RCT: A Robot-Collected Touch-Vision-Language Dataset for Tactile Generalization
Pith reviewed 2026-07-01 05:23 UTC · model grok-4.3
The pith
A robot-collected tactile dataset shows that holding out materials at training time drops tactile-to-text Recall@1 to 25 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
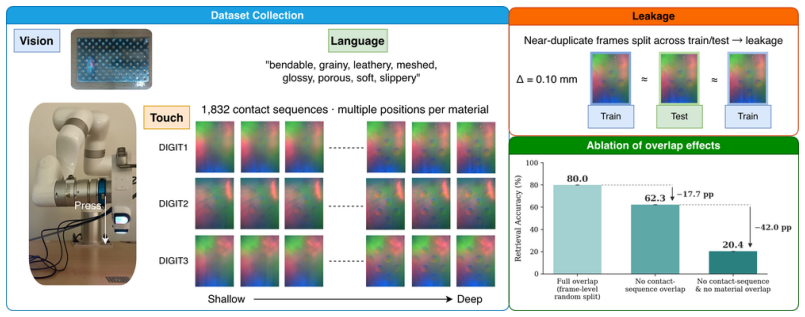
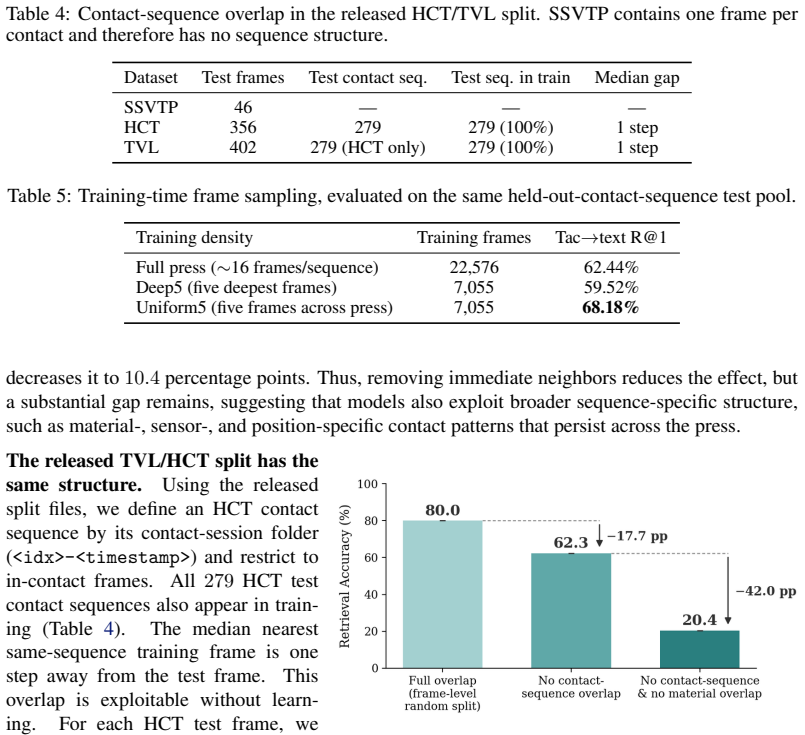
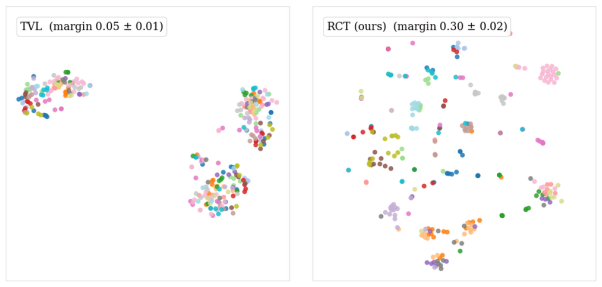
RCT preserves each robot press as a contact sequence across multiple positions and sensors, enabling splits that avoid sequence overlap. With an encoder held fixed, removing sequence overlap reduces Recall@1 by 17.7 points. Adding material hold-outs further reduces held-out-material Recall@1 to 25.1 plus or minus 6.1 percent across three draws. The public TVL/HCT split contains no material hold-outs and allows 98.3 percent sequence recovery by raw-pixel nearest neighbors. Uniform sampling within presses improves contrastive training, and embeddings trained on RCT raise category probe accuracy on unseen materials.
