Dynamic Parsing and Updating Natural Language Specification using VLMs for Robust Vision-Language Tracking
Pith reviewed 2026-06-30 07:18 UTC · model grok-4.3
The pith
A language dependency parsing mechanism with Qwen-VL enables dynamic, component-aware updates to natural language specifications for vision-language tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
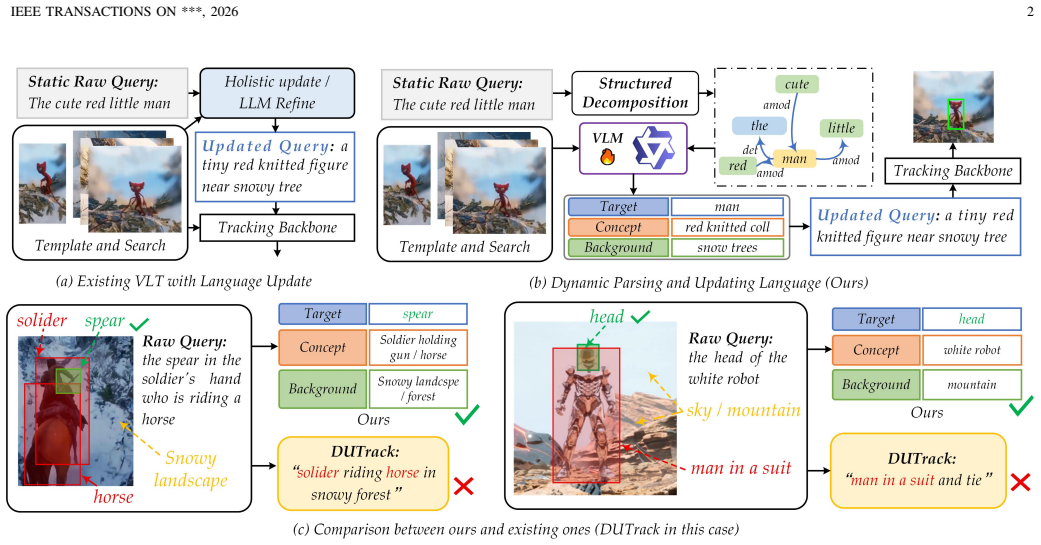
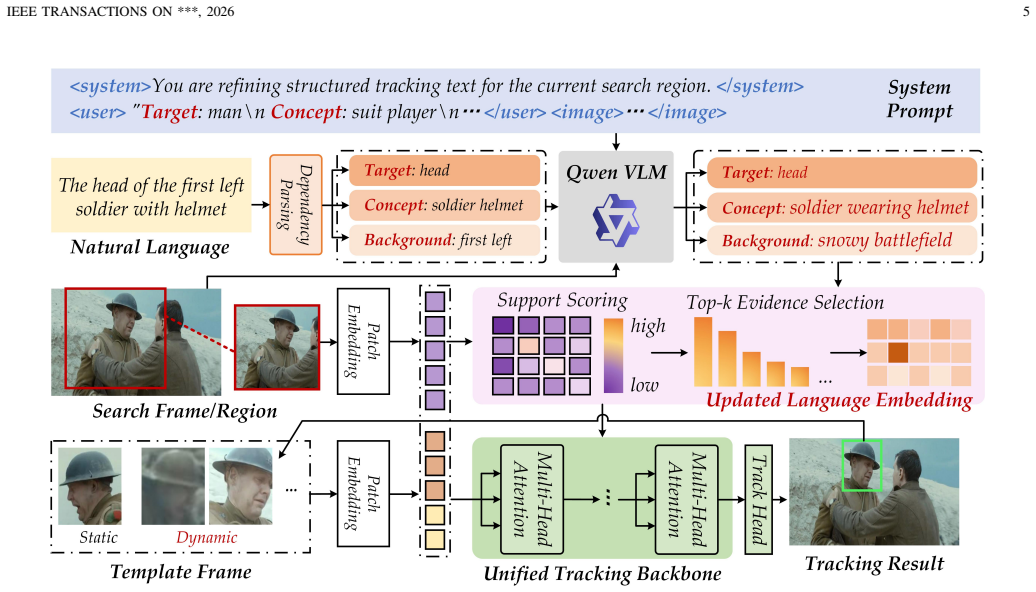
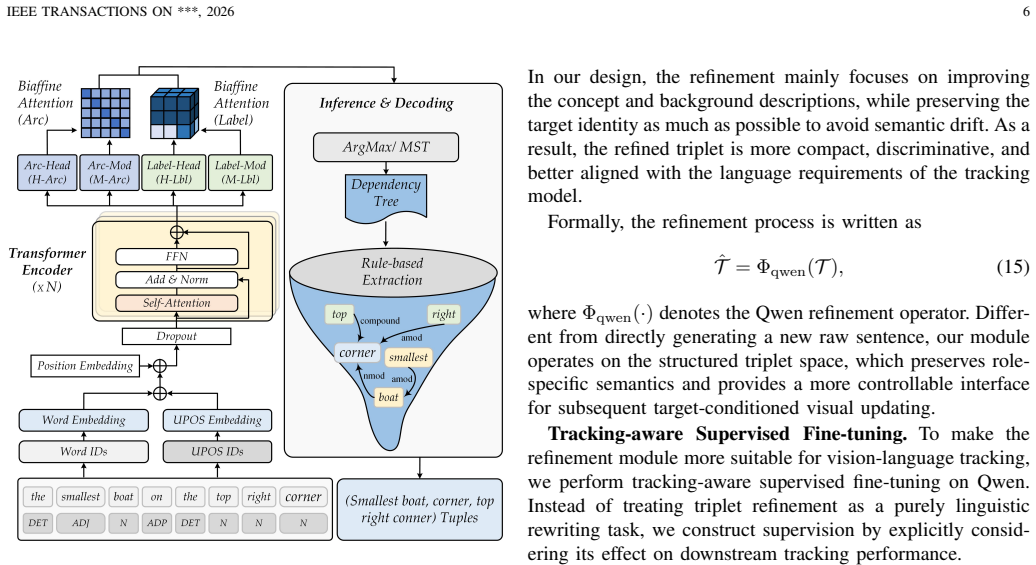
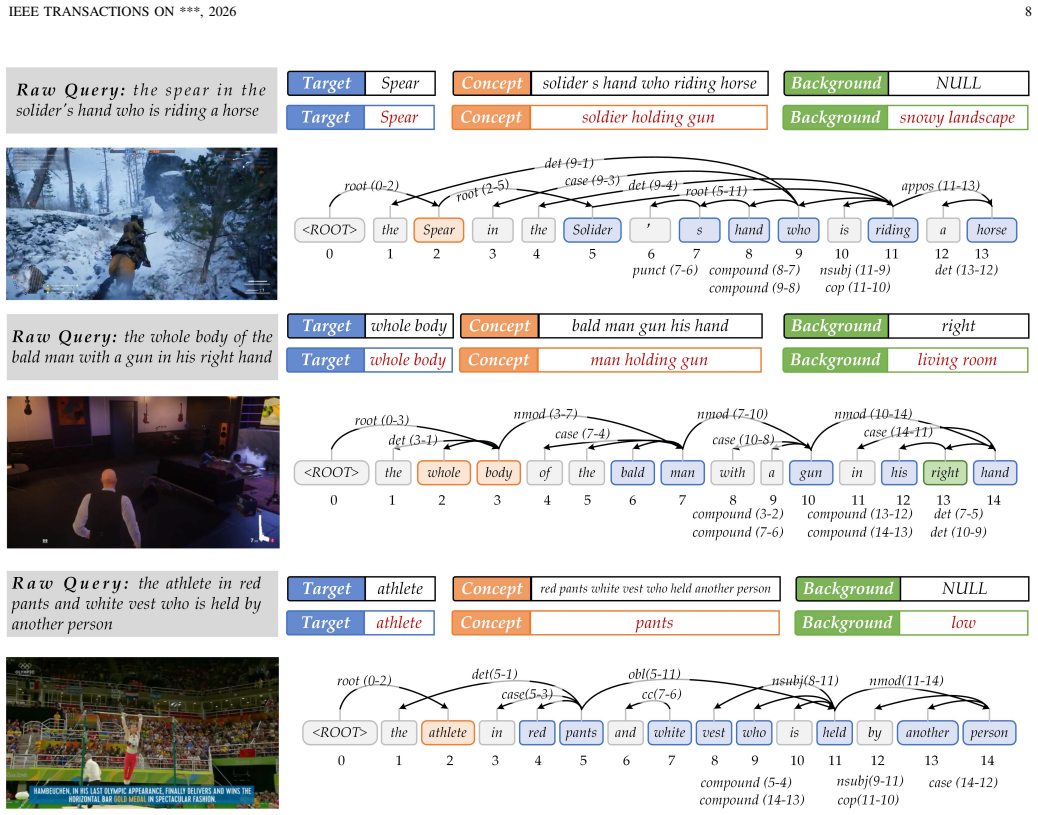
A novel language dependency parsing mechanism distills core tracking principal components encompassing target objects, semantic concepts, and background contextual information; component-aware adaptive textual description updates are then performed by exploiting the cross-modal understanding capability of the pre-trained vision-language model Qwen-VL. Integrating these modules into the baseline yields consistent and superior tracking performance on TNL2K, LaSOT, TNLLT, and OTB-LANG.
What carries the argument
Language dependency parsing mechanism that separates target objects, semantic concepts, and background context, followed by component-aware adaptive updates driven by Qwen-VL.
If this is right
- Semantic-visual mismatch from dynamic target variations is reduced.
- Erroneous target updating, background distraction, and hallucination artifacts are avoided.
- Tracking performance improves consistently across TNL2K, LaSOT, TNLLT, and OTB-LANG.
