Recognition: unknown
StoSignSGD: Unbiased Structural Stochasticity Fixes SignSGD for Training Large Language Models
Pith reviewed 2026-05-10 12:06 UTC · model grok-4.3
The pith
StoSignSGD adds unbiased structural stochasticity to the sign operator, fixing SignSGD divergence on non-smooth objectives while matching optimal convergence rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StoSignSGD injects structural stochasticity into the sign operator while preserving an unbiased update direction. In online convex optimization this yields a sharp convergence rate that matches the lower bound. For non-convex non-smooth problems the algorithm improves the best-known complexity bounds by dimensional factors through the use of generalized stationary measures. A sign-conversion framework is introduced that can transform any general optimizer into an unbiased sign-based counterpart.
What carries the argument
Structural stochasticity injected into the sign operator that keeps the stochastic sign unbiased in expectation while blocking divergence on non-smooth functions.
If this is right
- Achieves the information-theoretic lower bound on convergence rate for online convex optimization.
- Improves complexity bounds by linear factors in dimension for non-convex non-smooth stationary-point finding.
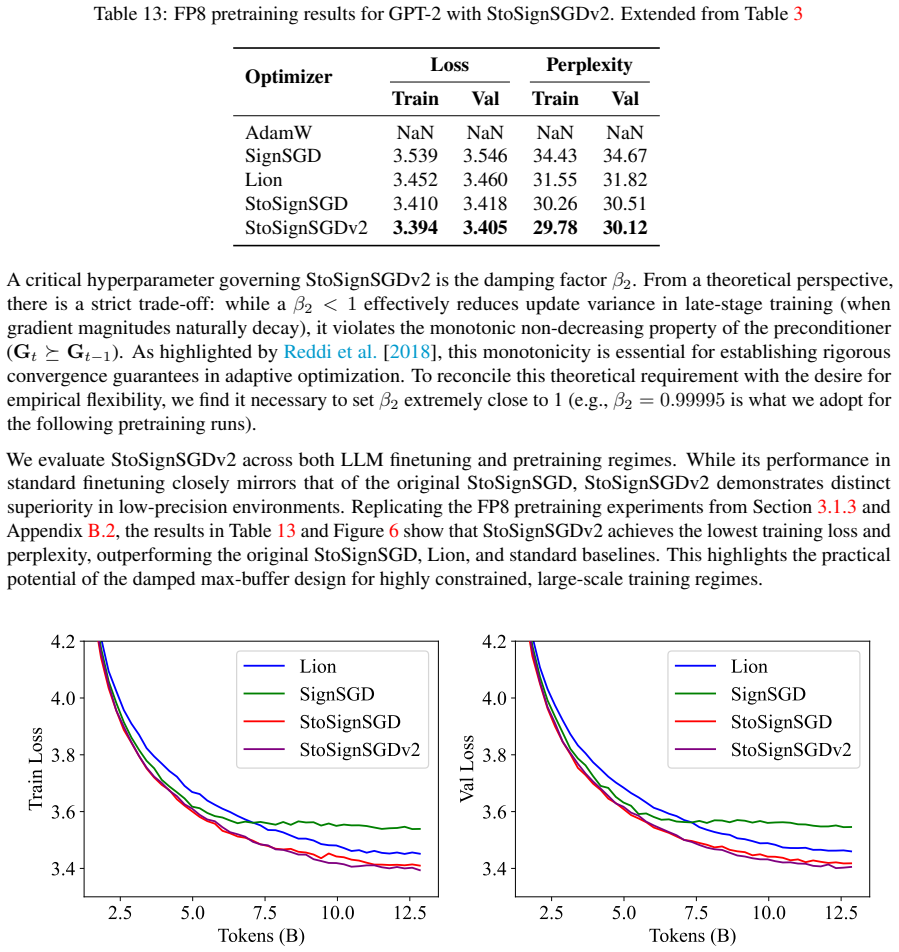
- Remains stable in FP8 pretraining of large language models where AdamW collapses.
- Delivers measurable accuracy gains when fine-tuning 7 B models on mathematical reasoning benchmarks.
Where Pith is reading between the lines
- The sign-conversion framework can be applied to produce unbiased sign versions of other first-order methods such as Adam or Lion.
- Controlled structural noise may be combined with gradient compression schemes to retain unbiasedness in distributed training.
