PANDO: Efficient Multimodal AI Agents via Online Skill Distillation
Pith reviewed 2026-06-30 11:59 UTC · model grok-4.3
The pith
PANDO shows a multimodal web agent can grow more efficient with experience by distilling skills online in a single rollout.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
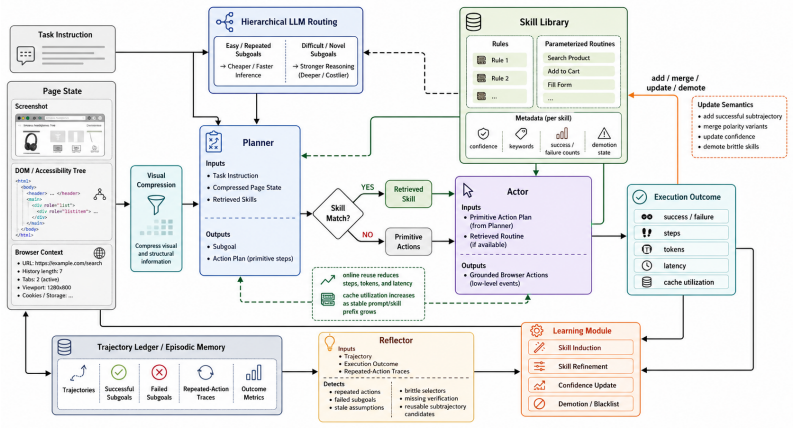
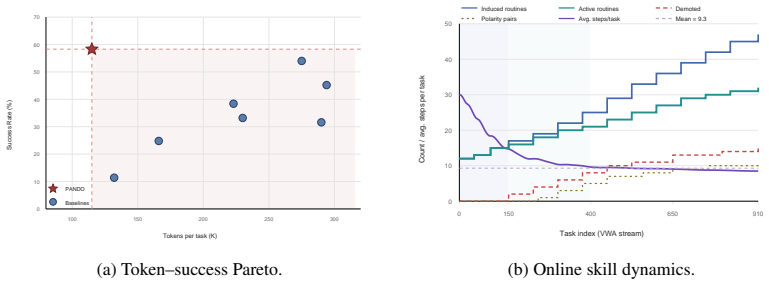
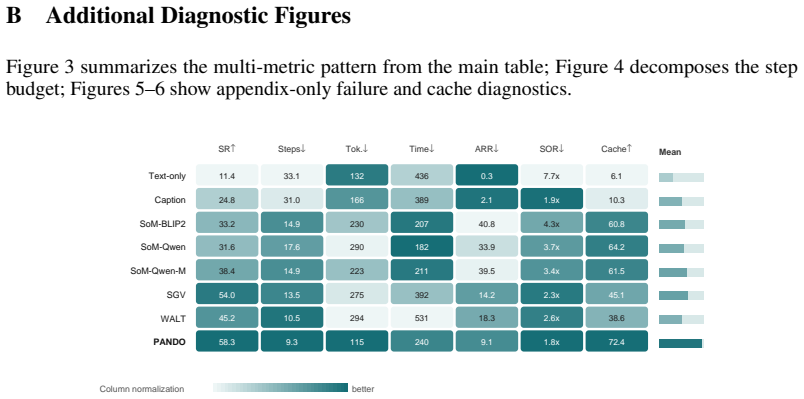
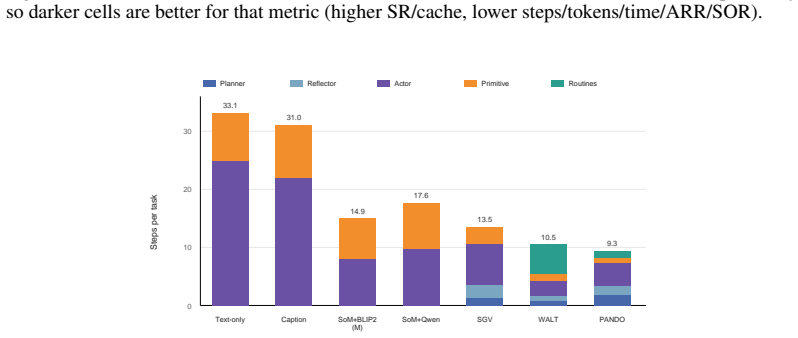
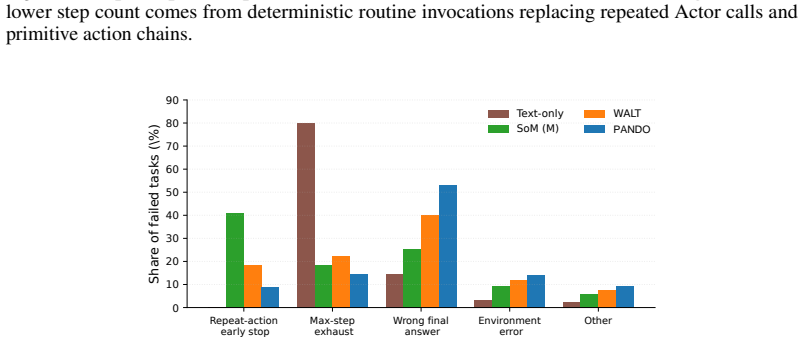
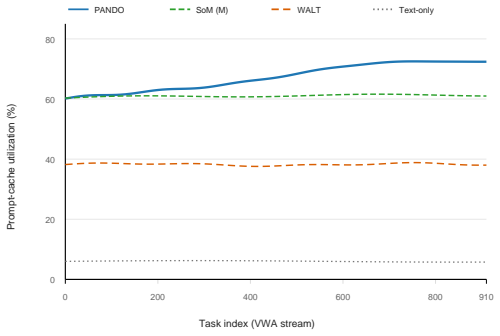
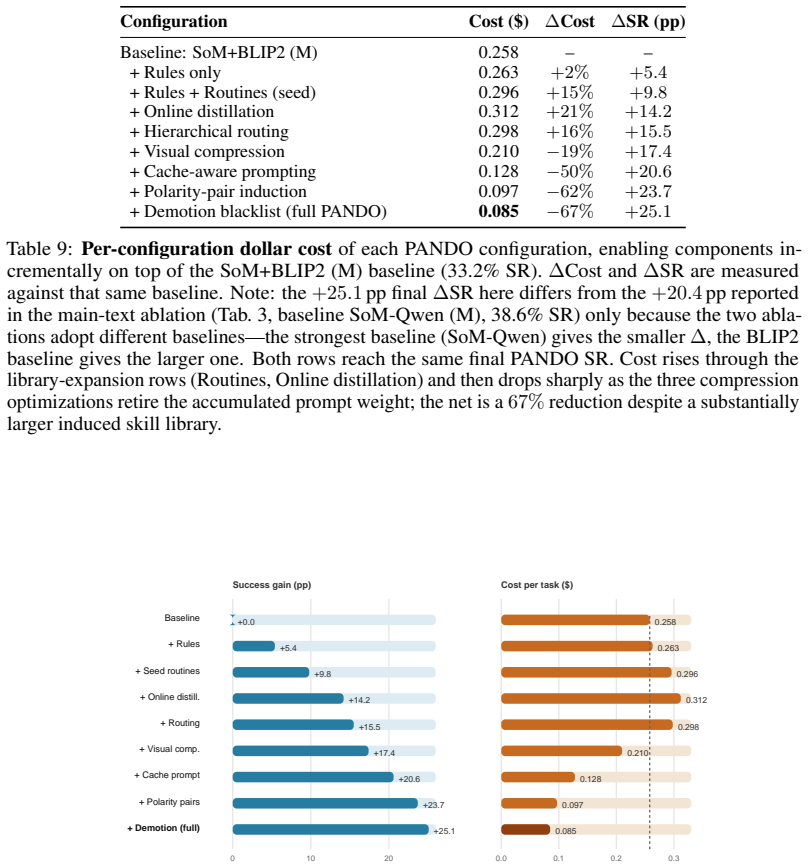
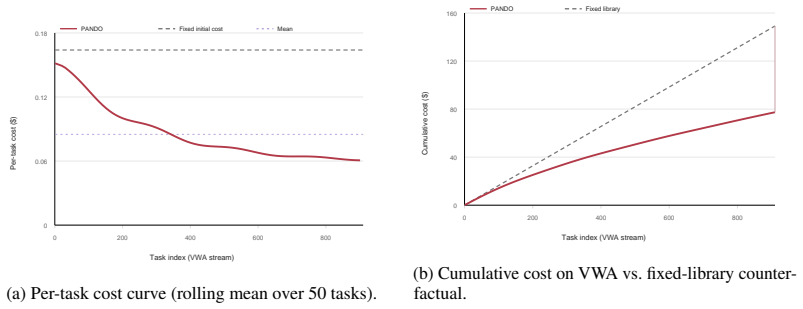
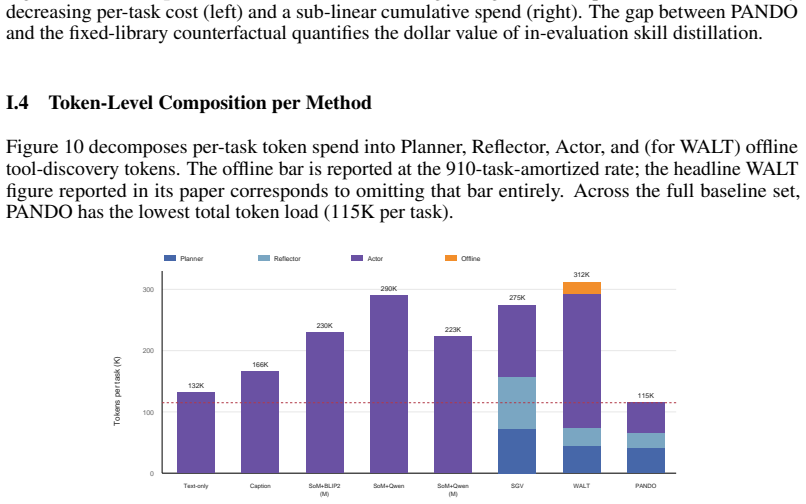
PANDO is a single-rollout online skill-distillation framework that maintains a structured Skill Library and combines progress reflection, confidence-based skill demotion, hierarchical routing, visual compression, and cache-aware prompting. This allows the agent to