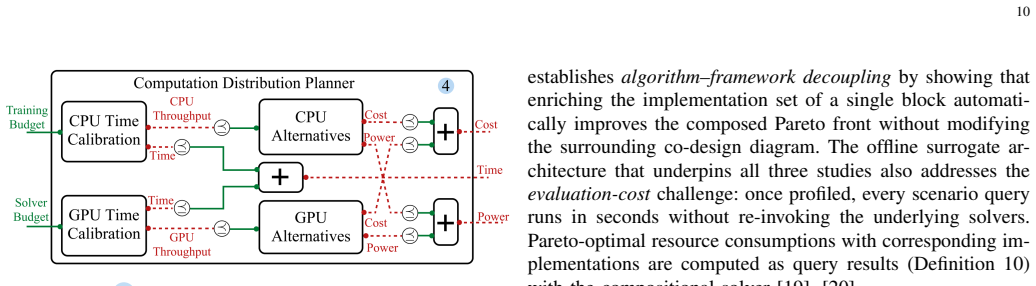
The central claim is that four design blocks spanning network training, chip mapping, wafer-level fabrication, and compute resource allocation can be composed via functionality-resource interfaces under monotone co-design theory. This setup allows any block to be refined independently. Uncertainty is addressed by treating Confidence, the inverse of success probability, as an explicit resource that can be optimized alongside traditional ones, with validation through three case studies showing Pareto recovery and propagation of improvements.
What carries the argument
Monotone co-design theory applied to functionality-resource interfaces across the four blocks, with Confidence as the inverse of success probability serving as an optimizable uncertainty metric.
If this is right
- Refining a single block automatically propagates improvements to the global Pareto front without altering the co-design structure.
- Confidence functions as a continuously tunable parameter rather than a post-design check.
- The framework recovers Pareto-optimal implementations for different application scenarios.
- All blocks remain composable even when individual implementations are updated.
Where Pith is reading between the lines
- The approach may generalize to co-design problems in other domains like software systems or mechanical engineering.
- It suggests that design teams could work on blocks separately while still achieving system-wide optimality.
- One could test the framework by adding a fifth block for post-fabrication testing.
Load-bearing premise
The design blocks interact solely through functionality and resource specifications under monotone co-design theory, ensuring that local refinements preserve global optimality.
What would settle it
Finding a case where updating one block's implementations worsens or fails to improve the overall Pareto front without changing the interface definitions.
Figures



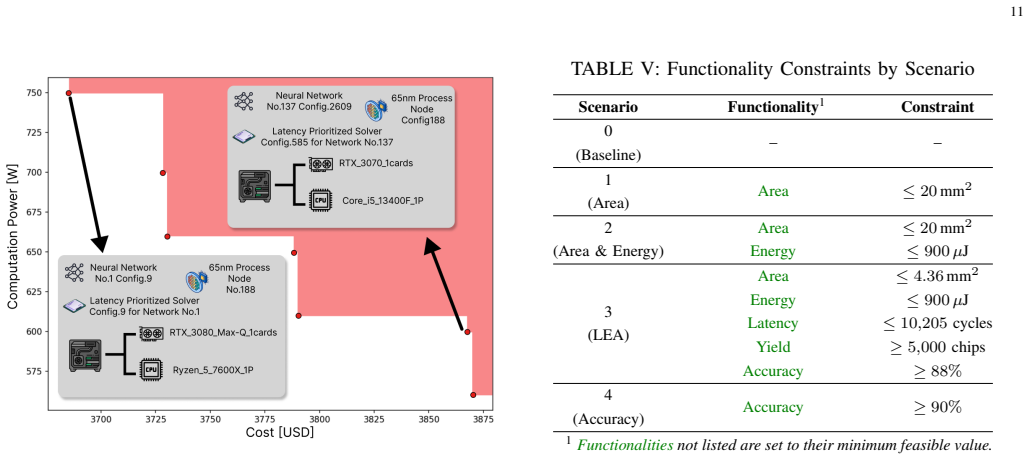
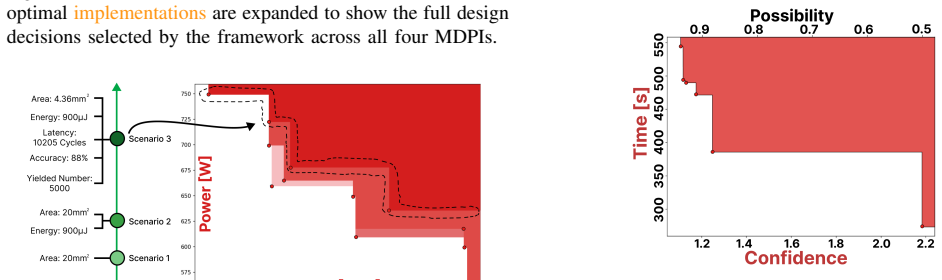
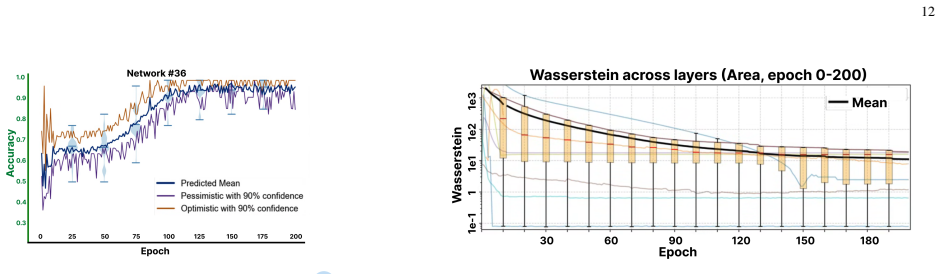
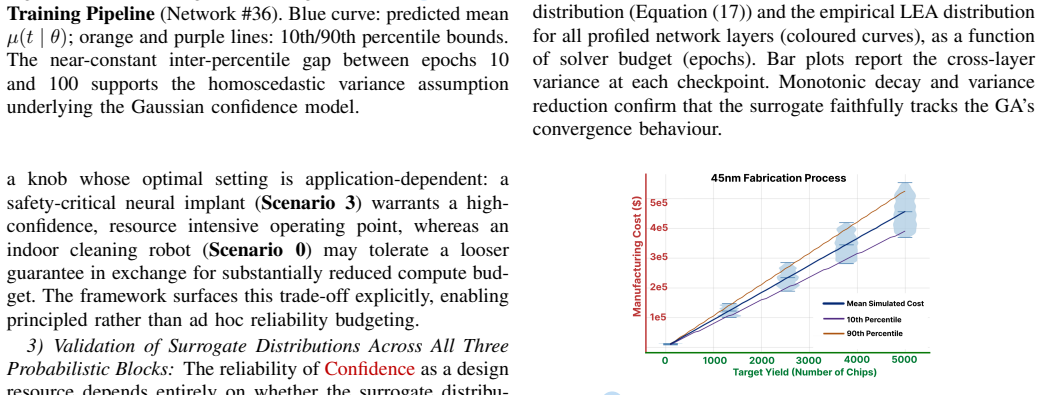

read the original abstract
