Skill Retrieval Augmentation for Agentic AI
Pith reviewed 2026-05-25 06:44 UTC · model grok-4.3
The pith
LLM agents improve by retrieving needed skills from large external corpora instead of listing every skill in their prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
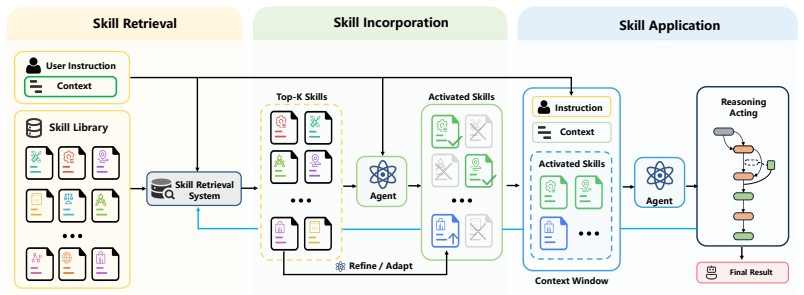
The paper formulates Skill Retrieval Augmentation (SRA) as the dynamic retrieval, incorporation, and application of skills from large external corpora, constructs SRA-Bench to measure the three stages separately, and reports that retrieval produces substantial gains in end-task accuracy while revealing that current models fail to modulate skill loading according to retrieval quality or task need.
What carries the argument
Skill Retrieval Augmentation (SRA), the on-demand retrieval and selective incorporation of skills from an external corpus rather than full enumeration in context.
If this is right
- Retrieval-based skill augmentation substantially raises agent performance on tasks that exceed native parametric capabilities.
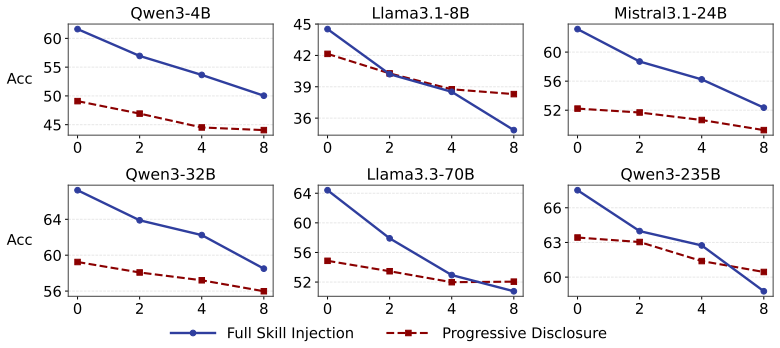
- The incorporation stage becomes the primary bottleneck once retrieval is available, because models load skills at similar rates regardless of relevance.
- SRA-Bench enables separate measurement of retrieval quality, incorporation decisions, and final task execution.
- Skill corpora can grow to tens of thousands of entries without exhausting context budgets when retrieval replaces enumeration.
Where Pith is reading between the lines
- Models may require additional training or prompting signals that explicitly teach when to request a skill versus when to solve internally.
- The observed incorporation gap suggests that future agent designs could separate retrieval from a learned policy that decides loading.
- Modular skill corpora could support agent specialization across domains if the incorporation mechanism improves.
- The benchmark's decomposed evaluation opens the door to targeted improvements in either retrieval models or incorporation logic.
Load-bearing premise
The 636 manually constructed gold skills mixed with web-collected distractors in SRA-Bench form a representative test of real-world skill retrieval and incorporation needs for agentic tasks.
What would settle it
A controlled experiment in which agents given gold skills retrieved from SRA-Bench show no accuracy gain over agents that receive only distractors or no retrieval at all on the same capability-intensive tasks.
