Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
Pith reviewed 2026-07-01 05:19 UTC · model grok-4.3
The pith
Reinforcement learning guided by models' self-judgments of performance produces more faithful uncertainty expression in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
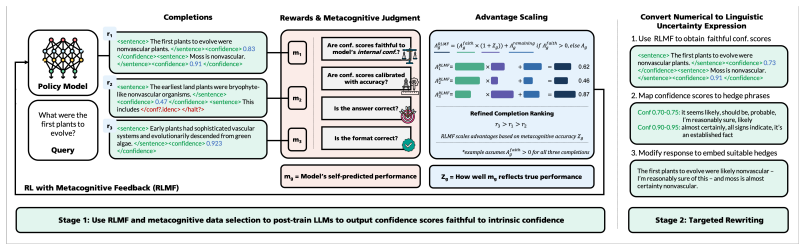
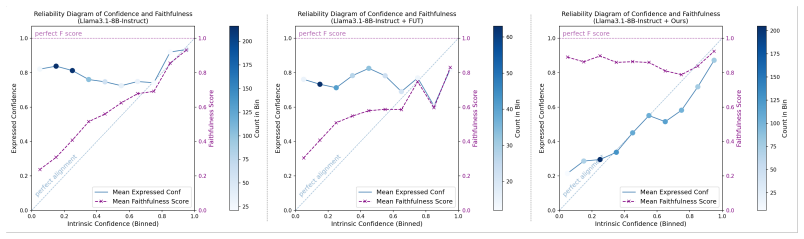
Reinforcement learning with metacognitive feedback (RLMF) incorporates the quality of a model's self-judgments of its performance to refine completion rankings during preference optimization and to select high-value training examples. Applied first to calibrate self-reported confidence scores and then to map them to context-adaptable linguistic uncertainty expressions, RLMF delivers generalizable state-of-the-art faithful calibration on diverse tasks while preserving accuracy and surpassing standard RL by up to 63 percent.
What carries the argument
Reinforcement learning with metacognitive feedback (RLMF), a training loop that ranks candidate completions by the accuracy of the model's own performance judgments rather than external rewards alone.
If this is right
- Models reach generalizable state-of-the-art faithful calibration across tasks without accuracy loss.
- The approach improves detection and expression of capability limits compared with baseline methods.
- Metacognitive self-judgment quality functions as a stronger reinforcement learning signal than standard intrinsic feedback.
- A two-stage process first aligns numeric confidence then converts it to natural language uncertainty.
Where Pith is reading between the lines
- The same self-judgment signal could be tested on other alignment objectives such as error detection or step-by-step reasoning.
- Deployed systems using this method might show reduced confident errors in safety-critical settings.
- The separation of numeric calibration from linguistic expression allows independent tuning of each stage.
- Scaling experiments on larger models would reveal whether the 63 percent gain holds or changes with model size.
Load-bearing premise
A model's judgments about whether its own outputs are correct supply a reliable, non-circular signal that can rank responses and pick training data.
What would settle it
Running the full RLMF pipeline on multiple held-out calibration benchmarks and finding no gain in calibration error or self-assessment accuracy relative to standard RL would falsify the central claim.