Where Pith is reading between the lines
- The parsing-plus-update loop could be tested on trackers that already use other vision-language models besides Qwen-VL.
- If the component separation proves stable, the same structure might help in tasks such as video object segmentation guided by language.
- Releasing the code allows direct measurement of how often updates actually change versus stay fixed across long sequences.
Load-bearing premise
Qwen-VL can accurately extract and update only the relevant tracking components without adding wrong information or hallucinations.
What would settle it
Running the method on TNL2K or LaSOT sequences with large appearance changes and measuring whether tracking accuracy drops or hallucinated descriptions appear in the updated text.
Figures
read the original abstract
Vision-language tracking guided by natural language specifications leverages high-level semantic cues of target objects to substantially boost tracking accuracy and robustness. Existing studies have verified that adaptively optimizing textual descriptions throughout the tracking process can effectively mitigate the semantic-visual mismatch induced by dynamic variations in target appearance, position, and other inherent attributes. Nevertheless, mainstream methods that directly generate textual information via sequence models or large language models inevitably suffer from inherent defects, including erroneous target updating, excessive background distraction, and pervasive hallucination artifacts. To address the aforementioned limitations, this paper proposes a novel language dependency parsing mechanism to precisely distill core tracking principal components, encompassing target objects, semantic concepts, and background contextual information. On this basis, we perform component-aware adaptive textual description updates by exploiting the powerful cross-modal understanding capability of the pre-trained vision-language model Qwen-VL. By integrating the proposed elaborately designed modules into the baseline framework, our method achieves consistent and superior tracking performance on multiple large-scale vision-language tracking benchmarks, including TNL2K, LaSOT, TNLLT, and OTB-LANG. The source code and pre-trained models will be released at https://github.com/Event-AHU/Open_VLTrack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a language dependency parsing mechanism to distill core tracking principal components (target objects, semantic concepts, and background contextual information) from natural language specifications and employs the pre-trained vision-language model Qwen-VL for component-aware adaptive textual description updates. By integrating these into a baseline framework, the method is claimed to achieve superior tracking performance on the TNL2K, LaSOT, TNLLT, and OTB-LANG benchmarks while avoiding issues like erroneous target updating and hallucination artifacts.