Figures
read the original abstract
As large language models (LLMs) evolve into agentic problem solvers, they increasingly rely on external, reusable skills to handle tasks beyond their native parametric capabilities. In existing agent systems, the dominant strategy for incorporating skills is to explicitly enumerate available skills within the context window. However, this strategy fails to scale: as skill corpora expand, context budgets are consumed rapidly, and the agent becomes markedly less accurate in identifying the right skill. To this end, this paper formulates Skill Retrieval Augmentation (SRA), a new paradigm in which agents dynamically retrieve, incorporate, and apply relevant skills from large external skill corpora on demand. To make this problem measurable, we construct a large-scale skill corpus and introduce SRA-Bench, the first benchmark for decomposed evaluation of the full SRA pipeline, covering skill retrieval, skill incorporation, and end-task execution. SRA-Bench contains 5,400 capability-intensive test instances and 636 manually constructed gold skills, which are mixed with web-collected distractor skills to form a large-scale corpus of 26,262 skills. Extensive experiments show that retrieval-based skill augmentation can substantially improve agent performance, validating the promise of the paradigm. At the same time, we uncover a fundamental gap in skill incorporation: current LLM agents tend to load skills at similar rates, regardless of whether a gold skill is retrieved or whether the task actually requires external capabilities. This shows that the bottleneck in skill augmentation lies not only in retrieval but also in the base model's ability to determine which skill to load and when external loading is actually needed. These findings position SRA as a distinct research problem and establish a foundation for the scalable augmentation of capabilities in future agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates Skill Retrieval Augmentation (SRA) as a paradigm in which LLM agents dynamically retrieve, incorporate, and apply skills from large external corpora rather than enumerating them in context. It introduces SRA-Bench (5,400 test instances, 26,262-skill corpus built from 636 manually constructed gold skills plus web distractors) for decomposed evaluation of retrieval, incorporation, and execution, and reports that retrieval augmentation substantially improves performance while exposing a gap in agents' ability to decide when to load external skills.
Significance. If the empirical results hold, the work establishes SRA as a distinct research problem and supplies a benchmark that can guide future work on scalable agent capabilities. The explicit separation of retrieval from incorporation and the identification of the incorporation bottleneck are useful contributions.
major comments (2)
- [SRA-Bench construction (abstract and §3)] SRA-Bench construction (abstract and §3): the 636 gold skills are manually authored and guaranteed relevant; the manuscript supplies no external validation, distributional analysis, or comparison to real-world skill corpora showing that these skills match the noise, overlap, or discovery patterns of practical agentic tasks. Because all reported gains and the incorporation-gap observation are measured exclusively on this benchmark, the generalizability of the central claims is not yet established.
- [Experimental claims (§4–5)] Experimental claims (§4–5): the abstract asserts that retrieval 'substantially improve[s] agent performance' and that agents 'tend to load skills at similar rates' regardless of gold-skill presence or task need, yet the visible text provides no concrete baselines, metrics, statistical tests, number of runs, or error analysis. These omissions make it impossible to judge whether the reported effects are robust or load-bearing for the paradigm-level conclusions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the SRA paradigm and SRA-Bench. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [SRA-Bench construction (abstract and §3)] SRA-Bench construction (abstract and §3): the 636 gold skills are manually authored and guaranteed relevant; the manuscript supplies no external validation, distributional analysis, or comparison to real-world skill corpora showing that these skills match the noise, overlap, or discovery patterns of practical agentic tasks. Because all reported gains and the incorporation-gap observation are measured exclusively on this benchmark, the generalizability of the central claims is not yet established.
Authors: We acknowledge that the gold skills were manually authored and that the manuscript does not include external validation against proprietary real-world corpora. In the revision we will expand §3 with: (1) a detailed description of the authoring protocol and task-coverage criteria, (2) distributional statistics on skill length, category, and dependency structure, and (3) a qualitative comparison of the distractor set to skills appearing in public agent repositories and codebases. These additions will better situate the benchmark while remaining within the scope of the current study; a large-scale empirical match to closed industrial corpora would require data-access agreements that are not presently available. revision: partial
-
Referee: [Experimental claims (§4–5)] Experimental claims (§4–5): the abstract asserts that retrieval 'substantially improve[s] agent performance' and that agents 'tend to load skills at similar rates' regardless of gold-skill presence or task need, yet the visible text provides no concrete baselines, metrics, statistical tests, number of runs, or error analysis. These omissions make it impossible to judge whether the reported effects are robust or load-bearing for the paradigm-level conclusions.
