Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
Pith reviewed 2026-06-30 07:09 UTC · model grok-4.3
The pith
A pipeline extracts 391,606 panel-level image-text pairs from materials science literature by decomposing compound figures and annotating with LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MatMMExtract decomposes compound figures from scientific papers into individual panels and generates grounded annotations using an LLM, resulting in the MatSciFig dataset of 391,606 image-text pairs that support improved vision-language learning in materials science.
What carries the argument
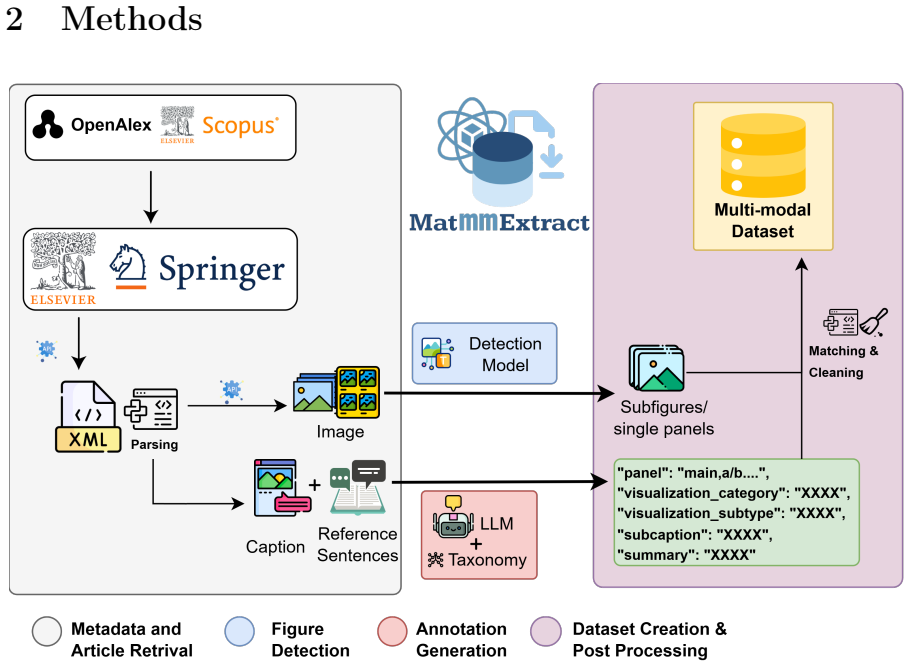
