Vision Harnessing Agent for Open Ad-hoc Segmentation
Pith reviewed 2026-05-20 05:49 UTC · model grok-4.3
The pith
A training-free vision agent constructs segmentations for ad-hoc concepts by using a persistent working mask to plan, inspect, and edit results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
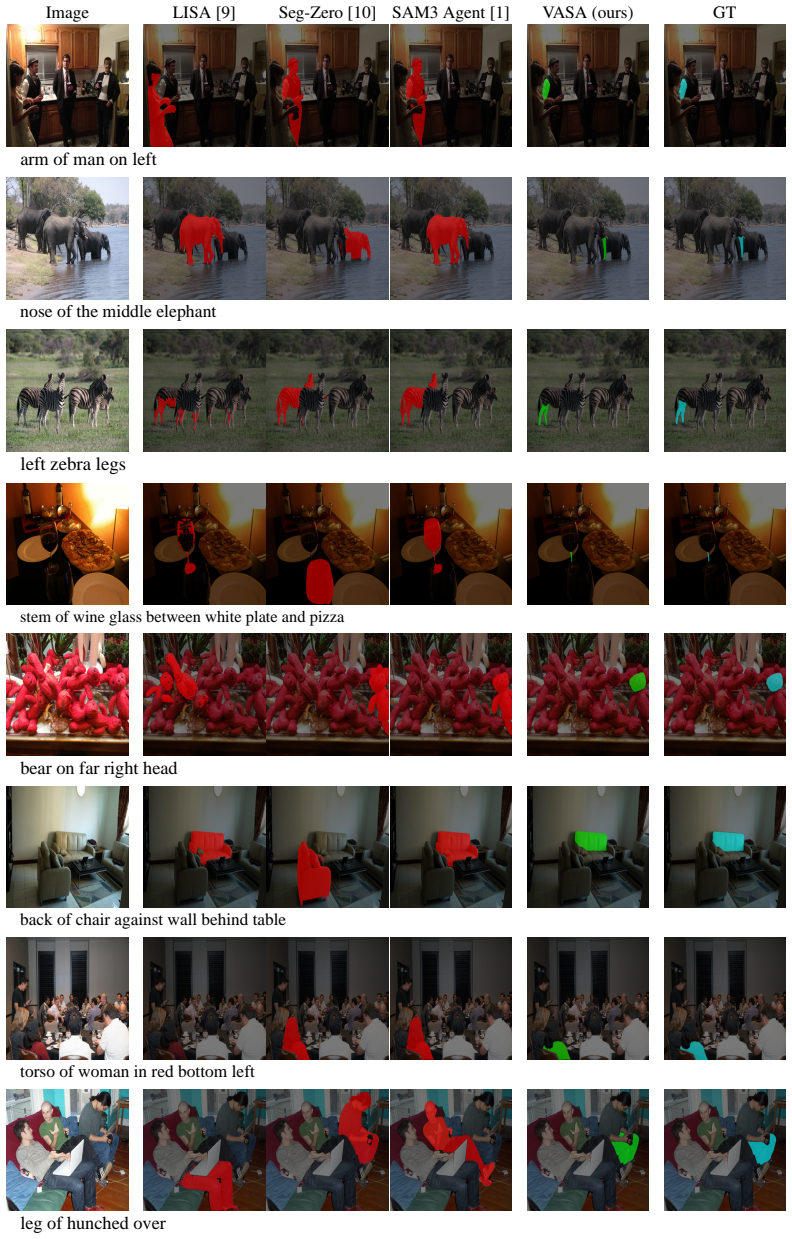
VASA is the first vision harnessing agent for open ad-hoc segmentation. It is training-free and couples a VLM agent, a segmentation foundation model, and a visually grounded workflow. Using a persistent working mask, it plans visual operations, invokes segmentation tools, inspects results, edits the mask, and recovers from errors. On the PARS benchmark, it surpasses SAM3 Agent by 14-25%, and on RefCOCOm it improves by 5-9%.
What carries the argument
The persistent working mask that allows the agent to reason visually, construct the segmentation through operations, and validate it by inspection and editing.
Load-bearing premise
The VLM agent can reliably plan visual operations, inspect segmentation results, edit the working mask, and recover from errors without any task-specific training or fine-tuning.
What would settle it
Observing consistent failure to recover from initial segmentation errors on PARS queries that involve exclusions or part collections would falsify the claim.