Authors: Sections 4 and 5 already report concrete metrics (retrieval recall, incorporation accuracy, end-task success), explicit baselines (no-skill, oracle-skill, random-retrieval), statistical significance tests, averages over five independent runs with standard deviations, and an error analysis of incorporation failures. To prevent any misreading, we will revise the abstract to include the key quantitative deltas and will add a short “Experimental Summary” paragraph in the introduction that points readers to the relevant tables and appendix. No new experiments are required; the revision improves clarity only. revision: yes
Circularity Check
No circularity; empirical claims on manually constructed benchmark
full rationale
The paper introduces SRA as a paradigm and evaluates it via experiments on SRA-Bench (5,400 instances, 636 manually authored gold skills mixed with distractors). No equations, derivations, fitted parameters, or self-referential definitions appear in the abstract or described structure. Performance claims are direct empirical measurements rather than reductions to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The manual benchmark construction raises external validity questions but does not create circularity under the specified criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents increasingly rely on external reusable skills beyond native parametric capabilities
- domain assumption Explicit enumeration of skills in context fails to scale with corpus size
invented entities (2)
-
Skill Retrieval Augmentation (SRA) paradigm
no independent evidence
-
SRA-Bench
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Enhancing Judgment Document Generation via Agentic Legal Information Collection and Rubric-Guided Optimization
Judge-R1 improves LLM judgment document generation by combining agentic legal information retrieval with GRPO-based rubric-guided optimization, outperforming baselines on the JuDGE benchmark.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A survey that taxonomizes agent skills for LLM-based agents across representation, acquisition, retrieval, and evolution stages while reviewing methods, resources, and open challenges.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
Reference graph
Works this paper leans on
-
[1]
MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems
Qingyao Ai, Yichen Tang, Changyue Wang, Jianming Long, Weihang Su, and Yiqun Liu. Memorybench: A benchmark for memory and continual learning in llm systems.arXiv preprint arXiv:2510.17281, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Anthropic. Claude code. https://www.anthropic.com/product/claude-code, 2026. Official product page. Accessed: 2026-04-20
work page 2026
-
[3]
An analysis of fusion functions for hybrid retrieval
Sebastian Bruch, Siyu Gai, and Amir Ingber. An analysis of fusion functions for hybrid retrieval. ACM Transactions on Information Systems, 42(1):1–35, 2023
work page 2023
-
[4]
Theoremqa: A theorem-driven question answering dataset
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7889–7901, 2023
work page 2023
-
[5]
Qian Dong, Qingyao Ai, Hongning Wang, Yiding Liu, Haitao Li, Weihang Su, Yiqun Liu, Tat- Seng Chua, and Shaoping Ma. Decoupling knowledge and context: An efficient and effective retrieval augmented generation framework via cross attention. InProceedings of the ACM on Web Conference 2025, 2025
work page 2025
-
[6]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Scaling laws for dense retrieval
Yan Fang, Jingtao Zhan, Qingyao Ai, Jiaxin Mao, Weihang Su, Jia Chen, and Yiqun Liu. Scaling laws for dense retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1339–1349, 2024
work page 2024
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Unsupervised Dense Information Retrieval with Contrastive Learning
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Active retrieval augmented generation.arXiv preprint arXiv:2305.06983, 2023
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation.arXiv preprint arXiv:2305.06983, 2023
-
