Sequential Planning via Anchored Robotic Keypoints
Pith reviewed 2026-06-30 04:56 UTC · model grok-4.3
The pith
SPARK plans robotic tasks with one LLM call to a behavior tree and spends the rest of its budget on perception robustness via alternative prompts and recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
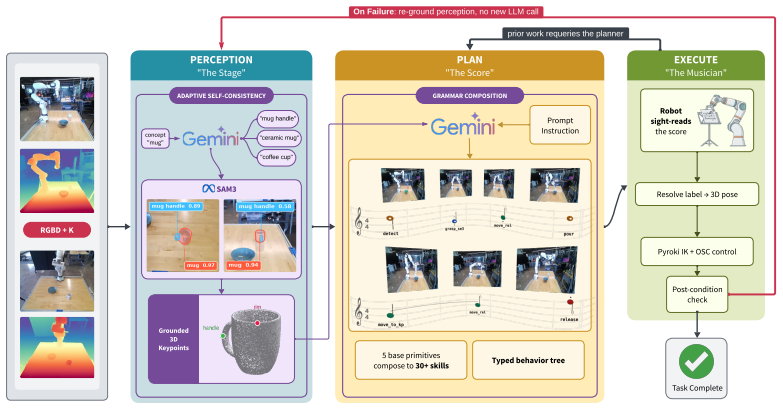
SPARK shows that sequential planning succeeds when a single LLM call produces a typed behavior tree of composable primitives that already embed low-level control, while the remaining budget is allocated to perception through three alternative text prompts evaluated by SAM3 and a recovery loop that retries primitives against new detections without any further LLM calls.
What carries the argument
A typed behavior tree of composable primitives, each containing its own motion, grasping, depth geometry, and checkable post-condition.
If this is right
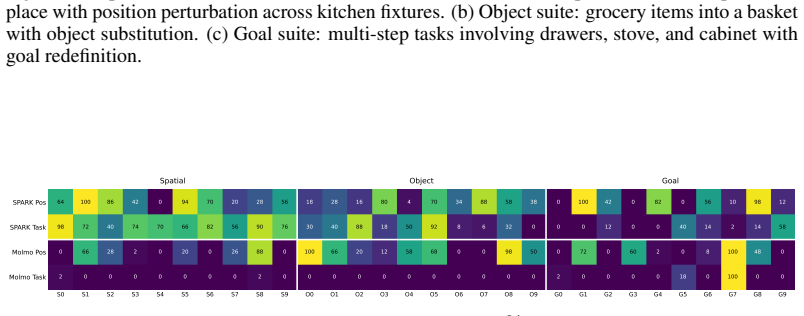
- Alternative prompts add 27.7 points on the spatial suite and 10.0 on the object suite.
- The recovery loop contributes an additional 5.0 points overall.
- The identical primitives achieve 68 percent average success across UR10e, Franka FR3, and bimanual Franka on nine tasks.
- Detector, planner, and controller modules can be swapped independently because they sit behind the typed plan.
- Every trial produces a verified, labeled trajectory that can supply training data for future learned policies.
Where Pith is reading between the lines
- The logged trajectories could reduce the need for teleoperation when collecting data for vision-language-action models.
- Because the plan is expressed as checkable post-conditions, failures can be attributed to specific modules rather than the entire policy.
- The modular structure suggests that replacing SAM3 with a stronger detector would improve performance without changing the planner or controllers.
- Extending the primitive library could allow the same planning approach to cover longer-horizon tasks without increasing LLM usage.
Load-bearing premise
Perception failures dominate and three alternative prompts plus a recovery loop without new LLM calls recover most failures across position and task changes.
What would settle it
A controlled experiment on the same six LIBERO-PRO cells where restricting the system to a single prompt and disabling the recovery loop drops success below 20 percent while an LLM re-planning baseline exceeds 30 percent.
