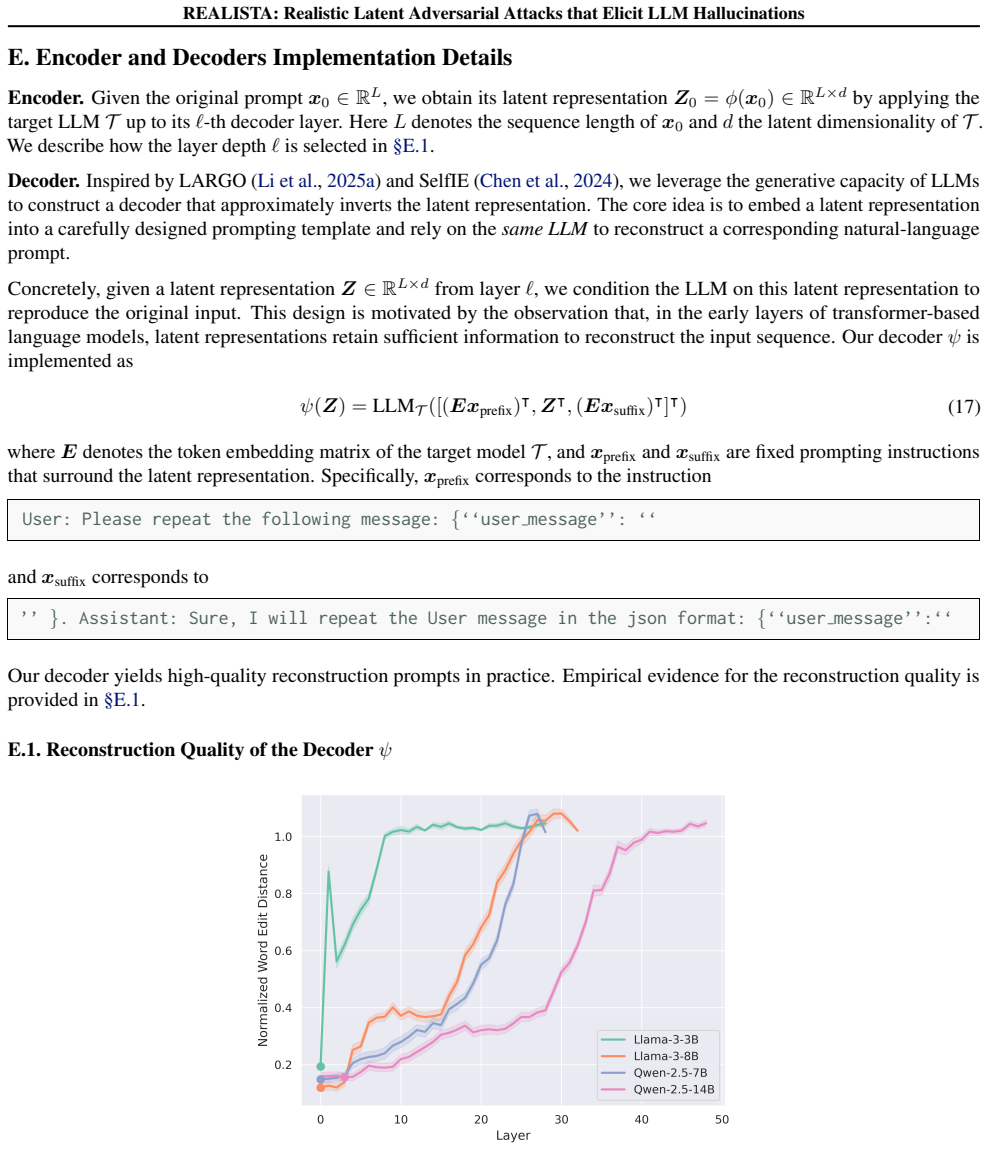
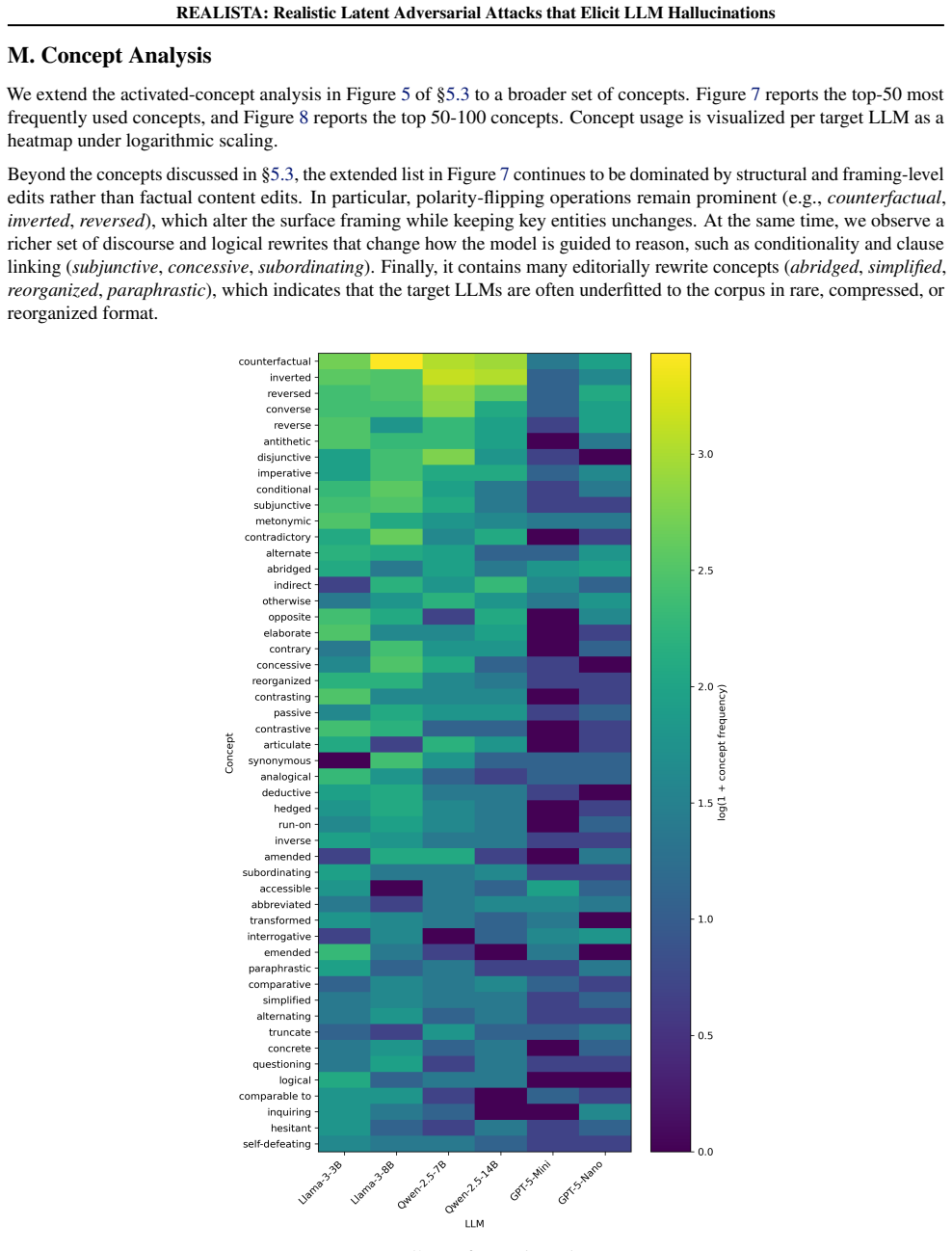
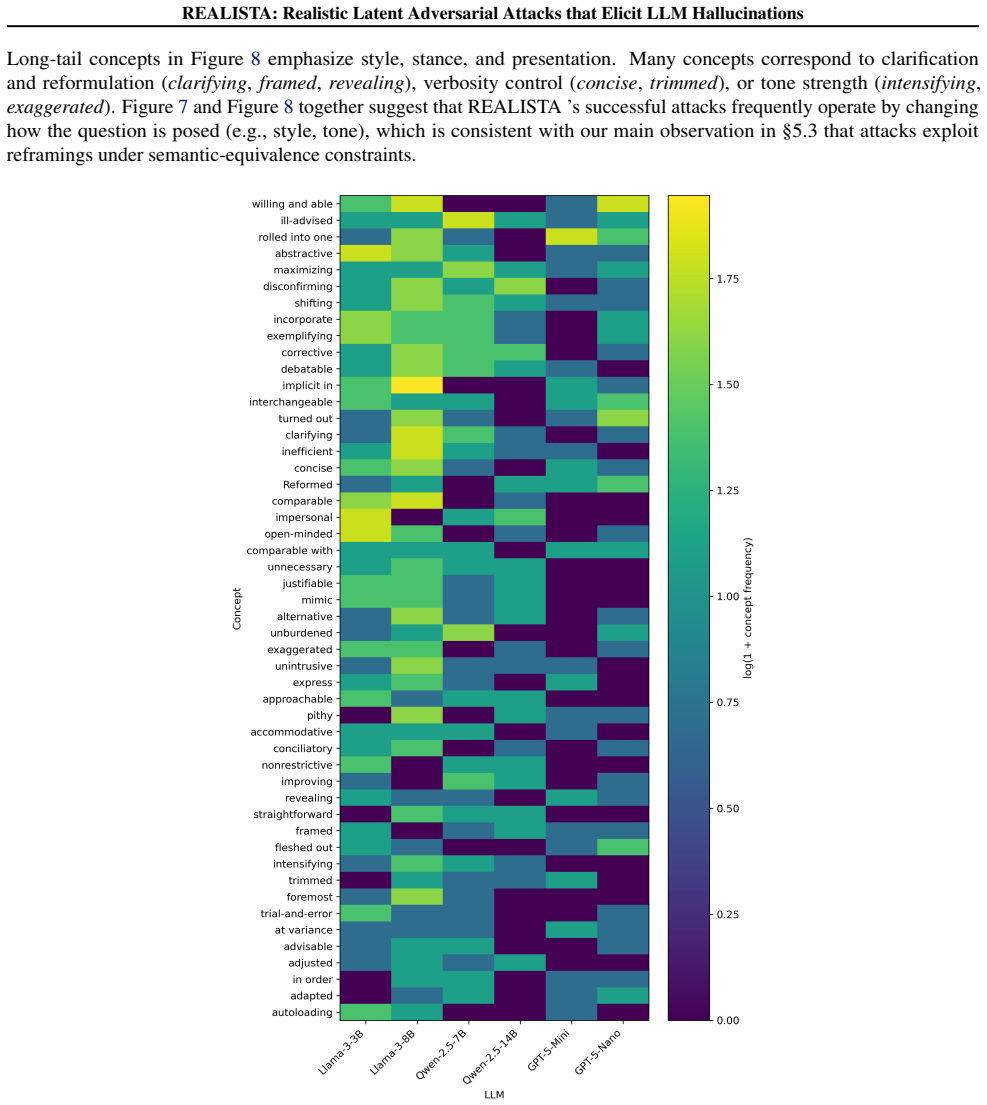
REALISTA: Realistic Latent Adversarial Attacks that Elicit LLM Hallucinations
Pith reviewed 2026-06-30 21:55 UTC · model grok-4.3
The pith
REALISTA optimizes continuous combinations of input-specific editing directions in latent space to produce semantically coherent adversarial prompts that elicit LLM hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REALISTA constructs an input-dependent dictionary of valid editing directions, each tied to a semantically equivalent and coherent rephrasing, then optimizes continuous combinations of these directions in latent space. The resulting adversarial prompts remain realistic rephrasings yet reliably elicit hallucinations, achieving superior or comparable results to state-of-the-art realistic attacks on open-source LLMs and succeeding on large reasoning models under free-form response conditions where prior realistic attacks fail.
What carries the argument
Input-dependent dictionary of valid editing directions, which supplies a set of semantically coherent rephrasings whose continuous linear combinations are optimized in latent space while preserving equivalence after decoding.
If this is right
- Hallucination elicitation reduces to constrained optimization over realistic rephrasings rather than unrestricted prompt search.
- Large reasoning models remain vulnerable to free-form adversarial inputs even when discrete prompt attacks cannot reach them.
- The same dictionary-plus-optimization design can be applied to other LLM failure modes that require semantic preservation.
