Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference
Pith reviewed 2026-06-29 21:35 UTC · model grok-4.3
The pith
Language models improve online inference by consolidating context into fast weights during periodic offline sleep phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
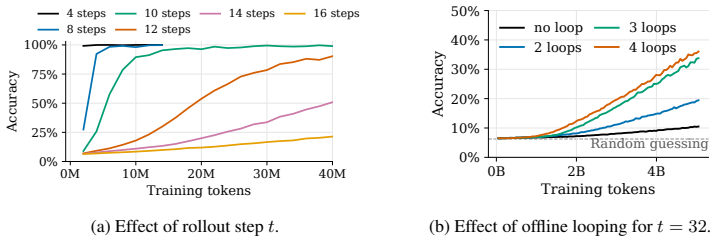
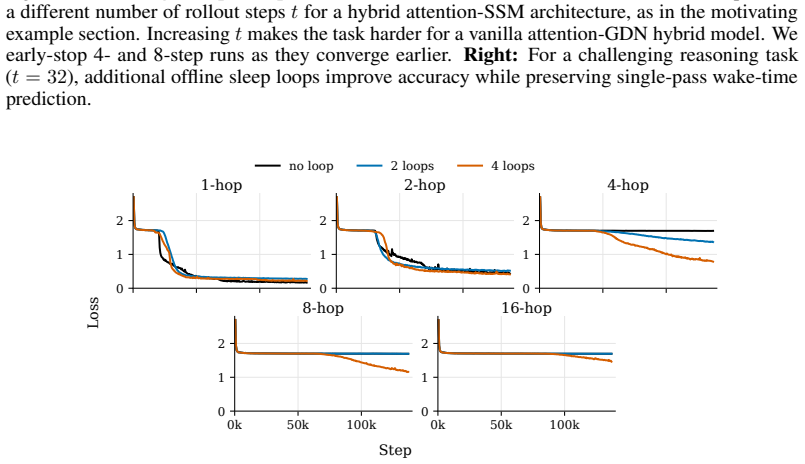
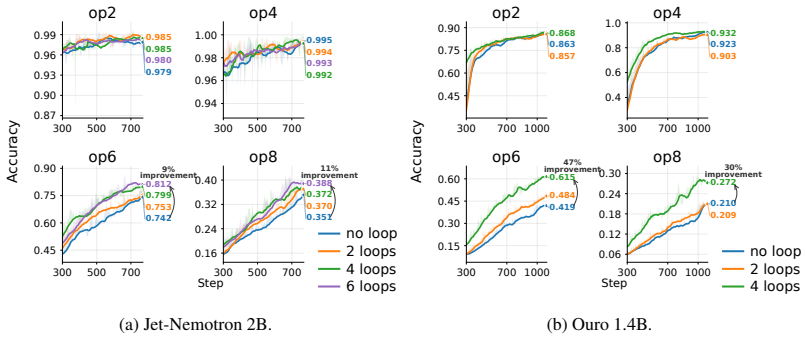
Performing N offline recurrent passes over accumulated context and updating fast weights in SSM blocks via a learned local rule consolidates information in a way that improves subsequent online inference, with gains scaling with sleep duration N and concentrated on harder reasoning examples.