Figures







read the original abstract
We present Sequential Planning via Anchored Robotic Keypoints, SPARK, a training-free neurosymbolic manipulation system that reaches 43.7% on six LIBERO-PRO position \& task cells, more than doubling CaP-Agent0 and Vision-Language-Action (VLA) baselines. CaP-Agent0, a multi-turn code-generation agent, achieves 18.2% by re-querying an LLM at every turn, but its restart-from-scratch solution proves costly against minor policy failures. Perception is the layer that fails most under position and task changes so SPARK spends its computation there. A single Gemini call composes the plan as a typed behavior tree (BT) of composable primitives, each already containing the low-level control (motion, grasping, depth geometry) a code-generation agent would otherwise regenerate on every trial. The rest of the budget goes to perception: a second Gemini call proposes three alternative text prompts per object, SAM3 evaluates each, and we keep the prompt$\to$label pair with the most confident detection and a recovery loop then retries a failed primitive against freshly detected objects, with no new LLM call. The alternative prompts add +27.7 points on the spatial suite and +10.0 on the object suite, with the recovery loop adding +5.0 overall. SPARK runs the same primitives on three robot families (UR10e, Franka FR3, bimanual Franka) across nine unique tasks at twenty trials each, averaging 68%. Since the detector, planner, and controller modules sit behind the typed plan, they swap independently without training, and each primitive's checkable post-condition traces a failure to the corresponding module or a kinematic limit. Every trial logs a verified, labeled trajectory, so a training-free planner that already beats VLAs can supply the data those policies need without teleoperation. Project page: https://cwru-aism.github.io/spark-page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SPARK, a training-free neurosymbolic robotic manipulation system. It generates a typed behavior tree via a single Gemini LLM call, allocates remaining compute to perception via three alternative text prompts per object (evaluated by SAM3) plus a recovery loop that retries failed primitives against fresh detections without new LLM calls, and reports 43.7% success on six LIBERO-PRO position & task cells (more than doubling CaP-Agent0 at 18.2% and VLA baselines). The design is justified by the claim that perception dominates failures under position/task variation; the system is evaluated across three robot platforms on nine tasks (20 trials each, averaging 68%), supplies per-primitive post-conditions for failure tracing, and logs verified trajectories for downstream training data.
Significance. If the performance claims and failure-mode attribution hold under detailed validation, the work offers a modular, training-free alternative to end-to-end VLAs or repeated LLM re-planning that can generate labeled data for policy training and generalizes across robot hardware without retraining. The typed BT structure with checkable post-conditions and independent module swapping are concrete strengths for reproducibility and debugging.
major comments (2)
- [Abstract] Abstract: The central design premise that 'Perception is the layer that fails most under position and task changes' (justifying allocation of compute to alternative prompts + recovery rather than re-planning) is not supported by any per-module failure statistics, per-primitive error attribution, or controlled ablation isolating perception failures from the effects of the typed BT structure or single-call planning. The reported aggregate gains (+27.7 spatial, +10 object, +5 recovery) therefore cannot be unambiguously attributed to the perception module.
- [Abstract] Abstract and experimental description: The headline result (43.7% on six LIBERO-PRO cells) and all ablation deltas are presented without an explicit experimental protocol, including exact task/cell definitions, number of trials per cell, variance or statistical tests, failure-mode breakdown, or precise reproduction details for the CaP-Agent0 baseline (e.g., whether its restart-from-scratch behavior was matched exactly).
minor comments (1)
- [Abstract] Abstract: Typo in 'position \& task cells' (should be '&').
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our work. We address each major comment below. Where the manuscript requires additional detail or clarification, we have revised accordingly and will incorporate the changes in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central design premise that 'Perception is the layer that fails most under position and task changes' (justifying allocation of compute to alternative prompts + recovery rather than re-planning) is not supported by any per-module failure statistics, per-primitive error attribution, or controlled ablation isolating perception failures from the effects of the typed BT structure or single-call planning. The reported aggregate gains (+27.7 spatial, +10 object, +5 recovery) therefore cannot be unambiguously attributed to the perception module.