Designing a neural network processor is an end-to-end co-design problem: network architecture and training budget determine the inference workload; hardware mapping decisions determine chip area, latency, and energy; and these characteristics govern fabrication yield and manufacturing cost. In practice, these decisions are made in separate stages, and existing co-design methodologies are tightly coupled to specific algorithms, making it difficult to improve one component without reworking the entire pipeline. This paper presents a unified framework, grounded in monotone co-design theory, that composes four interoperable design blocks spanning network training, chip mapping, wafer-level fabrication, and compute resource allocation. Each block exposes only a functionality-resource interface to the rest of the system, so any block can be refined without structural changes elsewhere. A central contribution is the treatment of uncertainty: rather than collapsing stochastic outcomes into point estimates, the framework introduces Confidence, the inverse of success probability, as an explicit and optimizable resource alongside cost, time, and power. Three case studies validate the approach. The first recovers Pareto-optimal implementations across heterogeneous application scenarios. The second confirms that Confidence functions as a continuously tunable design knob rather than a post-hoc diagnostic. The third demonstrates that improving a single block's implementation set automatically propagates to the global Pareto front, without modifying the co-design diagram.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a unified, modular framework for end-to-end co-design of neural network processors grounded in monotone co-design theory. It composes four interoperable blocks (training, mapping, fabrication, allocation) that expose only functionality-resource interfaces, allowing any block to be refined without diagram changes. A key innovation is treating uncertainty explicitly via a new resource called Confidence (inverse of success probability) alongside cost, time, and power. Three case studies are presented: recovery of Pareto-optimal implementations, validation of Confidence as a tunable knob, and automatic propagation of single-block improvements to the global Pareto front.