What carries the argument
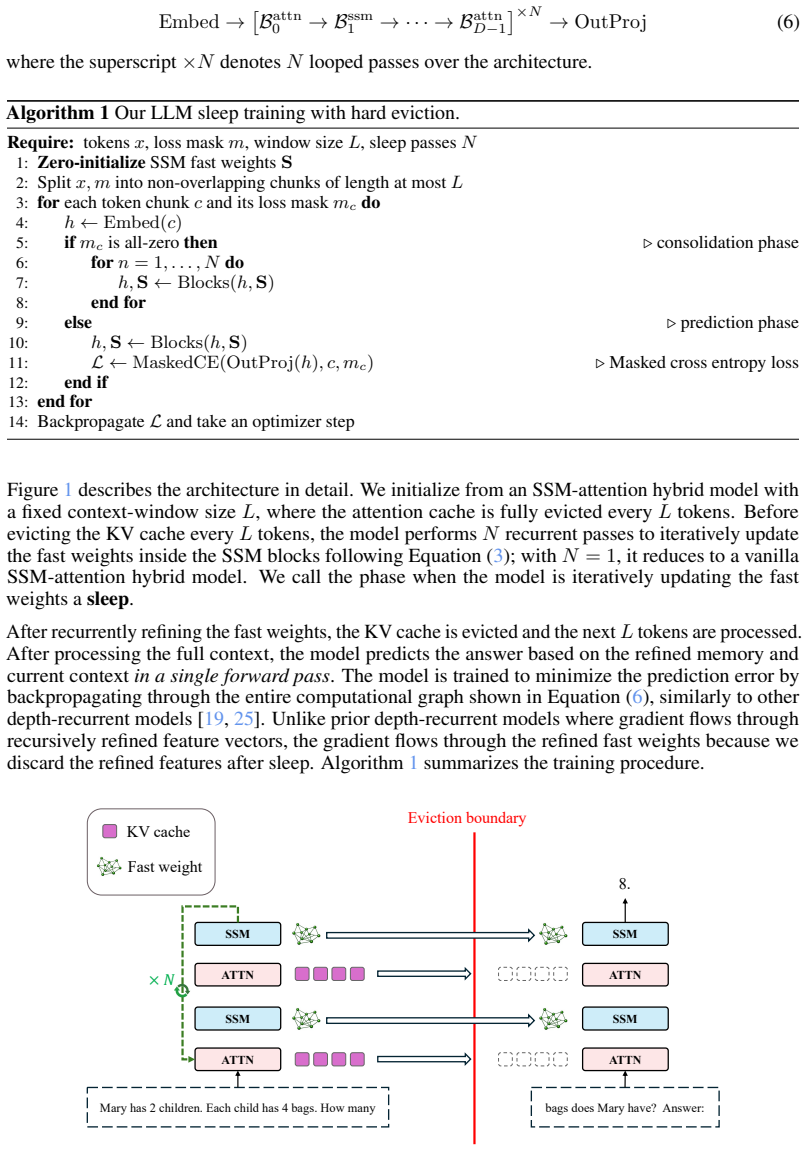
The offline recurrence sleep mechanism that converts recent context into persistent fast weights before clearing the key-value cache.
If this is right
- Increasing sleep duration N produces measurable performance gains on the tested tasks.
- Gains are largest on examples that require deeper reasoning.
- The method succeeds on cellular automata, multi-hop graph retrieval, and math reasoning where regular transformers and SSM-attention hybrids fail.
- Extra computation is shifted to sleep periods while online prediction latency remains unchanged.
Where Pith is reading between the lines
- The same consolidation step could be inserted into other hybrid architectures that already contain SSM blocks.
- If the learned local update rule generalizes, it might reduce reliance on ever-longer context windows during training.
- The offline phase resembles a form of experience replay that could be combined with existing memory-augmented models.
Load-bearing premise
Performing N offline recurrent passes over accumulated context and updating fast weights in SSM blocks via a learned local rule will consolidate information in a way that improves subsequent online inference.
What would settle it
If increasing sleep duration N produces no performance gain on the math reasoning task or if the gains are not larger on deeper-reasoning examples, the central claim would be falsified.