become more efficient as it accumulates experience rather than more expensive, achieving 58.3% success rate on 910 VisualWebArena tasks with 58% fewer tokens than SGV and 61% fewer than WALT, without any pre-evaluation discovery budget. A 300-task ablation shows rules and routines provide most success gains while routing, compression, and cache-aware prompting convert the larger library into lower marginal token cost. The paper als
What carries the argument
The structured Skill Library maintained through progress reflection and confidence-based demotion, supported by hierarchical routing, visual compression, and cache-aware prompting.
If this is right
- Agents reach higher success without requiring any pre-evaluation discovery budget.
- Token consumption falls as the skill library grows and is reused within one rollout.
- Rules and routines account for most of the success improvement; the efficiency techniques mainly reduce marginal costs.
- Efficiency becomes directly measurable with the three new trajectory metrics rather than only terminal success.
Where Pith is reading between the lines
- The same online distillation pattern could reduce compute waste in other agent domains that suffer repeated actions and low reuse.
- If the library continues to grow, long-term management of skill relevance may become a new limiting factor.
- The approach suggests that general inefficiency patterns in LLM agents are addressable without domain-specific engineering.
Load-bearing premise
The three identified sources of inefficiency are the dominant bottlenecks and the proposed components can be combined without creating new offsetting costs in a single rollout.
What would settle it
An evaluation on the same 910 tasks in which PANDO either fails to reduce tokens below the SGV and WALT baselines or loses its success-rate advantage when all listed components are active.