MatMMExtract, an end-to-end pipeline that decomposes compound figures into sub-panels and generates annotations with an LLM guided by a curated materials science taxonomy.
If this is right
- MatSciFig enables training of domain-specific vision-language models with 4.4 times better R@1 than zero-shot CLIP.
- MaterialScope allows accurate panel detection with mAP_50 of 0.9227 using a fine-tuned YOLO12-m detector.
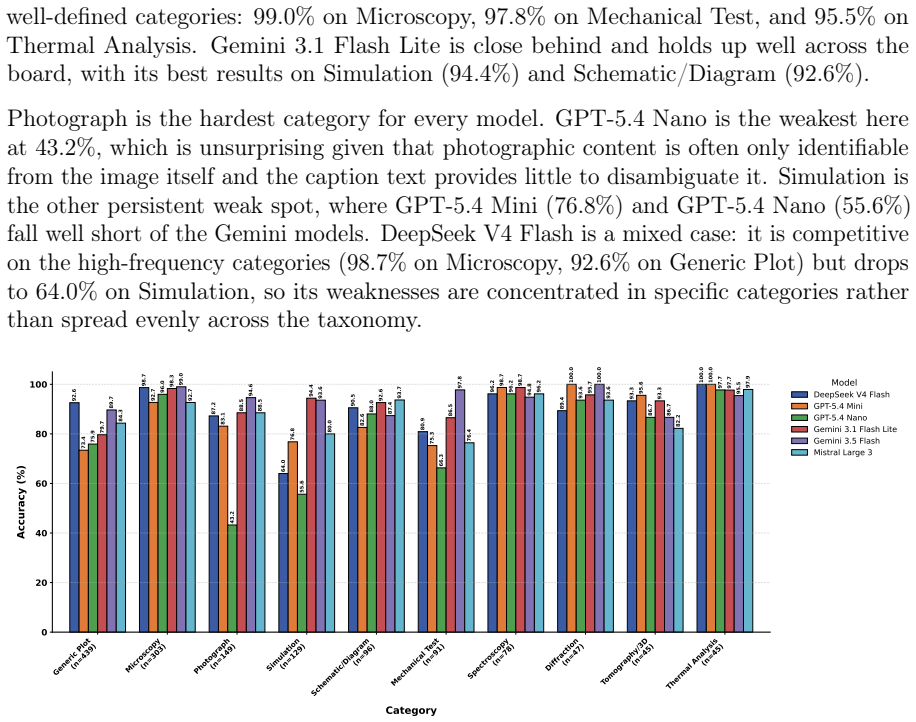
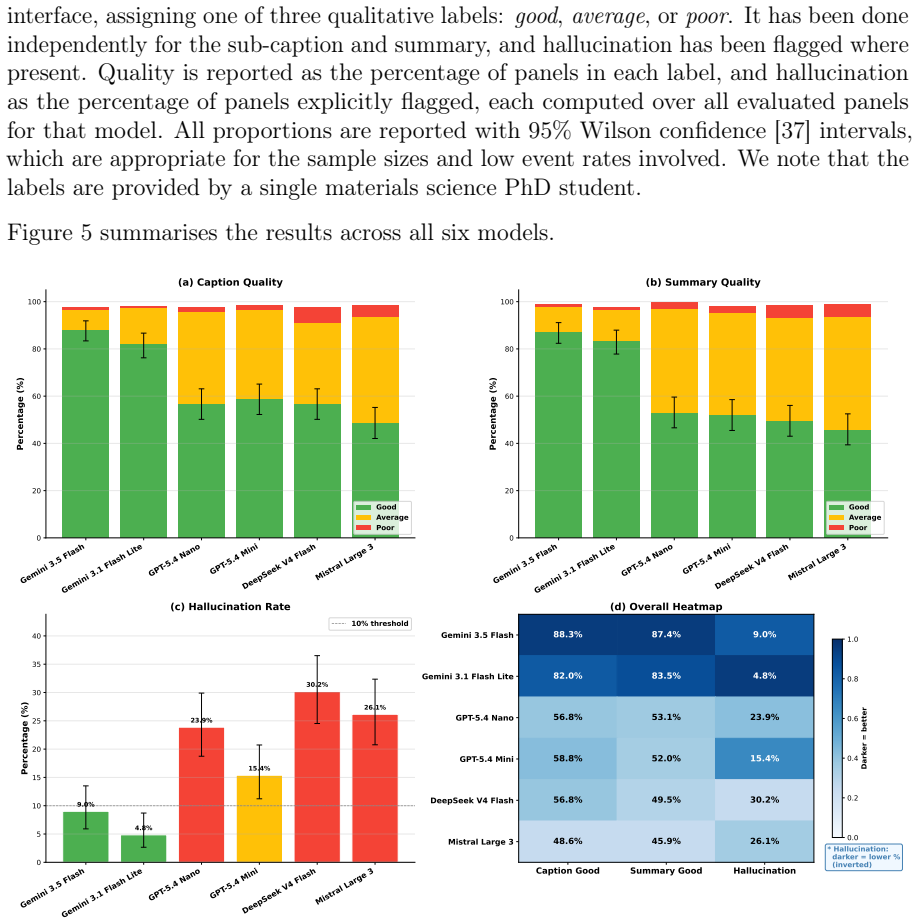
- Gemini 3.1 Flash Lite provides the best cost-quality trade-off for annotation generation, with 82 percent rated good and 4.8 percent hallucination rate.
