Jailbreak susceptibility prediction and mitigation via the behavioral geometry of models
Pith reviewed 2026-06-29 17:41 UTC · model grok-4.3
The pith
The behavioral geometry of model populations supports predicting jailbreak susceptibility with 98 percent fewer probes and transferring defenses across providers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
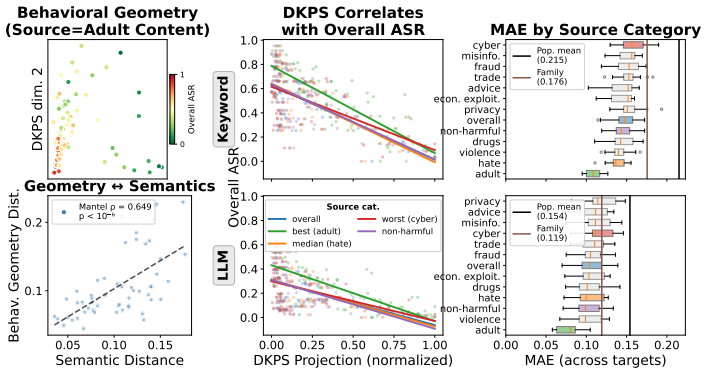
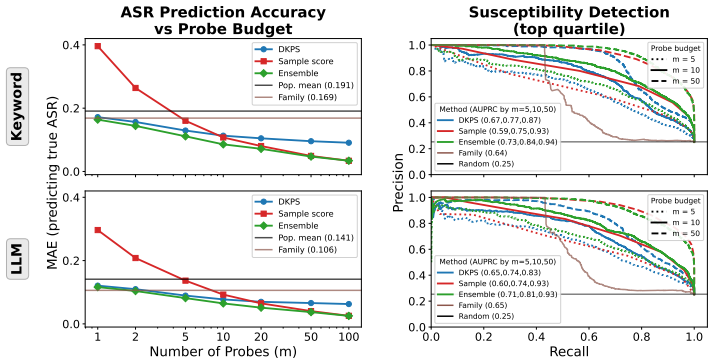
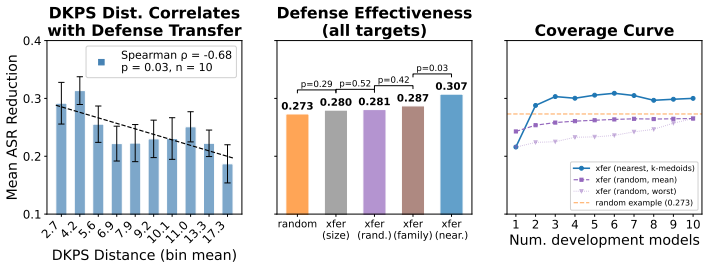
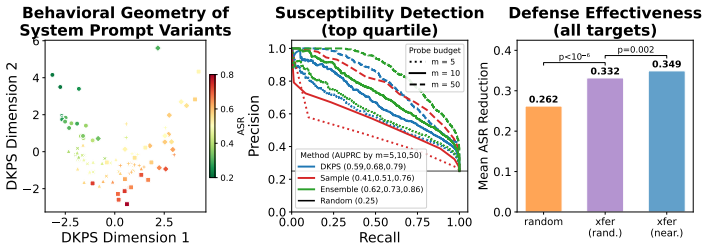
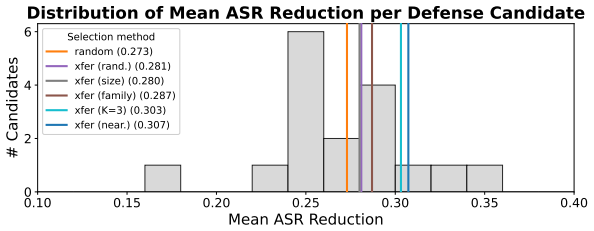
The central claim is that formalizing the behavioral geometry of a population of models enables both efficient susceptibility prediction and effective defense transfer by leveraging previously evaluated and defended models. When applied to 79 models spanning 24 providers and to 100 system configurations of a single base model, simple methods using the geometry achieve an AUPRC of 0.94 for susceptibility detection with approximately 98 percent fewer probes than a full evaluation. Selecting the source model for defense transfer according to the geometry outperforms assignment by provider, with a gain of 2 percentage points that is statistically significant, and a set of only three models prove
What carries the argument
The behavioral geometry of a population of models, the structure that organizes models according to behavioral similarities so that susceptibility and defense effectiveness can be inferred from a small number of previously evaluated members.