Significance. Should the empirical results hold and the VLM-based updates prove reliable, this work could advance vision-language tracking by providing a more structured and less error-prone way to dynamically update language specifications, potentially influencing future designs in multi-modal tracking systems. The commitment to releasing code and models supports reproducibility.
major comments (1)
- [Proposed method] The assumption that Qwen-VL has the powerful cross-modal understanding capability to precisely distill core tracking principal components and perform component-aware adaptive textual description updates without introducing erroneous target updating or hallucination artifacts is load-bearing for the central claim of superior performance (as stated in the abstract); however, the manuscript provides no mechanism details, prompting strategy, or robustness checks against typical VLM failure modes to substantiate this.
minor comments (1)
- [Abstract] The abstract could benefit from a brief mention of the baseline framework used for integration to provide context for the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [Proposed method] The assumption that Qwen-VL has the powerful cross-modal understanding capability to precisely distill core tracking principal components and perform component-aware adaptive textual description updates without introducing erroneous target updating or hallucination artifacts is load-bearing for the central claim of superior performance (as stated in the abstract); however, the manuscript provides no mechanism details, prompting strategy, or robustness checks against typical VLM failure modes to substantiate this.
Authors: We agree that the current version lacks explicit mechanism details, prompting strategy, and robustness analysis for the Qwen-VL component. In the revision we will add a dedicated subsection describing the exact prompting templates used for component distillation and adaptive updates, together with ablation studies and qualitative failure-case analysis that directly test against hallucination and erroneous target updating. revision: yes
Circularity Check
No circularity; empirical benchmark claims are independent of inputs
full rationale
The paper describes a proposed method (language dependency parsing + Qwen-VL component-aware updates) and asserts superior tracking performance on TNL2K, LaSOT, TNLLT, and OTB-LANG after integration into a baseline. No equations, fitted parameters, or derivation chain appear in the provided text. The performance claim is presented as an empirical outcome rather than a quantity forced by construction from the method's own definitions or prior self-citations. No load-bearing step reduces to self-definition, renaming, or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained VLMs like Qwen-VL have powerful cross-modal understanding capabilities for distilling tracking components.
Reference graph
Works this paper leans on
-
[1]
Tracking by natural language specification,
Z. Li, R. Tao, E. Gavves, C. G. Snoek, and A. W. Smeulders, “Tracking by natural language specification,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 6495–6503
2017
-
[2]
Towards more flexible and accurate object tracking with natural lan- guage: Algorithms and benchmark,
X. Wang, X. Shu, Z. Zhang, B. Jiang, Y . Wang, Y . Tian, and F. Wu, “Towards more flexible and accurate object tracking with natural lan- guage: Algorithms and benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 13 763–13 773
2021
-
[3]
X. Wang, C. Li, R. Yang, T. Zhang, J. Tang, and B. Luo, “Describe and attend to track: Learning natural language guided structural rep- resentation and visual attention for object tracking,”arXiv preprint arXiv:1811.10014, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Grounding-tracking- integration,
Z. Yang, T. Kumar, T. Chen, J. Su, and J. Luo, “Grounding-tracking- integration,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 9, pp. 3433–3443, 2020
2020
-
[5]
Joint visual grounding and tracking with natural language specification,
L. Zhou, Z. Zhou, K. Mao, and Z. He, “Joint visual grounding and tracking with natural language specification,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 23 151–23 160
2023
-
[6]
Large-scale multi-modal pre-trained models: A comprehensive survey,
X. Wang, G. Chen, G. Qian, P. Gao, X.-Y . Wei, Y . Wang, Y . Tian, and W. Gao, “Large-scale multi-modal pre-trained models: A comprehensive survey,”Machine Intelligence Research, vol. 20, no. 4, pp. 447–482, 2023