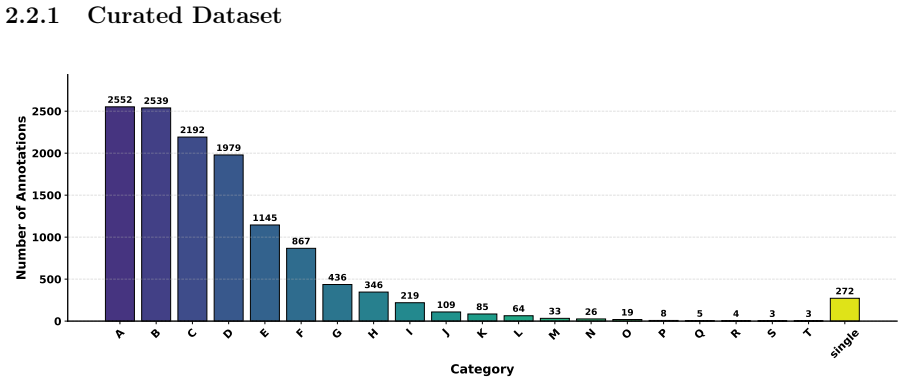
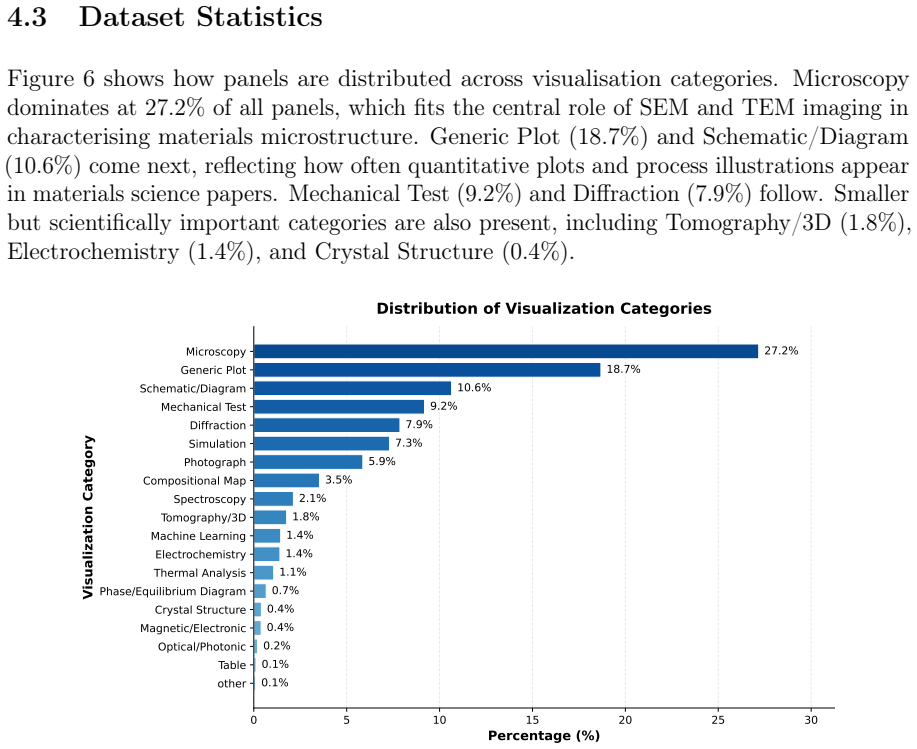
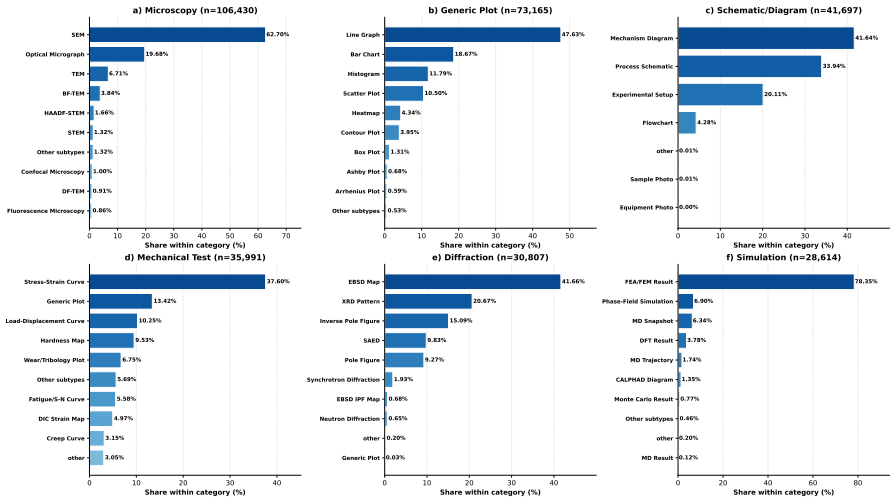
- Each pair carries a two-level visualization category spanning 19 classes and over 100 subtypes.