Significance. If the monotonicity and continuity conditions hold for all interfaces (including the new Confidence mappings), the framework would enable genuinely modular co-design pipelines in which local refinements automatically improve the global front without re-engineering the composition. This addresses a practical pain point in hardware-software co-design where stages are currently tightly coupled. The explicit handling of uncertainty as an optimizable resource, rather than a post-hoc metric, is a substantive conceptual contribution if the underlying theory applies without additional assumptions.
major comments (2)
- [Abstract (and presumably §3–4 describing the blocks)] The central claim rests on the four blocks exposing strictly monotone functionality-to-resource maps (including Confidence) so that the monotone co-design composition theorem guarantees Pareto-front improvement on refinement. The abstract asserts interoperability via these interfaces but provides no explicit verification that the stochastic-to-Confidence mapping in the fabrication block or the training-budget-to-Confidence mapping satisfies the required monotonicity and continuity conditions. If any interface fails monotonicity, refinement can produce non-monotonic jumps that invalidate automatic propagation.
- [Abstract (case study 3)] Case study 3 claims that improving a single block's implementation set automatically propagates to the global Pareto front without modifying the co-design diagram. No quantitative evidence (e.g., before/after front distances, number of new points, or sensitivity to the refinement) is referenced in the abstract; without such data it is impossible to assess whether the propagation is a consequence of the theory or an artifact of the specific instances chosen.
minor comments (2)
- [Abstract] The definition of Confidence as 'the inverse of success probability' should be stated with an explicit formula and domain (e.g., whether it is 1/p or -log p) to avoid ambiguity when composing with other resources.
- [Abstract] The abstract refers to 'heterogeneous application scenarios' in case study 1 without naming the workloads or hardware targets; adding one sentence identifying them would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where explicit verification and quantitative referencing can strengthen the presentation of the monotone co-design framework and its case studies. We respond point by point below and will incorporate revisions to address the concerns.
read point-by-point responses
-
Referee: [Abstract (and presumably §3–4 describing the blocks)] The central claim rests on the four blocks exposing strictly monotone functionality-to-resource maps (including Confidence) so that the monotone co-design composition theorem guarantees Pareto-front improvement on refinement. The abstract asserts interoperability via these interfaces but provides no explicit verification that the stochastic-to-Confidence mapping in the fabrication block or the training-budget-to-Confidence mapping satisfies the required monotonicity and continuity conditions. If any interface fails monotonicity, refinement can produce non-monotonic jumps that invalidate automatic propagation.
Authors: We agree that explicit verification of monotonicity and continuity for the Confidence mappings is necessary to fully substantiate the central claim. In the manuscript the interfaces are defined such that monotonicity holds by construction (higher training budget yields strictly higher achievable Confidence; fabrication process refinements monotonically increase Confidence). Continuity follows from the underlying continuous performance models. To make this rigorous and address the concern directly, we will add a dedicated subsection (or appendix) providing formal verification or numerical confirmation that all four blocks, including the stochastic-to-Confidence mappings, satisfy the required conditions. This will confirm that the composition theorem applies without additional assumptions. revision: yes
-
Referee: [Abstract (case study 3)] Case study 3 claims that improving a single block's implementation set automatically propagates to the global Pareto front without modifying the co-design diagram. No quantitative evidence (e.g., before/after front distances, number of new points, or sensitivity to the refinement) is referenced in the abstract; without such data it is impossible to assess whether the propagation is a consequence of the theory or an artifact of the specific instances chosen.
Authors: The full manuscript already contains quantitative results for case study 3, including before/after Pareto-front comparisons that demonstrate automatic propagation via added points and front improvement. We acknowledge, however, that the abstract does not reference these metrics. We will revise the abstract to include concise quantitative indicators (e.g., number of new Pareto points and front-distance reduction) so that the claim is supported by explicit data and readers can evaluate whether the outcome follows from the monotone theory. revision: yes
Circularity Check
No circularity; framework applies external monotone co-design theory without self-referential reductions
full rationale
The paper composes four design blocks via functionality-resource interfaces under monotone co-design theory, treating Confidence as an explicit resource. No equations, fitted parameters, or derivations are presented that reduce by construction to inputs, self-citations, or ansatzes from the authors' prior work. The central claims rest on the interoperability properties of the cited theory and empirical case studies rather than internal redefinition or forced predictions, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monotone co-design theory allows composition of design blocks via functionality-resource interfaces without structural changes to the overall diagram.
