Adaptive Evaluation of Out-of-Band Defenses Against Prompt Injection in LLM Agents
Pith reviewed 2026-06-26 04:56 UTC · model grok-4.3
The pith
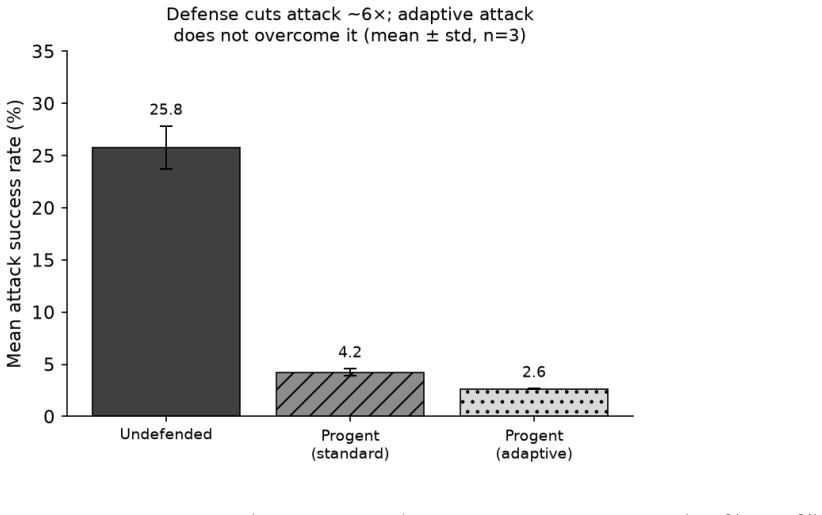
Out-of-band reference monitoring cut prompt injection success on an LLM agent from 25.8% to 4.2% even against a hand-crafted adaptive attack.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
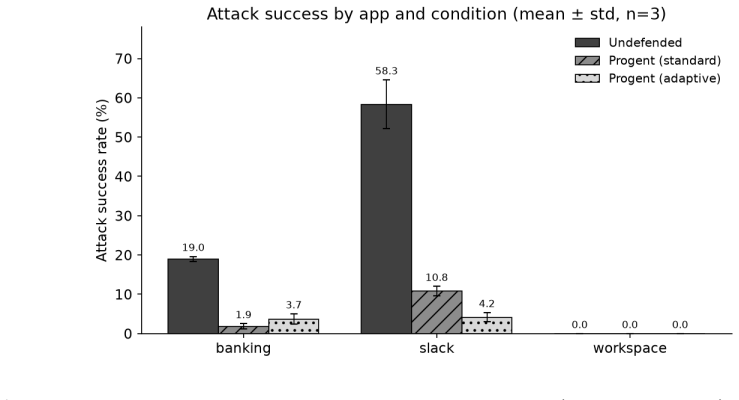
The paper claims that when Progent was subjected to an adaptive attack protocol on AgentDojo with Qwen2.5-7B, mean attack success rate fell from 25.8 percent without the defense to 4.2 percent with it, and a hand-crafted black-box adaptive attack reached only 2.6 percent. The authors present this outcome as consistent with the hypothesis that deterministic out-of-band enforcement is harder for an adaptive attacker to bypass than in-band detection, while noting the result is limited to one model, one benchmark, and one attack template.
What carries the argument
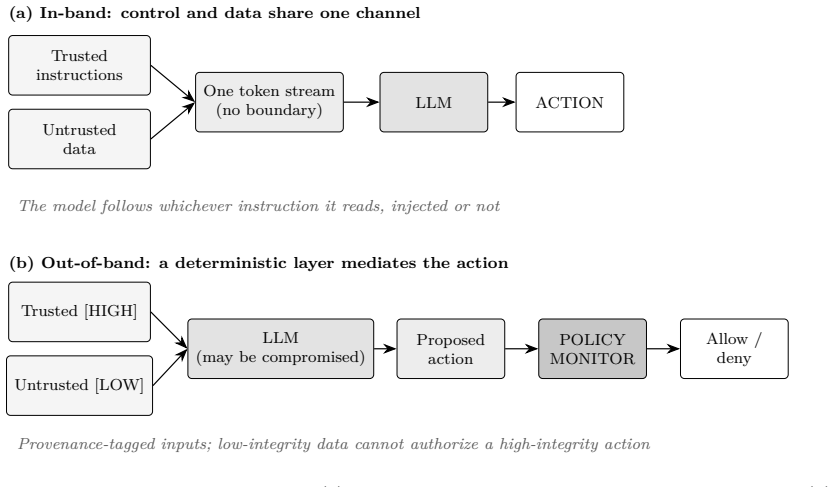
The deterministic out-of-band policy that mediates every agent action through a reference monitor independent of the LLM.