Figures

read the original abstract
Recent advances in multimodal web agents often rely on increased inference-time computation, including rollout search, verifier passes, offline skill discovery, and specialist model stacks. This raises a central question: can a web agent become more efficient as it accumulates experience, rather than more expensive? We first analyze trajectories from VisualWebArena and identify three recurring sources of inefficiency: repeat-action loops, hidden discovery costs, and low prompt-cache reuse. We then introduce PANDO, a single-rollout online skill-distillation framework that maintains a structured Skill Library and combines progress reflection, confidence-based skill demotion, hierarchical routing, visual compression, and cache-aware prompting. On the full set of 910 VisualWebArena tasks, PANDO achieves a 58.3% success rate, outperforming SGV (54.0%) and our WALT reproduction (45.2%), while using 58% fewer tokens than SGV and 61% fewer tokens than WALT, without any pre-evaluation discovery budget. A 300-task ablation further shows that rules and routines provide most of the success gains, while routing, compression, and cache-aware prompting convert the larger skill library into lower marginal token cost. Finally, we introduce three trajectory-level efficiency metrics -- Action Repetition Rate, Step Overhead Ratio, and Prompt Cache Utilization -- to make efficiency visible beyond terminal success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PANDO, a single-rollout online skill-distillation framework for multimodal web agents. It identifies three sources of inefficiency in prior agents (repeat-action loops, hidden discovery costs, low prompt-cache reuse) and introduces a structured Skill Library maintained via progress reflection, confidence-based skill demotion, hierarchical routing, visual compression, and cache-aware prompting. On the full 910-task VisualWebArena benchmark, PANDO reports 58.3% success (vs. SGV 54.0% and WALT reproduction 45.2%), with 58% and 61% token reductions respectively and zero pre-evaluation discovery budget. A 300-task ablation attributes most success gains to rules/routines and efficiency gains to the remaining modules; three new trajectory-level efficiency metrics (Action Repetition Rate, Step Overhead Ratio, Prompt Cache Utilization) are introduced.
Significance. If the reported performance numbers hold under independent replication, the work provides concrete evidence that multimodal web agents can improve both success rate and token efficiency through online experience accumulation rather than increased inference-time search or offline discovery. The introduction of the three trajectory-level efficiency metrics is a clear positive contribution that makes efficiency claims more falsifiable. The zero pre-evaluation budget and single-rollout constraint are also notable strengths relative to prior approaches that rely on specialist stacks or rollout search.
major comments (3)
- [Results on 910 VisualWebArena tasks] The central performance claims (58.3% success and 58–61% token reductions on all 910 tasks) rest on the authors' own WALT reproduction (45.2% success); without release of the reproduction code, exact hyper-parameters, or a side-by-side comparison against the original WALT implementation, the token-reduction numbers cannot be independently verified and are load-bearing for the efficiency claim.
- [Ablation study] The 300-task ablation attributes success gains primarily to 'rules and routines' and efficiency gains to routing/compression/cache-aware prompting, yet provides no quantitative breakdown (e.g., per-module token or step counts) for the full 910-task PANDO system; this leaves open whether skill-library maintenance and hierarchical routing introduce offsetting overheads that cancel the reported marginal savings when all five components run together.
- [Experimental results] No error bars, standard deviations across runs, or statistical significance tests are reported for the 58.3% vs. 54.0% success-rate difference on the full benchmark, making it impossible to assess whether the observed improvement is robust or could be explained by variance in the evaluation.
minor comments (2)
- The abstract and results section would benefit from explicit statement of the number of independent runs or random seeds used for the 910-task evaluation.
- Notation for the Skill Library structure and the exact demotion threshold is introduced without a dedicated figure or pseudocode, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below with clarifications and indicate the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Results on 910 VisualWebArena tasks] The central performance claims (58.3% success and 58–61% token reductions on all 910 tasks) rest on the authors' own WALT reproduction (45.2% success); without release of the reproduction code, exact hyper-parameters, or a side-by-side comparison against the original WALT implementation, the token-reduction numbers cannot be independently verified and are load-bearing for the efficiency claim.