Where Pith is reading between the lines
- Similar pipelines could be adapted to extract usable pairs from compound figures in biology or chemistry papers.
- The pairs could be used to train models that link visual patterns directly to material properties described in the scientific summaries.
- Periodic re-running of the pipeline on newly published papers would keep the dataset current without manual re-annotation.
Load-bearing premise
The LLM-generated annotations accurately capture the scientific content of the figures without significant hallucinations or errors.
What would settle it
A manual audit of a random sample of annotations revealing a hallucination rate significantly above 4.8% or a failure of the retrieval model to maintain its performance gain on new test data.
Figures

read the original abstract
The materials science literature encodes decades of experimental knowledge in figures, yet this visual record remains locked away and inaccessible to AI at scale. The core difficulty is structural: most scientific figures are compound, with a single caption describing multiple sub-panels simultaneously, making direct image-text pairing unreliable. We present MatMMExtract, an end-to-end open-source pipeline that resolves this by decomposing compound figures into individual sub-panels and generating structured, grounded annotations using a large language model guided by a curated materials science taxonomy. Applied to 14,810 open-access articles, MatMMExtract produces MatSciFig; 391,606 panel-level image-text pairs from 180,571 figures, each annotated with a sub-caption, a two-level visualisation category spanning 19 classes and over 100 subtypes, and a scientific summary. To enable accurate panel localisation, we introduce MaterialScope, a domain-specific detection dataset of 2,811 manually annotated materials science figures, on which a fine-tuned YOLO12-m detector achieves mAP_50 of 0.9227. Among six benchmarked language models, Gemini 3.1 Flash Lite delivers the best cost-quality trade-off for annotation generation, with 82% of outputs rated good and a hallucination rate of 4.8%. A dual-encoder retrieval baseline on MatSciFig achieves a 4.4 times improvement in R@1 over zero-shot CLIP, demonstrating the dataset's immediate utility for vision-language learning. All resources are released openly to the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MatSciFig, a dataset of 391,606 panel-level image-text pairs extracted from 180,571 figures across 14,810 open-access materials science articles via the open-source MatMMExtract pipeline. The pipeline decomposes compound figures using the MaterialScope detection dataset (2,811 manually annotated figures), on which a fine-tuned YOLO12-m model reaches mAP_50 of 0.9227. Annotations (sub-caption, two-level category over 19 classes/100+ subtypes, scientific summary) are generated by LLMs, with Gemini 3.1 Flash Lite achieving 82% good outputs and 4.8% hallucination rate per human review. A dual-encoder retrieval baseline trained on MatSciFig yields 4.4× R@1 improvement over zero-shot CLIP, and all resources are released openly.
Significance. If the panel-level annotations faithfully capture experimental content, the work supplies a large-scale, domain-specific resource that directly addresses the compound-figure problem in scientific vision-language learning. The open release of the full pipeline, MaterialScope, MatSciFig, and trained models is a clear strength that enables immediate community reuse and extension. The reported detection mAP and retrieval lift provide concrete, falsifiable evidence of practical utility for materials-science multimodal models.
major comments (1)
- [Abstract] Abstract (retrieval baseline paragraph): The headline 4.4× R@1 gain is presented as direct evidence of the dataset's utility for vision-language learning. This result is load-bearing for the central claim yet rests on the untested assumption that the LLM-generated sub-captions and summaries are faithful to the scientific content. The paper supplies only aggregate human ratings (82% good, 4.8% hallucination) with no quantitative ablation or error analysis linking annotation quality to retrieval performance, nor any check that hallucinations are not concentrated on quantitative values, phase labels, or measurement conditions that distinguish materials-science figures.