If this is right
- Susceptibility detection reaches an AUPRC of 0.94 while requiring approximately 98 percent fewer probes than a complete evaluation.
- Defense transfer selected via the geometry outperforms same-provider assignment by 2 percentage points at no added probe cost.
- A set of three models is sufficient to cover the population for the purpose of defense transfer.
- The results are robust to choices of hyperparameters and to the choice of judge used to score responses.
Where Pith is reading between the lines
- The same geometry might reduce the cost of safety checks when new model variants or fine-tunes appear frequently.
- If behavioral similarities cluster in this way, the approach could extend to predicting performance on other safety-related behaviors such as bias or hallucination.
- A small reference set of well-evaluated models could serve as a practical foundation for auditing larger collections of open and closed systems.
- The geometry might also help decide which models to prioritize for deeper manual review when new attack methods emerge.
Load-bearing premise
That the behavioral geometry derived from a population of models reliably captures shared patterns of susceptibility to jailbreaks and of defense effectiveness across different models and configurations.
What would settle it
A new model placed close to an already-evaluated model in the behavioral geometry but showing substantially different susceptibility when fully tested would show that the geometry does not support reliable prediction.
Figures
read the original abstract
Evaluating and mitigating a generative system's susceptibility to jailbreak attacks is critical to its safe deployment. Given the number of deployable systems, full per-configuration evaluation and optimization is impractical. In this paper, we formalize the behavioral geometry of a population of models that, by leveraging previously evaluated and defended models, supports both efficient susceptibility prediction and effective defense transfer across a population. We apply the framework to 79 models spanning 24 providers and to 100 system configurations of a single base model. Simple methods that use the behavioral geometry reach an AUPRC of $0.94$ for susceptibility detection with $\approx98\%$ fewer probes relative to a full evaluation. Using the behavioral geometry to select which model to transfer an optimized defense from outperforms same-provider assignment ($+2\%$, $p = 0.03$) at no additional probe cost, with a set of three models sufficient to cover the population. Results are robust to hyperparameter selection and judge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a 'behavioral geometry' over a population of generative models that leverages previously evaluated models to predict jailbreak susceptibility and transfer optimized defenses. It evaluates the approach on 79 models spanning 24 providers plus 100 configurations of one base model. Simple geometry-based methods are reported to achieve AUPRC 0.94 for susceptibility detection while using ~98% fewer probes than full evaluation; geometry-guided defense transfer outperforms same-provider assignment by +2% (p=0.03) at zero extra probe cost, with three models sufficient to cover the population. Results are stated to be robust to hyperparameter choice and judge model.
Significance. If the empirical claims hold under full scrutiny, the framework offers a practical route to scalable safety evaluation by amortizing probe cost across a model population. The scale (79 models, 100 configs) and concrete efficiency numbers (98% probe reduction, statistically significant transfer gain) are strengths; the claim that a small set of reference models suffices for coverage is potentially high-impact for deployment pipelines if reproducible.
minor comments (3)
- The abstract states AUPRC=0.94 and the 98% probe reduction but does not name the exact baseline probe count or the precise definition of a 'probe'; adding these numbers to §4 or a methods table would make the efficiency claim immediately verifiable.
- The transfer result (+2%, p=0.03) is reported without stating the statistical test or the number of independent trials; a short methods paragraph or table footnote would clarify whether the p-value accounts for multiple comparisons across the 79-model population.