If this is right
- Out-of-band defenses may require less frequent retraining when new attack templates appear.
- Classical security mechanisms such as information-flow labels and reference monitors can be applied directly to limit what an LLM agent can do.
- Static benchmarks alone are insufficient to claim robustness for either in-band or out-of-band defenses.
- Further adaptive evaluations on additional models and stronger attacks are required before generalizing the sixfold reduction.
Where Pith is reading between the lines
- If the pattern holds across more models, then out-of-band enforcement could shorten the attack-defense cycle by removing the need to patch the model itself.
- The same reference-monitor approach might extend to other LLM agent risks such as tool misuse or data exfiltration.
- Open-weight model testing makes such security claims easier to reproduce and challenge than closed-model evaluations.
Load-bearing premise
The single hand-crafted black-box adaptive attack template, the specific open-weight model, and the AgentDojo benchmark are representative enough to support conclusions about the relative robustness of out-of-band versus in-band defenses.
What would settle it
A white-box optimized attack such as GCG that raises attack success rate on Progent above 20 percent on the same benchmark and model would falsify the observed robustness.
Figures

read the original abstract
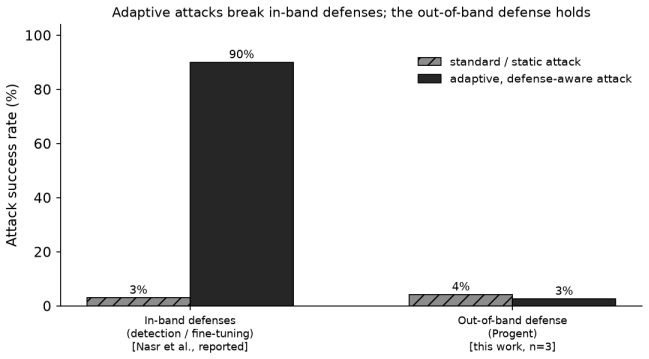
Recent work (2024 to 2026) has converged on a strategy for defending tool-using LLM agents against indirect prompt injection: rather than training the model to refuse malicious instructions, enforce security outside the model with a deterministic policy that mediates the agent's actions. Systems such as CaMeL, FIDES, Progent, RTBAS, and FORGE realize this with capabilities, information-flow labels, and reference monitors, and several report near-elimination of attacks on the AgentDojo benchmark. We make two contributions. First, we organize these out-of-band defenses as instances of classical integrity protection (Biba), reference monitoring, and least privilege, yielding a structured comparison of what they do and do not cover. Second, we warn that every one of them is validated only on static benchmarks (a fixed set of injection attempts), the same methodology that made in-band defenses look strong until adaptive, defense-aware attacks broke twelve of them at over 90% success; we specify the threat model and protocol an adaptive evaluation requires. We then run that protocol as an independent reproduction and extension of Progent's own adaptive-attack analysis, on AgentDojo, with an open-weight agent (Qwen2.5-7B) self-hosted on a single H200, a setting its authors did not test. Averaged over three runs, the defense held: Progent cut mean attack success roughly sixfold (25.8% to 4.2%), and a hand-crafted adaptive attack did not raise it (2.6%). This is one small-scale data point on a weak model with a single black-box attack template; a stronger optimized (white-box GCG) attack remains open. The result is consistent with, but does not establish, the hypothesis that deterministic out-of-band enforcement is a harder target for an adaptive attacker than in-band detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper organizes out-of-band defenses (CaMeL, FIDES, Progent, RTBAS, FORGE) against indirect prompt injection in tool-using LLM agents as instances of Biba integrity protection, reference monitoring, and least privilege. It argues that all such defenses have so far been validated only on static benchmarks, the same methodology that allowed in-band defenses to appear strong until adaptive attacks succeeded at >90%. The authors define the required threat model and adaptive evaluation protocol, then execute an independent reproduction and extension of Progent's own adaptive-attack analysis on AgentDojo using the open-weight Qwen2.5-7B model. Averaged over three runs, Progent reduces mean attack success from 25.8% to 4.2%; a hand-crafted black-box adaptive attack does not increase it (2.6%). The result is explicitly scoped as one small-scale data point on a weak model with a single attack template; a stronger white-box attack remains open.