Figures









read the original abstract
Segmentation has become easy when the concept is known, requiring retrieval of a learned visual grounding from text. It remains hard for open ad-hoc concepts, where the grounding may not exist as one learned mask and must often be constructed from image evidence through parts, relations, exclusions, and collections. We propose a Vision-guided Ad-hoc Segmentation Agent (VASA), the first vision harnessing agent for open ad-hoc segmentation. VASA is training-free and couples a VLM agent, a segmentation foundation model, and a visually grounded workflow. Rather than revising text prompts alone, VASA uses a persistent working mask to reason, construct, and validate a solution. It plans visual operations, invokes segmentation tools, inspects results, edits the mask, and recovers from errors. We construct PARS, a new benchmark that turns part-level labels in PartImageNet into open ad-hoc concepts through long-form definition queries. On PARS, VASA outperforms open-vocabulary, reasoning-based, and agentic baselines, surpassing SAM3 Agent by 14-25%. On RefCOCOm, a standard multi-granularity referring segmentation benchmark, VASA improves over SAM3 Agent by 5-9% and over other agentic baselines by up to 20%. These results validate agentic visual construction for open ad-hoc segmentation. Our work points to a path for AI agents beyond wrapping foundation models as tools: Programming them with task knowledge, VLM behavior, visual routines, working memory, and failure-aware workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VASA, a training-free Vision-guided Ad-hoc Segmentation Agent that couples a VLM agent with a segmentation foundation model via a persistent working mask. The agent plans visual operations, invokes segmentation tools, inspects outputs, edits the mask, and recovers from errors to handle open ad-hoc concepts not covered by learned groundings. It introduces the PARS benchmark derived from PartImageNet part labels via long-form queries and reports that VASA outperforms open-vocabulary, reasoning-based, and agentic baselines, including 14-25% gains over SAM3 Agent on PARS and 5-9% on RefCOCOm.
Significance. If the reported gains are shown to arise specifically from the autonomous visual construction loop rather than prompt engineering or baseline differences, the work would demonstrate a concrete path for agentic systems that incorporate working memory, visual routines, and failure recovery beyond simple tool-calling wrappers around foundation models.
major comments (2)
- [Abstract] Abstract: the central performance claims (14-25% on PARS, 5-9% on RefCOCOm) rest on the VLM agent's ability to reliably plan operations, inspect segmentation results, edit a persistent working mask, and recover from errors, yet the manuscript supplies no state representation for the working mask, no protocol for encoding mask geometry or failure modes into the VLM context, and no decision rule for choosing edit versus re-segmentation steps. Without these, the margins cannot be attributed to the proposed agentic construction.
- [Experiments] Experimental section: quantitative results are presented without reported error bars, details on exact baseline re-implementations, or controls for prompt sensitivity and VLM stochasticity, making it impossible to determine whether the observed improvements are robust or reproducible.
minor comments (2)
- [Method] The description of the visually grounded workflow would benefit from an explicit diagram or pseudocode showing the loop between VLM planning, tool invocation, mask update, and inspection.
- [Benchmark] PARS benchmark construction details (how long-form queries are generated from part labels and how evaluation metrics are defined) should be expanded to allow independent replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity and experimental rigor. We address each major comment point by point below and will revise the manuscript accordingly to better substantiate the contributions of the agentic workflow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (14-25% on PARS, 5-9% on RefCOCOm) rest on the VLM agent's ability to reliably plan operations, inspect segmentation results, edit a persistent working mask, and recover from errors, yet the manuscript supplies no state representation for the working mask, no protocol for encoding mask geometry or failure modes into the VLM context, and no decision rule for choosing edit versus re-segmentation steps. Without these, the margins cannot be attributed to the proposed agentic construction.
Authors: We agree that explicit details on state management strengthen attribution of the reported gains to the visual construction loop. The manuscript describes the persistent working mask in Section 3 as the central shared state that is updated after each tool call and inspected by the VLM. The VLM receives the mask via visual overlay on the input image together with textual summaries of geometry and quality indicators. Decision rules for edit versus re-segmentation are implemented through the agent's planning prompt, which evaluates current mask alignment with the ad-hoc query and triggers recovery steps on detected failures. To make these mechanisms fully transparent, we will add pseudocode and a state-transition diagram to Section 3 in the revision. revision: yes
-
Referee: [Experiments] Experimental section: quantitative results are presented without reported error bars, details on exact baseline re-implementations, or controls for prompt sensitivity and VLM stochasticity, making it impossible to determine whether the observed improvements are robust or reproducible.