Figures













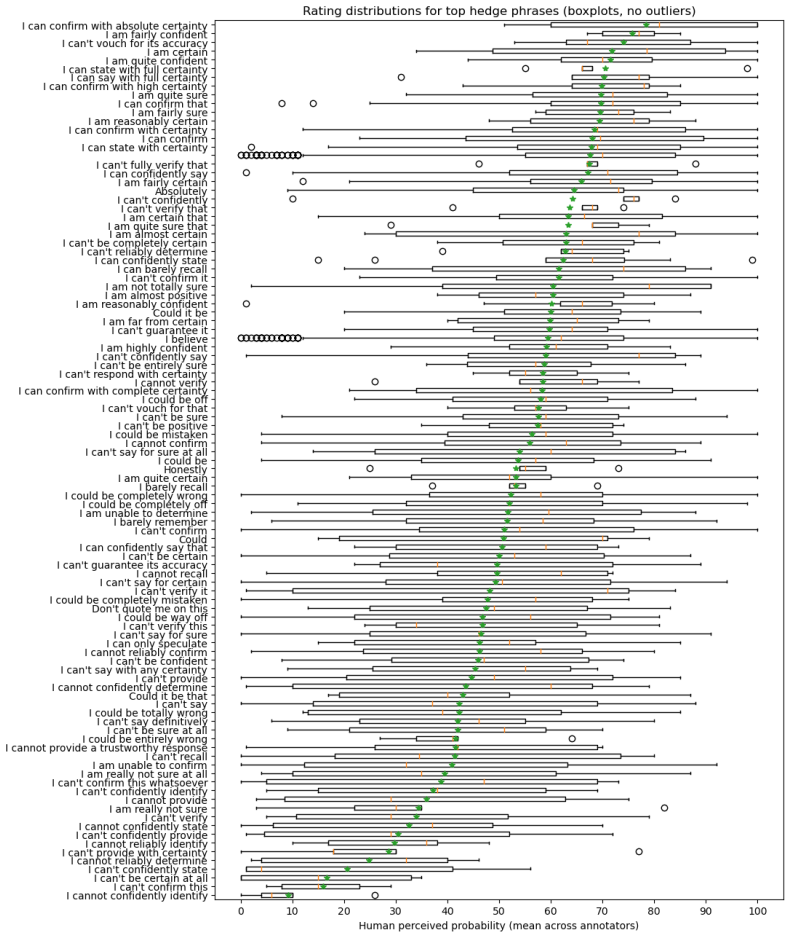
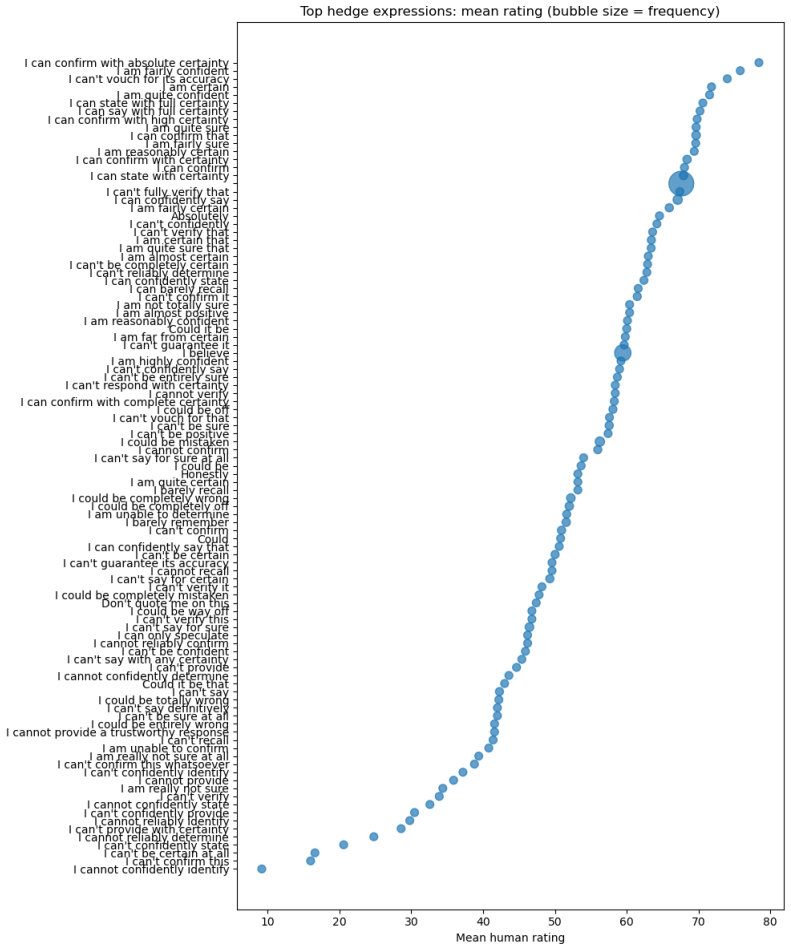
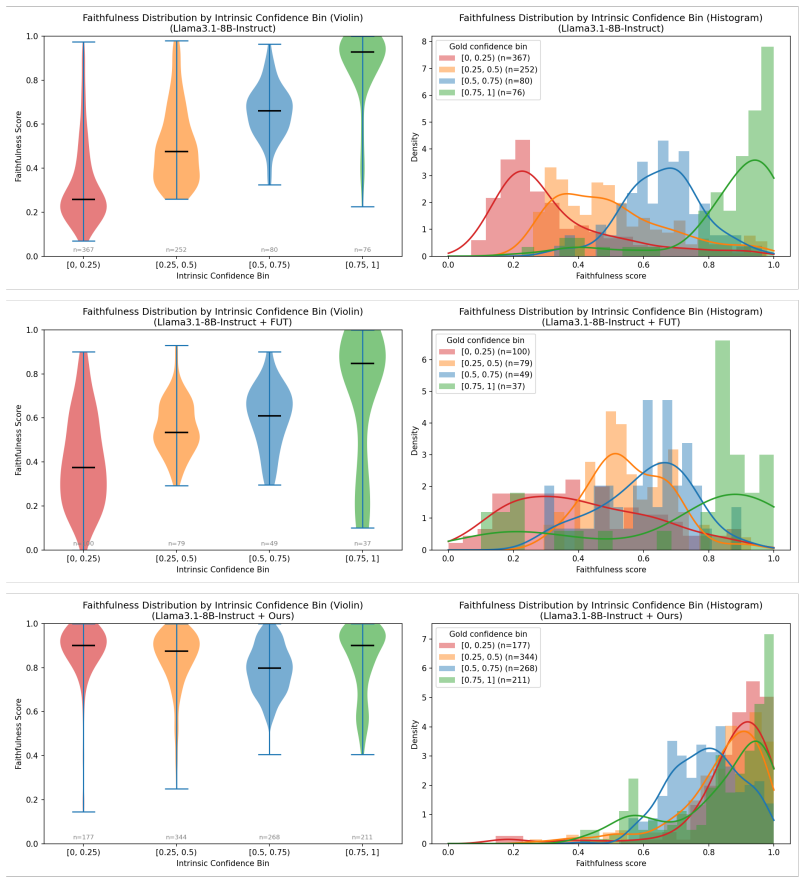
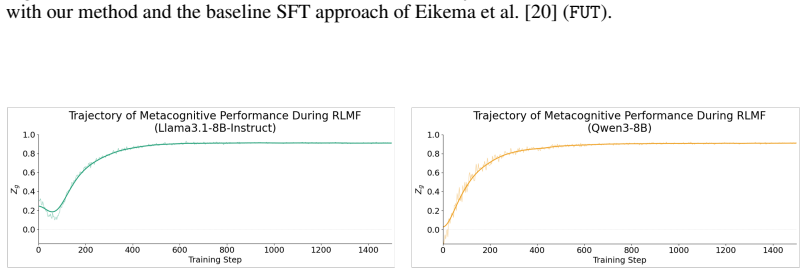



read the original abstract
Metacognition is a critical component of intelligence that describes the ability to monitor and regulate one's own cognitive processes. Yet LLMs exhibit systemic deficiencies in key metacognitive faculties: they hallucinate with high confidence, fail to recognize knowledge boundaries, and misrepresent their internal uncertainty--undermining trustworthiness and reliability. Since monitoring task performance and adapting behavior accordingly are central to metacognition, we posit that models capable of accurately judging their own performance are better positioned to improve it. We operationalize this idea via two novel mechanisms: reinforcement learning with metacognitive feedback (RLMF), a paradigm to refine completion rankings during preference optimization based on the quality of a model's self-judgments of performance, and metacognitive data selection, which uses similar self-judgments to identify high-value training examples, outperforming naive active learning. We apply these innovations to the problem of faithful calibration (FC), a task that is itself fundamentally metacognitive: the goal is to align expressed with intrinsic uncertainty, difficult even for frontier LLMs. We adopt a two-stage, decoupled approach, first using these methods to calibrate the faithfulness of models' self-reported confidence scores, then mapping to natural, context-adaptable linguistic uncertainty via targeted output editing. Extensive experiments show RLMF achieves generalizable, state-of-the-art FC on diverse tasks while preserving accuracy. Further, RLMF surpasses standard RL by up to 63% while enhancing models' ability to assess and express their own capability limits. This positions RLMF as a promising paradigm to enhance LLM metacognition toward improved abilities and alignment, and suggests metacognitive performance as an effective RL signal to overcome limits of prior intrinsic feedback methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reinforcement Learning with Metacognitive Feedback (RLMF) and metacognitive data selection to address LLMs' deficiencies in metacognition and faithful calibration (FC). It operationalizes the idea that accurate self-judgment of performance can improve model behavior via two mechanisms: using self-judgments to refine completion rankings in preference optimization and to select high-value training examples. A two-stage approach first calibrates self-reported confidence then maps to linguistic uncertainty expressions. The abstract claims this yields generalizable SOTA FC on diverse tasks while preserving accuracy and surpassing standard RL by up to 63%.