invented entities (1)
-
Confidence (defined as inverse of success probability)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Legup: high-level synthesis for fpga-based processor/accelerator systems,
A. Canis, J. Choi, M. Aldham, V . Zhang, A. Kammoona, J. H. An- derson, S. Brown, and T. Czajkowski, “Legup: high-level synthesis for fpga-based processor/accelerator systems,” inProceedings of the 19th ACM/SIGDA international symposium on Field programmable gate arrays, 2011, pp. 33–36
2011
-
[2]
Flexlearn: fast and highly efficient brain simulations using flexible on-chip learning,
E. Baek, H. Lee, Y . Kim, and J. Kim, “Flexlearn: fast and highly efficient brain simulations using flexible on-chip learning,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, 2019, pp. 304–318
2019
-
[3]
Zcomp: Reducing dnn cross-layer memory footprint using vector extensions,
B. Akin, Z. A. Chishti, and A. R. Alameldeen, “Zcomp: Reducing dnn cross-layer memory footprint using vector extensions,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microar- chitecture, 2019, pp. 126–138
2019
-
[4]
Y . Fu, Z. Yu, Y . Zhang, and Y . Lin, “Auto-agent-distiller: Towards efficient deep reinforcement learning agents via neural architecture search,”arXiv preprint arXiv:2012.13091, 2020
-
[5]
Autogan- distiller: Searching to compress generative adversarial networks,
Y . Fu, W. Chen, H. Wang, H. Li, Y . C. Lin, and Z. Wang, “Autogan- distiller: Searching to compress generative adversarial networks,”arXiv preprint arXiv:2006.08198, 2020
-
[6]
Mnasnet: Platform-aware neural architecture search for mobile,
M. Tan, B. Chen, R. Pang, V . Vasudevan, M. Sandler, A. Howard, and Q. V . Le, “Mnasnet: Platform-aware neural architecture search for mobile,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 2820–2828
2019
-
[7]
Searching for mobilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevanet al., “Searching for mobilenetv3,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 1314–1324
2019
-
[8]
Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search,
B. Wu, X. Dai, P. Zhang, Y . Wang, F. Sun, Y . Wu, Y . Tian, P. Vajda, Y . Jia, and K. Keutzer, “Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 10 734–10 742
2019
-
[9]
Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions,
A. Wan, X. Dai, P. Zhang, Z. He, Y . Tian, S. Xie, B. Wu, M. Yu, T. Xu, K. Chenet al., “Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 12 965–12 974
2020
-
[10]
DARTS: Differentiable Architecture Search
H. Liu, K. Simonyan, and Y . Yang, “Darts: Differentiable architecture search,”arXiv preprint arXiv:1806.09055, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Naas: Neural accelerator architecture search,
Y . Lin, M. Yang, and S. Han, “Naas: Neural accelerator architecture search,” in2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 2021, pp. 1051–1056
2021
-
[12]
Dance: Differ- entiable accelerator/network co-exploration,
K. Choi, D. Hong, H. Yoon, J. Yu, Y . Kim, and J. Lee, “Dance: Differ- entiable accelerator/network co-exploration,” in2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 2021, pp. 337–342
2021
-
[13]
Efficient design space exploration via statistical sampling and adaboost learning,
D. Li, S. Yao, Y .-H. Liu, S. Wang, and X.-H. Sun, “Efficient design space exploration via statistical sampling and adaboost learning,” in2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), 2016, pp. 1–6
2016
-
[14]
The gem5 simulator,
N. Binkert, B. Beckmann, G. Black, S. K. Reinhardt, A. Saidi, A. Basu, J. Hestness, D. R. Hower, T. Krishna, S. Sardashti, R. Sen, K. Sewell, M. Shoaib, N. Vaish, M. D. Hill, and D. A. Wood, “The gem5 simulator,” SIGARCH Comput. Archit. News, vol. 39, no. 2, p. 1–7, 2011
2011
-
[15]
Maestro: A data-centric approach to understand reuse, performance, and hardware cost of dnn mappings,
H. Kwon, P. Chatarasi, V . Sarkar, T. Krishna, M. Pellauer, and A. Parashar, “Maestro: A data-centric approach to understand reuse, performance, and hardware cost of dnn mappings,”IEEE Micro, vol. 40, no. 3, pp. 20–29, 2020
2020
-
[16]
