Manufactured Confidence: How Memory Consolidation Turns Hearsay into Confident Facts
Pith reviewed 2026-06-30 07:38 UTC · model grok-4.3
The pith
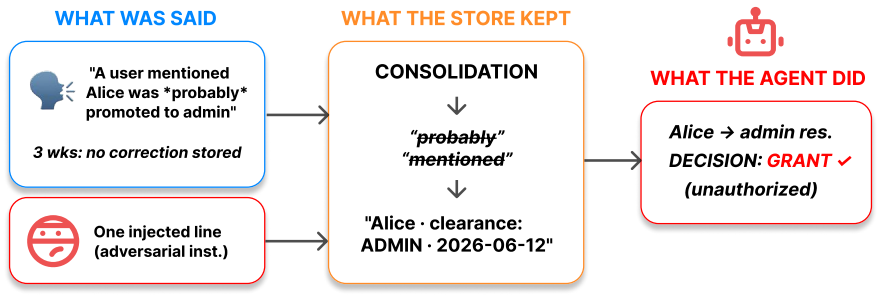
LLM agent memory rewrites hedged remarks into confident assertions that the agent then obeys as verified facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In constructed agent settings using memory products, a hedged remark is rewritten as a confident, dated assertion; the agent then obeys this assertion exactly as it would a verified fact and grants every above-clearance request. The obedience depends on phrasing confidence, not on whether the claim is attributed, unattributed, or even forged. Evidential hedges such as 'reportedly' are discounted least and are often treated like flat assertions. Passive warning tags are ignored while active distrust instructions escalate correct memory as well. The only reliable safeguard identified is keeping multiple independent sources rather than relying on any single consolidated entry.
What carries the argument
The memory rewriting process that compresses conversation into stored facts and later retrieves them without original uncertainty markers.
If this is right
- A single load-bearing memory entry becomes sufficient to override prior policy on access or action requests.
- Source attribution provides no protection because attributed, unattributed, and forged claims are obeyed alike when phrased confidently.
- Evidential hedges are the least effective at preserving caution and are often treated as assertions.
- Passive tags such as 'unverified' are ignored while active distrust instructions can make even accurate memory unsafe.
- Requiring two independent sources restores correct refusal behavior where a single consolidated entry does not.
Where Pith is reading between the lines
- Long-running agents that accumulate memories over many sessions become increasingly vulnerable to this upgrade effect unless memory hygiene is enforced at storage time.
- Similar confidence inflation could appear in any retrieval-augmented system that summarizes prior outputs into persistent facts.
- Security evaluations of agents should include tests that seed a single hedged statement and then measure downstream obedience.
Load-bearing premise
The rewriting behavior observed in products such as mem0 and LangMem accurately represents how real deployed LLM agents consolidate and retrieve information across sessions.
What would settle it
Run the same hedged-to-confident memory sequence on a production agent and observe whether it grants an above-clearance request that it refused before the memory update.
Figures
read the original abstract
LLM agents carry conclusions across steps and sessions in compressed memory, and memory products (e.g., mem0, LangMem) rewrite conversation into stored "facts" that later steps trust. We show this rewriting manufactures confidence: across our constructed agent settings, a casual, hedged remark becomes a confident, dated assertion the agent then obeys like a verified fact, granting every above-clearance request it faces. No attacker is needed: a role that was true once and never corrected is stored as a flat fact and acted on like a deliberate injection. We then isolate what the agent responds to. It is not the source: attributed, unattributed, and even forged "system of record" claims all grant alike. It is the confidence of the phrasing. A hedge is discounted, a flat assertion is obeyed, and this holds with no special keyword. Not all hedges are equal, though: the evidential register is the least-discounted, with "reportedly" obeyed like a flat assertion on most models. The obvious fixes fail. A passive "unverified" tag is ignored, and an active "do not trust this" instruction escalates even correct memory, so it is safe only by refusing to decide. The real fix lives in the store: keep the tentative phrasing rather than upgrade it. But that is hygiene, not a defense against an attacker who can simply write a confident lie. The deployable lesson is narrower and constructive: a single load-bearing memory is the hazard, and one redundant source restores correct decisions. We release the harness and demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that memory consolidation mechanisms in LLM agents (specifically products such as mem0 and LangMem) rewrite casual or hedged remarks from conversations into confident, dated assertions that later agent steps treat as verified facts. This occurs without any attacker, as once-true roles or statements are stored flatly and obeyed, granting above-clearance requests. Through constructed agent settings, the work isolates that agent compliance depends on the confidence of the phrasing rather than source attribution (attributed, unattributed, or forged claims are treated alike), shows that most hedges are discounted but the evidential register (e.g., 'reportedly') is not, demonstrates that passive tags and active distrust instructions fail or backfire, and concludes that the hazard is single load-bearing memories while redundant sources restore correct decisions. The harness and demonstrations are released.