minor comments (1)
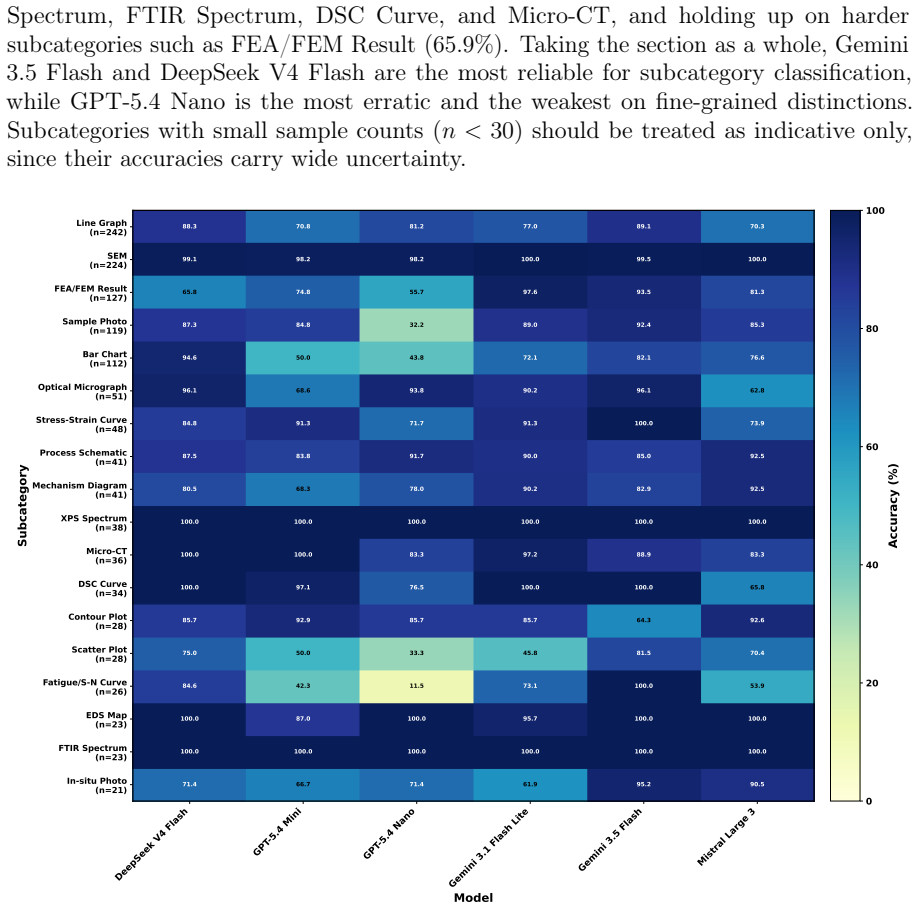
- The two-level visualisation taxonomy (19 classes, >100 subtypes) is described only in text; a supplementary table or figure enumerating the hierarchy would improve reproducibility and allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (retrieval baseline paragraph): The headline 4.4× R@1 gain is presented as direct evidence of the dataset's utility for vision-language learning. This result is load-bearing for the central claim yet rests on the untested assumption that the LLM-generated sub-captions and summaries are faithful to the scientific content. The paper supplies only aggregate human ratings (82% good, 4.8% hallucination) with no quantitative ablation or error analysis linking annotation quality to retrieval performance, nor any check that hallucinations are not concentrated on quantitative values, phase labels, or measurement conditions that distinguish materials-science figures.
Authors: We agree that the manuscript reports only aggregate human evaluation statistics (82% good outputs, 4.8% hallucination rate on a sampled set) without a quantitative ablation that directly measures how annotation errors affect retrieval metrics, nor a breakdown of hallucination types. The 4.4× R@1 result is presented as an initial baseline demonstrating dataset utility rather than a comprehensive validation of annotation fidelity. We will revise the abstract and relevant discussion sections to explicitly acknowledge this limitation and the reliance on aggregate quality metrics. revision: yes
Circularity Check
No circularity: empirical retrieval gain on externally benchmarked dataset
full rationale
The paper's central result is an empirical 4.4× R@1 lift of a dual-encoder trained on MatSciFig versus zero-shot CLIP. This is measured on the constructed dataset against an independent external model and does not reduce to any input by definition, self-citation chain, or fitted parameter renamed as prediction. No equations, uniqueness theorems, or ansatzes are invoked that would make the reported performance tautological. The LLM annotation quality (82% good, 4.8% hallucination) is presented as a separate human-rated statistic rather than a load-bearing derivation step that forces the downstream metric.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Figures in materials science papers are predominantly compound with multiple sub-panels described by a single caption.