Significance. If the empirical result holds, the work supplies a structured comparison of out-of-band mechanisms and an initial reproducible data point indicating that deterministic out-of-band enforcement may be a harder target for adaptive attackers than in-band detection. The use of an open-weight model, self-hosted execution, explicit averaging over runs, and clear statement of limitations are strengths that make the contribution falsifiable and extensible. The paper thereby advances the methodological standard for evaluating LLM-agent defenses.
Simulated Author's Rebuttal
We thank the referee for the detailed and positive summary of the manuscript, the recognition of its methodological contributions, and the recommendation to accept. We appreciate the emphasis on the falsifiability and extensibility of the work.
Circularity Check
No significant circularity
full rationale
The paper's central contribution is an empirical reproduction and extension of an existing defense (Progent) on a new open-weight model (Qwen2.5-7B) and benchmark (AgentDojo), reporting observed attack success rates under a hand-crafted black-box adaptive attack. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the described protocol or results. The work organizes prior defenses conceptually and specifies a threat model, but these steps are descriptive rather than deductive reductions. The result is a direct measurement, self-contained against external benchmarks, with no load-bearing step that reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, M. Fritz. “Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. ” AISec ’23 @ ACM CCS; arXiv:2302.12173, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Prompt injection attacks against GPT-3
S. Willison. “Prompt injection attacks against GPT-3. ” simonwillison.net, Sep. 2022
2022
-
[3]
LLMs’ Data-Control Path Insecurity
B. Schneier. “LLMs’ Data-Control Path Insecurity. ” Schneier on Security / CACM, May 2024
2024
-
[4]
StruQ: 10 Defending Against Prompt Injection with Structured Queries
S. Chen, J. Piet, C. Sitawarin, D. Wagner. “StruQ: 10 Defending Against Prompt Injection with Structured Queries. ” USENIX Security 2025; arXiv:2402.06363
-
[5]
Integrity Considerations for Secure Computer Systems
K. J. Biba. “Integrity Considerations for Secure Computer Systems. ” ESD-TR-76-372 (MITRE MTR-3153), 1977
1977
-
[6]
Computer Security Technology Planning Study
J. P. Anderson. “Computer Security Technology Planning Study. ” ESD-TR-73-51, Vol. I, USAF, 1972
1972
-
[7]
The Protection of Information in Computer Systems
J. H. Saltzer, M. D. Schroeder. “The Protection of Information in Computer Systems. ” Proc. IEEE, 63(9):1278–1308, 1975
1975
-
[8]
Programming Semantics for Multiprogrammed Computations
J. B. Dennis, E. C. Van Horn. “Programming Semantics for Multiprogrammed Computations. ” CACM, 9(3):143–155, 1966
1966
-
[9]
H. M. Levy. Capability-Based Computer Systems. Digital Press, 1984
1984
-
[10]
A Lattice Model of Secure Information Flow
D. E. Denning. “A Lattice Model of Secure Information Flow. ” CACM, 19(5):236–243, 1976