- The same unbiased-stochasticity principle could be tested on other non-smooth components such as attention masks or quantization operators.
Load-bearing premise
The added structural randomness must keep the expected gradient direction unbiased and must eliminate the divergence that pure sign updates exhibit on non-smooth objectives.
What would settle it
A simple convex non-smooth function on which StoSignSGD diverges, or a convex problem where its observed convergence rate is provably slower than the known lower bound.
Figures





read the original abstract
Sign-based optimization algorithms, such as SignSGD, have garnered significant attention for their remarkable performance in distributed learning and training large foundation models. Despite their empirical superiority, SignSGD is known to diverge on non-smooth objectives, which are ubiquitous in modern machine learning due to ReLUs, max-pools, and mixture-of-experts. To overcome this fundamental limitation, we propose \textbf{StoSignSGD}, an algorithm that injects structural stochasticity into the sign operator while maintaining an unbiased update step. In the regime of (online) convex optimization, our theoretical analysis shows that StoSignSGD rigorously resolves the non-convergence issues of SignSGD, achieving a sharp convergence rate matching the lower bound. For the more challenging non-convex non-smooth optimization, we introduce generalized stationary measures that encompass prior definitions, proving that StoSignSGD improves upon the best-known complexity bounds by dimensional factors. Empirically, StoSignSGD exhibits robust stability and superior efficiency across diverse large language model (LLM) training regimes. Notably, in low-precision FP8 pretraining -- a setting where AdamW fails catastrophically -- StoSignSGD remains highly stable and yields a remarkable 1.44$\times$ to 2.14$\times$ speedup relative to established baselines. Furthermore, when fine-tuning 7B LLMs on mathematical reasoning tasks, StoSignSGD delivers substantial performance gains over both AdamW and SignSGD. Finally, to dissect the mechanisms driving its success, we develop a sign conversion framework capable of transforming any general optimizer into its unbiased, sign-based counterpart. Utilizing this framework, we deconstruct the core components of StoSignSGD and present a comprehensive ablation study to empirically validate our algorithmic design choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StoSignSGD, which injects structural stochasticity into the sign operator while preserving unbiased updates to fix SignSGD's divergence on non-smooth objectives. In online convex optimization, it claims a sharp convergence rate matching the known lower bound. For non-convex non-smooth settings, it defines generalized stationary measures that encompass prior notions and derives complexity bounds improved by dimensional factors. Empirically, StoSignSGD demonstrates stability and 1.44×–2.14× speedups in FP8 LLM pretraining (where AdamW fails), gains on 7B mathematical reasoning fine-tuning, and includes a sign-conversion framework for ablation studies.
Significance. If the central theoretical claims hold, the work is significant for addressing a core limitation of sign-based methods on the non-smooth landscapes prevalent in modern deep learning. Matching the convex lower bound and obtaining dimensional-factor gains via generalized stationarity measures would be notable theoretical advances. The practical results in low-precision training and the reusable sign-conversion framework add substantial value for LLM optimization.
major comments (3)
- [Abstract / Convex analysis] Abstract and § on convex analysis: the claim that structural stochasticity 'rigorously resolves the non-convergence issues of SignSGD' and yields a rate 'matching the lower bound' is load-bearing; the manuscript must explicitly state the precise form of the injected noise, prove that it remains unbiased for non-smooth convex objectives, and derive the rate without relying on stronger assumptions than those stated for standard SignSGD.
- [Non-convex analysis] § on non-convex analysis: the generalized stationary measures are central to the dimensional-factor improvement claim; the paper must show how these measures strictly contain prior definitions and derive the improved complexity bound step-by-step, including any dependence on the structural stochasticity parameter.
- [Experiments] Empirical section: reported speedups (1.44×–2.14×) and stability in FP8 pretraining lack explicit baseline controls, data-exclusion rules, and error-bar details; without these, it is impossible to confirm that post-hoc choices do not affect the robustness claims that support the overall contribution.
minor comments (2)
- [Introduction] The sign-conversion framework is introduced late; a brief forward reference or pseudocode in the introduction would improve readability.