Significance. If the empirical claims hold with rigorous validation, this would be a meaningful contribution to LLM alignment and trustworthiness by introducing metacognitive performance as an external RL signal. The decoupled two-stage design and data-selection method could generalize beyond FC to other self-improvement settings.
major comments (2)
- [Abstract] Abstract (paragraph beginning 'Since monitoring task performance...'): the central premise that self-judgments of performance provide a reliable, non-circular signal for both ranking in preference optimization and filtering training examples is load-bearing for the 63% improvement claim and the SOTA FC result. The manuscript acknowledges 'systemic deficiencies' in exactly this faculty yet provides no demonstration that initial judgment quality is high enough to avoid reinforcing miscalibrations rather than correcting them.
- [Abstract] Abstract: the claims of 'generalizable, state-of-the-art FC' and 'surpasses standard RL by up to 63%' are presented without any experimental details, task definitions, baselines, metrics, error bars, or statistical tests. These omissions prevent evaluation of whether the reported gains are robust or reduce to implementation choices.
minor comments (1)
- [Abstract] Abstract: the acronym 'FC' for faithful calibration is introduced without a concise definition or pointer to how it differs from standard calibration metrics.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below with clarifications from the full paper and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning 'Since monitoring task performance...'): the central premise that self-judgments of performance provide a reliable, non-circular signal for both ranking in preference optimization and filtering training examples is load-bearing for the 63% improvement claim and the SOTA FC result. The manuscript acknowledges 'systemic deficiencies' in exactly this faculty yet provides no demonstration that initial judgment quality is high enough to avoid reinforcing miscalibrations rather than correcting them.
Authors: We agree this is a critical point. The manuscript explicitly notes systemic deficiencies in metacognition, and the RLMF framework is motivated precisely to address them via iterative refinement. Section 3 details how the two-stage process (first calibrating self-reported confidence via metacognitive feedback, then mapping to linguistic expressions) and the data selection mechanism use self-judgment quality as a signal that improves over iterations, with empirical results showing progressive gains rather than reinforcement of errors. To directly address the concern, we will add an ablation analysis (new subsection in Experiments) quantifying initial self-judgment accuracy against ground truth and its relationship to final performance improvements. revision: partial
-
Referee: [Abstract] Abstract: the claims of 'generalizable, state-of-the-art FC' and 'surpasses standard RL by up to 63%' are presented without any experimental details, task definitions, baselines, metrics, error bars, or statistical tests. These omissions prevent evaluation of whether the reported gains are robust or reduce to implementation choices.
