MVP-Nav: Multi-layer Value Map Planner Navigator
Pith reviewed 2026-07-01 05:17 UTC · model grok-4.3
The pith
MVP-Nav reconstructs 3D geometry from RGB images alone to enable safe zero-shot object navigation without depth sensors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
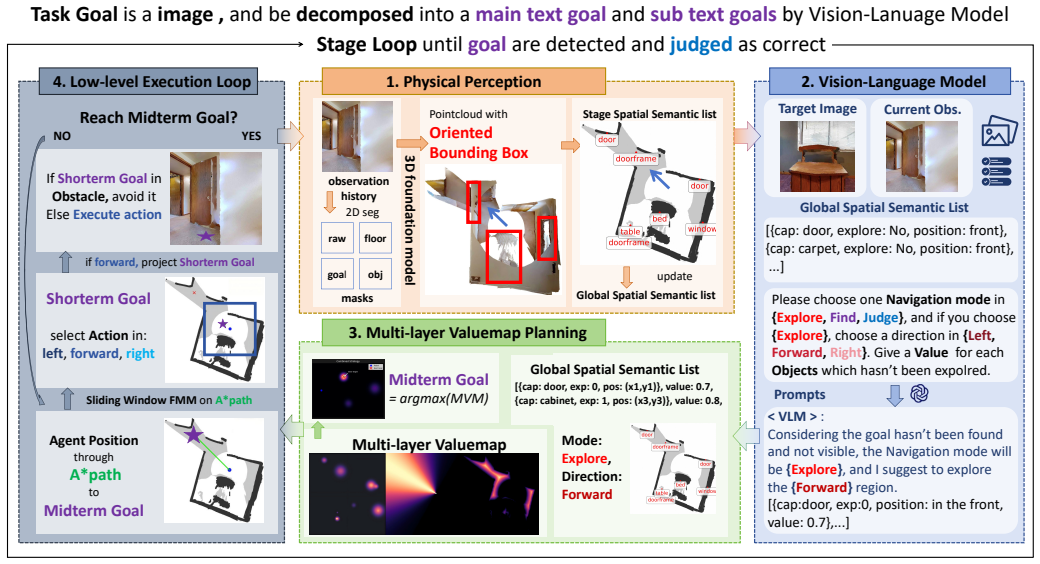
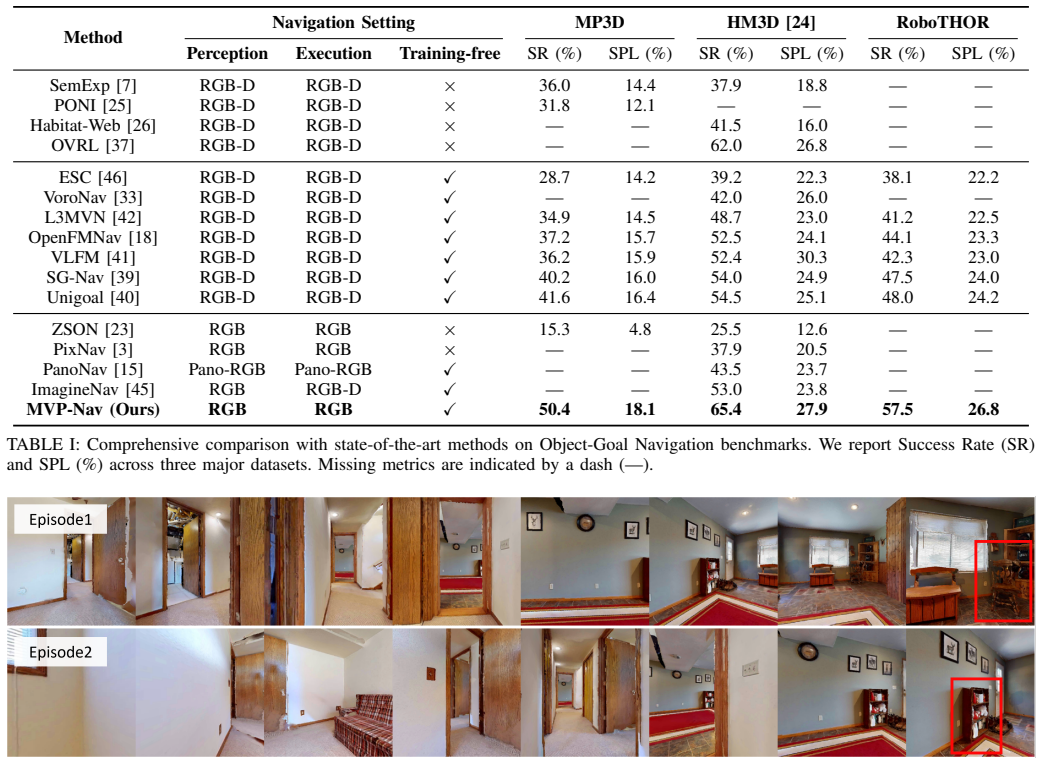
MVP-Nav reconstructs explicit physical occupancy from monocular observations by leveraging 3D foundation models to project 2D semantic instances into 3D oriented bounding boxes, forming a global spatial semantic representation. To unify high-level semantic reasoning and low-level physical constraints, it introduces a Multi-layer Value Map that integrates semantic priorities and reconstructed geometry into a shared cost space, enabling physically grounded geometric planning. Experiments on zero-shot object navigation benchmarks show it significantly outperforms existing depth-free methods.
What carries the argument
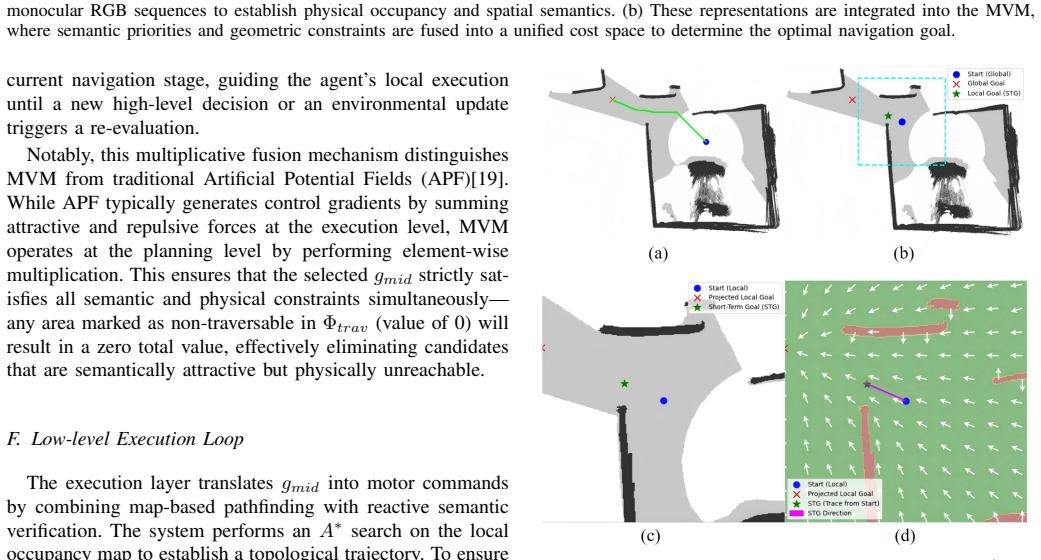
The Multi-layer Value Map, which places semantic priorities and reconstructed 3D geometry into a single shared cost space for unified planning.
If this is right
- Navigation policies become physically constrained without requiring depth sensors at runtime.
- Semantic reasoning and geometric constraints operate inside the same planning representation.
- State-of-the-art results on zero-shot object goal navigation benchmarks become attainable from RGB alone.
- Structured physical priors can substitute for active depth hardware in embodied settings.
Where Pith is reading between the lines
- The same projection-plus-value-map pattern could transfer to other monocular tasks such as manipulation or exploration.
- Accuracy gains in future 3D foundation models would directly raise the reliability of the resulting maps.
- The approach reconnects high-level vision-language reasoning with classical geometric planning techniques.
- Real-world robot trials would expose any remaining gaps between model-generated boxes and actual surfaces.