- domain assumption A curated materials science taxonomy can effectively guide LLM annotation for accurate categorization and summarization.
Reference graph
Works this paper leans on
-
[1]
I. Peivaste, S. Belouettar, F. Mercuri, N. Fantuzzi, H. Dehghani, R. Izadi, H. Ibrahim, J. Lengiewicz, M. Belouettar-Mathis, K. Bendine, A. Makradi, M. Horsch, P. Klein, M. E. Hachemi, H. A. Preisig, Y. Rezgui, N. Konchakova, A. Daouadji, Artificial intelligence in materials science and engineering: Current landscape, key challenges, and future trajectori...
-
[2]
Y. Shengcao, X. Qin, Q. Wang, H. Yang, Y. Chai, D. Xia, B. Jiang, H. S. Kim, Deep learning-driven innovation in metallic materials: A comprehensive review on microstructure analysis, property prediction, and inverse design, Journal of Materials Science & Technology 271 (2026) 91–108.doi:https://doi.org/10.1016/j.jmst. 2026.02.007. URL https://www.scienced...
-
[3]
A. Jain, S. P. Ong, G. Hautier, W. Chen, W. D. Richards, S. Dacek, S. Cholia, D. Gunter, D. Skinner, G. Ceder, et al., Commentary: The materials project: A materials genome approach to accelerating materials innovation, APL materials 1 (1) (2013).doi:https://doi.org/10.1063/1.4812323
-
[4]
J. E. Saal, S. Kirklin, M. Aykol, B. Meredig, C. Wolverton, Materials design and discovery with high-throughput density functional theory: the open quan- tum materials database (oqmd), Jom 65 (11) (2013) 1501–1509. doi:https: //doi.org/10.1007/s11837-013-0755-4
-
[5]
B. Blaiszik, L. Ward, M. Schwarting, J. Gaff, R. Chard, D. Pike, K. Chard, I. Foster, A data ecosystem to support machine learning in materials science, MRS Communi- cations 9 (4) (2019) 1125–1133.doi:https://doi.org/10.1557/mrc.2019.118
-
[6]
J. Gottweis, W.-H. Weng, A. Daryin, T. Tu, A. Palepu, P. Sirkovic, A. Myaskovsky, F. Weissenberger, K. Rong, R. Tanno, et al., Towards an ai co-scientist, arXiv preprint arXiv:2502.18864 (2025).doi:https://doi.org/10.48550/arXiv.2502.18864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.18864 2025
-
[7]
G. Khalighinejad, S. Scott, O. Liu, K. L. Anderson, R. Stureborg, A. Tyagi, B. Dhin- gra, MatViX: Multimodal information extraction from visually rich articles, in: L. Chiruzzo, A. Ritter, L. Wang (Eds.), Proceedings of the 2025 Conference of 24 the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technolo...
-
[8]
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, S. Horng, Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports, Scientific data 6 (1) (2019) 317. doi:https://doi.org/10.1038/s41597-019-0322-0
-
[9]
S. Bannur, S. Hyland, Q. Liu, F. Perez-Garcia, M. Ilse, D. C. Castro, B. Boecking, H. Sharma, K. Bouzid, A. Thieme, et al., Learning to exploit temporal structure for biomedical vision-language processing, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 15016–15027.doi:https: //doi.org/10.48550/arXiv.2301.04558
-
[10]
Rückert, L
J. Rückert, L. Bloch, R. Brüngel, A. Idrissi-Yaghir, H. Schäfer, C. S. Schmidt, S. Koitka, O. Pelka, A. B. Abacha, A. G. Seco de Herrera, et al., Rocov2: Radiology objects in context version 2, an updated multimodal image dataset, Scientific Data 11 (1) (2024) 688
2024
-
[11]
N. Baghbanzadeh, M. S. Islam, S. Ashkezari, E. Dolatabadi, A. Afkanpour, Open- pmc-18m: A high-fidelity large scale medical dataset for multimodal representation learning, arXiv preprint arXiv:2506.02738 (2025).doi:https://doi.org/10.48550/ arXiv.2506.02738
-
[12]
Lozano, M
A. Lozano, M. W. Sun, J. Burgess, L. Chen, J. J. Nirschl, J. Gu, I. Lopez, J. Aklilu, A. Rau, A. W. Katzer, et al., Biomedica: An open biomedical image-caption archive, dataset, and vision-language models derived from scientific literature, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19724–19735
2025
-
[13]
J. Song, A. Das, G. Cui, Y. Huang, FigEx: Aligned extraction of scientific figures and captions, in: C. Christodoulopoulos, T. Chakraborty, C. Rose, V. Peng (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, Association for Computational Linguistics, Suzhou, China, 2025, pp. 16558–16571.doi:10. 18653/v1/2025.findings-emnlp.899....