Authors: The abstract is a concise summary; all requested details are provided in the full manuscript. Section 4 defines the tasks (diverse benchmarks including factual QA, reasoning, and generation), baselines (standard RL methods such as DPO and PPO), and metrics (faithful calibration error, accuracy preservation, uncertainty expression alignment). Section 5 reports results with error bars from multiple seeds, statistical tests, and tables/figures demonstrating generalizability and the up-to-63% gains. These sections enable full evaluation of robustness. revision: no
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract presents RLMF as an operationalization of the posited idea that accurate self-judgment enables performance improvement, using self-judgments for ranking and data selection in a two-stage process for faithful calibration. No equations, derivations, or self-citations are quoted that reduce any claimed result (e.g., the 63% gain or SOTA FC) to the inputs by construction, nor is there evidence of fitted parameters renamed as predictions, ansatz smuggling, or uniqueness theorems. The central claims rest on experimental outcomes rather than definitional equivalence, making the chain independent of the target defect per the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The unreasonable effectiveness of entropy minimization in LLM reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in LLM reasoning. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems, 2025. URL https://openreview.net/ forum?id=UfFTBEsLgI
2025
-
[2]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://openreview.net/forum?id=y2V6YgLaW7
2023
-
[3]
Linguistic calibration of long-form generations, 2024
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long-form generations, 2024. URLhttps://arxiv.org/abs/2404.00474
-
[4]
Cycles of thought: Measuring llm confidence through stable explanations, 2024
Evan Becker and Stefano Soatto. Cycles of thought: Measuring llm confidence through stable explanations, 2024. URLhttps://arxiv.org/abs/2406.03441
-
[5]
Perceptions of linguistic uncertainty by language models and humans
Catarina G Belém, Markelle Kelly, Mark Steyvers, Sameer Singh, and Padhraic Smyth. Perceptions of linguistic uncertainty by language models and humans. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8467–8502, Miami, Florida, USA, November
2024
-
[6]
doi: 10.18653/v1/2024.emnlp-main.483
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.483. URLhttps://aclanthology.org/2024.emnlp-main.483/
-
[7]
NLTK: The natural language toolkit
Steven Bird and Edward Loper. NLTK: The natural language toolkit. InProceedings of the ACL Interactive Poster and Demonstration Sessions, pages 214–217, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/ P04-3031/
2004
-
[8]
Salah Bouktif, Abderraouf Cheniki, Ali Ouni, and Hesham El-Sayed. Deep reinforcement learning for traffic signal control with consistent state and reward design approach.Know.- Based Syst., 267(C), May 2023. ISSN 0950-7051. doi: 10.1016/j.knosys.2023.110440. URL https://doi.org/10.1016/j.knosys.2023.110440
-
[9]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision, 2024. URL https://arxiv.org/abs/2212.03827
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods.IEEE Transactions on Neural Networks and Learning Systems, 36(6):9737–9757, 2024
Yuji Cao, Huan Zhao, Yuheng Cheng, Ting Shu, Yue Chen, Guolong Liu, Gaoqi Liang, Junhua Zhao, Jinyue Yan, and Yun Li. Survey on large language model-enhanced reinforcement learning: Concept, taxonomy, and methods.IEEE Transactions on Neural Networks and Learning Systems, 36(6):9737–9757, 2024
2024
-
[11]
Finetuning language models to emit linguistic expressions of uncertainty, 2024
Arslan Chaudhry, Sridhar Thiagarajan, and Dilan Gorur. Finetuning language models to emit linguistic expressions of uncertainty, 2024. URLhttps://arxiv.org/abs/2409.12180
-
[12]
Finetuning language models to emit linguistic expressions of uncertainty
Arslan Chaudhry, Sridhar Thiagarajan, and Dilan Gorur. Finetuning language models to emit linguistic expressions of uncertainty. InICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI, 2025. URL https: //openreview.net/forum?id=eXkLpsoy54
2025
-
[13]
Quantifying uncertainty in answers from any language model and enhancing their trustworthiness
Jiuhai Chen and Jonas Mueller. Quantifying uncertainty in answers from any language model and enhancing their trustworthiness. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 5186–5200, Bangkok, Thailand, August
-
[14]
doi: 10.18653/v1/2024.acl-long.283
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.283. URL https://aclanthology.org/2024.acl-long.283/
-
[15]
Minghan Chen, Guikun Chen, Wenguan Wang, and Yi Yang. Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization.arXiv preprint arXiv:2505.12346, 2025
-
[16]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018. 10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E. Ho. Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models, 2024
2024
-
[18]
Beyond binary rewards: Training LMs to reason about their uncertainty
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training LMs to reason about their uncertainty. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=ASQ649zdHm
2026
-
[19]
Calibration of pre-trained transformers
Shrey Desai and Greg Durrett. Calibration of pre-trained transformers. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empiri- cal Methods in Natural Language Processing (EMNLP), pages 295–302, Online, November
2020
-
[20]
doi: 10.18653/v1/2020.emnlp-main.21
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.21. URLhttps://aclanthology.org/2020.emnlp-main.21/
-
[21]
Metacognitive capabilities of LLMs: An exploration in mathemat- ical problem solving
Aniket Rajiv Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy P Lillicrap, Danilo Jimenez Rezende, Yoshua Bengio, Michael Curtis Mozer, and Sanjeev Arora. Metacognitive capabilities of LLMs: An exploration in mathemat- ical problem solving. InAI for Math Workshop @ ICML 2024, 2024. URL https: //openreview.net/forum?id=0MsI3bSmmD
2024
-
[22]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computation...