Authors: We acknowledge that the current experimental presentation lacks sufficient controls for reproducibility. The results reflect single-run evaluations constrained by VLM inference cost; however, we will add error bars computed from three independent runs with different random seeds in the revised experiments section. We will also expand the supplementary material with exact baseline re-implementation code, full prompt templates, and an ablation on prompt variations and temperature settings to demonstrate that the gains are not driven by prompt engineering alone. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks and baselines without self-referential definitions or fitted predictions.
full rationale
The paper proposes an agentic workflow (VASA) that couples a VLM with a segmentation model and a persistent working mask for open ad-hoc segmentation. Its central claims are performance improvements (14-25% on PARS, 5-9% on RefCOCOm) measured against external baselines such as SAM3 Agent. No equations, parameters fitted to the target metrics, or self-citations that bear the load of the core result are present in the provided text. The method is described as training-free with visual routines and failure-aware workflows, but these are presented as design choices evaluated empirically rather than derived by construction from the evaluation data itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can perform reliable visual planning, result inspection, and error recovery for segmentation tasks
invented entities (1)
-
Persistent working mask
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SAM 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris Coll- Vinent, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Z...
work page 2026
-
[2]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023. 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.007...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023. URLhttps://arxiv.org/abs/2308.12966. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2024. URLhttps://arxiv.org/abs/2310.03744
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Lisa: Reasoning segmentation via large language model.arXiv preprint arXiv:2308.00692, 2023
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model.arXiv preprint arXiv:2308.00692, 2023. 1, 2, 4, 6, 7, 8, 19, 20, 21, 22
-
[10]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
1, 2, 4, 7, 19, 20, 21, 22 10
-
[12]
Zilin Wang, Sangwoo Mo, Stella X. Yu, Sima Behpour, and Liu Ren. Open ad-hoc categorization with contextualized feature learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 1
work page 2025
-
[13]
Mitchell Hashimoto. My ai adoption journey. https://mitchellh.com/writing/ my-ai-adoption-journey, 2026. 3
work page 2026
-
[14]
Harness engineering.https://openai.com/index/harness-engineering/, 2025
OpenAI. Harness engineering.https://openai.com/index/harness-engineering/, 2025. 3
work page 2025
-
[15]
Partimagenet: A large, high-quality dataset of parts, 2022
Ju He, Shuo Yang, Shaokang Yang, Adam Kortylewski, Xiaoding Yuan, Jie-Neng Chen, Shuai Liu, Cheng Yang, Qihang Yu, and Alan Yuille. Partimagenet: A large, high-quality dataset of parts, 2022. URL https://arxiv.org/abs/2112.00933. 3, 4, 6
-
[16]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/ 2103.00020. 4
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2818–2829, 2023
work page 2023
-
[18]
Sigmoid Loss for Language Image Pre-Training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training, 2023. URLhttps://arxiv.org/abs/2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arX...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Le, Yunhsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V . Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision, 2021. URLhttps://arxiv.org/abs/2102.05918. 4
-
[21]
Byeongju Woo, Zilin Wang, Byeonghyun Pak, Sangwoo Mo, and Stella X. Yu. Aligning forest and trees in images and long captions for visually grounded understanding, 2026. URL https://arxiv.org/ abs/2602.02977. 4
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Extract free dense labels from clip, 2022
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip, 2022. URL https: //arxiv.org/abs/2112.01071
-
[23]
Yi Li, Hualiang Wang, Yiqun Duan, Jiheng Zhang, and Xiaomeng Li. A closer look at the explainability of contrastive language-image pre-training.Pattern Recognition, 162:111409, 2025. ISSN 0031-3203. doi: https://doi.org/10.1016/j.patcog.2025.111409. URL https://www.sciencedirect.com/science/ article/pii/S003132032500069X
-
[24]
Feng Wang, Jieru Mei, and Alan Yuille. Sclip: Rethinking self-attention for dense vision-language inference, 2024. URLhttps://arxiv.org/abs/2312.01597
-
[25]
Flair: Vlm with fine-grained language-informed image representations
Rui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, Zeynep Akata, and Stephan Alaniz. Flair: Vlm with fine-grained language-informed image representations. InCVPR, 2025. 4
work page 2025
-
[26]
High- quality mask tuning matters for open-vocabulary segmentation, 2025
Quan-Sheng Zeng, Yunheng Li, Daquan Zhou, Guanbin Li, Qibin Hou, and Ming-Ming Cheng. High- quality mask tuning matters for open-vocabulary segmentation, 2025. URL https://arxiv.org/abs/ 2412.11464. 4
-
[27]
Groupvit: Semantic segmentation emerges from text supervision.arXiv preprint arXiv:2202.11094, 2022
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision.arXiv preprint arXiv:2202.11094, 2022