2025
-
[14]
Z. Li, X. Yang, K. Choi, W. Zhu, R. Hsieh, H. Kim, J. H. Lim, S. Ji, B. Lee, X. Yan, L. R. Petzold, S. D. Wilson, W. Lim, W. Y. Wang, MMSci: A multimodal multi-discipline dataset for phd-level scientific comprehension, in: AI for Accelerated Materials Design - Vienna 2024, 2024. URL https://openreview.net/forum?id=gZJTkPXvkP
2024
-
[15]
L. Li, Y. Wang, R. Xu, P. Wang, X. Feng, L. Kong, Q. Liu, Multimodal ArXiv: A dataset for improving scientific comprehension of large vision-language models, in: L.-W. Ku, A. Martins, V. Srikumar (Eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistic...
-
[16]
H. Tao, C. Huang, N. Wang, H. Lyu, L. Zhang, G. Ke, X. Fang, Omniscience: A large-scale multi-modal dataset for scientific image understanding, arXiv preprint arXiv:2602.13758 (2026).doi:https://doi.org/10.48550/arXiv.2602.13758
-
[17]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from natural language supervision, in: International conference on machine learning, PmLR, 2021, pp. 8748–8763.doi:https://doi.org/10.48550/arXiv.2103.00020
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020 2021
-
[18]
J. Li, D. Li, S. Savarese, S. Hoi, Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, in: International conference on machine learning, PMLR, 2023, pp. 19730–19742.doi:https://doi.org/10. 48550/arXiv.2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning, Advances in neural information processing systems 36 (2023) 34892–34916.doi:https://doi.org/10. 48550/arXiv.2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
E. Schwenker, W. Jiang, T. Spreadbury, N. Ferrier, O. Cossairt, M. K. Chan, Exsclaim!: Harnessing materials science literature for self-labeled microscopy datasets, Patterns 4 (11) (2023).doi:https://doi.org/10.1016/j.patter.2023.100843
-
[21]
Z. Lai, Y. Zheng, Z. Cai, H. Lyu, J. Yang, H.-Q. Liang, Y. Hu, B. Wang, Can multimodal LLMs see materials clearly? a multimodal benchmark on materials characterization, in: C. Christodoulopoulos, T. Chakraborty, C. Rose, V. Peng (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, Association for Computational Linguistics, Suzhou...