2023
-
[7]
Llmformer: Large language model for open-vocabulary semantic segmentation,
H. Shi, S. D. Dao, and J. Cai, “Llmformer: Large language model for open-vocabulary semantic segmentation,”International Journal of Computer Vision, vol. 133, no. 2, pp. 742–759, 2025
2025
-
[8]
Pedestrian attribute recognition: A new benchmark dataset and a large language model augmented framework,
J. Jin, X. Wang, Q. Zhu, H. Wang, and C. Li, “Pedestrian attribute recognition: A new benchmark dataset and a large language model augmented framework,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 4138–4146
2025
-
[9]
Language decou- pling with fine-grained knowledge guidance for referring multi-object tracking,
G. Li, S. Zhuang, Y . Jian, Y . Yan, and H. Wang, “Language decou- pling with fine-grained knowledge guidance for referring multi-object tracking,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 23 626–23 635
2025
-
[10]
Chattracker: Enhancing visual tracking performance via chatting with multimodal large language model,
Y . Sun, F. Yu, S. Chen, Y . Zhang, J. Huang, Y . Li, C. Li, and C. Wang, “Chattracker: Enhancing visual tracking performance via chatting with multimodal large language model,”Advances in Neural Information Processing Systems, vol. 37, pp. 39 303–39 324, 2024
2024
-
[11]
Dynamic updates for language adaptation in visual-language tracking,
X. Li, B. Zhong, Q. Liang, Z. Mo, J. Nong, and S. Song, “Dynamic updates for language adaptation in visual-language tracking,”arXiv preprint arXiv:2503.06621, 2025
-
[12]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[13]
Glad: Generative language-assisted visual tracking for low-semantic templates: X. luo et al
X. Luo, Y . Cai, J. Liu, J. Tang, G. Wu, and L. Wang, “Glad: Generative language-assisted visual tracking for low-semantic templates: X. luo et al.”International Journal of Computer Vision, vol. 134, no. 3, p. 121, 2026
2026
-
[14]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Reasoningtrack: Chain-of-thought reasoning for long-term vision- language tracking,
X. Wang, L. Jin, X. Lou, S. Wang, L. Chen, B. Jiang, and Z. Zhang, “Reasoningtrack: Chain-of-thought reasoning for long-term vision- language tracking,”arXiv preprint arXiv:2508.05221, 2025
-
[16]
Lasot: A high-quality benchmark for large-scale single object tracking,
H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai, Y . Xu, C. Liao, and H. Ling, “Lasot: A high-quality benchmark for large-scale single object tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5374–5383
2019
-
[17]
Towards more flexible and accurate object tracking with natural lan- guage: Algorithms and benchmark,
X. Wang, X. Shu, Z. Zhang, B. Jiang, Y . Wang, Y . Tian, and F. Wu, “Towards more flexible and accurate object tracking with natural lan- guage: Algorithms and benchmark,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13 763–13 773
2021
-
[18]
Divert more attention to vision- language tracking,
M. Guo, Z. Zhang, H. Fan, and L. Jing, “Divert more attention to vision- language tracking,”Advances in Neural Information Processing Systems, vol. 35, pp. 4446–4460, 2022
2022
-
[19]
All in one: Exploring unified vision-language tracking with multi-modal alignment,
C. Zhang, X. Sun, Y . Yang, L. Liu, Q. Liu, X. Zhou, and Y . Wang, “All in one: Exploring unified vision-language tracking with multi-modal alignment,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 5552–5561
2023
-
[20]
Toward unified token learning for vision-language tracking,
Y . Zheng, B. Zhong, Q. Liang, G. Li, R. Ji, and X. Li, “Toward unified token learning for vision-language tracking,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 4, pp. 2125– 2135, 2023
2023
-
[21]
Context- aware integration of language and visual references for natural language tracking,
Y . Shao, S. He, Q. Ye, Y . Feng, W. Luo, and J. Chen, “Context- aware integration of language and visual references for natural language tracking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 208–19 217
2024
-
[22]
Unifying visual and vision-language tracking via contrastive learning,
Y . Ma, Y . Tang, W. Yang, T. Zhang, J. Zhang, and M. Kang, “Unifying visual and vision-language tracking via contrastive learning,” 2024
2024
-
[23]
Mambavlt: Time- evolving multimodal state space model for vision-language tracking,
X. Liu, L. Zhou, Z. Zhou, J. Chen, and Z. He, “Mambavlt: Time- evolving multimodal state space model for vision-language tracking,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 8731–8741