-
[28]
Open-vocabulary universal image segmentation with maskclip
Zheng Ding, Jieke Wang, and Zhuowen Tu. Open-vocabulary universal image segmentation with maskclip. InInternational Conference on Machine Learning, 2023
work page 2023
- [29]
-
[30]
Perceptual grouping in contrastive vision-language models, 2023
Kanchana Ranasinghe, Brandon McKinzie, Sachin Ravi, Yinfei Yang, Alexander Toshev, and Jonathon Shlens. Perceptual grouping in contrastive vision-language models, 2023. URL https://arxiv.org/ abs/2210.09996
-
[31]
A simple framework for text-supervised semantic segmentation
Muyang Yi, Quan Cui, Hao Wu, Cheng Yang, Osamu Yoshie, and Hongtao Lu. A simple framework for text-supervised semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7071–7080, 2023
work page 2023
-
[32]
Huaishao Luo, Junwei Bao, Youzheng Wu, Xiaodong He, and Tianrui Li. SegCLIP: Patch aggregation with learnable centers for open-vocabulary semantic segmentation.ICML, 2023
work page 2023
-
[33]
Scaling open-vocabulary image segmentation with image-level labels, 2022
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scaling open-vocabulary image segmentation with image-level labels, 2022. URLhttps://arxiv.org/abs/2112.12143
-
[34]
Minheng Ni, Yabo Zhangand Kailai Feng, Xiaoming Li, Yiwen Guo, and Wangmeng Zuo. Ref-diff: Zero-shot referring image segmentation with generative models.arXiv preprint arXiv:2308.16777, 2023. 4
-
[35]
Findit: Generalized localization with natural language queries, 2022
Weicheng Kuo, Fred Bertsch, Wei Li, AJ Piergiovanni, Mohammad Saffar, and Anelia Angelova. Findit: Generalized localization with natural language queries, 2022. URL https://arxiv.org/abs/2203. 17273. 4
work page 2022
-
[36]
Language-driven semantic segmentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Rene Ranftl. Language-driven semantic segmentation. InInternational Conference on Learning Representations, 2022. URL https: //openreview.net/forum?id=RriDjddCLN
work page 2022
-
[37]
Open-vocabulary sam: Segment and recognize twenty-thousand classes interactively
Haobo Yuan, Xiangtai Li, Chong Zhou, Yining Li, Kai Chen, and Chen Change Loy. Open-vocabulary sam: Segment and recognize twenty-thousand classes interactively. InECCV, 2024
work page 2024
-
[38]
Omg-seg: Is one model good enough for all segmentation?, 2024
Xiangtai Li, Haobo Yuan, Wei Li, Henghui Ding, Size Wu, Wenwei Zhang, Yining Li, Kai Chen, and Chen Change Loy. Omg-seg: Is one model good enough for all segmentation?, 2024. URL https://arxiv.org/abs/2401.10229
-
[39]
Mengde Xu, Zheng Zhang, Fangyun Wei, Han Hu, and Xiang Bai. San: Side adapter network for open- vocabulary semantic segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[40]
Open-vocabulary object detection via vision and language knowledge distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. InInternational Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=lL3lnMbR4WU
work page 2022
-
[41]
Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, and Nicolas Carion. Mdetr–modulated detection for end-to-end multi-modal understanding.arXiv preprint arXiv:2104.12763, 2021
-
[42]
T-rex2: Towards generic object detection via text-visual prompt synergy, 2024
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shilong Liu, and Lei Zhang. T-rex2: Towards generic object detection via text-visual prompt synergy, 2024
work page 2024
-
[43]
Desco: Learning object recognition with rich language descriptions
Liunian Harold Li, Zi-Yi Dou, Nanyun Peng, and Kai-Wei Chang. Desco: Learning object recognition with rich language descriptions. InThirty-seventh Conference on Neural Information Processing Systems,
-
[44]
URLhttps://openreview.net/forum?id=J2Cso0wWZX
-
[45]
Grounded language-image pre-training
Liunian Harold Li*, Pengchuan Zhang*, Haotian Zhang*, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. InCVPR, 2022
work page 2022
-
[46]
Haotian* Zhang, Pengchuan* Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Harold Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding.arXiv preprint arXiv:2206.05836, 2022
-
[47]
Open-vocabulary semantic segmentation with mask-adapted clip
Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7061–7070,
-
[48]
Simple open-vocabulary object detection with vision transformers, 2022
Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. Simple open-vocabulary object detection with vision transformers, 2022. URLhttps://arxiv.org/abs/2205.06230. 12
-
[49]
Scaling open-vocabulary object detection, 2024
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection, 2024. URLhttps://arxiv.org/abs/2306.09683
-
[50]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Grounding dino 1.5: Advance the "edge" of open-set object detection, 2024
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, Yuda Xiong, Hao Zhang, Feng Li, Peijun Tang, Kent Yu, and Lei Zhang. Grounding dino 1.5: Advance the "edge" of open-set object detection, 2024. URL https: //arxiv.org/abs/2405.10300
-
[52]
Dino-x: A unified vision model for open-world object detection and understanding, 2024
Tianhe Ren, Yihao Chen, Qing Jiang, Zhaoyang Zeng, Yuda Xiong, Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, Xiaoke Jiang, Xingyu Chen, Zhuheng Song, Yuhong Zhang, Hongjie Huang, Han Gao, Shilong Liu, Hao Zhang, Feng Li, Kent Yu, and Lei Zhang. Dino-x: A unified vision model for open-world object detection and understanding, 2024. URL https://arxiv.org/a...