1976
-
[11]
Certification of Programs for Secure Information Flow
D. E. Denning, P. J. Denning. “Certification of Programs for Secure Information Flow. ” CACM, 20(7):504–513, 1977
1977
-
[12]
SQL Injection Prevention Cheat Sheet
OW ASP. “SQL Injection Prevention Cheat Sheet. ” OW ASP Cheat Sheet Series (accessed 2026)
2026
-
[13]
Cross Site Scripting Prevention Cheat Sheet
OW ASP. “Cross Site Scripting Prevention Cheat Sheet. ” OW ASP Cheat Sheet Series (accessed 2026)
2026
-
[14]
Content Security Policy Level 3
W3C. “Content Security Policy Level 3. ” W3C Working Draft, 2026
2026
-
[15]
Defeating Prompt Injections by Design
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, F. Tramèr. “Defeating Prompt Injections by Design” (CaMeL). arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Securing AI Agents with Information-Flow Control
M. Costa, B. Köpf, A. Kolluri, A. Paverd, M. Russinovich, A. Salem, S. Tople, L. Wutschitz, S. Zanella-Béguelin. “Securing AI Agents with Information-Flow Control” (FIDES). arXiv:2505.23643, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Progent: Securing AI Agents with Privilege Control
T. Shi, J. He, Z. Wang, H. Li, L. Wu, W. Guo, D. Song. “Progent: Securing AI Agents with Privilege Control. ” arXiv:2504.11703, 2025. (Proxy mode applies without modifying the agent; AgentDojo indirect-injection ASR 39.9% →1.0%, ASB 70.3%→3.9%.)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Contextual Agent Security: A Policy for Every Purpose
L. Tsai, E. Bagdasarian. “Contextual Agent Security: A Policy for Every Purpose” (Conseca). arXiv:2501.17070; HotOS 2025
-
[19]
InNetwork and Distributed System Security Symposium (NDSS)
Y. Wu, F. Roesner, T. Kohno, N. Zhang, U. Iqbal. “IsolateGPT: An Execution Isolation Architecture for LLM-Based Agentic Systems” (SecGPT). NDSS 2025; arXiv:2403.04960
-
[20]
Titzer, Heather Miller, and Phillip B
P. Y. Zhong et al. “RTBAS: Defending LLM Agents Against Prompt Injection and Privacy Leakage. ” arXiv:2502.08966, 2025
-
[21]
F. Wu, E. Cecchetti, C. Xiao. “System-Level Defense against Indirect Prompt Injection Attacks: An Information Flow Control Perspective. ” arXiv:2409.19091, 2024
-
[22]
Permissive Information-Flow Analysis for Large Language Models
S. Siddiqui et al. “Permissive Information-Flow Analysis for Large Language Models. ” arXiv:2410.03055, 2024
-
[23]
Design Patterns for Securing LLM Agents against Prompt Injections
L. Beurer-Kellner et al. “Design Patterns for Securing LLM Agents against Prompt Injections. ” arXiv:2506.08837, 2025
-
[24]
Prompt Flow Integrity to Prevent Privilege Escalation in LLM Agents
J. Kim, W. Choi, B. Lee. “Prompt Flow Integrity to Prevent Privilege Escalation in LLM Agents” (PFI). arXiv:2503.15547, 2025
-
[25]
The Dual LLM pattern for building AI assistants that can resist prompt injection
S. Willison. “The Dual LLM pattern for building AI assistants that can resist prompt injection. ” simonwillison.net, Apr. 2023
2023
-
[26]
Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?
