Recognition: no theorem link
ExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Pith reviewed 2026-05-15 09:32 UTC · model grok-4.3
The pith
ExpertGen steers frozen diffusion policies from imperfect demonstrations to high task success by optimizing only their initial noise in simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ExpertGen initializes a diffusion policy on imperfect demonstrations and uses RL to optimize its initial noise input while keeping the policy weights frozen, thereby steering the generated behaviors toward high task success rates within safe manifolds. On industrial assembly tasks this yields 90.5% success and on long-horizon manipulation 85% success, outperforming baselines, with the resulting state-based policies distilled via DAgger into visuomotor policies that deploy successfully on real hardware.
What carries the argument
Reinforcement learning optimization of only the initial noise vector supplied to a frozen diffusion policy, which regularizes exploration to human-like behavior manifolds while using sparse rewards.
If this is right
- The method produces dexterous policies that remain robust across varied initial configurations and recovery from failures.
- State-based experts learned in simulation transfer to real robots after distillation into visuomotor policies.
- Effective learning occurs with only sparse rewards because the frozen prior limits unsafe exploration.
- Imperfect sources such as LLM-generated demonstrations become sufficient starting points for high-performing policies.
Where Pith is reading between the lines
- If noise optimization alone keeps behaviors inside safe manifolds, the same idea could apply to other generative models used for policy generation.
- Strong performance on long-horizon tasks suggests the approach could support composition of sequential robotic skills without additional dense supervision.
- Avoiding weight updates during the RL phase may lower compute needs compared with full policy fine-tuning, allowing quicker simulation iterations.
- Successful sim-to-real transfer via simple distillation implies that behavior regularization can substitute for extensive domain randomization in many cases.
Load-bearing premise
That optimizing only the initial noise of a frozen diffusion policy will reliably steer behavior toward high task success while remaining inside safe, human-like manifolds without reward engineering or policy updates.
What would settle it
An experiment showing that noise-optimized policies achieve lower success rates than strong baselines on the same assembly and long-horizon tasks or fail to transfer after DAgger distillation to real hardware.
Figures











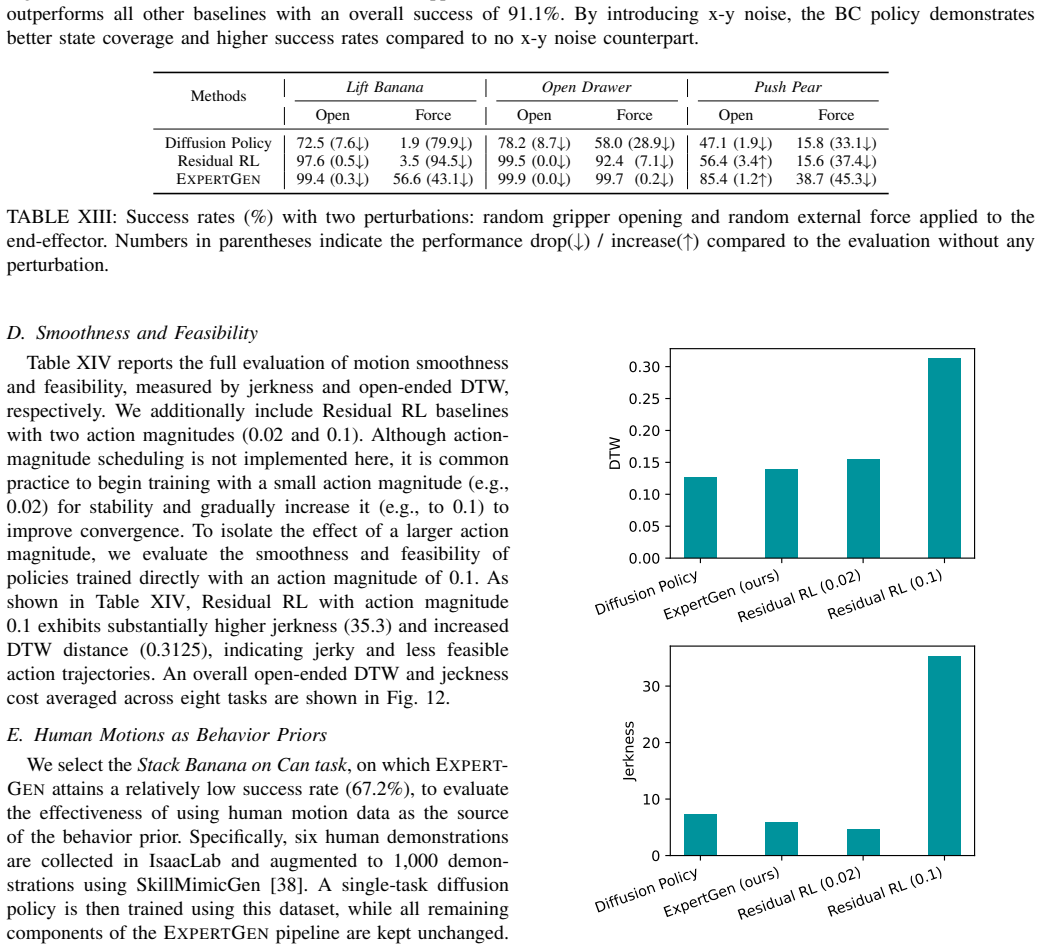








read the original abstract
Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExpertGen, a framework that trains a diffusion policy on imperfect demonstrations (synthesized by LLMs or from humans) as a behavior prior, then applies RL to optimize only the initial noise input while keeping the diffusion policy frozen. This steers the policy toward high task success using sparse rewards without reward engineering. It reports 90.5% overall success on industrial assembly tasks and 85% on long-horizon manipulation tasks, outperforming baselines, with policies that are dexterous and robust; the state-based experts are then distilled via DAgger into visuomotor policies for real-robot deployment.