-
[53]
Grounded sam: Assembling open-world models for diverse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open-world models for diverse visual tasks, 2024
work page 2024
-
[54]
Aligning and prompting everything all at once for universal visual perception
Yunhang Shen, Chaoyou Fu, Peixian Chen, Mengdan Zhang, Ke Li, Xing Sun, Yunsheng Wu, Shaohui Lin, and Rongrong Ji. Aligning and prompting everything all at once for universal visual perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[55]
Yifan Xu, Mengdan Zhang, Chaoyou Fu, Peixian Chen, Xiaoshan Yang, Ke Li, and Changsheng Xu. Multi-modal queried object detection in the wild.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[56]
Heng Yin, Yuqiang Ren, Ke Yan, Shouhong Ding, and Yongtao Hao. Rod-mllm: Towards more reliable object detection in multimodal large language models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14358–14368, 2025. doi: 10.1109/CVPR52734.2025.01339
-
[57]
Evf-sam: Early vision-language fusion for text-prompted segment anything model
Yuxuan Zhang, Tianheng Cheng, Rui Hu, Lei Liu, Heng Liu, Longjin Ran, Xiaoxin Chen, Wenyu Liu, and Xinggang Wang. Evf-sam: Early vision-language fusion for text-prompted segment anything model. arXiv preprint arXiv:2406.20076, 2024
-
[58]
Generalized decoding for pixel, image, and language, 2022
Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, and Jianfeng Gao. Generalized decoding for pixel, image, and language, 2022. URLhttps://arxiv.org/abs/2212.11270. 8
-
[59]
Segment everything everywhere all at once
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=UHBrWeFWlL. 8
work page 2023
-
[60]
Open- vocabulary panoptic segmentation with text-to-image diffusion models, 2023
Jiarui Xu, Sifei Liu, Arash Vahdat, Wonmin Byeon, Xiaolong Wang, and Shalini De Mello. Open- vocabulary panoptic segmentation with text-to-image diffusion models, 2023. URL https://arxiv. org/abs/2303.04803
-
[61]
Sam-clip: Merging vision foundation models towards semantic and spatial understanding, 2024
Haoxiang Wang, Pavan Kumar Anasosalu Vasu, Fartash Faghri, Raviteja Vemulapalli, Mehrdad Farajtabar, Sachin Mehta, Mohammad Rastegari, Oncel Tuzel, and Hadi Pouransari. Sam-clip: Merging vision foundation models towards semantic and spatial understanding, 2024. URL https://arxiv.org/abs/ 2310.15308. 4
-
[62]
Gres: Generalized referring expression segmentation,
Chang Liu, Henghui Ding, and Xudong Jiang. Gres: Generalized referring expression segmentation,
- [63]
-
[64]
Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity.arXiv preprint arXiv:2307.04767, 2023. 4, 7
-
[65]
Resanything: Attribute prompting for arbitrary referring segmentation, 2025
Ruiqi Wang and Hao Zhang. Resanything: Attribute prompting for arbitrary referring segmentation, 2025. URLhttps://arxiv.org/abs/2505.02867. 4, 7, 8
-
[66]
Yong Liu, Cairong Zhang, Yitong Wang, Jiahao Wang, Yujiu Yang, and Yansong Tang. Universal segmentation at arbitrary granularity with language instruction.arXiv preprint arXiv:2312.01623, 2023. 4 13
-
[67]
Unveiling parts beyond objects:towards finer-granularity referring expression segmentation, 2024
Wenxuan Wang, Tongtian Yue, Yisi Zhang, Longteng Guo, Xingjian He, Xinlong Wang, and Jing Liu. Unveiling parts beyond objects:towards finer-granularity referring expression segmentation, 2024. URL https://arxiv.org/abs/2312.08007. 4, 8, 19, 21, 22
-
[68]