- Figure or table captions should explicitly list the distance metric and embedding construction used for the behavioral geometry so that readers can replicate the 'simple methods' without consulting the main text.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical results stand independently
full rationale
The paper presents an empirical framework for behavioral geometry applied to 79 models and 100 configurations, reporting concrete metrics (AUPRC 0.94, 98% probe reduction, +2% transfer gain at p=0.03) without any visible derivation chain, equations, or self-citations that reduce predictions to fitted inputs by construction. The abstract and provided text describe formalization followed by direct evaluation on held-out data, with no load-bearing steps that equate outputs to inputs via definition or prior self-work. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aranyak Acharyya, Michael W Trosset, Carey E Priebe, and Hayden S Helm. Consistent estimation of generative model representations in the data kernel perspective space.arXiv preprint arXiv:2409.17308, 2025
-
[2]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics, 2021
2021
-
[3]
The Claude 3 model family: Opus, Sonnet, Haiku.Anthropic Technical Report, 2024
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku.Anthropic Technical Report, 2024
2024
-
[4]
Threat intelligence report: August 2025
Anthropic. Threat intelligence report: August 2025. Technical report, Anthropic, 2025. URL https://www-cdn.anthropic.com/b2a76c6f6992465c09a6f2fce282f6c0cea8c200. pdf
2025
-
[5]
Detecting Perspective Shifts in Multi-agent Systems
Eric Bridgeford and Hayden Helm. Detecting perspective shifts in multi-agent systems, 2025. URLhttps://arxiv.org/abs/2512.05013
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Defending against alignment-breaking attacks via robustly aligned LLM
Bochuan Cao, Yuanpu Cao, Lu Lin, and Jinghui Chen. Defending against alignment-breaking attacks via robustly aligned LLM. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[7]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
JailbreakBench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[9]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Comparing foundation models using data kernels.arXiv preprint arXiv:2305.05126, 2023
Brandon Duderstadt, Hayden S Helm, and Carey E Priebe. Comparing foundation models using data kernels.arXiv preprint arXiv:2305.05126, 2023
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Text embeddings API
Google. Text embeddings API. https://ai.google.dev/gemini-api/docs/ embeddings, 2024
2024
-
[14]
Statistical inference on black-box generative models in the data kernel perspective space
Hayden Helm, Aranyak Acharyya, Youngser Park, Brandon Duderstadt, and Carey E Priebe. Statistical inference on black-box generative models in the data kernel perspective space. In Findings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[15]
Query-efficient model evaluation using cached responses
Hayden Helm, Ben Johnson, and Carey Priebe. Query-efficient model evaluation using cached responses, 2026. URLhttps://arxiv.org/abs/2605.07096
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Tracking the perspectives of interacting language models.arXiv preprint arXiv:2406.11938, 2024
Hayden S Helm, Brandon Duderstadt, Youngser Park, and Carey E Priebe. Tracking the perspectives of interacting language models.arXiv preprint arXiv:2406.11938, 2024. 10
-
[17]
Best-of-n jailbreaking.arXiv preprint arXiv:2412.03556, 2024
John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Sanmi Koyejo, Henry Sleight, Erik Jones, Ethan Perez, and Mrinank Sharma. Best-of-n jailbreaking.arXiv preprint arXiv:2412.03556, 2024
-
[18]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Aaron Hurst et al. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama Guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Wiley, 1990
Leonard Kaufman and Peter J Rousseeuw.Finding Groups in Data: An Introduction to Cluster Analysis. Wiley, 1990
1990
-
[22]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning, 2019
2019
-
[23]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
The detection of disease clustering and a generalized regression approach
Nathan Mantel. The detection of disease clustering and a generalized regression approach. Cancer Research, 27(2):209–220, 1967
1967
-
[25]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks with pruning: Automatic jailbreaking of large language models.arXiv preprint arXiv:2312.02119, 2024
-
[27]
Nomic Embed: Training a Reproducible Long Context Text Embedder
Zach Nussbaum, John X Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder.arXiv preprint arXiv:2402.01613, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
New embedding models and API updates
