WorldFly: A World-Model-Based Vision-Language-Action Model for UAV Navigation
Pith reviewed 2026-06-28 01:27 UTC · model grok-4.3
The pith
A world-model-based VLA model lets UAVs navigate occluded urban environments by jointly predicting future video and actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
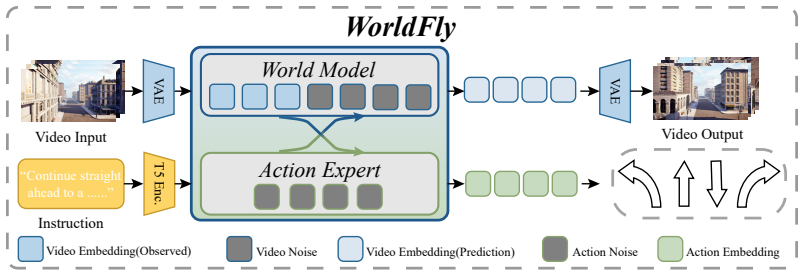
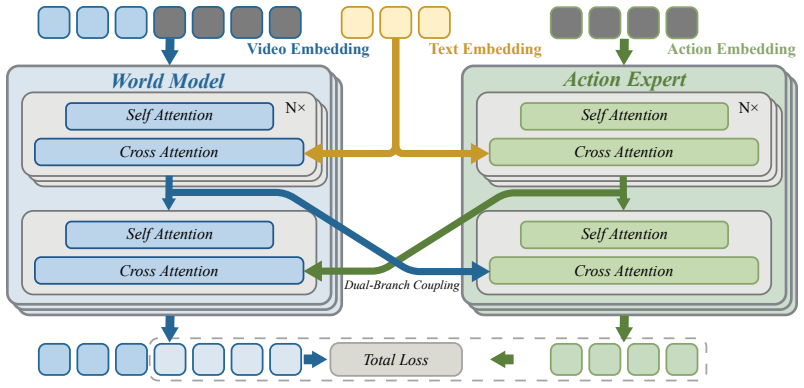
WorldFly is a world-model-based VLA framework that employs a dual-branch coupled flow matching mechanism to jointly generate future video predictions and navigation actions, thereby explicitly guiding the agent's policy via spatial imagination.
What carries the argument
dual-branch coupled flow matching mechanism that jointly generates future video predictions and navigation actions
If this is right
- Navigation policies gain robustness to partial observability when future video is predicted alongside actions.
- Performance advantages appear most clearly in environments outside the training distribution.
- World models can be integrated into embodied aerial agents through joint generation rather than separate modules.
- The same coupled prediction approach may reduce the impact of drastic viewpoint transitions during flight.
Where Pith is reading between the lines
- The same joint prediction structure could be tested on ground robots that also face sudden occlusions in cluttered spaces.
- Extending the benchmark to include wind, lighting changes, or moving obstacles would expose additional limits of current VLA methods.
- Flow-matching-based world models may transfer to other robotic domains where long-horizon spatial reasoning is required.
Load-bearing premise
Imagining future states supplies the spatial information needed for good decisions when current camera views are blocked or change abruptly.
What would settle it
If a standard VLA model without any future-state prediction matches or exceeds WorldFly's success rate on the Urban Canyon Traversal Benchmark in unseen environments, the central claim would be falsified.
Figures

read the original abstract
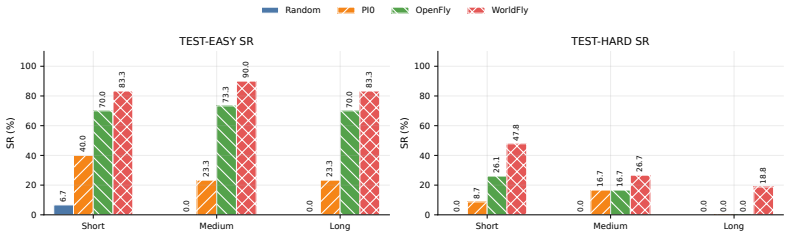
End-to-end Vision-Language-Action (VLA) models have shown promise in UAV navigation. However, existing approaches typically rely on historical observations to directly predict actions, often struggling in dense urban environments where severe occlusions and sharp turns result in drastic viewpoint transitions. We argue that the ability to "imagine" future states -- inherent in World Models -- is critical for robust decision-making under such partial observability. To address this, we construct a challenging Urban Canyon Traversal Benchmark, specifically designed to evaluate spatial understanding in scenarios characterized by severe occlusions and drastic viewpoint transitions. To this end, we propose WorldFly, a novel world-model-based VLA framework that employs a dual-branch coupled flow matching mechanism to jointly generate future video predictions and navigation actions, thereby explicitly guiding the agent's policy via spatial imagination. Extensive evaluations on our benchmark demonstrate that WorldFly outperforms other baselines, particularly in unseen environments, validating the effectiveness of integrating world models into embodied aerial agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WorldFly, a world-model-based Vision-Language-Action framework for UAV navigation in dense urban environments. It employs a dual-branch coupled flow matching mechanism to jointly generate future video predictions and navigation actions, explicitly incorporating spatial imagination to address partial observability from occlusions and viewpoint changes. The paper also presents the Urban Canyon Traversal Benchmark and claims that extensive evaluations show WorldFly outperforming baselines, particularly in unseen environments, thereby validating the value of integrating world models into embodied aerial agents.