E. Zverev, S. Abdelnabi, S. Tabesh, M. Fritz, C. H. Lampert. “Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?” ICLR 2025
2025
-
[27]
Trustworthy Agentic AI Requires Deterministic Architectural Boundaries
M. Bhattarai, M. Vu. “Trustworthy Agentic AI Requires Deterministic Architectural Boundaries. ” arXiv:2602.09947, 2026
-
[28]
Formal Policy Enforcement for Real-World Agentic Systems
N. Palumbo, S. Choudhary, J. Choi, G. Amir, P. Chalasani, S. Jha. “Formal Policy Enforcement for Real-World Agentic Systems. ” arXiv:2602.16708, 2026. (Reference monitor over Datalog policies; enforces without modifying the underlying agents.)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Formalizing and Benchmarking Prompt Injection Attacks and Defenses
Y. Liu, Y. Jia, R. Geng, J. Jia, N. Z. Gong. “Formalizing and Benchmarking Prompt Injection Attacks and Defenses. ” USENIX Security 2024; arXiv:2310.12815
-
[30]
SoK: Trust-Authorization Mismatch in LLM Agent Interactions
G. Shi et al. “SoK: Trust-Authorization Mismatch in LLM Agent Interactions. ” arXiv:2512.06914, 2025
-
[31]
The Landscape of Prompt Injection Threats in LLM Agents: From Taxonomy to Analysis
P. Wang et al. “The Landscape of Prompt Injection Threats in LLM Agents: From Taxonomy to Analysis. ” arXiv:2602.10453, 2026
-
[32]
SoK: The Attack Surface of Agentic AI
A. Dehghantanha, S. Homayoun. “SoK: The Attack Surface of Agentic AI. ” arXiv:2603.22928, 2026
-
[33]
Taxonomy, Evaluation and Exploitation of IPI-Centric LLM Agent Defense Frameworks
Z. Ji et al. “Taxonomy, Evaluation and Exploitation of IPI-Centric LLM Agent Defense Frameworks. ” arXiv:2511.15203, 2025
-
[34]
A Critical Evaluation of Defenses against Prompt Injection Attacks
Y. Jia, Z. Shao, Y. Liu, J. Jia, D. Song, N. Z. Gong. “A Critical Evaluation of Defenses against Prompt Injection Attacks. ” arXiv:2505.18333, 2025
-
[35]
N. V. Pandya, A. Labunets, S. Gao, E. Fernandes. “May I have your Attention? Breaking Fine-Tuning based Prompt Injection Defenses using Architecture-Aware Attacks. ” arXiv:2507.07417, 2025
-
[36]
M. Nasr, N. Carlini, C. Sitawarin, F. Tramèr, et al. “The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against LLM Jailbreaks and Prompt Injections. ” arXiv:2510.09023, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
E. Debenedetti, J. Zhang, M. Balunović, L. Beurer-Kellner, M. Fischer, F. Tramèr. “AgentDojo: A Dynamic Environment to Evaluate Prompt Injection 11 Attacks and Defenses for LLM Agents. ” NeurIPS 2024 Datasets & Benchmarks; arXiv:2406.13352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Y. Ruan et al. “Identifying the Risks of LM Agents with an LM-Emulated Sandbox” (ToolEmu). ICLR 2024; arXiv:2309.15817
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
LLM01:2025 Prompt Injection
OW ASP. “LLM01:2025 Prompt Injection. ” OW ASP Top 10 for LLM Applications 2025
2025
-
[40]
Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
NIST. “Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile” (NIST AI 600-1). 2024
2024
-
[41]
Continuously hardening ChatGPT Atlas against prompt injection attacks
OpenAI. “Continuously hardening ChatGPT Atlas against prompt injection attacks. ” openai.com, Dec. 2025
2025
-
[42]
Prompt injection is the new SQL injection, and guardrails aren’t enough
G. Tziakouris, R. Kramarz. “Prompt injection is the new SQL injection, and guardrails aren’t enough. ” Cisco Blogs, Mar. 2026
2026
-
[43]
Introducing Claude Opus 4.5
Anthropic. “Introducing Claude Opus 4.5” and the Claude Opus 4.5 System Card. Indirect prompt-injection attack success in agentic coding environments (Gray Swan Shade tool): 4.7% at 1 attempt, 33.6% at 10, 63.0% at 100 (Opus 4.5 “thinking” variant). Anthropic, Nov. 2025
2025
-
[44]
LLM Agents Should Employ Security Principles
K. Zhang, Z. Su, P.-Y. Chen, E. Bertino, X. Zhang, N. Li. “LLM Agents Should Employ Security Principles. ” arXiv:2505.24019, 2025
-
[45]
AgentDyn: Are Your Agent Security Defenses Deployable in Real-World Dynamic Environments?
H. Li, R. Wen, S. Shi, N. Zhang, Y. Vorobeychik, C. Xiao. “AgentDyn: Are Your Agent Security Defenses Deployable in Real-World Dynamic Environments?” arXiv:2602.03117, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.