What carries the argument
Contact-sequence-preserving splits with material hold-outs on the RCT dataset of robot presses.
If this is right
- Uniform sampling of frames within each press improves contrastive training on the dataset.
- Embeddings from RCT training raise accuracy on category probes for materials never seen in training.
- The public TVL/HCT split allows 98.3 percent recovery of test sequences by nearest-neighbor lookup on raw pixels.
- Removing contact-sequence overlap from splits lowers Recall@1 by 17.7 points even without material hold-outs.
Where Pith is reading between the lines
- Tactile models may require explicit mechanisms to separate material identity from surface texture or geometry.
- Future robot manipulation benchmarks should adopt material hold-out protocols as a minimum standard.
- The performance gap suggests that active touch strategies or additional modalities could be needed for reliable open-world use.
Load-bearing premise
The 122 chosen materials and the three sensors at the selected contact positions capture enough variety to represent open-world objects and sensing conditions.
What would settle it
Collect a new test set of presses on materials outside the original 122 using a fourth DIGIT sensor or different robot arm and measure whether Recall@1 on those materials stays near 25 percent or rises substantially.
Figures

read the original abstract
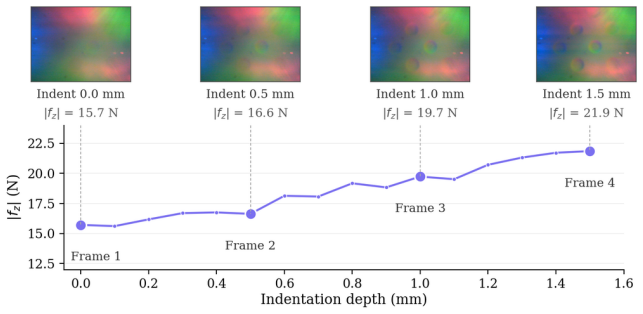
For robots manipulating open-world objects, tactile representations must generalize to unseen materials. We introduce RCT (Robotic Contact Tactile), a robot-collected touch-vision-language dataset with 29,279 tactile frames from full robot presses on 122 industrial reference materials in 7 categories, recorded with three DIGIT sensors at multiple contact positions. RCT preserves each press as a contact sequence, enabling held-out evaluation across materials, categories, sensors, contact positions, and contact sequences. Frames from one press are strongly correlated: frame-random splits can place near-duplicate observations of the same physical interaction in both training and test. With the encoder held fixed, removing contact-sequence overlap reduces tactile-to-text Recall@1 by 17.7 percentage points. When materials are additionally held out at training time, performance drops sharply, leaving held-out-material Recall@1 at 25.1 +/- 6.1% averaged over three held-out draws. The public TVL/HCT split shows the same structure: every test contact sequence appears in training, and raw-pixel nearest neighbors recover the correct sequence in 98.3% of cases. Uniformly sampling a press improves contrastive training, and RCT-trained embeddings improve category probes on unseen materials. RCT makes contact-sequence-aware, held-out-material evaluation reproducible and exposes novel-material generalization as a central challenge for robotic tactile perception. The RCT dataset is open-sourced at https://faerber-lab.github.io/RCT/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the RCT dataset of 29,279 robot-collected tactile frames from full presses on 122 industrial materials in 7 categories, recorded with three DIGIT sensors at multiple positions. It preserves contact sequences to enable held-out splits across materials, categories, sensors, positions, and sequences, shows that frame-random splits inflate performance due to near-duplicates (17.7 pp drop when sequence overlap is removed), and reports that additional material hold-out at training time yields held-out Recall@1 of 25.1 +/- 6.1% averaged over three draws. The work also notes issues with the public TVL/HCT split and shows benefits of uniform press sampling and RCT-trained embeddings for category probes on unseen materials.