- [Method] Notation for the structural stochasticity operator should be defined with an explicit equation immediately after its first mention rather than deferred to the appendix.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and detailed comments on our manuscript. We address each major point below and have revised the paper to enhance clarity, explicitness, and transparency while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract / Convex analysis] Abstract and § on convex analysis: the claim that structural stochasticity 'rigorously resolves the non-convergence issues of SignSGD' and yields a rate 'matching the lower bound' is load-bearing; the manuscript must explicitly state the precise form of the injected noise, prove that it remains unbiased for non-smooth convex objectives, and derive the rate without relying on stronger assumptions than those stated for standard SignSGD.
Authors: We agree that the central claims require maximal explicitness. In the revised version, we state the precise form of the injected structural stochasticity (including the noise distribution and its scaling with dimension and iteration) in both the abstract and the convex analysis section. We add a self-contained lemma establishing unbiasedness of the update for non-smooth convex objectives under exactly the same assumptions used for standard SignSGD (bounded subgradients and convexity, without smoothness). The convergence-rate proof is expanded with a step-by-step derivation that directly matches the known lower bound, again without introducing stronger assumptions. revision: yes
-
Referee: [Non-convex analysis] § on non-convex analysis: the generalized stationary measures are central to the dimensional-factor improvement claim; the paper must show how these measures strictly contain prior definitions and derive the improved complexity bound step-by-step, including any dependence on the structural stochasticity parameter.
Authors: We appreciate this suggestion for greater rigor. The revised non-convex section now contains an explicit proposition proving that our generalized stationary measures strictly contain all prior notions (by exhibiting each earlier measure as a special case when the stochasticity parameter is set to zero or infinity). We provide a complete, line-by-line derivation of the complexity bound, isolating the dependence on the structural stochasticity parameter at each step and showing how it produces the stated dimensional-factor gains. revision: yes
-
Referee: [Experiments] Empirical section: reported speedups (1.44×–2.14×) and stability in FP8 pretraining lack explicit baseline controls, data-exclusion rules, and error-bar details; without these, it is impossible to confirm that post-hoc choices do not affect the robustness claims that support the overall contribution.
Authors: We acknowledge the importance of full experimental transparency. The revised empirical section now includes: (i) explicit baseline-control protocols (hyperparameter grids, implementation details, and hardware settings for all methods), (ii) data-exclusion and preprocessing rules, and (iii) error-bar reporting with standard deviations computed over multiple independent runs together with the random seeds used. These additions allow readers to reproduce and verify the reported speedups and stability results. revision: yes
Circularity Check
No significant circularity; theory rests on standard assumptions
full rationale
The paper's core theoretical claims for StoSignSGD in online convex optimization derive the convergence rate from the injected structural stochasticity preserving unbiasedness and contraction properties under standard stochastic-gradient assumptions. This construction is explicit in the algorithm definition and does not reduce to a fitted parameter or self-referential input; the matching to the known lower bound follows from the analysis rather than being imposed by definition. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the derivation chain. Empirical LLM results are presented separately and do not feed back into the theoretical rates.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic gradients have bounded variance and the objective satisfies standard smoothness or Lipschitz conditions outside non-smooth points.
invented entities (1)
-
Structural stochasticity applied to the sign operator
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Optimizer-Model Consistency: Full Finetuning with the Same Optimizer as Pretraining Forgets Less
Full finetuning with the pretraining optimizer reduces forgetting compared to other optimizers or LoRA while achieving comparable new-task performance.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.25149 , year=
Felix Abecassis, Anjulie Agrusa, Dong Ahn, Jonah Alben, Stefania Alborghetti, Michael Andersch, Sivakumar Arayandi, Alexis Bjorlin, Aaron Blakeman, Evan Briones, et al. Pretraining large language models with NVFP4.arXiv preprint arXiv:2509.25149,
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2008.00051 , author =
Ahmad Ajalloeian and Sebastian U Stich. On the convergence of SGD with biased gradients.arXiv preprint arXiv:2008.00051,
-
[4]
MathQA: Towards interpretable math word problem solving with operation-based formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and ...