[11]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, et al. Mrkl systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning.arXiv preprint arXiv:2205.00445, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina S Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad W Safranek, Abid A Anwar, Andrew Zhang, et al. Medcalc- bench: Evaluating large language models for medical calculations.Advances in Neural Infor- mation Processing Systems, 37:84730–84745, 2024
work page 2024
-
[14]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020. 19
work page 2020
-
[15]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
George Ling, Shanshan Zhong, and Richard Huang. Agent skills: A data-driven analysis of claude skills for extending large language model functionality.arXiv preprint arXiv:2602.08004, 2026
-
[17]
Yujun Mao, Yoon Kim, and Yilun Zhou. Champ: A competition-level dataset for fine-grained analyses of llms’ mathematical reasoning capabilities. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13256–13274, 2024
work page 2024
-
[18]
Meta. Llama 3.3 model card. https://www.llama.com/docs/ model-cards-and-prompt-formats/llama3_3/, 2024. Accessed: 2026-04-20
work page 2024
-
[19]
Mistral AI. Mistral small 3.1. https://mistral.ai/news/mistral-small-3-1 , March
- [20]
-
[21]
OpenAI. Codex. https://openai.com/codex/, 2026. Official product page. Accessed: 2026-04-20
work page 2026
-
[22]
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Accessed: 2026-04-20
work page 2026
-
[23]
Logicbench: Towards systematic evaluation of logical reasoning ability of large language models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, and Chitta Baral. Logicbench: Towards systematic evaluation of logical reasoning ability of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13679–13707, 2024
work page 2024
-
[24]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[25]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems, 37:126544–126565, 2024
work page 2024
-
[26]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[27]
Stephen Robertson, Hugo Zaragoza, et al. The probabilistic relevance framework: Bm25 and beyond.Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009
work page 2009
-
[28]
Stephen Edward Robertson, Steve Walker, Susan Jones, Micheline M Hancock-Beaulieu, Mike Gatford, et al. Okapi at trec. 1994
work page 1994
-
[29]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[30]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
work page 2023
-
[31]
Skillsmp: Agent skills marketplace
SkillsMP. Skillsmp: Agent skills marketplace. https://skillsmp.com/, 2026. Accessed: 2026-04-26
work page 2026
-
[32]
A statistical interpretation of term specificity and its application in retrieval
Karen Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11–21, 1972
work page 1972
-
[33]
Peter Steinberger and OpenClaw Contributors. Openclaw, 2026. Open-source personal AI assistant. Accessed: 2026-04-20. 20
work page 2026
-
[34]
Wikiformer: Pre-training with structured information of wikipedia for ad-hoc retrieval
Weihang Su, Qingyao Ai, Xiangsheng Li, Jia Chen, Yiqun Liu, Xiaolong Wu, and Shengluan Hou. Wikiformer: Pre-training with structured information of wikipedia for ad-hoc retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19026–19034, 2024
work page 2024
-
[35]
Weihang Su, Qingyao Ai, Yueyue Wu, Anzhe Xie, Changyue Wang, Yixiao Ma, Haitao Li, Zhijing Wu, Yiqun Liu, and Min Zhang. Pre-training for legal case retrieval based on inter-case distinctions.ACM Transactions on Information Systems, 43(5):1–27, 2025
work page 2025
-
[36]
Dynamic and parametric retrieval-augmented generation, 2025
Weihang Su, Qingyao Ai, Jingtao Zhan, Qian Dong, and Yiqun Liu. Dynamic and parametric retrieval-augmented generation, 2025
work page 2025
-
[37]
Sigir-ap 2025 tutorial proposal: Dynamic and parametric retrieval-augmented generation
Weihang Su, Qian Dong, Qingyao Ai, and Yiqun Liu. Sigir-ap 2025 tutorial proposal: Dynamic and parametric retrieval-augmented generation. In3rd International ACM SIGIR Conference on Information Retrieval in the Asia Pacific, 2025
work page 2025
-
[38]
STARD: A Chinese statute retrieval dataset derived from real-life queries by non-professionals
Weihang Su, Yiran Hu, Anzhe Xie, Qingyao Ai, Quezi Bing, Ning Zheng, Yun Liu, Weixing Shen, and Yiqun Liu. STARD: A Chinese statute retrieval dataset derived from real-life queries by non-professionals. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10658–10671, M...