Significance. If the coverage assumption holds and the empirical gains are reproducible, ExpertGen could meaningfully advance scalable expert policy acquisition in robotics by reducing reliance on high-quality teleoperated data and manual reward design, while using frozen diffusion priors for safe, manifold-constrained exploration. The sim-to-real distillation step adds practical value for hardware transfer.
major comments (2)
- [Abstract] Abstract: The central empirical claims (90.5% assembly success, 85% long-horizon success, outperformance of all baselines) are presented without any mention of evaluation protocol, number of trials, random seeds, error bars, or statistical significance tests. This information is load-bearing for assessing whether the reported rates substantiate the method's advantage over baselines.
- [Method description] Method description (as summarized): The claim that optimizing only the initial noise of a frozen diffusion prior reliably recovers high-success behaviors rests on the untested assumption that the prior manifold (trained on imperfect demos) already contains near-optimal trajectories. No ablation isolating noise optimization, measuring manifold coverage, or comparing against unfrozen policy updates is described, leaving open the possibility that successes arise from implicit policy capacity rather than the proposed mechanism.
minor comments (2)
- [Abstract] Abstract: Specify the exact baselines (e.g., names, implementations) and how imperfect demonstrations are generated (e.g., LLM prompt details or human demo quality metrics) to allow readers to contextualize the outperformance.
- [Abstract] The phrase 'no reward engineering' is used while claiming sparse rewards; clarify whether any task-specific reward shaping or success detection is still required for the RL stage.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (90.5% assembly success, 85% long-horizon success, outperformance of all baselines) are presented without any mention of evaluation protocol, number of trials, random seeds, error bars, or statistical significance tests. This information is load-bearing for assessing whether the reported rates substantiate the method's advantage over baselines.
Authors: We agree that the abstract would benefit from a concise reference to the evaluation protocol. In the revised version we will add a short clause noting that the reported success rates are averaged over 100 trials per task across five random seeds, with standard deviations and statistical comparisons provided in the experimental section. This change will be limited to one sentence to preserve abstract length while addressing the concern. revision: yes
-
Referee: [Method description] Method description (as summarized): The claim that optimizing only the initial noise of a frozen diffusion prior reliably recovers high-success behaviors rests on the untested assumption that the prior manifold (trained on imperfect demos) already contains near-optimal trajectories. No ablation isolating noise optimization, measuring manifold coverage, or comparing against unfrozen policy updates is described, leaving open the possibility that successes arise from implicit policy capacity rather than the proposed mechanism.
Authors: The current manuscript does not contain an explicit ablation that isolates noise optimization from full policy updates or directly measures manifold coverage. The existing baseline comparisons provide indirect support for the value of the frozen prior, but we acknowledge that a more targeted analysis would strengthen the mechanistic claim. We will therefore add a new ablation subsection that (i) compares frozen noise optimization against unfrozen fine-tuning of the diffusion policy and (ii) reports a simple coverage metric on the imperfect demonstration set. A brief discussion of the coverage assumption will also be inserted in the method section. revision: yes
Circularity Check
No circularity: method relies on standard diffusion pretraining plus RL noise optimization with independent empirical validation
full rationale
The paper presents a two-stage pipeline (diffusion policy pretrained on imperfect demonstrations, followed by RL optimization of initial noise only while keeping the policy frozen) whose success rates are measured empirically on assembly and manipulation benchmarks. No equations, derivations, or self-citations reduce the reported 90.5% or 85% success rates to quantities defined by construction from the fitted parameters or prior data. The central claim rests on the coverage assumption of the behavior manifold, which is an empirical hypothesis rather than a definitional loop. Standard RL and diffusion components are used without self-referential fitting or uniqueness theorems imported from the authors' prior work. This is a normal non-circular empirical method paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL optimization hyperparameters
axioms (1)
- domain assumption A diffusion policy trained on imperfect demonstrations can serve as a safe behavior prior that RL can refine without policy updates.