- [23]
-
[24]
Fact-checking the output of large language models via token-level uncertainty quantification
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, and Maxim Panov. Fact-checking the output of large language models via token-level uncertainty quantification. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,...
-
[25]
Perception of probability words, 2023
Wade Fagen-Ulmschneider. Perception of probability words, 2023. URL https://waf.cs. illinois.edu/visualizations/Perception-of-Probability-Words/
2023
-
[26]
How to measure metacognition.Frontiers in Human Neuroscience, 8:443, 07 2014
Stephen Fleming and Hakwan Lau. How to measure metacognition.Frontiers in Human Neuroscience, 8:443, 07 2014. doi: 10.3389/fnhum.2014.00443
-
[27]
Quantifying Faithful Confidence Expression in Large Reasoning Models
Areeb Gani, Asal Meskin, Gabrielle Kaili-May Liu, and Arman Cohan. Quantifying faithful confidence expression in large reasoning models.arXiv preprint arXiv:2606.03969, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Epistemic integrity in large language models
Bijean Ghafouri, Shahrad Mohammadzadeh, James Zhou, Pratheeksha Nair, Jacob-Junqi Tian, Mayank Goel, Reihaneh Rabbany, Jean-François Godbout, and Kellin Pelrine. Epistemic integrity in large language models. InNeurips Safe Generative AI Workshop 2024, 2024. URL https://openreview.net/forum?id=o3wQbxRaKo
2024
-
[29]
Gemini 2.5 flash-lite model card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Flash-Lite-Model-Card.pdf, 2025
Google DeepMind. Gemini 2.5 flash-lite model card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Flash-Lite-Model-Card.pdf, 2025
2025
-
[30]
Gemini 3 flash model card
Google DeepMind. Gemini 3 flash model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf, 2025
2025
-
[31]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf, 2026. 11
2026
-
[32]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravanku- mar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Yashvir S. Grewal, Edwin V . Bonilla, and Thang D. Bui. Improving uncertainty quantification in large language models via semantic embeddings, 2024. URL https://arxiv.org/abs/ 2410.22685
-
[34]
Maxime Griot, Coralie Hemptinne, Jean Vanderdonckt, and Demet Yuksel. Large language models lack essential metacognition for reliable medical reasoning.Nature Communications, 16, 01 2025. doi: 10.1038/s41467-024-55628-6
-
[35]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR, 2017
2017
-
[36]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/ v70/guo17a.html
2017
-
[37]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Decom- posing uncertainty for large language models through input clarification ensembling, 2024
Bairu Hou, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang, and Yang Zhang. Decom- posing uncertainty for large language models through input clarification ensembling, 2024. URLhttps://arxiv.org/abs/2311.08718
-
[41]
A survey of uncertainty estimation in llms: Theory meets practice, 2024
Hsiu-Yuan Huang, Yutong Yang, Zhaoxi Zhang, Sanwoo Lee, and Yunfang Wu. A survey of uncertainty estimation in llms: Theory meets practice, 2024. URL https://arxiv.org/ abs/2410.15326
-
[42]
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. Look before you leap: An exploratory study of uncertainty analysis for large language models.IEEE Transactions on Software Engineering, 51(2):413–429, February 2025. ISSN 2326-3881. doi: 10.1109/tse.2024.3519464. URL http://dx.doi.org/10.1109/ TSE.2024.3519464
-
[43]
Calibrating long-form generations from large language models
Yukun Huang, Yixin Liu, Raghuveer Thirukovalluru, Arman Cohan, and Bhuwan Dhingra. Calibrating long-form generations from large language models. In Yaser Al-Onaizan, Mo- hit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13441–13460, Miami, Florida, USA, November 2024. As- sociation for Comp...
-
[44]
Can LLMs Estimate Cognitive Complexity of Reading Comprehension Items?