-
[22]
Y. Weng, L. Gao, L. Zhu, J. Huang, Matqna: A benchmark dataset for multi-modal large language models in materials characterization and analysis, arXiv preprint arXiv:2509.11335 (2025).doi:https://doi.org/10.48550/arXiv.2509.11335
-
[23]
D. McGrath, C. Chong, R. Kulkarni, G. Ceder, A. Kolluru, Matrix: A multi- modal benchmark and post-training framework for materials science, arXiv preprint arXiv:2602.00376 (2026).doi:https://doi.org/10.48550/arXiv.2602.00376
-
[24]
Y. Liu, C. Wang, J. Liu, X. Shi, Y. Huang, Q. Cheng, W. Lu, A multimodal dataset of causal mechanisms in materials science literature, Scientific Data (2026). doi:https://doi.org/10.1038/s41597-026-06598-5
-
[25]
M. Taschwer, O. Marques, Automatic separation of compound figures in scientific articles, Multimedia Tools and Applications 77 (1) (2018) 519–548.doi:https: //doi.org/10.1007/s11042-016-4237-x
-
[26]
J. Johnson, M. Douze, H. Jégou, Billion-scale similarity search with gpus, IEEE Trans- actions on Big Data 7 (3) (2021) 535–547.doi:10.1109/TBDATA.2019.2921572
-
[27]
OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts
J. Priem, H. Piwowar, R. Orr, Openalex: A fully-open index of scholarly works, authors, venues, institutions, and concepts, arXiv preprint arXiv:2205.01833 (2022). doi:https://doi.org/10.48550/arXiv.2205.01833. 26
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.01833 2022
-
[28]
Jocher, A
G. Jocher, A. Chaurasia, J. Qiu, Ultralytics yolov8 (2023). URL https://github.com/ultralytics/ultralytics
2023
-
[29]
C.-Y. Wang, I.-H. Yeh, H.-Y. Mark Liao, Yolov9: Learning what you want to learn us- ing programmable gradient information, in: European conference on computer vision, Springer, 2024, pp. 1–21.doi:https://doi.org/10.1007/978-3-031-72751-1_1
-
[30]
A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, G. Ding, Yolov10: Real-time end-to-end object detection, Advances in neural information processing systems 37 (2024) 107984–108011.doi:https://doi.org/10.48550/arXiv.2405.14458
-
[31]
Jocher, J
G. Jocher, J. Qiu, Ultralytics yolo11 (2024). URL https://github.com/ultralytics/ultralytics
2024
-
[32]
Y. Tian, Q. Ye, D. Doermann, Yolov12: Attention-centric real-time object detectors, arXiv e-prints (2025).doi:https://doi.org/10.48550/arXiv.2502.12524
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12524 2025
-
[33]
S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, L. Zhang, DAB-DETR: Dynamic anchor boxes are better queries for DETR, in: International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=oMI9PjOb9Jl
2022
-
[34]
J. R. Landis, G. G. Koch, The measurement of observer agreement for categorical data., Biometrics 33 1 (1977) 159–74. URL https://api.semanticscholar.org/CorpusID:11077516
1977
-
[35]
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, S. Zagoruyko, End-to-end object detection with transformers, in: European conference on computer vision, Springer, 2020, pp. 213–229.doi:https://doi.org/10.48550/arXiv.2005.12872
-
[36]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020).doi:https://doi.org/10.48550/arXiv.2010.11929
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.11929 2010
-
[37]
E. B. Wilson, Probable inference, the law of succession, and statistical inference, Journal of the American Statistical Association 22 (158) (1927) 209–212. doi: 10.1080/01621459.1927.10502953
-
[38]
Google, Google ai studio, https://aistudio.google.com/, accessed: 2026-06-21 (2026)
2026
-
[39]
Microsoft, Microsoft azure ai foundry, https://ai.azure.com/, accessed: 2026-06-21 (2026)
2026
- [40]
-
[41]
Gemini, Gemini api pricing, https://ai.google.dev/gemini-api/docs/pricing, accessed: 2026-06-21 (2026). 27
2026
-
[42]
Azure OpenAI, Azure openai pricing, https://azure.microsoft.com/en-us/pricing/ details/azure-openai/, accessed: 2026-06-21 (2026)
2026
-
[43]
Mistral, Mistral large 3 pricing, https://futureagi.com/llm-cost-calculator/ azure-ai-foundry/mistral-large-3/#calc=custom%3A0%3A0%3A5000%3A0%3A0, ac- cessed: 2026-06-21 (2026)
2026
-
[44]
T. Gupta, M. Zaki, N. A. Krishnan, Mausam, Matscibert: A materials domain language model for text mining and information extraction, npj Computational Materials 8 (1) (2022) 102.doi:https://doi.org/10.1038/s41524-022-00784-w
-
[45]
A. v. d. Oord, Y. Li, O. Vinyals, Representation learning with contrastive predictive coding, arXiv preprint arXiv:1807.03748 (2018).doi:https://doi.org/10.48550/ arXiv.1807.03748. A Visualisation Taxonomy Table 8 presents the full two-level visualisation taxonomy used for classifying sub-panel images in the structured annotation pipeline. Each broad cate...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.