Forward citations
Cited by 1 Pith paper
-
You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Optimizing a single constant initial noise vector for frozen generative robot policies improves success rates on 38 of 43 tasks by up to 58% relative improvement.
Reference graph
Works this paper leans on
-
[1]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[2]
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating ai for math with mas- sive open-source instruction data.arXiv preprint arXiv:2410.01560, 2024
-
[3]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278– 25294, 2022
work page 2022
-
[4]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 techni- cal report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Bap- tiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Jinghuan Shang, Karl Schmeckpeper, Brandon B May, Maria Vittoria Minniti, Tarik Kelestemur, David Watkins, and Laura Herlant. Theia: Distilling diverse vision foundation models for robot learning.arXiv preprint arXiv:2407.20179, 2024
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[11]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InInternational conference on ma- chine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[13]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, An- toine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learn- ing.Advances in neural information processing systems, 35:23716–23736, 2022
work page 2022
-
[14]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision- language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
MolmoAct: Action Reasoning Models that can Reason in Space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, et al. Molmoact: Action reason- ing models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipula- tion with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11142–11152, 2025
work page 2025
-
[20]
Ran Gong*, Xiaohan Zhang*, Jinghuan Shang*, Maria Vittoria Minniti*, Jigarkumar Patel, Valerio Pepe, Riedana Yan, Ahmet Gundogdu, Ivan Kapelyukh, Ali Abbas, Xiaoqiang Yan, Harsh Patel, Laura Herlant, and Karl Schmeckpeper. Anytask: an automated task and data generation framework for advancing sim-to-real policy learning.arXiv preprint arXiv:2512.17853, 2025
-
[21]
Wenli Xiao, Haotian Lin, Andy Peng, Haoru Xue, Tairan He, Yuqi Xie, Fengyuan Hu, Jimmy Wu, Zhengyi Luo, Linxi Fan, et al. Self-improving vision-language-action models with data generation via residual rl.arXiv preprint arXiv:2511.00091, 2025
-
[22]
Learning to walk in minutes using massively parallel deep reinforcement learning
Nikita Rudin, David Hoeller, Philipp Reist, and Marco Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learning, pages 91–100. PMLR, 2022
work page 2022
-
[23]
Tairan He, Zi Wang, Haoru Xue, Qingwei Ben, Zhengyi Luo, Wenli Xiao, Ye Yuan, Xingye Da, Fernando Casta˜neda, Shankar Sastry, et al. Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv:2511.15200, 2025
-
[24]
Opening the sim- to-real door for humanoid pixel-to-action policy transfer
Haoru Xue, Tairan He, Zi Wang, Qingwei Ben, Wenli Xiao, Zhengyi Luo, Xingye Da, Fernando Casta ˜neda, Guanya Shi, Shankar Sastry, et al. Opening the sim- to-real door for humanoid pixel-to-action policy transfer. arXiv preprint arXiv:2512.01061, 2025
-
[25]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr ¨ugg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Hei- den, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Ani- mesh Garg, Renato Gasoto, Lionel Gulich, Yijie...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Steering your diffusion policy with latent space reinforcement learning
Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Naga- bandi, Abhishek Gupta, and Sergey Levine. Steering your diffusion policy with latent space reinforcement learning. arXiv preprint arXiv:2506.15799, 2025
-
[27]
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control.arXiv preprint arXiv:2505.22642, 2025
-
[28]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelli- gence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[29]
Tom Silver, Kelsey Allen, Josh Tenenbaum, and Leslie Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
From imitation to refinement- residual rl for precise assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement- residual rl for precise assembly. In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 01–08. IEEE, 2025
work page 2025
-
[31]
Siheng Zhao, Yanjie Ze, Yue Wang, C Karen Liu, Pieter Abbeel, Guanya Shi, and Rocky Duan. Resmimic: From general motion tracking to humanoid whole-body loco-manipulation via residual learning.arXiv preprint arXiv:2510.05070, 2025
-
[32]
Xiu Yuan, Tongzhou Mu, Stone Tao, Yunhao Fang, Mengke Zhang, and Hao Su. Policy decorator: Model- agnostic online refinement for large policy model.arXiv preprint arXiv:2412.13630, 2024
-
[33]
Lakshita Dodeja, Karl Schmeckpeper, Shivam Vats, Thomas Weng, Mingxi Jia, George Konidaris, and Stefanie Tellex. Accelerating residual reinforcement learning with uncertainty estimation.arXiv preprint arXiv:2506.17564, 2025
-
[34]
Efficient online reinforcement learning fine-tuning need not retain offline data,