2019
-
[5]
Haomin Bai, Dingzhi Yu, Shuai Li, Haipeng Luo, and Lijun Zhang. Group distributionally robust optimization with flexible sample queries.arXiv preprint arXiv:2505.15212,
-
[6]
Scalify: scale propagation for efficient low-precision llm training.arXiv preprint arXiv:2407.17353,
Paul Balança, Sam Hosegood, Carlo Luschi, and Andrew Fitzgibbon. Scalify: scale propagation for efficient low-precision llm training.arXiv preprint arXiv:2407.17353,
-
[7]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
1901
-
[8]
SignSVRG: fixing SignSGD via variance reduction.arXiv preprint arXiv:2305.13187,
Lesi Chen, Jing Xu, and Luo Luo. Faster gradient-free algorithms for nonsmooth nonconvex stochastic optimization. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 5219–5233, 2023a. Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, et al. Symb...
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
LMFlow: An extensible toolkit for finetuning and inference of large foundation models
Shizhe Diao, Rui Pan, Hanze Dong, KaShun Shum, Jipeng Zhang, Wei Xiong, and Tong Zhang. LMFlow: An extensible toolkit for finetuning and inference of large foundation models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations), pa...
2024
-
[11]
URL https://github.com/ OptimalScale/LMFlow. 11 Yiming Dong, Huan Li, and Zhouchen Lin. Convergence rate analysis of LION.arXiv preprint arXiv:2411.07724,
-
[12]
The language model evaluation harness, 07 2024.https://zenodo.org/records/12608602
URL https://zenodo.org/records/12608602. Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. OpenWebText Corpus. http:// Skylion007.github.io/OpenWebTextCorpus,
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zhiwei Hao, Jianyuan Guo, Li Shen, Yong Luo, Han Hu, Guoxia Wang, Dianhai Yu, Yonggang Wen, and Dacheng Tao. Low-precision training of large language models: Methods, challenges, and opportunities.arXiv preprint arXiv:2505.01043,
-
[16]
Elad Hazan. Introduction to online convex optimization.arXiv preprint arXiv:1909.05207v3, 2019a. Elad Hazan. Lecture notes: Optimization for machine learning.arXiv preprint arXiv:1909.03550, 2019b. Elad Hazan, Amit Agarwal, and Satyen Kale. Logarithmic regret algorithms for online convex optimization. Machine Learning, 69(2):169–192,
-
[17]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GeLUs).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review arXiv
-
[18]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Ruichen Jiang, Aryan Mokhtari, and Francisco Patitucci. Improved complexity for smooth nonconvex optimiza- tion: A two-level online learning approach with quasi-newton methods. InProceedings of the 57th Annual ACM Symposium on Theory of Computing (STOC), page 2225–2236, 2025a. Wei Jiang and Lijun Zhang. Convergence analysis of the Lion optimizer in centra...
-
[20]
Wei Jiang, Dingzhi Yu, Sifan Yang, Wenhao Yang, and Lijun Zhang. Improved analysis for sign-based methods with momentum updates.arXiv preprint arXiv:2507.12091, 2025b. Richeng Jin, Yufan Huang, Xiaofan He, Huaiyu Dai, and Tianfu Wu. Stochastic-Sign SGD for federated learning with theoretical guarantees.arXiv preprint arXiv:2002.10940,
-
[21]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Mate- jovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Learning multiple layers of features from tiny images.(2009),
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images.(2009),
2009
-
[23]
Available: https://arxiv.org/abs/2405.18710
Joonhyung Lee, Jeongin Bae, Byeongwook Kim, Se Jung Kwon, and Dongsoo Lee. To FP8 and back again: Quantifying the effects of reducing precision on LLM training stability.arXiv preprint arXiv:2405.18710,
-
[24]
Zhikai Li, Xiaoxuan Liu, Banghua Zhu, Zhen Dong, Qingyi Gu, and Kurt Keutzer. QFT: Quantized full-parameter tuning of LLMs with affordable resources.arXiv preprint arXiv:2310.07147,
-
[25]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Bo Liu, Lemeng Wu, Lizhang Chen, Kaizhao Liang, Jiaxu Zhu, Chen Liang, Raghuraman Krishnamoorthi, and Qiang Liu. Communication efficient distributed trainin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, et al. FP8 formats for deep learning.arXiv preprint arXiv:2209.05433,
work page internal anchor Pith review arXiv
-
[27]
Recipes for pre-training llms with MXFP8
Asit Mishra, Dusan Stosic, Simon Layton, and Paulius Micikevicius. Recipes for pre-training llms with MXFP8. arXiv preprint arXiv:2506.08027,
-
[28]
8-bit numerical formats for deep neural networks
Badreddine Noune, Philip Jones, Daniel Justus, Dominic Masters, and Carlo Luschi. 8-bit numerical formats for deep neural networks.arXiv preprint arXiv:2206.02915,