Authors: We agree that the abstract does not contain explicit per-module failure statistics or a controlled ablation that isolates perception from the typed BT structure and single-call planning. The manuscript does provide per-primitive post-conditions for failure tracing and reports the incremental gains from the alternative-prompt and recovery components while holding the BT fixed. However, these do not constitute a direct head-to-head comparison against repeated LLM re-planning under identical perception conditions. We will add a dedicated failure-mode breakdown table (using the logged post-condition outcomes) and a short controlled comparison in the revised manuscript to make the attribution unambiguous. revision: yes
-
Referee: [Abstract] Abstract and experimental description: The headline result (43.7% on six LIBERO-PRO cells) and all ablation deltas are presented without an explicit experimental protocol, including exact task/cell definitions, number of trials per cell, variance or statistical tests, failure-mode breakdown, or precise reproduction details for the CaP-Agent0 baseline (e.g., whether its restart-from-scratch behavior was matched exactly).
Authors: The full manuscript (Section 4 and Appendix) specifies the six LIBERO-PRO cells, 20 trials per cell, the three robot platforms, and the nine tasks. The CaP-Agent0 baseline was reproduced with its original restart-from-scratch behavior. Nevertheless, the abstract and main experimental description are concise and omit variance, statistical tests, and cell-by-cell definitions. We will expand the experimental protocol paragraph in Section 4 and add a short protocol summary to the abstract to satisfy the request for explicit reproduction details. revision: yes
Circularity Check
No circularity: empirical system description with no derivation chain
full rationale
The paper describes a training-free neurosymbolic robotic system (SPARK) and reports empirical results on LIBERO-PRO tasks, including ablations for alternative prompts and recovery loops. No mathematical derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. All performance claims (43.7% success, +27.7 spatial points, etc.) rest on direct experimental measurements rather than any reduction to inputs by construction. This is a standard empirical systems paper with no circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single LLM call can produce a valid typed behavior tree whose primitives already contain correct low-level control for the target robots.
- domain assumption Perception is the dominant failure mode under position and task variation, so extra perception budget yields larger gains than re-planning.
Reference graph
Works this paper leans on
-
[1]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Robotics: Science and Systems (RSS) 2025
2025
-
[4]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
H. Fang, J. Duan, D. Clay, S. Wang, S. Liu, W. Huang, X. Fan, W.-C. Tsai, S. Chen, Y . R. Wang, S. Xing, J. Cho, J. S. Park, A. Eftekhar, P. Sushko, K. Farley, A. Wadhwa, C. Harrison, W. Han, Y .-C. Lee, E. VanderBilt, R. Hendrix, S. Ellawela, L. Ngoo, J. Chai, Z. Ren, A. Farhadi, D. Fox, and R. Krishna. Molmoact2: Action reasoning models for real-world d...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2023. arXiv:2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. LIBERO-PRO: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Sparse Autoencoders Reveal Interpretable and Steerable Features in VLA Models
A. Swann, L. McGranahan, H. Buurmeijer, M. Kennedy III, and M. Schwager. Sparse autoencoders reveal interpretable and steerable features in VLA models.arXiv preprint arXiv:2603.19183, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [10]
-
[11]
R. Hu, N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Doll ´ar, N. Ravi, K. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. Ruano, K. Jeffrey, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Retti...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotar, P. Sermanet, N. Brown, T. Jackson, L. Luu, S. Levine, K. Hausman, and B. Ichter. Inner monologue: Embodied reasoning through planning with language models. InConference on Robot Learning (CoRL), 2022. arXiv:2207.05608