Load-bearing premise
3D foundation models can reliably project 2D semantic instances into accurate 3D oriented bounding boxes from monocular observations to form a trustworthy global spatial semantic representation without major physical errors.
What would settle it
Controlled tests in which the 3D bounding boxes contain frequent geometric errors that produce collisions or failed paths would show the central claim does not hold.
Figures






read the original abstract
Zero-shot Object Goal Navigation (ZSON) with RGB-only perception poses a fundamental challenge for embodied agents, as the absence of explicit depth information introduces severe physical uncertainty and semantic-physical misalignment. Existing approaches either rely on high-level semantic reasoning without geometric grounding or learn end-to-end policies that lack explicit physical constraints, often resulting in semantically plausible but physically unsafe behaviors. In this paper, we propose MVP-Nav, a physical-aware RGB-only navigation framework that aligns perception, planning, and control with the real 3D world. MVP-Nav reconstructs explicit physical occupancy from monocular observations by leveraging 3D foundation models to project 2D semantic instances into 3D oriented bounding boxes, forming a global spatial semantic representation. To unify high-level semantic reasoning and low-level physical constraints, we introduce a Multi-layer Value Map (MVM) that integrates semantic priorities and reconstructed geometry into a shared cost space, enabling physically grounded geometric planning. Extensive experiments on zero-shot object navigation benchmarks demonstrate that MVP-Nav significantly outperforms existing depth-free methods, achieving state-of-the-art performance and validating that structured physical priors can effectively compensate for the absence of active depth sensors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MVP-Nav, a physical-aware RGB-only framework for zero-shot object goal navigation. It reconstructs explicit physical occupancy from monocular RGB observations by using 3D foundation models to project 2D semantic instances into 3D oriented bounding boxes, forming a global spatial semantic representation. A Multi-layer Value Map (MVM) is introduced to integrate semantic priorities and reconstructed geometry into a shared cost space for physically grounded planning. The manuscript claims that MVP-Nav significantly outperforms existing depth-free methods on ZSON benchmarks and validates that structured physical priors can compensate for the absence of active depth sensors.
Significance. If the reconstruction step holds, the work would show that explicit geometric priors derived from monocular observations can enable safe navigation without depth sensors, with potential impact on cost-effective embodied systems. The MVM concept provides a concrete mechanism for unifying semantic reasoning and physical constraints. Credit is due for the explicit attempt to ground planning in reconstructed 3D structure rather than end-to-end learning alone.
major comments (2)
- [Abstract] Abstract: The central empirical claim that MVP-Nav 'significantly outperforms existing depth-free methods, achieving state-of-the-art performance' is asserted without any quantitative benchmark scores, tables, error analysis, or ablation results, preventing evaluation of the outperformance assertion.
- [Method] Method section (reconstruction pipeline): The claim that 3D foundation models produce sufficiently accurate 3D oriented bounding boxes and occupancy from single RGB frames to form a 'trustworthy global spatial semantic representation' is load-bearing for the physical-compensation thesis, yet no quantitative fidelity metrics (e.g., IoU against ground-truth depth or 3D scans), error propagation analysis, or handling of monocular scale/orientation ambiguities are reported.
minor comments (1)
- [Introduction] The acronym MVM is defined but its relationship to existing layered cost-map or value-map representations in the navigation literature is not discussed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the presentation of results and validation of the reconstruction pipeline.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that MVP-Nav 'significantly outperforms existing depth-free methods, achieving state-of-the-art performance' is asserted without any quantitative benchmark scores, tables, error analysis, or ablation results, preventing evaluation of the outperformance assertion.
Authors: We agree that the abstract would benefit from explicit quantitative support. The experiments section of the manuscript contains the relevant tables, success rates, and comparisons; to address the concern directly, we will revise the abstract to include key numerical results (e.g., success rate deltas on the primary ZSON benchmarks) while preserving its concise nature. revision: yes
-
Referee: [Method] Method section (reconstruction pipeline): The claim that 3D foundation models produce sufficiently accurate 3D oriented bounding boxes and occupancy from single RGB frames to form a 'trustworthy global spatial semantic representation' is load-bearing for the physical-compensation thesis, yet no quantitative fidelity metrics (e.g., IoU against ground-truth depth or 3D scans), error propagation analysis, or handling of monocular scale/orientation ambiguities are reported.