Figures
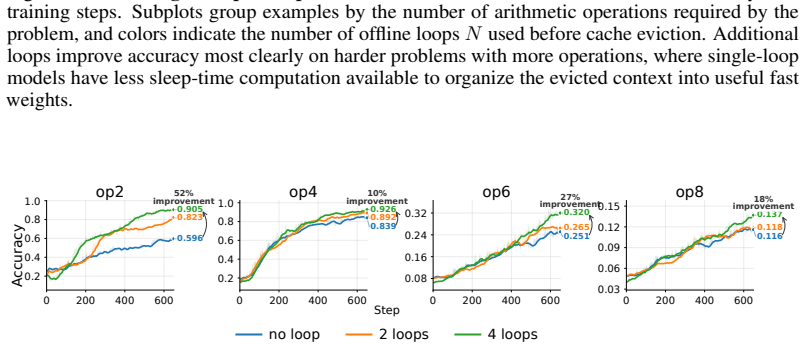
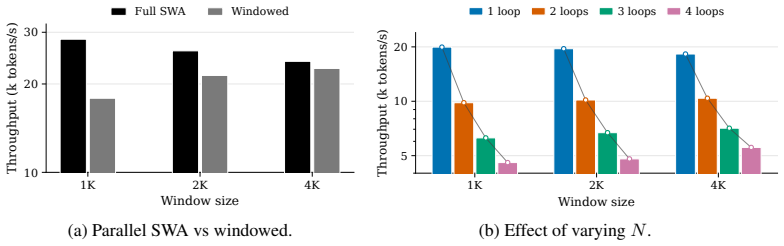
read the original abstract
Transformer-based large language models are increasingly used for long-horizon tasks; however, their attention mechanism scales poorly with context length. To handle this, we study a sleep-like consolidation mechanism in which a model periodically converts recent context into persistent fast weights before clearing its key-value cache. During sleep, the model performs $N$ offline recurrent passes over the accumulated context and updates the fast weights in its state-space model (SSM) blocks through a learned local rule. During inference, this shifts extra computation to sleep while preserving the latency of wake-time prediction. We test our method on controlled synthetic tasks, including cellular automata and multi-hop graph retrieval, as well as a realistic math reasoning task, on which a regular transformer as well as SSM-attention hybrid models fail. We then show that increasing sleep duration $N$ for our models improves performance, with the largest gains on examples that require deeper reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that incorporating a sleep-like consolidation phase, where the model performs N offline recurrent passes over context to update fast weights in SSM blocks using a learned local rule, allows for improved performance on long-horizon tasks during online inference. This is evaluated on synthetic tasks such as cellular automata and multi-hop graph retrieval, as well as a math reasoning task, demonstrating that larger N leads to better results, with the most significant improvements on examples requiring deeper reasoning where standard models fail.
Significance. If the results are robust, this method represents a meaningful advance in handling long contexts by moving computation to an offline "sleep" phase, preserving online latency. The manuscript's strength lies in its use of controlled synthetic tasks with ablations on sleep duration N and task difficulty, providing evidence for the consolidation mechanism. The empirical nature of the work, with comparisons to failing baselines, is noted positively. The stress-test concern regarding whether offline passes consolidate information to improve inference does not appear to land as a flaw, given the reported controlled comparisons and ablations.
minor comments (3)
- [Abstract] Consider adding a sentence summarizing the magnitude of performance gains with increasing N to better highlight the key finding.
- [Method] Provide a clearer definition or equation for the learned local rule used to update the fast weights in the SSM blocks.
- [Experiments] Include error bars or standard deviations in the reported results for different values of N to allow assessment of variability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the proposed sleep-like consolidation mechanism, and recommendation for minor revision. We appreciate the recognition of the controlled synthetic tasks, ablations on sleep duration N, and comparisons to failing baselines.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical method for offline recurrence in SSM-augmented models, with performance gains demonstrated via controlled experiments on synthetic and math tasks as N increases. No equations, fitted parameters, or self-citations are shown to reduce the central claim (improved inference via sleep consolidation) to a definitional tautology or input by construction. The reported scaling with N is an observed outcome rather than a renamed fit or self-referential prediction. The derivation chain is self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes that collapse the result.