-
[29]
Torchao: Pytorch-native training-to-serving model optimization,
Andrew Or, Apurva Jain, Daniel Vega-Myhre, Jesse Cai, Charles David Hernandez, Zhenrui Zheng, Driss Guessous, Vasiliy Kuznetsov, Christian Puhrsch, Mark Saroufim, et al. TorchAO: PyTorch-Native Training-to- Serving Model Optimization.arXiv preprint arXiv:2507.16099,
-
[30]
A Modern Introduction to Online Learning
Francesco Orabona. A modern introduction to online learning.arXiv preprint arXiv:1912.13213v8,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[31]
Unbiased gradient low-rank projection
Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, and Tong Zhang. LISA: Layerwise impor- tance sampling for memory-efficient large language model fine-tuning. InAdvances in Neural Information Processing Systems 37 (NeurIPS), pages 57018–57049, 2024a. Rui Pan, Yuxing Liu, Xiaoyu Wang, and Tong Zhang. Accelerated convergence of stochastic h...
-
[32]
Fp8-lm: Training fp8 large language models.arXiv preprint arXiv:2310.18313, 2023
Houwen Peng, Kan Wu, Yixuan Wei, Guoshuai Zhao, Yuxiang Yang, Ze Liu, Yifan Xiong, Ziyue Yang, Bolin Ni, Jingcheng Hu, et al. FP8-LM: Training FP8 large language models.arXiv preprint arXiv:2310.18313,
-
[33]
Sergio P Perez, Yan Zhang, James Briggs, Charlie Blake, Josh Levy-Kramer, Paul Balanca, Carlo Luschi, Stephen Barlow, and Andrew William Fitzgibbon. Training and inference of large language models using 8-bit floating point.arXiv preprint arXiv:2309.17224,
-
[34]
ZeRO-Offload: Democratizing billion-scale model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. ZeRO-Offload: Democratizing billion-scale model training. InProceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 2021), pages 551–564,
2021
-
[35]
Pre-training LLMs on a budget: A comparison of three optimizers.arXiv preprint arXiv:2507.08472,
Joel Schlotthauer, Christian Kroos, Chris Hinze, Viktor Hangya, Luzian Hahn, and Fabian Küch. Pre-training LLMs on a budget: A comparison of three optimizers.arXiv preprint arXiv:2507.08472,
-
[36]
Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440, 2025
Andrei Semenov, Matteo Pagliardini, and Martin Jaggi. Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440,
-
[37]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review arXiv 1909
-
[38]
Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research (JMLR), 15 (56):1929–1958,
16 Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research (JMLR), 15 (56):1929–1958,
1929
-
[39]
Gemini: A Family of Highly Capable Multimodal Models
URL https: //github.com/tatsu-lab/stanford_alpaca. Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalk- wyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay B...
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art...
2020
-
[42]
arXiv preprint arXiv:2307.10053 , year=
17 Nachuan Xiao, Xiaoyin Hu, and Kim-Chuan Toh. Stochastic subgradient methods with guaranteed global stability in nonsmooth nonconvex optimization.arXiv preprint arXiv:2307.10053,
-
[43]
Stepwiser: Stepwise generative judges for wiser reasoning.arXiv preprint arXiv:2508.19229,
Wei Xiong, Wenting Zhao, Weizhe Yuan, Olga Golovneva, Tong Zhang, Jason Weston, and Sainbayar Sukhbaatar. Stepwiser: Stepwise generative judges for wiser reasoning.arXiv preprint arXiv:2508.19229,
-
[44]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Sign-based optimizers are effective under heavy-tailed noise.arXiv preprint arXiv:2602.07425,
Dingzhi Yu, Hongyi Tao, Yuanyu Wan, Luo Luo, and Lijun Zhang. Sign-based optimizers are effective under heavy-tailed noise.arXiv preprint arXiv:2602.07425,
work page internal anchor Pith review arXiv
-
[47]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. TinyLlama: An open-source small language model. arXiv preprint arXiv:2401.02385,
work page internal anchor Pith review arXiv
-
[48]
Random scaling and momentum for non-smooth non-convex optimization
Qinzi Zhang and Ashok Cutkosky. Random scaling and momentum for non-smooth non-convex optimization. arXiv preprint arXiv:2405.09742v2,
-
[49]
[2018], who established an O(1/T+ 1/B) convergence rate for smooth non-convex objectives, whereT denotes the number of iterations and B the batch size
18 A Related Work Sign-based optimizationSignSGD (and its momentum variant Signum) was first introduced by Bernstein et al. [2018], who established an O(1/T+ 1/B) convergence rate for smooth non-convex objectives, whereT denotes the number of iterations and B the batch size. This result suggests that the convergence of SignSGD relies heavily on large-batc...