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Gemini Robotics Team. Gemini robotics 1.5: Pushing the frontier of generalist robots with ad- vanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Google DeepMind technical report
-
[16]
Z. Zhu, S. Wu, S. Zhao, Z. Zhao, S. Li, Y . Wang, F. Li, and H. Luo. NS-VLA: Towards neuro-symbolic vision-language-action models.arXiv preprint arXiv:2603.09542, 2026. doi: 10.48550/arXiv.2603.09542
-
[17]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models, 2025. URLhttps://arxiv.org/abs/2510.13626
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Code as Policies: Language Model Programs for Embodied Control
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InIEEE International Conference on Robotics and Automation (ICRA), 2023. arXiv:2209.07753
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor. ChatGPT for robotics: Design principles and model abilities.arXiv preprint arXiv:2306.17582, 2023
-
[20]
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. ProgPrompt: Generating situated robot task plans using large language models. In IEEE International Conference on Robotics and Automation (ICRA), 2023. arXiv:2209.11302
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxPoser: Composable 3d value maps for robotic manipulation with language models. InConference on Robot Learning (CoRL), 2023. arXiv:2307.05973
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [22]
-
[23]
B. Liu, Y . Jiang, X. Zhang, Q. Liu, S. Zhang, J. Biswas, and P. Stone. LLM+P: Empowering large language models with optimal planning proficiency.arXiv preprint arXiv:2304.11477, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
X. Chen, M. Lin, N. Sch ¨arli, and D. Zhou. Teaching large language models to self-debug. In International Conference on Learning Representations (ICLR), 2024. arXiv:2304.05128
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
W. Xiao, J. Xie, T. Zhang, H. Lin, L. M. Fu, H. Xue, J. Lu, Y . Yang, C. Dai, Z. Wang, J. Wu, G. Wang, S. S. Sastry, K. Goldberg, L. J. Fan, Y . Zhu, and G. Shi. Enpire: Agentic robot policy self-improvement in the real world, 2026. URLhttps://arxiv.org/abs/2606.19980
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei. ReKep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation. InConference on Robot Learning (CoRL), pages 4573–4602, 2024. arXiv:2409.01652. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Predicate Invention from Pixels via Pretrained Vision-Language Models
A. Athalye, N. Kumar, T. Silver, Y . Liang, J. Wang, T. Lozano-P´erez, and L. P. Kaelbling. From pixels to predicates: Learning symbolic world models via pretrained vision-language models. IEEE Robotics and Automation Letters (RA-L), 11:4002–4009, 2026. arXiv:2501.00296; ear- lier ICLR 2025 version titled “Predicate Invention from Pixels via Pretrained Vi...
-
[30]
X. Chen, Y . Cai, Y . Mao, M. Li, W. Yang, W. Xu, and J. Wang. Integrating intent understanding and optimal behavior planning for behavior tree generation from human instructions. InPro- ceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI), pages 6832–6840, 2024. doi:10.24963/ijcai.2024/755
- [31]
- [32]
- [33]
-
[34]
J. Kwok, C. Agia, R. Sinha, M. Foutter, S. Li, I. Stoica, A. Mirhoseini, and M. Pavone. RoboMonkey: Scaling test-time sampling and verification for vision-language-action models. InConference on Robot Learning (CoRL), 2025. PMLR 305:3200–3217; arXiv:2506.17811; Stanford + UC Berkeley + NVIDIA Research
-
[35]
Playful Agentic Robot Learning
J. Zhang, J. Ge, H. Yoo, L. Fu, Z. Yang, Y . Liu, R. Saravanan, S. Yin, J. Yu, D. Niu, Z. Wang, R. Herzig, K. Goldberg, Y . Bai, D. M. Chan, I. Stoica, A. Kanazawa, J. Lei, H. Feng, and T. Darrell. Playful agentic robot learning.arXiv preprint arXiv:2606.19419, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
J. Gardner, I. Simon, E. Manilow, C. Hawthorne, and J. Engel. Mt3: Multi-task multitrack music transcription, 2022. URLhttps://arxiv.org/abs/2111.03017
-
[37]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. arXiv:2304.02643