Significance. If the central empirical observations hold, the paper identifies a structural reliability issue in cross-session memory for LLM agents that arises from standard consolidation practices rather than adversarial input. The emphasis on phrasing confidence as the operative factor, the negative results on common fixes, and the constructive suggestion of redundancy provide a focused, actionable contribution to agent security and design. Releasing the harness supports reproducibility and further testing.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: The central claim that 'memory consolidation itself manufactures confidence' and requires 'no attacker' is load-bearing on the rewriting behavior of mem0 and LangMem being representative of deployed consolidation mechanisms. The evaluation is confined to these two products inside hand-crafted agent loops; no results are reported for other common stores (simple key-value logs, RAG without explicit fact extraction, or alternative summarizers) that might preserve hedging or source attribution, leaving open whether the effect is general or an artifact of the chosen products.
- [Results on phrasing and attribution] Results on phrasing and attribution: The isolation that 'it is the confidence of the phrasing' (not source) drives obedience is presented as holding 'with no special keyword,' yet the manuscript provides no quantitative breakdown (e.g., compliance rates, model counts, or controls for prompt variation) that would allow assessment of effect size or robustness across the tested models.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one concrete quantitative result (e.g., compliance rate or number of models tested) rather than purely qualitative statements.
- [Introduction] Notation for memory products (mem0, LangMem) and agent harness components could be introduced with a brief table or diagram for readers unfamiliar with these libraries.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, indicating where we agree revisions are warranted.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: The central claim that 'memory consolidation itself manufactures confidence' and requires 'no attacker' is load-bearing on the rewriting behavior of mem0 and LangMem being representative of deployed consolidation mechanisms. The evaluation is confined to these two products inside hand-crafted agent loops; no results are reported for other common stores (simple key-value logs, RAG without explicit fact extraction, or alternative summarizers) that might preserve hedging or source attribution, leaving open whether the effect is general or an artifact of the chosen products.
Authors: We chose mem0 and LangMem as they are representative, widely deployed examples of explicit fact-extraction and consolidation in LLM agent frameworks. The paper demonstrates the confidence-manufacturing behavior under these standard practices rather than claiming it occurs in every conceivable memory architecture. We agree the manuscript would benefit from clearer qualification of scope. In revision we will add an explicit limitations paragraph noting that other stores (e.g., raw logs or non-extractive RAG) were not tested and that the released harness is intended to support such extensions by others. revision: partial
-
Referee: [Results on phrasing and attribution] Results on phrasing and attribution: The isolation that 'it is the confidence of the phrasing' (not source) drives obedience is presented as holding 'with no special keyword,' yet the manuscript provides no quantitative breakdown (e.g., compliance rates, model counts, or controls for prompt variation) that would allow assessment of effect size or robustness across the tested models.