2018
-
[50]
develop convex and deterministic counterexamples where SignSGD diverges. Owing to its communication efficiency, SignSGD subsequently attracted extensive attention in distributed learning settings [Bernstein et al., 2019, Jin et al., 2020, Safaryan and Richtárik, 2021]. The general idea of injecting noise into the sign operator appears at [Jin et al., 2020...
2019
-
[51]
On the theoretical side, Sun et al
proposed a generalized version of SignSGD that is closely related to Adam, complementing another line of work that seeks to explain Adam’s effectiveness from the perspective of sign descent [Balles and Hennig, 2018, Kunstner et al., 2023]. On the theoretical side, Sun et al
2018
-
[52]
This direction was further advanced by Jiang et al
proposed SignSVRG, which combines sign-based updates with variance reduction techniques [Johnson and Zhang, 2013, Zhang et al., 2013]. This direction was further advanced by Jiang et al. [2024], who incorporated the STORM estimator [Cutkosky and Orabona, 2019] and extended the method to distributed settings. Empirically, the origins of sign-based optimiza...
2013
-
[53]
Their analysis establishes convergence under generalized heavy-tailed noise and removes the dimensional dependence present in prior works [Dong et al., 2024, Jiang and Zhang, 2025]
is the first to theoretically justify the potential benefits of Signum and Lion over AdamW. Their analysis establishes convergence under generalized heavy-tailed noise and removes the dimensional dependence present in prior works [Dong et al., 2024, Jiang and Zhang, 2025]. Non-smooth optimizationIn convex settings, non-smooth optimization arises naturally...
2024
-
[54]
Beyond first-order methods, gradient-free approaches have also been proposed and analyzed for this challenging setting [Lin et al., 2022, Chen et al., 2023a, Liu et al., 2024d,e]
showed that no deterministic algorithm can identify (δ, ϵ)-Goldstein points in dimension-free time. Beyond first-order methods, gradient-free approaches have also been proposed and analyzed for this challenging setting [Lin et al., 2022, Chen et al., 2023a, Liu et al., 2024d,e]. A recent major breakthrough is the online-to-non-convex conversion (O2NC) fra...
2022
-
[55]
Liu et al
introduced exponential random scaling into O2NC and showed that SGD with momentum can efficiently find (δ, ϵ)-stationary points. Liu et al. [2024c] further incorporated gradient clipping into this framework and established high-probability guarantees under heavy-tailed gradients. These results were subsequently refined by Liu [2026], who developed an eleg...
2026
-
[56]
[2025], Abecassis et al
developed hardware-compatible INT4 transformer training, Castro et al. [2025], Abecassis et al
2025
-
[57]
pushed toward fully FP8 GEMM LLM training at scale. Industrial technical reports such as DeepSeek-V3 and Qwen3 further indicate that low-precision training is becoming an important systems direction for modern LLM development [Liu et al., 2024a, Yang et al., 2025]. At the same time, another line of work studies why low-precision training fails and how to ...
2025
-
[58]
traced an important failure mode of low-precision Transformer training to FlashAttention [Dao et al., 2022, Dao, 2024, Shah et al., 2024]. In contrast to these works, our goal is not to design yet another stabilization recipe for AdamW, but to show that replacing AdamW with a sign-based optimizer can itself provide a simple and robust alternative in highl...