Seonjeong Hwang, Hyounghun Kim, and Gary Geunbae Lee. Can llms estimate cognitive complexity of reading comprehension items?arXiv preprint arXiv:2510.25064, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, Pascale Fung, and Nicola Cancedda. Calibrating verbal uncertainty as a linear feature to reduce hallucinations.arXiv preprint arXiv:2503.14477, 2025
-
[46]
Calibrating language models via augmented prompt ensembles
Mingjian Jiang, Yangjun Ruan, Sicong Huang, Saifei Liao, Silviu Pitis, Roger Baker Grosse, and Jimmy Ba. Calibrating language models via augmented prompt ensembles. 2023. URL https://api.semanticscholar.org/CorpusID:271797871
2023
-
[47]
Conformal linguistic calibration: Trading-off between factuality and specificity, 2025
Zhengping Jiang, Anqi Liu, and Benjamin Van Durme. Conformal linguistic calibration: Trading-off between factuality and specificity, 2025. URL https://arxiv.org/abs/2502. 19110
2025
-
[48]
Matt Gardner Johannes Welbl, Nelson F. Liu. Crowdsourcing multiple choice science questions. 2017
2017
-
[49]
Johnson, Rachel S Goodman, J
Douglas B. Johnson, Rachel S Goodman, J. Randall Patrinely, Cosby A Stone, Eli Zimmerman, Rebecca Rigel Donald, Sam S Chang, Sean T Berkowitz, Avni P Finn, Eiman Jahangir, Elizabeth A Scoville, Tyler Reese, Debra E. Friedman, Julie A. Bastarache, Yuri F van der Heijden, Jordan Wright, Nicholas Carter, Matthew R Alexander, Jennifer H Choe, Cody A Chastain,...
2023
-
[50]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Cobb, Anirban Roy, Brian Matejek, Manoj Acharya, Daniel Elenius, Alexander Michael Berenbeim, John A
Ramneet Kaur, Colin Samplawski, Adam D. Cobb, Anirban Roy, Brian Matejek, Manoj Acharya, Daniel Elenius, Alexander Michael Berenbeim, John A. Pavlik, Nathaniel D. Bastian, and Susmit Jha. Addressing uncertainty in LLMs to enhance reliability in generative AI. InNeurips Safe Generative AI Workshop 2024, 2024. URL https://openreview.net/ forum?id=Z3DS4Pcxct
2024
-
[52]
Sunnie S. Y . Kim, Q. Vera Liao, Mihaela V orvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. "i’m not sure, but...": Examining the impact of large language models’ uncertainty expression on user reliance and trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’24, page 822–835, New York, NY , USA,...
-
[53]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=VD-AYtP0dve
2023
-
[54]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transac...
2019
-
[55]
Reinforcement Learning from Human Feedback
Nathan Lambert. Reinforcement learning from human feedback.arXiv preprint arXiv:2504.12501, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Hedges in japanese conversation: The influence of age, sex, and formality
Shizuka Lauwereyns. Hedges in japanese conversation: The influence of age, sex, and formality. Language Variation and Change, 14(2):239–259, 2002. doi: 10.1017/S0954394502142049
-
[57]
Taming overconfidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724, 2024
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. Taming overconfidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724, 2024
-
[58]
LegalAgentBench: Evaluating LLM agents in legal domain
Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, Wuyue Wang, Yiqun Liu, and Minlie Huang. LegalAgentBench: Evaluating LLM agents in legal domain. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association ...
-
[59]
Halueval: A large-scale hallucination evaluation benchmark for large language models, 2023
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Halueval: A large-scale hallucination evaluation benchmark for large language models, 2023. URL https://arxiv.org/abs/2305.11747
-
[60]
Confidence is all you need: Few-shot RL fine-tuning of language models, 2026
Pengyi Li, Matvey Skripkin, Alexander Zubrey, Andrey Kuznetsov, and Ivan Oseledets. Confidence is all you need: Few-shot RL fine-tuning of language models, 2026. URL https://openreview.net/forum?id=G8xyzI2eQb
2026
-
[61]
Semantic volume: Quantifying and detecting both external and internal uncertainty in LLMs
Xiaomin Li, Zhou Yu, Ziji Zhang, Yingying Zhuang, Swair Shah, Narayanan Sadagopan, and Anurag Beniwal. Semantic volume: Quantifying and detecting both external and internal uncertainty in LLMs. InNeurIPS 2025 Workshop on Structured Probabilistic Inference & Generative Modeling, 2025. URLhttps://openreview.net/forum?id=4ZfkoukhQ4
2025
-
[62]
Conftuner: Training large language models to express their confidence verbally
Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verbally. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum? id=VZQ04Ojhu5. 15
2025
-
[63]
Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=8s8K2UZGTZ
2022
-
[64]
Can LLMs Use Linguistic Uncertainty Markers to Reliably Reflect Intrinsic Confidence?