work page 2024
-
[39]
Weihang Su, Jianming Long, Changyue Wang, Shiyu Lin, Jingyan Xu, Ziyi Ye, Qingyao Ai, and Yiqun Liu. Towards unification of hallucination detection and fact verification for large language models.arXiv preprint arXiv:2512.02772, 2025
-
[40]
Miti- gating entity-level hallucination in large language models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, and Yiqun Liu. Miti- gating entity-level hallucination in large language models. InProceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pages 23–31, 2024
work page 2024
-
[41]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. DRAGIN: Dynamic retrieval augmented generation based on the real-time information needs of large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12...
work page 2024
-
[42]
Parametric retrieval augmented generation
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. Parametric retrieval augmented generation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1240–1250, 2025
work page 2025
-
[43]
Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, Yujia Zhou, and Yiqun Liu. Unsupervised real-time hallucination detection based on the internal states of large language models.arXiv preprint arXiv:2403.06448, 2024
-
[44]
SurGE: A Benchmark and Evaluation Framework for Scientific Survey Generation
Weihang Su, Anzhe Xie, Qingyao Ai, Jianming Long, Xuanyi Chen, Jiaxin Mao, Ziyi Ye, and Yiqun Liu. Surge: A benchmark and evaluation framework for scientific survey generation. arXiv preprint arXiv:2508.15658, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Judge: Benchmarking judgment document generation for chinese legal system
Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, and Yiqun Liu. Judge: Benchmarking judgment document generation for chinese legal system. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25), July 13–18, 2025, Padua, Italy, 2025
work page 2025
-
[46]
Is chatgpt good at search? investigating large language models as re-ranking agents
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. Is chatgpt good at search? investigating large language models as re-ranking agents. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 14918–14937, 2023
work page 2023
-
[47]
Yuqiao Tan, Shizhu He, Huanxuan Liao, Jun Zhao, and Kang Liu. Dynamic parametric retrieval augmented generation for test-time knowledge enhancement.arXiv preprint arXiv:2503.23895, 2025. 21
-
[48]
Multi-field tool retrieval.arXiv preprint arXiv:2602.05366, 2026
Yichen Tang, Weihang Su, Yiqun Liu, and Qingyao Ai. Multi-field tool retrieval.arXiv preprint arXiv:2602.05366, 2026
-
[49]
Analytical search.arXiv preprint arXiv:2602.11581, 2026
Yiteng Tu, Shuo Miao, Weihang Su, Yiqun Liu, and Qingyao Ai. Analytical search.arXiv preprint arXiv:2602.11581, 2026
-
[50]
Robust fine-tuning for retrieval augmented generation against retrieval defects
Yiteng Tu, Weihang Su, Yujia Zhou, Yiqun Liu, and Qingyao Ai. Robust fine-tuning for retrieval augmented generation against retrieval defects. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1272–1282, 2025
work page 2025
-
[51]
Improve Large Language Model Systems with User Logs
Changyue Wang, Weihang Su, Qingyao Ai, and Yiqun Liu. Improve large language model systems with user logs.arXiv preprint arXiv:2602.06470, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Changyue Wang, Weihang Su, Qingyao Ai, and Yiqun Liu. Joint evaluation of answer and reasoning consistency for hallucination detection in large reasoning models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33377–33385, 2026
work page 2026
-
[53]
Knowledge editing through chain-of-thought
Changyue Wang, Weihang Su, Qingyao Ai, Yichen Tang, and Yiqun Liu. Knowledge editing through chain-of-thought. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10684–10704, 2025
work page 2025
-
[54]
Decoupling reasoning and knowledge injection for in-context knowledge editing
Changyue Wang, Weihang Su, Qingyao Ai, Yujia Zhou, and Yiqun Liu. Decoupling reasoning and knowledge injection for in-context knowledge editing. InFindings of the Association for Computational Linguistics: ACL 2025, pages 24543–24562, 2025
work page 2025
-
[55]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[57]
C- pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C- pack: Packed resources for general chinese embeddings. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pages 641–649, 2024
work page 2024
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[60]
Glm-5.1: Towards long-horizon tasks
Z.ai. Glm-5.1: Towards long-horizon tasks. https://z.ai/blog/glm-5.1, April 2026. Accessed: 2026-04-20
work page 2026
-
[61]
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. Toolqa: A dataset for llm question answering with external tools.Advances in Neural Information Processing Systems, 36:50117–50143, 2023
work page 2023
-
[62]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Bench- marking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877, 2024. 22 A Dataset-Specific Construction Details This appendix provides the ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
name: Canonical theorem name
-
[64]
description: One sentence summarizing what the theorem computes or states
-
[65]
•When to recognize that this theorem applies
Content (Markdown): •Core principle or theorem statement. •When to recognize that this theorem applies. •Step-by-step application procedure. •Common errors or pitfalls. •One worked example using a new problem (not from the problems above). A.1.2 Expert Revision Beyond the general revision principles described in Section 3.2, TheoremQA requires special att...