Axiom & Free-Parameter Ledger
free parameters (1)
- N
axioms (1)
- domain assumption A learned local rule can update fast weights to consolidate context during offline passes
invented entities (1)
-
fast weights in SSM blocks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Physics of language models: Part 4.1, architecture design and the magic of canon layers
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 4.1, architecture design and the magic of canon layers. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=kxv0M6I7Ud
2025
-
[2]
Simran Arora, Sabri Eyuboglu, Michael Zhang, Aman Timalsina, Silas Alberti, Dylan Zinsley, James Zou, Atri Rudra, and Christopher Ré. Simple linear attention language models balance the recall-throughput tradeoff.arXiv preprint arXiv:2402.18668, 2024
-
[3]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as a labora...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Deep equilibrium models.Advances in neural information processing systems, 32, 2019
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models.Advances in neural information processing systems, 32, 2019
2019
-
[5]
End-to-end algorithm synthesis with recurrent networks: Extrapolation without overthinking.Advances in Neural Information Processing Systems, 35:20232–20242, 2022
Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. End-to-end algorithm synthesis with recurrent networks: Extrapolation without overthinking.Advances in Neural Information Processing Systems, 35:20232–20242, 2022
2022
-
[6]
Language models need sleep: Learning to self modify and consolidate memories
Ali Behrouz, Farnoosh Hashemi, and Vahab Mirrokni. Language models need sleep: Learning to self modify and consolidate memories
-
[7]
Transformers to ssms: Dis- tilling quadratic knowledge to subquadratic models.Advances in neural information processing systems, 37:31788–31812, 2024
Aviv Bick, Kevin Y Li, Eric P Xing, J Zico Kolter, and Albert Gu. Transformers to ssms: Dis- tilling quadratic knowledge to subquadratic models.Advances in neural information processing systems, 37:31788–31812, 2024
2024
-
[8]
Short window attention enables long-term memorization
Loïc Cabannes, Maximilian Beck, Gergely Szilvasy, Matthijs Douze, Maria Lomeli, Jade Copet, Pierre-Emmanuel Mazaré, Gabriel Synnaeve, and Hervé Jégou. Short window attention enables long-term memorization.arXiv preprint arXiv:2509.24552, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Training plug-n-play knowledge modules with deep context distillation, 2025
Lucas Caccia, Alan Ansell, Edoardo Ponti, Ivan Vuli ´c, and Alessandro Sordoni. Training plug-n-play knowledge modules with deep context distillation, 2025. URL https://arxiv. org/abs/2503.08727
-
[10]
Bowen Cao, Deng Cai, and Wai Lam. Infiniteicl: Breaking the limit of context window size via long short-term memory transformation, 2025. URL https://arxiv.org/abs/2504.01707
-
[11]
On contrastive divergence learning
Miguel A Carreira-Perpinan and Geoffrey Hinton. On contrastive divergence learning. In International workshop on artificial intelligence and statistics, pages 33–40. PMLR, 2005. 12
2005
-
[12]
Meta-reinforcement learning with self-modifying networks.Advances in Neural Information Processing Systems, 35:7838–7851, 2022
Mathieu Chalvidal, Thomas Serre, and Rufin VanRullen. Meta-reinforcement learning with self-modifying networks.Advances in Neural Information Processing Systems, 35:7838–7851, 2022
2022
-
[13]
Generative adapter: Contextualizing language models in parameters with a single forward pass, 2024
Tong Chen, Hao Fang, Patrick Xia, Xiaodong Liu, Benjamin Van Durme, Luke Zettlemoyer, Jianfeng Gao, and Hao Cheng. Generative adapter: Contextualizing language models in parameters with a single forward pass, 2024. URLhttps://arxiv.org/abs/2411.05877
-
[14]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Universality in elementary cellular automata.Complex systems, 15(1): 1–40, 2004
Matthew Cook et al. Universality in elementary cellular automata.Complex systems, 15(1): 1–40, 2004
2004
-
[16]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations, volume 2024, pages 35549–35562, 2024
2024
-