Authors: We agree that independent verification requires releasing the WALT reproduction details. In the revised version we will provide the reproduction code, exact hyperparameters, and a side-by-side comparison table against the original WALT implementation, either in the supplementary material or via a public repository link. revision: yes
-
Referee: [Ablation study] The 300-task ablation attributes success gains primarily to 'rules and routines' and efficiency gains to routing/compression/cache-aware prompting, yet provides no quantitative breakdown (e.g., per-module token or step counts) for the full 910-task PANDO system; this leaves open whether skill-library maintenance and hierarchical routing introduce offsetting overheads that cancel the reported marginal savings when all five components run together.
Authors: We concur that a quantitative per-module breakdown on the full 910-task set would strengthen the efficiency claims. We will add an extended ablation table (or appendix) reporting token and step counts for each component when all modules operate together on the complete benchmark, explicitly quantifying any overhead from skill-library maintenance and routing. revision: yes
-
Referee: [Experimental results] No error bars, standard deviations across runs, or statistical significance tests are reported for the 58.3% vs. 54.0% success-rate difference on the full benchmark, making it impossible to assess whether the observed improvement is robust or could be explained by variance in the evaluation.
Authors: The 910-task evaluation was executed as a single run due to the high computational cost. We will revise the manuscript to state this limitation explicitly and discuss its implications for assessing robustness. We cannot supply error bars or significance tests without additional independent runs, which we will note as future work. revision: partial
Circularity Check
No significant circularity; results are direct empirical measurements on fixed benchmark
full rationale
The paper reports success rates (58.3%) and token reductions on the fixed 910-task VisualWebArena benchmark via direct evaluation of the described agent framework. No equations, fitted parameters, or derivation steps are present that reduce these outcomes to self-defined inputs or predictions by construction. Ablations attribute gains to specific modules but remain experimental measurements. Self-citation to WALT reproduction is present but not load-bearing for the central claims, which rest on external benchmark results rather than internal reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VisualWebArena trajectories exhibit repeat-action loops, hidden discovery costs, and low prompt-cache reuse as the main inefficiencies.
- ad hoc to paper The listed mechanisms (progress reflection, confidence-based demotion, hierarchical routing, visual compression, cache-aware prompting) can be integrated into a single-rollout online skill library without offsetting costs.
Reference graph
Works this paper leans on
-
[1]
OSWorld-Human: Benchmarking the Efficiency of Computer-Use Agents
Reyna Abhyankar, Qi Qi, and Yiying Zhang. OSWorld-Human: Benchmarking the efficiency of computer-use agents.arXiv preprint arXiv:2506.16042,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Windows Agent Arena: Evaluating multi-modal OS agents at scale.arXiv preprint arXiv:2409.08264,
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows Agent Arena: Evaluating multi-modal OS agents at scale.arXiv preprint arXiv:2409.08264,
-
[3]
The unreasonable effectiveness of scaling agents for computer use.arXiv preprint arXiv:2510.02250,
Gonzalo Gonzalez-Pumariega, Vincent Tu, Chih-Lun Lee, Jiachen Yang, Ang Li, and Xin Eric Wang. The unreasonable effectiveness of scaling agents for computer use.arXiv preprint arXiv:2510.02250,
-
[4]
Kaiwen He et al. Recon-Act: A self-evolving multi-agent browser-use system via web reconnaissance, tool generation, and task execution.arXiv preprint arXiv:2509.21072,
-
[5]
VisualWebArena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024a. Jing Yu ...