Significance. If the empirical claims hold after proper validation, the work would offer concrete evidence that explicit future-state prediction improves robustness in VLA models for aerial navigation under severe partial observability. The specialized benchmark targeting urban canyon scenarios with drastic viewpoint transitions could become a useful community resource for testing generalization in embodied AI.
major comments (3)
- [Experiments] Experiments section: The central claim attributes outperformance (especially in unseen environments) to the integration of world models via future video prediction. However, no ablation is described that disables or decouples the video-generation branch while retaining the action-prediction components, model capacity, and training data; without this, the attribution to the world-model component cannot be established.
- [Abstract, Experiments] Abstract and Experiments section: The assertion of outperformance and 'extensive evaluations' is presented without any quantitative metrics, baseline names and descriptions, dataset statistics, error bars, or experimental protocol details, rendering the validation claim impossible to assess from the manuscript.
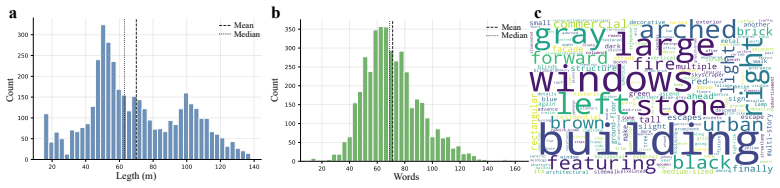
- [Benchmark] Benchmark section: The Urban Canyon Traversal Benchmark is introduced as the key testbed for the generalization claim, yet no details are supplied on its size, number of environments, definition of 'unseen' splits, or occlusion/viewpoint statistics, which are load-bearing for interpreting the reported gains.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence summarizing the evaluation metrics (e.g., success rate, collision rate) used to support the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional detail will strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim attributes outperformance (especially in unseen environments) to the integration of world models via future video prediction. However, no ablation is described that disables or decouples the video-generation branch while retaining the action-prediction components, model capacity, and training data; without this, the attribution to the world-model component cannot be established.
Authors: We agree that an ablation isolating the video-generation branch is required to support attribution of gains to the world-model component. In the revised manuscript we will add this ablation: a variant trained with identical capacity and data but with the video branch disabled, reporting performance differences on the benchmark (including unseen environments). revision: yes
-
Referee: [Abstract, Experiments] Abstract and Experiments section: The assertion of outperformance and 'extensive evaluations' is presented without any quantitative metrics, baseline names and descriptions, dataset statistics, error bars, or experimental protocol details, rendering the validation claim impossible to assess from the manuscript.
Authors: The current abstract and experiments section indeed omit these quantitative elements. We will revise the abstract to report key metrics and baseline names, and expand the experiments section with baseline descriptions, dataset statistics, error bars, and full protocol details so that the validation claims can be properly evaluated. revision: yes
-
Referee: [Benchmark] Benchmark section: The Urban Canyon Traversal Benchmark is introduced as the key testbed for the generalization claim, yet no details are supplied on its size, number of environments, definition of 'unseen' splits, or occlusion/viewpoint statistics, which are load-bearing for interpreting the reported gains.
Authors: We acknowledge that the benchmark description lacks these load-bearing specifications. The revised manuscript will include the benchmark size, number of environments, precise definition of the 'unseen' splits, and statistics on occlusions and viewpoint transitions. revision: yes
Circularity Check
No circularity in claimed derivation or validation
full rationale
The paper advances an empirical architecture (dual-branch flow matching for joint video/action prediction) and reports comparative performance on a newly constructed benchmark. No equations, parameter fits, or first-principles derivations are present that reduce a claimed prediction to its own inputs by construction. The central validation claim rests on outperformance versus baselines rather than any self-referential loop, self-citation chain, or renaming of known results. This is a standard empirical ML evaluation structure with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025
2025
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control. corr, abs/2410.24164, 2024. doi: 10.48550.arXiv preprint ARXIV .2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Mind: Learning a dual-system world model for real-time planning and implicit risk analysis, 2025
Xiaowei Chi, Kuangzhi Ge, Jiaming Liu, Siyuan Zhou, Peidong Jia, Zichen He, Yuzhen Liu, Tingguang Li, Lei Han, Sirui Han, Shanghang Zhang, and Yike Guo. Mind: Learning a dual-system world model for real-time planning and implicit risk analysis, 2025
2025
-
[5]
Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, et al. Openfly: A comprehensive platform for aerial vision-language navigation.arXiv preprint arXiv:2502.18041, 2025
-
[6]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, Yuxin Jiang, Yue Hu, Jingbin Cai, Si Liu, Jianlan Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Yume: An interactive world generation model.arXivpreprintarXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
-
[12]
Valerii Serpiva, Artem Lykov, Artyom Myshlyaev, Muhammad Haris Khan, Ali Alridha Ab- dulkarim, Oleg Sautenkov, and Dzmitry Tsetserukou. Racevla: Vla-based racing drone naviga- tion with human-like behaviour.arXiv preprint arXiv:2503.02572, 2025
-
[13]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators.arXiv preprint arXiv:2512.06963, 2025
-
[14]
Xiangyu Wang, Donglin Yang, Yue Liao, Wenhao Zheng, Bin Dai, Hongsheng Li, Si Liu, et al. Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning.arXiv preprint arXiv:2505.15725, 2025. 10 A Model Configuration A.1 Training Configuration We evaluate three models,WorldFly,OpenFly, andPi-0-UA V, under identical training settings...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.