Significance. If the quantitative results hold, the dataset supplies a reproducible, contact-sequence-aware benchmark that isolates material generalization as a measurable challenge in robotic tactile perception, with concrete error-barred numbers demonstrating the performance gap between in-distribution and held-out-material settings. The open release and explicit contrast to existing splits add immediate utility for the community.
major comments (1)
- [Abstract and results section] Abstract and results (held-out material evaluation): the central claim that material hold-out produces a 'sharp' drop to 25.1 +/- 6.1% Recall@1 rests on only three material draws. The reported standard deviation already indicates substantial variability across draws; without additional draws, category-balance details across draws, or sensitivity analysis, the robustness of the headline generalization conclusion is limited.
minor comments (2)
- [Abstract] Abstract: provides no details on the encoder architecture, contrastive loss, or exact training procedure used to obtain the reported Recall@1 numbers, which limits immediate verification of the benchmark results.
- [Introduction / Dataset section] Dataset description: the representativeness claim for the 122 materials and seven categories relative to open-world robotic conditions is stated but not quantified (e.g., no comparison to common household or industrial object distributions).
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the RCT dataset and the constructive feedback on the held-out material results. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract and results section] Abstract and results (held-out material evaluation): the central claim that material hold-out produces a 'sharp' drop to 25.1 +/- 6.1% Recall@1 rests on only three material draws. The reported standard deviation already indicates substantial variability across draws; without additional draws, category-balance details across draws, or sensitivity analysis, the robustness of the headline generalization conclusion is limited.
Authors: We agree that three draws constitute a modest sample size and that the reported standard deviation of 6.1% already signals meaningful variability across material selections. The manuscript does not currently provide per-draw category balances or per-draw performance numbers. In the revision we will add both: (i) the exact category composition of each of the three draws and (ii) the individual Recall@1 values for each draw alongside the mean and standard deviation. This will allow readers to judge balance and sensitivity directly. Additional draws are not feasible at this stage because each draw requires a full robot collection campaign (approximately 30 hours of press time per draw on the current hardware). The core empirical observation—that material hold-out produces a large drop relative to the sequence-preserving in-distribution baseline—remains intact even after accounting for the observed variability. revision: partial
Circularity Check
No circularity: purely empirical dataset release with direct held-out measurements
full rationale
The paper introduces RCT, a new tactile dataset, and reports empirical benchmark results on material/category/sensor hold-outs. No equations, ansatzes, fitted parameters renamed as predictions, or derivation chains appear. The central quantitative claim (held-out Recall@1 of 25.1 +/- 6.1%) is a direct experimental measurement averaged over three draws, not a quantity that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any claimed derivation. This matches the default expectation for dataset papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions underlying contrastive multimodal embedding training and Recall@1 metric
Reference graph
Works this paper leans on
-
[1]
Lambeta, P.-W
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra. DIGIT: A novel design for a low- cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020
2020
-
[2]
L. Fu, G. Datta, H. Huang, W. C.-H. Panitch, J. Drake, J. Ortiz, M. Mukadam, M. Lambeta, R. Calandra, and K. Goldberg. A touch, vision, and language dataset for multimodal alignment. InProceedings of the 41st International Conference on Machine Learning (ICML), volume 235 ofProceedings of Machine Learning Research, pages 14080–14101, 2024
2024
-
[3]
N. Cheng, J. Xu, C. Guan, J. Gao, W. Wang, Y . Li, F. Meng, J. Zhou, B. Fang, and W. Han. Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal repre- sentation.Information Fusion, 124:103305, 2025. doi:10.1016/j.inffus.2025.103305
-
[4]