Authors: The referee is correct that explicit fidelity metrics would strengthen the physical-compensation argument. The current manuscript emphasizes end-to-end navigation outcomes rather than isolated reconstruction benchmarks; we will add a dedicated analysis (main text or appendix) reporting IoU and scale-error statistics against available ground-truth depth/scan data from the evaluation environments, along with a description of how multi-view fusion and semantic consistency in the MVM mitigate monocular ambiguities. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents MVP-Nav as a framework that reconstructs 3D occupancy via 3D foundation models projecting 2D instances to oriented bounding boxes and then builds a Multi-layer Value Map integrating semantics and geometry. No equations, fitted parameters, or self-citations are shown that reduce any claimed prediction or result to its own inputs by construction. The derivation chain consists of system design choices justified by external foundation models and empirical benchmarks rather than self-referential definitions or renamed fits. The accuracy of monocular 3D projections is an external assumption subject to verification, not a circular step internal to the paper's logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D foundation models can accurately project 2D semantic instances into reliable 3D oriented bounding boxes from monocular RGB observations
invented entities (1)
-
Multi-layer Value Map (MVM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Mano- lis Savva, and Amir R. Zamir. On evaluation of embodied navigation agents, 2018. URL https://arxiv.org/abs/1807. 06757
2018
-
[2]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large- scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bridg- ing zero-shot object navigation and foundation models through pixel-guided navigation skill
Wenzhe Cai, Siyuan Huang, Guangran Cheng, Yuxing Long, Peng Gao, Changyin Sun, and Hao Dong. Bridg- ing zero-shot object navigation and foundation models through pixel-guided navigation skill. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5228–5234. IEEE, 2024
2024
-
[4]
Cognav: Cognitive process modeling for object goal navigation with llms
Yihan Cao, Jiazhao Zhang, Zhinan Yu, Shuzhen Liu, Zheng Qin, Qin Zou, Bo Du, and Kai Xu. Cognav: Cognitive process modeling for object goal navigation with llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9550–9560, 2025
2025
-
[5]
Matterport3D: Learning from RGB-D data in indoor environments.International Conference on 3D Vision (3DV), 2017
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3D: Learning from RGB-D data in indoor environments.International Conference on 3D Vision (3DV), 2017
2017
-
[6]
Learning to explore using active neural slam
Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. Learning to explore using active neural slam. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[7]
Object goal navigation using goal-oriented semantic exploration
Devendra Singh Chaplot, Dhiraj Prakashchand Gandhi, Abhinav Gupta, and Russ R Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. Advances in Neural Information Processing Systems, 33: 4247–4258, 2020
2020
-
[8]
Geometrically-constrained agent for spatial reasoning
Zeren Chen, Xiaoya Lu, Zhijie Zheng, Pengrui Li, Lehan He, Yijin Zhou, Jing Shao, Bohan Zhuang, and Lu Sheng. Geometrically-constrained agent for spatial reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 38689–38699, 2026
2026
-
[9]
Robothor: An open simulation-to-real embodied ai platform
Matt Deitke, Winson Han, Alvaro Herrasti, Anirud- dha Kembhavi, Eric Kolve, Roozbeh Mottaghi, Jordi Salvador, Dustin Schwenk, Eli VanderBilt, Matthew Wallingford, et al. Robothor: An open simulation-to-real embodied ai platform. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3164–3174, 2020
2020
-
[10]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[11]
The University of North Carolina at Chapel Hill, 2000
Stefan Aric Gottschalk.Collision queries using oriented bounding boxes. The University of North Carolina at Chapel Hill, 2000
2000
-
[12]
A formal basis for the heuristic determination of minimum cost paths.IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968
Peter E Hart, Nils J Nilsson, and Bertram Raphael. A formal basis for the heuristic determination of minimum cost paths.IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968
1968
-
[13]
AstraNav-World: World Model for Foresight Control and Consistency
Junjun Hu, Jintao Chen, Haochen Bai, Minghua Luo, Shichao Xie, Ziyi Chen, Fei Liu, Zedong Chu, Xinda Xue, Botao Ren, et al. Astranav-world: World model for foresight control and consistency.arXiv preprint arXiv:2512.21714, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt- 4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Panonav: Mapless zero-shot object navigation with panoramic scene parsing and dynamic memory, 2025
Qunchao Jin, Yilin Wu, and Changhao Chen. Panonav: Mapless zero-shot object navigation with panoramic scene parsing and dynamic memory, 2025. URL https: //arxiv.org/abs/2511.06840
-
[16]
MapAnything: Univer- sal feed-forward metric 3D reconstruction
Nikhil Keetha, Norman M ¨uller, Johannes Sch ¨onberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bul`o, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. MapAnything: Univer- sal feed-forward metric 3D reconstructi...