2025
-
[24]
Atctrack: Aligning target-context cues with dynamic target states for robust vision-language tracking,
X. Feng, S. Hu, X. Li, D. Zhang, M. Wu, J. Zhang, X. Chen, and K. Huang, “Atctrack: Aligning target-context cues with dynamic target states for robust vision-language tracking,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 19 850–19 861
2025
-
[25]
Cross-modal retrieval via deep and bidirectional representation learning,
Y . He, S. Xiang, C. Kang, J. Wang, and C. Pan, “Cross-modal retrieval via deep and bidirectional representation learning,”IEEE Transactions on Multimedia, vol. 18, no. 7, pp. 1363–1377, 2016
2016
-
[26]
Adversarial attribute-text embed- ding for person search with natural language query,
Z.-J. Zha, J. Liu, D. Chen, and F. Wu, “Adversarial attribute-text embed- ding for person search with natural language query,”IEEE Transactions on Multimedia, vol. 22, no. 7, pp. 1836–1846, 2020
2020
-
[27]
Align and tell: Boosting text-video retrieval with local alignment and fine-grained supervision,
X. Wang, L. Zhu, Z. Zheng, M. Xu, and Y . Yang, “Align and tell: Boosting text-video retrieval with local alignment and fine-grained supervision,”IEEE Transactions on Multimedia, 2022
2022
-
[28]
Multi-task cnn model for attribute prediction,
A. H. Abdulnabi, G. Wang, J. Lu, and K. Jia, “Multi-task cnn model for attribute prediction,”IEEE Transactions on Multimedia, vol. 17, no. 11, pp. 1949–1959, 2015
1949
-
[29]
Correlation graph convolu- tional network for pedestrian attribute recognition,
H. Fan, H.-M. Hu, S. Liu, W. Lu, and S. Pu, “Correlation graph convolu- tional network for pedestrian attribute recognition,”IEEE Transactions on Multimedia, vol. 24, pp. 49–60, 2022
2022
-
[30]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[33]
Sam 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rä- dle, C. Rolland, L. Gustafsonet al., “Sam 2: Segment anything in images and videos,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 28 085–28 128
2025
-
[34]
Florence-2: Advancing a unified representation for a variety of vision tasks,
B. Xiao, H. Wu, W. Xu, X. Dai, H. Hu, Y . Lu, M. Zeng, C. Liu, and L. Yuan, “Florence-2: Advancing a unified representation for a variety of vision tasks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4818–4829
2024
-
[35]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liuet al., “Llava-onevision: Easy visual task transfer,”arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5-vl technical report, 2025,”URL https://arxiv. org/abs/2502.13923, vol. 6, pp. 13–23, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
R1-track: Direct application of mllms to visual object tracking via reinforcement learning,
B. Wang and W. Li, “R1-track: Direct application of mllms to visual object tracking via reinforcement learning,”arXiv preprint arXiv:2506.21980, 2025
-
[38]
VPTracker: Global Vision-Language Tracking via Visual Prompt
J. Wang, K. Zhou, Z. Wu, K. Ji, D. Huang, and Y . Zheng, “Vptracker: Global vision-language tracking via visual prompt and mllm,”arXiv preprint arXiv:2512.22799, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Llm- track: Semantic multi-object tracking with multi-modal large language models,
P. Liao, F. Yang, D. Wu, J. Yu, Y . Zhu, W. Zhao, and D. Zhang, “Llm- track: Semantic multi-object tracking with multi-modal large language models,”arXiv preprint arXiv:2601.06550, 2026
-
[40]
Deep biaffine attention for neural dependency parsing,
T. Dozat and C. D. Manning, “Deep biaffine attention for neural dependency parsing,” inInternational Conference on Learning Repre- sentations, 2017. IEEE TRANSACTIONS ON ***, 2026 14
2017
-
[41]
Universal dependencies v1: A multilingual treebank collection,
J. Nivre, M.-C. de Marneffe, F. Ginter, Y . Goldberg, J. Hajic, C. D. Manning, R. McDonald, S. Petrov, S. Pyysalo, N. Silveira, R. Tsarfaty, and D. Zeman, “Universal dependencies v1: A multilingual treebank collection,” inProceedings of the Tenth International Conference on Language Resources and Evaluation, 2016, pp. 1659–1666
2016
-
[42]
A gold standard dependency corpus for english,
N. Silveira, T. Dozat, M.-C. de Marneffe, S. R. Bowman, M. Connor, J. Bauer, and C. D. Manning, “A gold standard dependency corpus for english,” inProceedings of the Ninth International Conference on Language Resources and Evaluation, 2014, pp. 2897–2904
2014
-
[43]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022
2022
-
[44]