[17]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Soham De, Samuel L Smith, Anushan Fernando, Aleksandar Botev, George Cristian-Muraru, Albert Gu, Ruba Haroun, Leonard Berrada, Yutian Chen, Srivatsan Srinivasan, et al. Griffin: Mixing gated linear recurrences with local attention for efficient language models.arXiv preprint arXiv:2402.19427, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Hymba: A hybrid-head architecture for small language models.arXiv preprint arXiv:2411.13676, 2024
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zijia Chen, Ameya Sunil Mahabalesh- warkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, et al. Hymba: A hybrid-head architecture for small language models.arXiv preprint arXiv:2411.13676, 2024
-
[21]
Depth-adaptive transformer.arXiv preprint arXiv:1910.10073, 2019
Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer.arXiv preprint arXiv:1910.10073, 2019
-
[22]
Sabri Eyuboglu, Ryan Ehrlich, Simran Arora, Neel Guha, Dylan Zinsley, Emily Liu, Will Tennien, Atri Rudra, James Zou, Azalia Mirhoseini, et al. Cartridges: Lightweight and general- purpose long context representations via self-study.arXiv preprint arXiv:2506.06266, 2025
-
[23]
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model.arXiv preprint arXiv:2307.06945, 2023
-
[24]
Scaling up test-time compute with latent reasoning: A recurrent depth approach
Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. InNeurIPS, 2025
2025
-
[25]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Yuxian Gu, Qinghao Hu, Shang Yang, Haocheng Xi, Junyu Chen, Song Han, and Han Cai. Jet-Nemotron: Efficient language model with post neural architecture search.arXiv preprint arXiv:2508.15884, 2025
-
[27]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[29]
Psychology press, 2005
Donald Olding Hebb.The organization of behavior: A neuropsychological theory. Psychology press, 2005. 13
2005
-
[30]
wake-sleep
Geoffrey E Hinton, Peter Dayan, Brendan J Frey, and Radford M Neal. The" wake-sleep" algorithm for unsupervised neural networks.Science, 268(5214):1158–1161, 1995
1995
-
[31]
RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
2024
-
[32]
Samy Jelassi, David Brandfonbrener, Sham M Kakade, and Eran Malach. Repeat after me: Transformers are better than state space models at copying.arXiv preprint arXiv:2402.01032, 2024
-
[33]
Luo, Carla P
Anmol Kabra, Yilun Yin, Albert Gong, Kamile Stankeviciute, Dongyoung Go, Johann Lee, Katie Z. Luo, Carla P. Gomes, and Kilian Q. Weinberger. Learning from synthetic data improves multi-hop reasoning. InInternational Conference on Learning Representations, 2026
2026
-
[34]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[35]
Sleep-time compute: Beyond inference scaling at test-time
Kevin Lin, Charlie Snell, Yu Wang, Charles Packer, Sarah Wooders, Ion Stoica, and Joseph E Gonzalez. Sleep-time compute: Beyond inference scaling at test-time.arXiv preprint arXiv:2504.13171, 2025
-
[36]
Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749, 2022
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749, 2022
-
[37]
Yuxi Liu, Konpat Preechakul, Kananart Kuwaranancharoen, and Yutong Bai. The serial scaling hypothesis.arXiv preprint arXiv:2507.12549, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
James L McClelland, Bruce L McNaughton, and Randall C O’Reilly. Why there are comple- mentary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory.Psychological review, 102(3):419, 1995
1995
-
[39]
Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teach- ing pretrained language models to think deeper with retrofitted recurrence.arXiv preprint arXiv:2511.07384, 2025
-
[40]
William Merrill and Ashish Sabharwal. A little depth goes a long way: The expressive power of log-depth transformers.arXiv preprint arXiv:2503.03961, 2025
-
[41]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[42]
Offline replay supports planning in human reinforcement learning.elife, 7:e32548, 2018
Ida Momennejad, A Ross Otto, Nathaniel D Daw, and Kenneth A Norman. Offline replay supports planning in human reinforcement learning.elife, 7:e32548, 2018
2018
-
[43]
P-completeness of cellular automaton rule 110
Turlough Neary and Damien Woods. P-completeness of cellular automaton rule 110. In International Colloquium on Automata, Languages, and Programming, pages 132–143. Springer, 2006
2006
-
[44]
Deep sequence models tend to memorize geometrically; it is unclear why