F. Yang, C. Feng, Z. Chen, H. Park, D. Wang, Y . Dou, Z. Zeng, X. Chen, R. Gangopadhyay, A. Owens, and A. Wong. Binding touch to everything: Learning unified multimodal tactile representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[5]
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y . Sun, B. Fang, and D. Hu. Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[6]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017. doi:10.3390/s17122762
-
[7]
Calandra, A
R. Calandra, A. Owens, M. Upadhyaya, W. Yuan, J. Lin, E. H. Adelson, and S. Levine. The feeling of success: Does touch sensing help predict grasp outcomes? InProceedings of the 1st Annual Conference on Robot Learning (CoRL), volume 78 ofProceedings of Machine Learning Research, pages 314–323, 2017
2017
-
[8]
F. Yang, C. Ma, J. Zhang, J. Zhu, W. Yuan, and A. Owens. Touch and go: Learning from human-collected vision and touch. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2022
2022
-
[9]
R. Gao, Z. Si, Y .-Y . Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, and J. Wu. Objectfolder 2.0: A multisensory object dataset for sim2real transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[10]
S. Wang, M. Lambeta, P.-W. Chou, and R. Calandra. TACTO: A fast, flexible, and open-source simulator for high-resolution vision-based tactile sensors.IEEE Robotics and Automation Letters, 7(2):3930–3937, 2022. doi:10.1109/LRA.2022.3146945
-
[11]
J. Kerr, H. Huang, A. Wilcox, R. Hoque, J. Ichnowski, R. Calandra, and K. Goldberg. Self- supervised visuo-tactile pretraining to locate and follow garment features. InRobotics: Science and Systems (RSS), 2023. doi:10.15607/RSS.2023.XIX.018
- [12]
-
[13]
S. Yu, K. Lin, A. Xiao, J. Duan, and H. Soh. Octopi: Object property reasoning with large tactile-language models. InRobotics: Science and Systems (RSS), 2024
2024
-
[14]
Higuera, A
C. Higuera, A. Sharma, C. K. Bodduluri, T. Fan, P. Lancaster, M. Kalakrishnan, M. Kaess, B. Boots, M. Lambeta, T. Wu, and M. Mukadam. Sparsh: Self-supervised touch representa- tions for vision-based tactile sensing. InProceedings of the 8th Conference on Robot Learning (CoRL), 2024. 9
2024
-
[15]
W. Yuan, S. Wang, S. Dong, and E. H. Adelson. Connecting look and feel: Associating the visual and tactile properties of physical materials. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[16]
W. Yuan, Y . Mo, S. Wang, and E. H. Adelson. Active clothing material perception using tactile sensing and deep learning. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2018
2018
- [17]
-
[18]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
2021
-
[19]
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. V . Le, Y .-H. Sung, Z. Li, and T. Duerig. Scaling up visual and vision-language representation learning with noisy text su- pervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021
2021
-
[20]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[21]
Girdhar, A
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra. Image- bind: One embedding space to bind them all. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[22]
B. Barz and J. Denzler. Do we train on test data? purging CIFAR of near-duplicates.Journal of Imaging, 6(6):41, 2020. doi:10.3390/jimaging6060041
-
[23]
S. Kapoor and A. Narayanan. Leakage and the reproducibility crisis in machine-learning-based science.Patterns, 4(9):100804, 2023. doi:10.1016/j.patter.2023.100804
-
[24]
P. W. Koh, S. Sagawa, H. Marklund, S. M. Xie, M. Zhang, A. Balsubramani, W. Hu, M. Ya- sunaga, R. L. Phillips, I. Gao, T. Lee, E. David, I. Stavness, W. Guo, B. A. Earnshaw, I. S. Haque, S. Beery, J. Leskovec, A. Kundaje, E. Pierson, S. Levine, C. Finn, and P. Liang. WILDS: A benchmark of in-the-wild distribution shifts. InProceedings of the 38th Inter- n...
2021
-
[25]
Jing and K
X. Jing and K. Qian. Reducing cross-sensor domain gaps in tactile sensing via few-sample- driven style-to-content unsupervised domain adaptation.Sensors, 25(1):256, 2025. doi:10. 3390/s25010256
2025
-
[26]
Gemma Team. Gemma 3 technical report, 2025. arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Chuang, J
C.-Y . Chuang, J. Robinson, Y .-C. Lin, A. Torralba, and S. Jegelka. Debiased contrastive learn- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[28]
H. Liu, C. Li, Y . Li, and Y . J. Lee. Improved baselines with visual instruction tuning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[29]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-vl: En- hancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 10 A Additional Dataset and Annotation Details Figure 4: RCT collect...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.