Generalized intersection over union: A metric and a loss for bound- ing box regression,
H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bound- ing box regression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 658–666
2019
-
[45]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for dense object detection,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2980–2988
2017
-
[46]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019
2019
-
[47]
Joint feature learning and relation modeling for tracking: A one-stream framework,
B. Ye, H. Chang, B. Ma, S. Shan, and X. Chen, “Joint feature learning and relation modeling for tracking: A one-stream framework,” inECCV, 2022
2022
-
[48]
Mixformer: End-to-end tracking with iterative mixed attention,
Y . Cui, C. Jiang, L. Wang, and G. Wu, “Mixformer: End-to-end tracking with iterative mixed attention,” inProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2022, pp. 13 608– 13 618
2022
-
[49]
Aiatrack: Attention in attention for transformer visual tracking,
S. Gao, C. Zhou, C. Ma, X. Wang, and J. Yuan, “Aiatrack: Attention in attention for transformer visual tracking,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 146–164
2022
-
[50]
Citetracker: Correlating image and text for visual tracking,
X. Li, Y . Huang, Z. He, Y . Wang, H. Lu, and M.-H. Yang, “Citetracker: Correlating image and text for visual tracking,” inICCV, 2023
2023
-
[51]
Robust object modeling for visual tracking,
Y . Cai, J. Liu, J. Tang, and G. Wu, “Robust object modeling for visual tracking,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9589–9600
2023
-
[52]
Generalized relation modeling for transformer tracking,
S. Gao, C. Zhou, and J. Zhang, “Generalized relation modeling for transformer tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18 686–18 695
2023
-
[53]
Odtrack: Online dense temporal token learning for visual tracking,
Y . Zheng, B. Zhong, Q. Liang, Z. Mo, S. Zhang, and X. Li, “Odtrack: Online dense temporal token learning for visual tracking,” inAAAI, 2024
2024
-
[54]
Explicit visual prompts for visual object tracking,
L. Shi, B. Zhong, Q. Liang, N. Li, S. Zhang, and X. Li, “Explicit visual prompts for visual object tracking,” inAAAI, 2024
2024
-
[55]
Autoregressive queries for adaptive tracking with spatio-temporal trans- formers,
J. Xie, B. Zhong, Z. Mo, S. Zhang, L. Shi, S. Song, and R. Ji, “Autoregressive queries for adaptive tracking with spatio-temporal trans- formers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 300–19 309
2024
-
[56]
Less is more: Token context-aware learning for object tracking,
C. Xu, B. Zhong, Q. Liang, Y . Zheng, G. Li, and S. Song, “Less is more: Token context-aware learning for object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8824–8832
2025
-
[57]
Enhancing vision-language tracking by effectively con- verting textual cues into visual cues,
X. Feng, D. Zhang, S. Hu, X. Li, M. Wu, J. Zhang, X. Chen, and K. Huang, “Enhancing vision-language tracking by effectively con- verting textual cues into visual cues,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[58]
Sutrack: Towards simple and unified single object tracking,
X. Chen, B. Kang, W. Geng, J. Zhu, Y . Liu, D. Wang, and H. Lu, “Sutrack: Towards simple and unified single object tracking,” 2025
2025
-
[59]
Dynamic updates for language adaptation in visual-language tracking,
X. Li, , B. Zhong, Q. Liang, Z. Mo, J. Nong, and S. Song, “Dynamic updates for language adaptation in visual-language tracking,” inCVPR, 2025
2025
-
[60]
Selective distillation of lan- guage tokens for redundancy suppression in vision-language tracking,
T. Bai, S. Yang, Y . Wang, and G. Zhang, “Selective distillation of lan- guage tokens for redundancy suppression in vision-language tracking,” Expert Systems with Applications, p. 132255, 2026
2026
-
[61]
Seqtrack: Sequence to sequence learning for visual object tracking,
X. Chen, H. Peng, D. Wang, H. Lu, and H. Hu, “Seqtrack: Sequence to sequence learning for visual object tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 14 572–14 581
2023
-
[62]
Tdcl: Dense seman- tic contrastive learning for vision-language tracking,
Z. Wang, X. He, K. Lan, Y . Cui, and D. Guo, “Tdcl: Dense seman- tic contrastive learning for vision-language tracking,” inECAI 2024: 27th European Conference on Artificial Intelligence, 19–24 October 2024, Santiago de Compostela, Spain–Including 13th Conference on Prestigious Applications of Intelligent Systems (PAIS 2024). SAGE Publications Pvt. Ltd 1 O...