2026
-
[17]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Yuxuan Kuang, Hai Lin, and Meng Jiang. Openfm- nav: Towards open-set zero-shot object navigation via vision-language foundation models.arXiv preprint arXiv:2402.10670, 2024
-
[19]
Artificial potential field based path planning for mobile robots using a virtual obstacle concept
Min Cheol Lee and Min Gyu Park. Artificial potential field based path planning for mobile robots using a virtual obstacle concept. InProceedings 2003 IEEE/ASME In- ternational Conference on Advanced Intelligent Mecha- tronics (AIM 2003), volume 2, pages 735–740 vol.2,
2003
-
[20]
doi: 10.1109/AIM.2003.1225434
-
[21]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open- set object detection.arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Stubborn: A strong baseline for indoor object navigation
Haokuan Luo, Albert Yue, Zhang-Wei Hong, and Pulkit Agrawal. Stubborn: A strong baseline for indoor object navigation. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3287– 3293, 2022. doi: 10.1109/IROS47612.2022.9981646
-
[24]
Zson: Zero-shot object- goal navigation using multimodal goal embeddings.Ad- vances in Neural Information Processing Systems, 35: 32340–32352, 2022
Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. Zson: Zero-shot object- goal navigation using multimodal goal embeddings.Ad- vances in Neural Information Processing Systems, 35: 32340–32352, 2022
2022
-
[25]
Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. InThirty-fifth Conference on Neural Information...
-
[26]
URL https://arxiv.org/abs/2109.08238
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Poni: Potential functions for objectgoal navigation with interaction-free learning, 2022
Santhosh Kumar Ramakrishnan, Devendra Singh Chap- lot, Ziad Al-Halah, Jitendra Malik, and Kristen Grauman. Poni: Potential functions for objectgoal navigation with interaction-free learning, 2022. URL https://arxiv.org/ abs/2201.10029
-
[28]
Habitat-web: Learning embodied object- search strategies from human demonstrations at scale
Ram Ramrakhya, Eric Undersander, Dhruv Batra, and Abhishek Das. Habitat-web: Learning embodied object- search strategies from human demonstrations at scale. In CVPR, 2022
2022
-
[29]
Grounded sam: Assembling open-world models for di- verse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kun- chang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for di- verse visual tasks, 2024. URL https://arxiv.org/abs/2401. 14159
2024
-
[30]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied ai research. InICCV, 2019
2019
-
[31]
A fast marching level set method for monotonically advancing fronts.proceedings of the National Academy of Sciences, 93(4):1591–1595, 1996
James A Sethian. A fast marching level set method for monotonically advancing fronts.proceedings of the National Academy of Sciences, 93(4):1591–1595, 1996
1996
-
[32]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalk- wyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[34]
Learning to Learn How to Learn: Self-Adaptive Visual Navigation Using Meta-Learning
Mitchell Wortsman, Kiana Ehsani, Mohammad Raste- gari, Ali Farhadi, and Roozbeh Mottaghi. Learning to learn how to learn: Self-adaptive visual navigation using meta-learning, 2019. URL https://arxiv.org/abs/ 1812.00971
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shanghang Zhang, and Chang Liu. V oronav: V oronoi- based zero-shot object navigation with large language model.arXiv preprint arXiv:2401.02695, 2024
-
[36]
Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese
Fei Xia, Amir R. Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. Gibson Env: real- world perception for embodied agents. InComputer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on. IEEE, 2018
2018
-
[37]
Mobility vla: Multi- modal instruction navigation with long-context vlms and topological graphs
Zhuo Xu, Hao-Tien Lewis Chiang, Zipeng Fu, Mithun George Jacob, Tingnan Zhang, Tsang-Wei Ed- ward Lee, Wenhao Yu, Connor Schenck, David Rendle- man, Dhruv Shah, Fei Xia, Jasmine Hsu, Jonathan Hoech, Pete Florence, Sean Kirmani, Sumeet Singh, Vikas Sindhwani, Carolina Parada, Chelsea Finn, Peng Xu, Sergey Levine, and Jie Tan. Mobility vla: Multi- modal ins...