work page 2016
-
[66]
Compute each high-growth dividend:D t =D 0(1+g1)t fort= 1, . . . , n
-
[67]
Discount each to present: PV t =D t/(1+r)t
-
[68]
Note:the numerator isD n+1 =D n(1+g2),notD n
Terminal value at yearn: TV n =D n(1+g2)/(r−g2). Note:the numerator isD n+1 =D n(1+g2),notD n
-
[69]
Discount terminal value: PV(TV)=TV n/(1+r)n
-
[70]
Critical Pitfalls: • Wrong terminal value base: TV usesD n+1, notD n
Sum:P 0 =P PVt +PV(TV). Critical Pitfalls: • Wrong terminal value base: TV usesD n+1, notD n. • Missing growth step: givenD 0, the first dividend isD 1 =D 0(1+g), notD 0. • Rate format: if r and g are given as percentages (e.g., 12%), convert to decimals (0.12) before computing r−g. Worked Example: D0 = 4, g1 = 18% for 3 years, then g2 = 6%, r= 14% . D1 =...
-
[72]
Special Cases:L(n,1) =n!;L(n, n) = 1
ComputeL(n, k) = n! k! × n−1 k−1 . Special Cases:L(n,1) =n!;L(n, n) = 1. ▷No distinction from Stirling numbers; models confuse ordered vs. unordered partitions Worked Example:Divide 8 elements into 5 ordered subsets: L(8,5) = 8! 5! × 7 4 = 336×35 = 11760 . ▷Same parameters as an input instance Golden Skill name:Lah Numbers description: Computing Lah numbe...
-
[73]
Identifyn(total elements) andk(number of groups)
-
[74]
Verify the problem asks fororderedgroups (sequences, ranked committees, lists)—not unordered subsets
-
[75]
ComputeL(n, k) = n! k! × n−1 k−1
-
[76]
Sanity check:L(n,1) =n!,L(n, n) = 1. Distinguishing from Related Problems: Concept Groups ordered? Within-group order? Lah numberL(n, k)No Yes Stirling 2nd kindS(n, k)No No k!×S(n, k)Yes No Key distinction: “subsets” or “groups” (unordered within) → Stirling numbers. “Sequences,” “ranked lists,” or “ordered subsets”→Lah numbers. Worked Example:Divide 4 bo...
-
[77]
name: Canonical inference rule name
-
[78]
description: One sentence summarizing what the rule states and its scope
-
[79]
Content (Markdown): •Formal statement of the inference rule. •When to recognize that this rule applies. •Step-by-step application procedure. •Common errors or pitfalls. •One worked example using a new problem (not from the problems above). 2https://plato.stanford.edu, a comprehensive, peer-reviewed reference for logic and philosophy. 27 A.2.2 Expert Revis...
-
[80]
Identify the conditional premise: extract antecedent A and consequent C
-
[81]
Confirm that C is negated in the premises
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.