Gabrielle Kaili-May Liu and Arman Cohan. Can llms use linguistic uncertainty markers to reliably reflect intrinsic confidence?arXiv preprint arXiv:2605.28778, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Gabrielle Kaili-May Liu, Gal Yona, Avi Caciularu, Idan Szpektor, Tim G. J. Rudner, and Arman Cohan. MetaFaith: Faithful natural language uncertainty expression in LLMs. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages ...
-
[66]
Haotian Liu, Shuo Wang, and Hongteng Xu. C2gspg: Confidence-calibrated group sequence policy gradient towards self-aware reasoning.arXiv preprint arXiv:2509.23129, 2025
-
[67]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories.arXiv preprint, 2022
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Hannaneh Hajishirzi, and Daniel Khashabi. When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories.arXiv preprint, 2022
2022
-
[69]
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, December 2023. Association for Computa...
-
[70]
On the probability–quality paradox in language generation
Clara Meister, Gian Wiher, Tiago Pimentel, and Ryan Cotterell. On the probability–quality paradox in language generation. In Smaranda Muresan, Preslav Nakov, and Aline Villav- icencio, editors,Proceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (Volume 2: Short Papers), pages 36–45, Dublin, Ireland, May 2022. Associat...
-
[71]
Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau
Sabrina J. Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau. Reducing conversational agents’ overconfidence through linguistic calibration.Transactions of the Association for Computational Linguistics, 10:857–872, 2022. doi: 10.1162/tacl_a_00494. URL https: //aclanthology.org/2022.tacl-1.50/
-
[72]
Pilar Mur-Dueñas. There may be differences: Analysing the use of hedges in english and spanish research articles.Lingua, 260:103131, 2021. ISSN 0024-3841. doi: https://doi. org/10.1016/j.lingua.2021.103131. URL https://www.sciencedirect.com/science/ article/pii/S0024384121001030
-
[73]
Thu Nguyen Thi Thuy. A corpus-based study on cross-cultural divergence in the use of hedges in academic research articles written by vietnamese and native english-speaking authors.Social Sciences, 7(4), 2018. ISSN 2076-0760. doi: 10.3390/socsci7040070. URL https://www.mdpi.com/2076-0760/7/4/70
-
[74]
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities, 2024. URL https://arxiv.org/abs/2405.20003
-
[75]
Measuring calibration in deep learning
Jeremy Nixon, Michael W Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. Measuring calibration in deep learning. InCVPR workshops, volume 2, 2019. 16
2019
-
[76]
Nick Oh. Before you< think>, monitor: Implementing flavell’s metacognitive framework in llms.arXiv preprint arXiv:2510.16374, 2025
-
[77]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[78]
Reasoning-SQL: Reinforcement learning with SQL tailored partial rewards for reasoning-enhanced text-to-SQL
Mohammadreza Pourreza, Shayan Talaei, Ruoxi Sun, Xingchen Wan, Hailong Li, Azalia Mirhoseini, Amin Saberi, and Sercan O Arik. Reasoning-SQL: Reinforcement learning with SQL tailored partial rewards for reasoning-enhanced text-to-SQL. InSecond Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=HbwkIDWQgN
2025
-
[79]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HPuSIXJaa9
2023
-
[80]
Mauricio Rivera, Jean-François Godbout, Reihaneh Rabbany, and Kellin Pelrine. Com- bining confidence elicitation and sample-based methods for uncertainty quantification in misinformation mitigation. In Raúl Vázquez, Hande Celikkanat, Dennis Ulmer, Jörg Tiedemann, Swabha Swayamdipta, Wilker Aziz, Barbara Plank, Joris Baan, and Marie- Catherine de Marneffe,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.