- Performance gains appear on both open-source and reasoning models without sacrificing prompt realism.
Where Pith is reading between the lines
- The method could generate synthetic training examples to strengthen alignment procedures against realistic adversarial inputs.
- Extending the dictionary construction to other modalities or tasks might produce comparable attacks on vision-language models.
- If the dictionary size or coverage proves insufficient on some inputs, hybrid discrete-continuous search could be tested as a direct follow-up.
Load-bearing premise
The dictionary of editing directions contains enough effective combinations that remain semantically equivalent and coherent once decoded into text.
What would settle it
Running the optimization on a target LLM and finding that every decoded prompt from the optimized combination either fails to elicit hallucinations or produces incoherent or non-equivalent text.
Figures






read the original abstract
Large language models (LLMs) achieve strong performance across many tasks but remain vulnerable to hallucinations, making it important to systematically evaluate their reliability under realistic adversarial inputs. We formulate hallucination elicitation as a constrained optimization problem, where the goal is to find semantically coherent adversarial prompts that are equivalent to benign user prompts. Existing attack methods remain limited: discrete prompt-based attacks preserve semantic equivalence and coherence but search only over a limited set of prompt variations, while continuous latent-space attacks explore a richer space but often decode into prompts that are no longer valid rephrasings. To address these limitations, we propose REALISTA, a realistic latent-space attack framework. REALISTA constructs an input-dependent dictionary of valid editing directions, each corresponding to a semantically equivalent and coherent rephrasing, and optimizes continuous combinations of these directions in latent space. This design combines the optimization flexibility of continuous attacks with the semantic realism of discrete rephrasing-based attacks. Experiments demonstrate that REALISTA achieves superior or comparable performance to state-of-the-art realistic attacks on open-source LLMs and, crucially, succeeds in attacking large reasoning models under free-form response settings, where prior realistic attacks fail. Code is available at https://github.com/Buyun-Liang/REALISTA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REALISTA, a latent adversarial attack framework for eliciting hallucinations in LLMs. It formulates the task as constrained optimization over semantically coherent and equivalent prompts, constructs an input-dependent dictionary of valid editing directions in latent space, and optimizes continuous combinations of these directions. The central empirical claim is that this yields superior or comparable performance to prior realistic attacks on open-source LLMs and succeeds against large reasoning models in free-form response settings where earlier realistic methods fail.
Significance. If the central empirical results hold, the work would be significant for LLM reliability evaluation by combining the search flexibility of continuous latent attacks with the semantic validity of discrete rephrasing attacks. The public code release at https://github.com/Buyun-Liang/REALISTA is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: performance claims (superior/comparable results on open-source LLMs; success on large reasoning models in free-form settings) are stated without any quantitative numbers, tables, error bars, or details on how semantic equivalence and coherence are enforced or measured.
- [Abstract] The load-bearing premise that the input-dependent dictionary of editing directions is sufficiently dense and combinable to produce valid, coherent, semantically equivalent rephrasings after gradient-based optimization (rather than out-of-distribution text) receives no quantitative characterization of coverage, density, or decoded-output failure rate; without this the superiority claim on reasoning models cannot be assessed.
minor comments (1)
- [Abstract] The abstract would benefit from a brief sentence on the scale of the evaluated models and the number of test cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract could be strengthened with quantitative details. We agree that incorporating key results and method specifics will improve clarity and will revise the abstract accordingly. Our responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance claims (superior/comparable results on open-source LLMs; success on large reasoning models in free-form settings) are stated without any quantitative numbers, tables, error bars, or details on how semantic equivalence and coherence are enforced or measured.
Authors: We acknowledge that the current abstract presents these claims qualitatively. The full manuscript (Section 4) includes detailed tables, figures with error bars, and quantitative comparisons showing performance margins on open-source LLMs as well as success rates on reasoning models. We will revise the abstract to include 1-2 key quantitative highlights (e.g., relative improvements and success rates) and a concise clause on how semantic equivalence is enforced via the constrained optimization over input-dependent editing directions (detailed in Section 3). revision: yes
-
Referee: [Abstract] The load-bearing premise that the input-dependent dictionary of editing directions is sufficiently dense and combinable to produce valid, coherent, semantically equivalent rephrasings after gradient-based optimization (rather than out-of-distribution text) receives no quantitative characterization of coverage, density, or decoded-output failure rate; without this the superiority claim on reasoning models cannot be assessed.