-
[6]
Power hungry processing: Watts driving the cost of ai deployment? InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT),
Alexandra Sasha Luccioni, Yacine Jernite, and Emma Strubell. Power hungry processing: Watts driving the cost of ai deployment? InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT),
2024
-
[7]
GAIA: a benchmark for General AI Assistants
Gregoire Mialon, Clementine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candes, and Tatsunori Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Energy Use of AI Inference, Efficiency Pathways, and Test-Time Scaling
Felipe Oviedo, Fiodar Kazhamiaka, Esha Choukse, Allen Kim, Amy Luers, Melanie Nakagawa, Ricardo Bianchini, and Juan M. Lavista Ferres. Energy use of AI inference: Efficiency pathways and test-time compute.arXiv preprint arXiv:2509.20241,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin et al. UI-TARS: Pioneering automated GUI interaction with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2503.21614 (2025)
11 Xiaoye Qu, Yafu Li, Zhao-Chen Su, Weigao Sun, Jianhao Yan, et al. A survey of efficient reasoning for large reasoning models: Language, multimodality, and beyond.arXiv preprint arXiv:2503.21614,
-
[12]
Qwen Team. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models.arXiv preprint arXiv:2403.15388,
-
[14]
Smith, Alex Hubbard, Adam Newkirk, Nuoa Lei, Md Abu Bakar Siddik, Billie Holecek, Jonathan Koomey, Eric Masanet, and Dale Sartor
Arman Shehabi, Sarah J. Smith, Alex Hubbard, Adam Newkirk, Nuoa Lei, Md Abu Bakar Siddik, Billie Holecek, Jonathan Koomey, Eric Masanet, and Dale Sartor. 2024 united states data center energy usage report. https://eta-publications.lbl.gov/publications/2024-unite d-states-data-center-energy,
2024
-
[15]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, Hongye Jin, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. VOYAGER: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang et al. UI-TARS-2 technical report: Advancing GUI agent with multi-turn reinforce- ment learning.arXiv preprint arXiv:2509.02544, 2025a. Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities. InInternational Conference on Learning Representations (ICLR), 2025b. Xiaoqiang ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Inducing programmatic skills for agentic tasks
Zora Zhiruo Wang, Apurva Gandhi, Graham Neubig, and Daniel Fried. Inducing programmatic skills for agentic tasks. InConference on Language Modeling (COLM), 2025c. 12 Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. In International Conference on Machine Learning (ICML), 2025d. Zhiyong Wu, Chengcheng Han, Zichen Ding, ...
2024
-
[19]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Melroy Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. TheAgentCompany: Benchmarking LLM agents on consequential real world tasks...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025a
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025a. Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous GUI interaction. In International Conference on Mach...
-
[21]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. SkillWeaver: Web agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
I spread, I extend, I unfold
C A Note on the Name Pando, the first-person singular present indicative of the Latin verbpandere, means “I spread, I extend, I unfold.” It is also the name of a grove: a single clonal colony of quaking aspen (Populus tremuloides) in Fishlake National Forest, Utah, whose roughly 47,000 visible trunks share one genome and one root system. The colony’s age ...
2026
-
[23]
Amortized
relative to the single-rollout, single-model, no-pre-evaluation baseline π0. ‡ SGV’sρ≈2.2 comes from its two-pass self-grounded verifier (Eq. 4); it is not a dollar ratio against π0 but against its own no-verifier single-rollout form. ⋆ W ALT’s at-evalρ=1 is preserved but Cpre is unreported in the original paper (Eq. 5); the “Amortized” column bounds the ...
2026
-
[24]
58.3+19.9 SGV∼45.0 (Gemini-Flash, single-pass; Andrade et al., 2026, Tab
2026
-
[25]
PANDO achieves the highest reproduced SR
(single-pass Gemini- Flash ≈45% , PANDO-on-Gemini 50.3%), confirming that the lift is mechanism-driven rather than Opus-specific. The remaining 4.4 pp gap to Opus-backboned PANDO matches the Opus-vs-Gemini capability gap on multimodal web tasks reported in concurrent benchmarks. We will scale both runs to full VW A-910 for the camera-ready and report the ...
2000
-
[26]
discard vs. compress
Row ordering follows the narrative order of the subsections. Method Benchmark(s) Grounding Cost axis Headline SR WebV oyager [He et al., 2024] 643 live-web tasks Screenshot+SoM single-rollout VLM 59.1 SeeAct [Zheng et al., 2024] Mind2Web-Live HTML+SoM hybrid single-rollout VLM 51.1 (oracle) OS-Copilot/FRIDAY [Wu et al., 2024] GAIA L1 Text+tools code+APIs ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.