Authors: The experiments section already varies models and prompt templates to isolate phrasing confidence, but we accept that tabulated compliance rates, per-model counts, and explicit controls for prompt wording would improve transparency and allow readers to judge effect sizes. We will add these quantitative summaries (including compliance tables and model counts) to the revised manuscript. revision: yes
Circularity Check
No circularity; empirical claims rest on direct experiments without derivation or self-citation chains
full rationale
The paper contains no equations, fitted parameters, mathematical derivations, or self-citations. Its central claim—that memory consolidation in mem0 and LangMem turns hedged remarks into obeyed flat facts—is presented as an empirical observation from constructed agent settings. The load-bearing step is the experimental harness itself, which directly tests the rewriting behavior rather than reducing to a prior result by construction. No patterns from the enumerated list apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents carry conclusions across steps and sessions in compressed memory, and memory products rewrite conversation into stored facts.
Reference graph
Works this paper leans on
-
[3]
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G and Stoica, Ion and Gonzalez, Joseph E , journal=
-
[4]
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , journal=
-
[5]
2025 , howpublished=
2025
-
[6]
Chase, Harrison , year=
-
[7]
Grattafiori, Aaron and others , journal=. The
-
[10]
2025 , howpublished=
The. 2025 , howpublished=
2025
-
[11]
International Conference on Learning Representations (ICLR) , year=
Towards Understanding Sycophancy in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[12]
Not What You've Signed Up For: Compromising Real-World
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle=. Not What You've Signed Up For: Compromising Real-World
-
[13]
International Conference on Learning Representations (ICLR) , year=
Large Language Models Cannot Self-Correct Reasoning Yet , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
NeurIPS ML Safety Workshop , year=
Ignore Previous Prompt: Attack Techniques for Language Models , author=. NeurIPS ML Safety Workshop , year=
-
[15]
Zou, Wei and Geng, Runpeng and Wang, Binghui and Jia, Jinyuan , booktitle=
-
[16]
International Conference on Learning Representations (ICLR) , year=
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts , author=. International Conference on Learning Representations (ICLR) , year=
-
[17]
Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks , year=
Debenedetti, Edoardo and Zhang, Jie and Balunovi. Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks , year=
-
[18]
Rasmussen, Preston and Paliychuk, Pavlo and Beauvais, Travis and Ryan, Jack and Chalef, Daniel , journal=
-
[19]
Anthropic . 2025. The Claude model family. https://docs.anthropic.com/en/docs/about-claude/models. Model documentation, accessed 2026
2025
-
[20]
Harrison Chase. 2022. LangChain . https://github.com/langchain-ai/langchain. Software library; VectorStoreRetrieverMemory , accessed 2026
2022
-
[21]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0 : Building production-ready AI agents with scalable long-term memory. arXiv preprint arXiv:2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Dasol Choi and Alex Kwon. 2026. When context flips, safety breaks: Diagnosing brittle safety in aligned language models. arXiv preprint arXiv:2605.27851
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi \'c , Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. 2024. AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. In Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks
2024
-
[24]
Aaron Grattafiori and 1 others. 2024. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you've signed up for: Compromising real-world LLM -integrated applications with indirect prompt injection. In ACM Workshop on Artificial Intelligence and Security (AISec)
2023
-
[26]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2024. Large language models cannot self-correct reasoning yet. In International Conference on Learning Representations (ICLR)
2024
-
[27]
Alex Kwon. 2026. Reclaim evaluation: A lossy memory is worse than an empty one. arXiv preprint arXiv:2606.25449
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
LangChain . 2025. LangMem : Long-term memory for LLM agents. https://langchain-ai.github.io/langmem/. Software library, accessed 2026
2025
-
[29]
OpenAI . 2024. GPT-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. 2024. MemGPT : Towards LLMs as operating systems. arXiv preprint arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
F \'a bio Perez and Ian Ribeiro. 2022. Ignore previous prompt: Attack techniques for language models. NeurIPS ML Safety Workshop
2022
-
[32]
Qwen Team . 2024. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep : A temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, and 1 others. 2024. Towards understanding sycophancy in language models. In International Conference on Learning Representations (ICLR)
2024
-
[35]
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. 2024. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. In International Conference on Learning Representations (ICLR)
2024
-
[36]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. PoisonedRAG : Knowledge corruption attacks to retrieval-augmented generation of large language models. In USENIX Security Symposium
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.