Authors: The manuscript validates coherence and equivalence through automatic metrics and human evaluation in the experiments, but we agree that explicit quantitative characterization of dictionary coverage, density, and decoded-output failure rates is not currently in the abstract (or sufficiently highlighted). We will add a brief analysis of these aspects (e.g., failure rate of optimized prompts remaining valid rephrasings) to the method/experiments sections and reference the key statistic in the revised abstract to support the claims on reasoning models. revision: yes
Circularity Check
No circularity: algorithmic framework with independent construction steps
full rationale
The paper presents REALISTA as a procedural framework: it constructs an input-dependent dictionary of editing directions from the input prompt and then performs continuous optimization over combinations of those directions. No equations or claims reduce a derived quantity to a fitted parameter by construction, no self-citations are invoked as load-bearing uniqueness theorems, and the optimization objective is stated as an external constrained problem rather than a self-referential definition. The method therefore remains self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
URL http://arxiv.org/abs/2309.08600 . arXiv:2309.08600 [cs]. Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Lan- guage Understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (l...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/1390156.1390191 2019
-
[2]
On the importance of different cough phases for covid-19 detection,
URL https://openreview.net/forum?id=dF wBosAcJkN. Li, B., Li, Z., Du, Q., Luo, J., Wang, W., Xie, Y ., Stepput- tis, S., Wang, C., Sycara, K., Ravikumar, P., and others. Logicity: Advancing neuro-symbolic ai with abstract urban simulation.Advances in Neural Information Pro- cessing Systems, 37:69840–69864, 2024. Li, R., Wang, H., and Mao, C. LARGO: Latent...
-
[3]
Mehrotra, A., Zampetakis, M., Kassianik, P., Nelson, B., Anderson, H., Singer, Y ., and Karbasi, A
arXiv:2503.10965 [cs]. Mehrotra, A., Zampetakis, M., Kassianik, P., Nelson, B., Anderson, H., Singer, Y ., and Karbasi, A. Tree of Attacks: Jailbreaking Black-Box LLMs Automatically. In Glober- son, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Processing Systems, volume 37, pp. 61065– ...
-
[4]
Association for Computational Linguistics. doi: 10.3115/v1/D14-1162. URL http://aclweb.org/ant hology/D14-1162. 12 REALISTA: Realistic Latent Adversarial Attacks that Elicit LLM Hallucinations Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., and Zettlemoyer, L. Deep Contextualized Word Representations. In Walker, M., Ji, H., and Ste...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3115/v1/d14-1162 2018
-
[5]
URL http://arxiv.org/abs/2501.09929 . arXiv:2501.09929 [cs]. Tenney, I., Xia, P., Chen, B., Wang, A., Poliak, A., Mc- Coy, R. T., Kim, N., Durme, B. V ., Bowman, S., Das, D., and Pavlick, E. What Do You Learn from Con- text? Probing for Sentence Structure in Contextual- ized Word Representations. InInternational Confer- ence on Learning Representations, 2...
-
[6]
Steering Language Models With Activation Engineering
URL http://arxiv.org/abs/2308.10248 . arXiv:2308.10248 [cs]. Wang, C., Duan, J., Xiao, C., Kim, E., Stamm, M., and Xu, K. Semantic Adversarial Attacks via Diffusion Models, September 2023. URL http://arxiv.org/abs/2309 .07398. arXiv:2309.07398 [cs]. Wiegreffe, S., Tafjord, O., Belinkov, Y ., Hajishirzi, H., and Sabharwal, A. Answer, Assemble, Ace: Under- ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-0048 2023
-
[7]
Universal and Transferable Adversarial Attacks on Aligned Language Models
URL http://arxiv.org/abs/2307.15043 . arXiv:2307.15043 [cs]. Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., Goel, S., Li, N., Byun, M. J., Wang, Z., Mallen, A., Basart, S., Koyejo, S., Song, D., Fredrikson, M., Kolter, J. Z., and Hendrycks, D. Representation Engineering: A Top-Down Approach t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.