2025
-
[38]
Omninav: A unified framework for prospective exploration and visual-language navigation
Xinda Xue, Junjun Hu, Minghua Luo, Xie Shichao, Jin- tao Chen, Zixun Xie, Quan Kuichen, Guo Wei, Mu Xu, and Zedong Chu. Omninav: A unified framework for prospective exploration and visual-language navigation. arXiv preprint arXiv:2509.25687, 2025
-
[39]
Offline visual repre- sentation learning for embodied navigation
Karmesh Yadav, Ram Ramrakhya, Arjun Majumdar, Vincent-Pierre Berges, Sachit Kuhar, Dhruv Batra, Alexei Baevski, and Oleksandr Maksymets. Offline visual repre- sentation learning for embodied navigation. InWorkshop on Reincarnating Reinforcement Learning at ICLR 2023, 2023
2023
-
[40]
Visual semantic navigation using scene priors, 2018
Wei Yang, Xiaolong Wang, Ali Farhadi, Abhinav Gupta, and Roozbeh Mottaghi. Visual semantic navigation using scene priors, 2018. URL https://arxiv.org/abs/1810. 06543
2018
-
[41]
Sg-nav: Online 3d scene graph prompting for llm- based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm- based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024
2024
-
[42]
Unigoal: Towards universal zero- shot goal-oriented navigation
Hang Yin, Xiuwei Xu, Linqing Zhao, Ziwei Wang, Jie Zhou, and Jiwen Lu. Unigoal: Towards universal zero- shot goal-oriented navigation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19057–19066, 2025
2025
-
[43]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In International Conference on Robotics and Automation (ICRA), 2024
2024
-
[44]
L3mvn: Leveraging large language models for visual target nav- igation
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. L3mvn: Leveraging large language models for visual target nav- igation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3554–3560,
-
[45]
doi: 10.1109/IROS55552.2023.10342512
-
[46]
A theory of geometry representations for spatial navigation.Progress in Neurobiology, 211:102228, 2022
Taiping Zeng, Bailu Si, and Jianfeng Feng. A theory of geometry representations for spatial navigation.Progress in Neurobiology, 211:102228, 2022
2022
-
[47]
Embodied navigation foundation model, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Ji- ahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, Yuxin Fan, Wenjun Li, Zhibo Chen, Fei Gao, Qi Wu, Zhizheng Zhang, and He Wang. Embodied navigation foundation model, 2025. URL https://arxiv.org/abs/2509.12129
-
[48]
Imaginenav: Prompting vision-language models as embodied navigator through scene imagination
Xinxin Zhao, Wenzhe Cai, Likun Tang, and Teng Wang. Imaginenav: Prompting vision-language models as embodied navigator through scene imagination. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Learning Representations, volume 2025, pages 94387–94401, 2025. URL https://proceedings.iclr.cc/paper files/paper/2025/file/ ...
2025
-
[49]
Esc: Exploration with soft commonsense constraints for zero- shot object navigation
Kaiwen Zhou, Kaizhi Zheng, Connor Pryor, Yilin Shen, Hongxia Jin, Lise Getoor, and Xin Eric Wang. Esc: Exploration with soft commonsense constraints for zero- shot object navigation. InInternational Conference on Machine Learning, pages 42829–42842. PMLR, 2023
2023
-
[50]
Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J. Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. Target- driven visual navigation in indoor scenes using deep reinforcement learning, 2016. URL https://arxiv.org/abs/ 1609.05143
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.