Donggon Jang, Yucheol Cho, Suin Lee, Taehyeon Kim, and Dae-Shik Kim. Mmr: A large-scale benchmark dataset for multi-target and multi-granularity reasoning segmentation, 2025. URL https: //arxiv.org/abs/2503.13881. 4, 8
-
[69]
Ov-parts: Towards open-vocabulary part segmentation
Meng Wei, Xiaoyu Yue, Wenwei Zhang, Shu Kong, Xihui Liu, and Jiangmiao Pang. Ov-parts: Towards open-vocabulary part segmentation. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. 4
work page 2023
-
[70]
Going denser with open-vocabulary part segmentation.arXiv preprint arXiv:2305.11173, 2023
Peize Sun, Shoufa Chen, Chenchen Zhu, Fanyi Xiao, Ping Luo, Saining Xie, and Zhicheng Yan. Going denser with open-vocabulary part segmentation.arXiv preprint arXiv:2305.11173, 2023. 7
-
[71]
Zifu Wan, Yaqi Xie, Ce Zhang, Zhiqiu Lin, Zihan Wang, Simon Stepputtis, Deva Ramanan, and Katia P. Sycara. InstructPart: Task-oriented part segmentation with instruction reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 24202–24227, Vienna, Austria, July 2025. Association fo...
-
[72]
Detect What You Can: Detecting and Representing Objects using Holistic Models and Body Parts
Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu, Sanja Fidler, Raquel Urtasun, and Alan Yuille. Detect what you can: Detecting and representing objects using holistic models and body parts, 2014. URL https://arxiv.org/abs/1406.2031. 4
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[73]
PACO: Parts and attributes of common objects
Vignesh Ramanathan, Anmol Kalia, Vladan Petrovic, Yi Wen, Baixue Zheng, Baishan Guo, Rui Wang, Aaron Marquez, Rama Kovvuri, Abhishek Kadian, Amir Mousavi, Yiwen Song, Abhimanyu Dubey, and Dhruv Mahajan. PACO: Parts and attributes of common objects. InarXiv preprint arXiv:2301.01795,
-
[74]
Reasoning to attend: Try to understand how <seg> token works,
Rui Qian, Xin Yin, and Dejing Dou. Reasoning to attend: Try to understand how <seg> token works,
- [75]
-
[76]
Lisa++: An improved baseline for reasoning segmentation with large language model, 2024
Senqiao Yang, Tianyuan Qu, Xin Lai, Zhuotao Tian, Bohao Peng, Shu Liu, and Jiaya Jia. Lisa++: An improved baseline for reasoning segmentation with large language model, 2024. URL https: //arxiv.org/abs/2312.17240. 7
-
[77]
Gsva: Generalized segmentation via multimodal large language models
Zhuofan Xia, Dongchen Han, Yizeng Han, Xuran Pan, Shiji Song, and Gao Huang. Gsva: Generalized segmentation via multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3858–3869, June 2024. 8
work page 2024
-
[78]
Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S
Hanoona Rasheed, Muhammad Maaz, Sahal Shaji, Abdelrahman Shaker, Salman Khan, Hisham Cholakkal, Rao M. Anwer, Eric Xing, Ming-Hsuan Yang, and Fahad S. Khan. Glamm: Pixel grounding large multimodal model.The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 8
work page 2024
-
[79]
OMG-LLaV A: Bridging image-level, object-level, pixel-level reasoning and understanding
Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, and Shuicheng YAN. OMG-LLaV A: Bridging image-level, object-level, pixel-level reasoning and understanding. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=WeoNd6PRqS
work page 2024
-
[80]
Hyperseg: Towards universal visual segmentation with large language model, 2024
Cong Wei, Yujie Zhong, Haoxian Tan, Yong Liu, Zheng Zhao, Jie Hu, and Yujiu Yang. Hyperseg: Towards universal visual segmentation with large language model, 2024. URL https://arxiv.org/ abs/2411.17606
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.