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online reinforcement learn- ing fine-tuning need not retain offline data.arXiv preprint arXiv:2412.07762, 2024
-
[35]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[36]
Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Ben- jamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
-
[37]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Ire- tiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596, 2023
-
[38]
Caelan Garrett, Ajay Mandlekar, Bowen Wen, and Dieter Fox. Skillmimicgen: Automated demonstration genera- tion for efficient skill learning and deployment.arXiv preprint arXiv:2410.18907, 2024
-
[39]
Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning
Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi Jim Fan, and Yuke Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning. In2025 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 16923–16930. IEEE, 2025
work page 2025
-
[40]
Zhengrong Xue, Shuying Deng, Zhenyang Chen, Yixuan Wang, Zhecheng Yuan, and Huazhe Xu. Demogen: Syn- thetic demonstration generation for data-efficient visuo- motor policy learning.arXiv preprint arXiv:2502.16932, 2025
-
[41]
Zihan Zhou, Animesh Garg, Ajay Mandlekar, and Caelan Garrett. Reinforcegen: Hybrid skill policies with auto- mated data generation and reinforcement learning.arXiv preprint arXiv:2512.16861, 2025
-
[42]
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xan- der Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, and Tse kai Chan et al. Maniskill3: Gpu parallelized robotics simulation and rendering for gen- eralizable embodied ai.Robotics: Science and Systems, 2025
work page 2025
-
[43]
Maniskill2: A uni- fied benchmark for generalizable manipulation skills
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, and Hao Su. Maniskill2: A uni- fied benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023
work page 2023
-
[44]
Robotwin: Dual-arm robot benchmark with generative digital twins
Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, et al. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025
work page 2025
-
[45]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Qiwei Liang, Zixuan Li, Xianliang Lin, Yi- heng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain random- ization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy.arXiv preprint arXiv:2511.16651, 2025
-
[47]
Gen- sim2: Scaling robot data generation with multi-modal and reasoning llms
Pu Hua, Minghuan Liu, Annabella Macaluso, Yunfeng Lin, Weinan Zhang, Huazhe Xu, and Lirui Wang. Gen- sim2: Scaling robot data generation with multi-modal and reasoning llms. In8th Annual Conference on Robot Learning, 2024
work page 2024
-
[48]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[50]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
work page 2018
-
[51]
Address- ing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Address- ing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
work page 2018
-
[52]
A distributional perspective on reinforcement learning
Marc G Bellemare, Will Dabney, and R ´emi Munos. A distributional perspective on reinforcement learning. InInternational conference on machine learning, pages 449–458. PMLR, 2017
work page 2017
-
[53]
Code as Policies: Language Model Programs for Embodied Control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embod- ied control.arXiv preprint arXiv:2209.07753, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[54]
Bingjie Tang, Iretiayo Akinola, Jie Xu, Bowen Wen, Ankur Handa, Karl Van Wyk, Dieter Fox, Gaurav S Sukhatme, Fabio Ramos, and Yashraj Narang. Automate: Specialist and generalist assembly policies over diverse geometries.arXiv preprint arXiv:2407.08028, 1(2), 2024
-
[55]
SMP: Reusable Score-Matching Motion Priors for Physics-Based Character Control
Yuxuan Mu, Ziyu Zhang, Yi Shi, Minami Matsumoto, Kotaro Imamura, Guy Tevet, Chuan Guo, Michael Tay- lor, Chang Shu, Pengcheng Xi, et al. Smp: Reusable score-matching motion priors for physics-based character control.arXiv preprint arXiv:2512.03028, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Binomial proportion confidence interval — Wikipedia, the free encyclopedia
Wikipedia contributors. Binomial proportion confidence interval — Wikipedia, the free encyclopedia. https://en.wikipedia.org/w/index.php?title=Binomial proportion confidence interval&oldid=1333177192,
-
[57]
[Online; accessed 31-January-2026]
work page 2026
-
[58]
Paolo Tormene, Toni Giorgino, Silvana Quaglini, and Mario Stefanelli. Matching incomplete time series with dynamic time warping: an algorithm and an application to post-stroke rehabilitation.Artificial intelligence in medicine, 45(1):11–34, 2009
work page 2009
-
[59]
Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands, 2025
Ritvik Singh, Arthur Allshire, Ankur Handa, Nathan Ratliff, and Karl Van Wyk. Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands, 2025
work page 2025
-
[60]
""Lift plug from socket till disassembly and then randomize end-effector pose
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015. APPENDIXA HYPER-PARAMETERS A. Diffusion Policy This paper considers diffusion policy for all imitation learn- ing train...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.