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer. SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InEuropean Conference on Computer Vision (ECCV), 2024. arXiv:2303.05499. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
M. Minderer, A. Gritsenko, A. Stone, M. Neumann, D. Weissenborn, A. Dosovitskiy, A. Ma- hendran, A. Arnab, M. Dehghani, Z. Shen, X. Wang, X. Zhai, T. Kipf, and N. Houlsby. Simple open-vocabulary object detection with vision transformers. InEuropean Conference on Com- puter Vision (ECCV), 2022. arXiv:2205.06230; OWL-ViT
-
[41]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandku- mar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Anonymous. A unified framework for real-time failure handling in robotics using VLMs, reactive planner and behavior trees.arXiv preprint arXiv:2503.15202, 2025. ABB YuMi; AI2-THOR
-
[43]
S. Pchelintsev, M. Patratskiy, A. Onishchenko, A. Korchemnyi, A. Medvedev, U. Vinogradova, I. Galuzinsky, A. Postnikov, A. K. Kovalev, and A. I. Panov. LERa: Replanning with visual feedback in instruction following.arXiv preprint arXiv:2507.05135, 2025. doi:10.48550/ arXiv.2507.05135
-
[44]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023. arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [45]
-
[46]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Ir- pan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Y . Xie, Y . Yan, Y . Zhao, H. Wang, and Y . Jin. STRONG-VLA: Decoupled robustness learning for vision-language-action models under multimodal perturbations.arXiv preprint arXiv:2604.10055, 2026. Submitted 11 Apr 2026; 28 perturbation types
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [49]
-
[50]
J. Guo, Z. Wu, C. Tu, Y . Ma, X. Kong, Z. Liu, J. Ji, S. Zhang, Y . Chen, K. Chen, Q. Dou, Y . Yang, X. Liu, H. Zhao, W. Lv, and S. Li. On robustness of vision-language-action model against multi-modal perturbations. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2510.00037; method named RobustVLA; OpenReview cS6xizdYD5; 17 per...
-
[51]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, H. Koppula, Y . LeCun, I. Misra, M. Rab- bat, and M. Shvets. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025. arXiv:2506.09985
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024. ICML 2025; arXiv:2411.04983
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
P. Wang, Y . He, X. Lv, Y . Zhou, L. Xu, J. Yu, and J. Gu. PartNeXt: A next-generation dataset for fine-grained and hierarchical 3d part understanding. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2025
2025
-
[54]
Y . Tian, J. Jacob, Y . Huang, J. Zhao, E. L. Gu, P. Ma, A. Zhang, F. Javid, B. Romero, S. Chitta, S. Sueda, H. Li, and W. Matusik. Fabrica: Dual-arm assembly of general multi-part objects via integrated planning and learning. In9th Annual Conference on Robot Learning (CoRL), Oral, Best Paper Award, 2025. URLhttps://openreview.net/forum?id=aSUNzvEJIf. arX...
-
[55]
M. Zhou, R. Li, X. Lyu, Z. Song, Z. Huang, C. Zheng, C. Rupprecht, A. Vedaldi, and S. Wu. Articraft: An agentic system for scalable articulated 3d asset generation, 2026. URLhttps: //arxiv.org/abs/2605.15187
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [56]
-
[57]
FlexiTac: A Low-Cost, Open-Source, Scalable Tactile Sensing Solution for Robotic Systems
B. Huang and Y . Li. Flexitac: A low-cost, open-source, scalable tactile sensing solution for robotic systems.arXiv preprint arXiv:2604.28156, 2026. arXiv:2604.28156
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiri- any, and Y . Zhu. Robosuite: A modular simulation framework and benchmark for robot learn- ing. InarXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[59]
application/json
B. Lim, J. Kim, J. Kim, Y . Lee, and F. C. Park. EquiGraspFlow: SE(3)-equivariant 6-DoF grasp pose generative flows. InConference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Research, pages 5067–5086. PMLR, 2024. 15 A Implementation Details We document the per-component settings sufficient to reproduce SPARKon LIBERO-PROand CAP-...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.