Shahriar Noroozizadeh, Vaishnavh Nagarajan, Elan Rosenfeld, and Sanjiv Kumar. Deep sequence models tend to memorize geometrically; it is unclear why.arXiv preprint arXiv:2510.26745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
NVIDIA. NVIDIA Nemotron Nano 2: An accurate and efficient hybrid Mamba-Transformer reasoning model.arXiv preprint arXiv:2508.14444, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Parcae: Scaling Laws For Stable Looped Language Models
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y Fu. Parcae: Scaling laws for stable looped language models.arXiv preprint arXiv:2604.12946, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
About sleep’s role in memory.Physiological reviews, 2013
Björn Rasch and Jan Born. About sleep’s role in memory.Physiological reviews, 2013. 14
2013
-
[48]
Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. Samba: Simple hybrid state space models for efficient unlimited context language modeling.arXiv preprint arXiv:2406.07522, 2024
-
[49]
Linear transformers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers. InInternational conference on machine learning, pages 9355–9366. PMLR, 2021
2021
-
[50]
Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks.Advances in Neural Information Processing Systems, 34:6695–6706, 2021
Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Furong Huang, Uzi Vishkin, Micah Goldblum, and Tom Goldstein. Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks.Advances in Neural Information Processing Systems, 34:6695–6706, 2021
2021
-
[51]
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models
Kristian Schwethelm, Daniel Rueckert, and Georgios Kaissis. How much is one recurrence worth? iso-depth scaling laws for looped language models.arXiv preprint arXiv:2604.21106, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Learning by distilling context, 2022
Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context, 2022. URL https://arxiv.org/abs/2209.15189
-
[53]
Dyna, an integrated architecture for learning, planning, and reacting.ACM Sigart Bulletin, 2(4):160–163, 1991
Richard S Sutton. Dyna, an integrated architecture for learning, planning, and reacting.ACM Sigart Bulletin, 2(4):160–163, 1991
1991
-
[54]
Online adaptation of language models with a memory of amortized contexts, 2024
Jihoon Tack, Jaehyung Kim, Eric Mitchell, Jinwoo Shin, Yee Whye Teh, and Jonathan Richard Schwarz. Online adaptation of language models with a memory of amortized contexts, 2024. URLhttps://arxiv.org/abs/2403.04317
-
[55]
End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675,
Arnuv Tandon, Karan Dalal, Xinhao Li, Daniel Koceja, Marcel Rød, Sam Buchanan, Xiaolong Wang, Jure Leskovec, Sanmi Koyejo, Tatsunori Hashimoto, et al. End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675, 2025
-
[56]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[57]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[58]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
1948
-
[59]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, 2017
2017
-
[60]
The mamba in the llama: Distilling and accelerating hybrid models.Advances in Neural Information Processing Systems, 37:62432–62457, 2024
Junxiong Wang, Daniele Paliotta, Avner May, Alexander M Rush, and Tri Dao. The mamba in the llama: Distilling and accelerating hybrid models.Advances in Neural Information Processing Systems, 37:62432–62457, 2024
2024
-
[61]
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Parallelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
2024
-
[64]
Zeliang Zhang, Xiaodong Liu, Hao Cheng, Hao Sun, Chenliang Xu, and Jianfeng Gao. Train- ing large reasoning models efficiently via progressive thought encoding.arXiv preprint arXiv:2602.16839, 2026
-
[65]
GSM-Infinite: How do your LLMs behave over infinitely increasing reasoning complexity and context length? In ICML 2025 Workshop on Long-Context Foundation Models, 2025
Yang Zhou, Hongyi Liu, Zhuoming Chen, Yuandong Tian, and Beidi Chen. GSM-Infinite: How do your LLMs behave over infinitely increasing reasoning complexity and context length? In ICML 2025 Workshop on Long-Context Foundation Models, 2025
2025
-
[66]
Scaling Latent Reasoning via Looped Language Models
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, et al. Scaling latent reasoning via looped language models.arXiv preprint arXiv:2510.25741, 2025. 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.