Efficiently exploiting low activity factors to accelerate rtl simulation,
S. Beamer and D. Donofrio, “Efficiently exploiting low activity factors to accelerate rtl simulation,” in2020 57th ACM/IEEE Design Automation Conference (DAC), 2020, pp. 1–6
2020
-
[17]
Boom-explorer: Risc-v boom microarchitecture design space exploration framework,
C. Bai, Q. Sun, J. Zhai, Y . Ma, B. Yu, and M. D. Wong, “Boom-explorer: Risc-v boom microarchitecture design space exploration framework,” in 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), 2021, pp. 1–9
2021
-
[18]
Chiplever: A hardware- software co-design framework towards extension of chiplet system for fully homomorphic encryption,
Y . Du, Y . Wang, M. Wang, X. Li, and Y . Han, “Chiplever: A hardware- software co-design framework towards extension of chiplet system for fully homomorphic encryption,”IEEE transactions on computer-aided design of integrated circuits and systems, 2025
2025
-
[19]
A Mathematical Theory of Co-Design
A. Censi, “A mathematical theory of co-design,”arXiv preprint arXiv:1512.08055, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Co-Design of Complex Systems: From Autonomy to Future Mobility Systems,
G. Zardini, “Co-Design of Complex Systems: From Autonomy to Future Mobility Systems,” Ph.D. dissertation, ETH Zurich, 2023
2023
-
[21]
Censi, J
A. Censi, J. Lorand, and G. Zardini,Applied Compositional Thinking for Engineering, 2024, work-in-progress book. [Online]. Available: https://bit.ly/3qQNrdR
2024
-
[22]
Co-design of autonomous sys- tems: From hardware selection to control synthesis,
G. Zardini, A. Censi, and E. Frazzoli, “Co-design of autonomous sys- tems: From hardware selection to control synthesis,” in2021 European Control Conference (ECC), 2021, pp. 682–689
2021
-
[23]
Task-driven modular co-design of vehicle control systems,
G. Zardini, Z. Suter, A. Censi, and E. Frazzoli, “Task-driven modular co-design of vehicle control systems,” in2022 IEEE 61st Conference on Decision and Control (CDC). IEEE, 2022, pp. 2196–2203
2022
-
[24]
Codei: Resource-efficient task-driven co-design of perception and decision making for mobile robots applied to autonomous vehicles,
D. Milojevic, G. Zardini, M. Elser, A. Censi, and E. Frazzoli, “Codei: Resource-efficient task-driven co-design of perception and decision making for mobile robots applied to autonomous vehicles,”IEEE Transactions on Robotics, vol. 41, pp. 2727–2748, 2025
2025
-
[25]
Task-Driven Co-Design of Heterogeneous Multi-Robot Systems
M. Stralz, M. Alharbi, Y . Huang, and G. Zardini, “Task-driven co-design of heterogeneous multi-robot systems,”arXiv preprint arXiv:2604.21894, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Co- design to enable user-friendly tools to assess the impact of future mobil- ity solutions,
G. Zardini, N. Lanzetti, A. Censi, E. Frazzoli, and M. Pavone, “Co- design to enable user-friendly tools to assess the impact of future mobil- ity solutions,”IEEE Transactions on Network Science and Engineering, vol. 10, no. 2, pp. 827–844, 2022
2022
-
[27]
On the co-design of components and racing strategies in formula 1,
M.-P. Neumann, G. Zardini, A. Cerofolini, and C. H. Onder, “On the co-design of components and racing strategies in formula 1,” in2024 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2024, pp. 2876–2881
2024
-
[28]
Distributional Uncertainty and Adaptive Decision-Making in System Co-design,
Y . Huang and G. Zardini, “Distributional Uncertainty and Adaptive Decision-Making in System Co-design,”arXiv preprint arXiv:2603.14047, 2026
-
[29]
Gamma: automating the hw mapping of dnn models on accelerators via genetic algorithm,
S.-C. Kao and T. Krishna, “Gamma: automating the hw mapping of dnn models on accelerators via genetic algorithm,” inProceedings of the 39th International Conference on Computer-Aided Design, 2020
2020
-
[30]
Compositional Online Learning for Multi-Objective System Co-Design
M. Alharbi, M. A. Dahleh, and G. Zardini, “Compositional on- line learning for multi-objective system co-design,”arXiv preprint arXiv:2604.22624, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.