2024
-
[63]
Consistencies are all you need for semi-supervised vision-language tracking,
J. Ge, J. Cao, X. Zhu, X. Zhang, C. Liu, K. Wang, and B. Liu, “Consistencies are all you need for semi-supervised vision-language tracking,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1895–1904
2024
-
[64]
One-stream stepwise decreasing for vision-language tracking,
G. Zhang, B. Zhong, Q. Liang, Z. Mo, N. Li, and S. Song, “One-stream stepwise decreasing for vision-language tracking,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9053– 9063, 2024
2024
-
[65]
Atstrack: Enhancing visual-language tracking by aligning temporal and spatial scales,
Y . Zhen, Q. Wang, Y . Qiao, L. Qu, and H. Fan, “Atstrack: Enhancing visual-language tracking by aligning temporal and spatial scales,”arXiv preprint arXiv:2507.00454, 2025
-
[66]
Robust tracking via mamba-based context-aware token learning,
J. Xie, B. Zhong, Q. Liang, N. Li, Z. Mo, and S. Song, “Robust tracking via mamba-based context-aware token learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8727–8735
2025
-
[67]
Aware distilla- tion for robust vision-language tracking under linguistic sparsity,
G. Zhang, B. Zhong, S. Yang, Y . Wang, and T. Bai, “Aware distilla- tion for robust vision-language tracking under linguistic sparsity,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 15, 2026, pp. 12 439–12 447
2026
-
[68]
Vision-language tracking with attention-based optimization,
S. Hu, T. Liu, L. Han, and R. Xing, “Vision-language tracking with attention-based optimization,”Journal of Visual Communication and Image Representation, vol. 114, p. 104644, 2026
2026
-
[69]
Sematrack: semantic-driven unified vision-language tracking: J. zhang et al
J. Zhang, L. Xu, H. Zhang, X. Yan, B. Jiang, and J. Wu, “Sematrack: semantic-driven unified vision-language tracking: J. zhang et al.”The Visual Computer, vol. 42, no. 2, p. 142, 2026
2026
-
[70]
Rwkv-inspired multi-modal relation modeling for vision-language tracking,
G. Zhang, Y . Wang, B. Zhong, Y . Mu, and T. Bai, “Rwkv-inspired multi-modal relation modeling for vision-language tracking,”IEEE Transactions on Multimedia, 2026
2026
-
[71]
Transformer tracking with cyclic shifting window attention,
Z. Song, J. Yu, Y .-P. P. Chen, and W. Yang, “Transformer tracking with cyclic shifting window attention,” 2022. [Online]. Available: https://arxiv.org/abs/2205.03806
-
[72]
Transformer vision- language tracking via proxy token guided cross-modal fusion,
H. Zhao, X. Wang, D. Wang, H. Lu, and X. Ruan, “Transformer vision- language tracking via proxy token guided cross-modal fusion,”Pattern Recognition Letters, vol. 168, pp. 10–16, 2023
2023
-
[73]
Real-time visual object tracking with natural language description,
Q. Feng, V . Ablavsky, Q. Bai, G. Li, and S. Sclaroff, “Real-time visual object tracking with natural language description,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2020, pp. 700–709
2020
-
[74]
Siamese natural language tracker: Tracking by natural language descriptions with siamese track- ers,
Q. Feng, V . Ablavsky, Q. Bai, and S. Sclaroff, “Siamese natural language tracker: Tracking by natural language descriptions with siamese track- ers,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5851–5860
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.