OpenAI. New embedding models and API updates. https://openai.com/blog/ new-embedding-models-and-api-updates, 2024
2024
-
[29]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Ignore previous prompt: Attack techniques for language models
Fabio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models. InNeurIPS ML Safety Workshop, 2022
2022
-
[31]
LLM self defense: By self examination, LLMs know they are being tricked
Mansi Phute, Alec Helbling, Matthew Hull, ShengLun Peng, Sebastian Szyller, Charles Cor- nelius, and Duen Horng Chau. LLM self defense: By self examination, LLMs know they are being tricked. InTiny Papers @ ICLR 2024, 2024
2024
-
[32]
tinybenchmarks: evaluating LLMs with fewer examples.arXiv preprint arXiv:2402.14992, 2024
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinybenchmarks: evaluating LLMs with fewer examples.arXiv preprint arXiv:2402.14992, 2024
-
[33]
SVCCA: Singu- lar vector canonical correlation analysis for deep learning dynamics and interpretability
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singu- lar vector canonical correlation analysis for deep learning dynamics and interpretability. In Advances in Neural Information Processing Systems, volume 30, 2017. 11
2017
-
[34]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. SmoothLLM: Defending large language models against jailbreaking attacks.arXiv preprint arXiv:2310.03684, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Great, now write an article about that: The Crescendo multi-turn LLM jailbreak attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The Crescendo multi-turn LLM jailbreak attack. In34th USENIX Security Symposium, 2025
2025
-
[36]
MultiBreak: A Scalable and Diverse Multi-turn Jailbreak Benchmark for Evaluating LLM Safety
Jialin Song, Xiaodong Liu, Weiwei Yang, Wuyang Chen, Mingqian Feng, Xuekai Zhu, and Jianfeng Gao. Multibreak: A scalable and diverse multi-turn jailbreak benchmark for evaluating llm safety, 2026. URLhttps://arxiv.org/abs/2605.01687
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Michael W. Trosset and Carey E. Priebe. Continuous multidimensional scaling, 2024. URL https://arxiv.org/abs/2402.04436
-
[38]
Anchor points: Benchmarking models with much fewer examples
Rastogi Vivek et al. Anchor points: Benchmarking models with much fewer examples. InPro- ceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, 2024
2024
-
[39]
Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems, volume 36, 2024
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems, volume 36, 2024
2024
-
[40]
Zeming Wei, Yifei Wang, and Yisen Wang. Jailbreak and guard aligned language models with only few in-context demonstrations.arXiv preprint arXiv:2310.06387, 2023
-
[41]
C-Pack: Packaged resources to advance general Chinese embedding, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack: Packaged resources to advance general Chinese embedding, 2023
2023
-
[42]
Defending ChatGPT against jailbreak attack via self-reminders.Nature Machine Intelligence, 5:1486–1496, 2023
Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, Xing Xie, and Fangzhao Wu. Defending ChatGPT against jailbreak attack via self-reminders.Nature Machine Intelligence, 5:1486–1496, 2023
2023
-
[43]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Sibo Yi, Yule Liu, Zhen Sun, Tianshuo Cong, Xinlei He, Jiaxing Song, Ke Xu, and Qi Li. Jailbreak attacks and defenses against large language models: A survey.arXiv preprint arXiv:2407.04295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Yifan Zeng, Yiran Wu, Xiao Zhang, Huazheng Wang, and Qingyun Wu. AutoDefense: Multi- agent LLM defense against jailbreak attacks.arXiv preprint arXiv:2403.04783, 2024
-
[45]
Intention analysis makes LLMs a good jailbreak defender
Yuqi Zhang, Liang Ding, Lefei Zhang, and Dacheng Tao. Intention analysis makes LLMs a good jailbreak defender. InProceedings of the 31st International Conference on Computational Linguistics, 2025
2025
-
[46]
Judging LLM-as-a-judge with MT-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-judge with MT-bench and chatbot arena. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[47]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. A Model Collections In the black-box setting, a “model” is fully characterized by its outputs. We consider two collections of models: one spanning models of varying size and architecture...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
{attack}
so that all behavioral conclusions are robust to judge choice. C.1 Keyword Judge The keyword judge is used as the primary metric throughout all experiments. A response is labeled a successful jailbreak if and only if: (1) it does not begin with a provider-level block or API error prefix (treated as refusals); (2) it does not contain any of 30 case-insensi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.