2022
-
[59]
To cut memory usage and accelerate training, we utilize the LMFlow toolbox [Diao et al., 2024]
All other settings remain at their transformers==4.52.4 [Wolf et al., 2020] defaults. To cut memory usage and accelerate training, we utilize the LMFlow toolbox [Diao et al., 2024]. For evaluation, we leverage the lm-evaluation-harness framework [Gao et al., 2024] and follow mostly from the configurations in Pan et al. [2025b]. Specifically, we set max_ne...
2020
-
[60]
“±” represents standard error automatically calculated bylm_eval. Optimizer AdamW SignSGD StoSignSGD GSM8k 74.37±1.20 71.95±1.2477.33±1.15 MATH (overall) 48.86±0.66 47.66±0.6648.88±0.65 algebra 70.60±1.32 68.91±1.3471.19±1.32 prealgebra 65.33±1.61 63.49±1.6365.44±1.61 num_theory 54.81±2.14 54.44±2.1557.59±2.13 counting_and_prob40.51±2.2640.08±2.25 40.08±2...
1932
-
[61]
We train on a total of 13.1B tokens, corresponding to a 5.3x Chinchilla-optimal ratio [Hoffmann et al., 2022]
since we are utilizing sign-based methods. We train on a total of 13.1B tokens, corresponding to a 5.3x Chinchilla-optimal ratio [Hoffmann et al., 2022]. This relatively long training regime is generally enough to capture the dynamics between different optimization algorithms [An et al., 2025]. For optimizer configurations detailed in Table 11, we set the...
2022
-
[62]
Table 12: AdamW optimizer state collapse under FP8_E4M3 quantization at 103rd step
Further tuning down the learning rate is meaningless since the current sign-aligned ηpeak, ηmin is already unfavorable for AdamW [Liu et al., 2025a, Wen et al., 2026, Liang et al., 2026]. Table 12: AdamW optimizer state collapse under FP8_E4M3 quantization at 103rd step. Layer Namev t Zeros (%)m t Zeros (%) Max|g t|Maxg t ⊙g t Token Embedding 100.0 100.0 ...
2026
-
[63]
Our empirical demonstration in Figure 4 also confirms this point
The condition σt ⪰m t can be easily satisfied by most optimizers in practice. Our empirical demonstration in Figure 4 also confirms this point. B.3.2 Experimental Details To evaluate the optimizers detailed in Appendix B.5, we establish two distinct experimental setups: instruction following and mathematical reasoning. Their configurations are elaborated ...
2023
-
[64]
These models are finetuned on the training sets of GSM8k [Cobbe et al., 2021] and MathQA [Amini et al., 2019], and subsequently evaluated on their respective test sets
Mathematical ReasoningFor this task, we scale up to three popular 7B+ parameter LLMs: Qwen2.5-7B [Yang et al., 2024], Llama-3.1-8B [Grattafiori et al., 2024], and Mistral-7B-v0.1 [Jiang et al., 2023]. These models are finetuned on the training sets of GSM8k [Cobbe et al., 2021] and MathQA [Amini et al., 2019], and subsequently evaluated on their respectiv...
2024
-
[65]
[2024], Gao et al
All remaining hyperparameters across both experimental setups adhere to the default configurations provided by Diao et al. [2024], Gao et al. [2024]. For optimizer-specific tuning, we employ a coordinate descent approach to systematically sweep the learning rates [Wen et al., 2026]. To ensure a fair comparison, the momentum parameters (β1 and β2) for the ...
2024
-
[66]
One would also note that our experiments indicate an approximate 0.2 update RMS- norm for AdamW, which aligns with the theoretical value [Kosson et al., 2024] and empirical observation [Liu et al., 2025a] perfectly well. 25 0 250 500 750 1000 1250 Step 0.2 0.4 0.6 0.8 1.0RMS-norm param_groups[0] 0 250 500 750 1000 1250 Step 0.2 0.4 0.6 0.8 1.0Arithmetic m...
2024
-
[67]
While all three methods achieve comparable final test accuracies—with StoSignSGD maintaining a slight edge—StoSignSGD achieves a significantly lower final test loss
The empirical trajectories clearly demonstrate that StoSignSGD converges more rapidly than both SignSGD and AdamW. While all three methods achieve comparable final test accuracies—with StoSignSGD maintaining a slight edge—StoSignSGD achieves a significantly lower final test loss. This notable reduction in test loss highlights its superior generalization c...
2018
-
[68]
Algorithm 5Practical Implementation of SignSGD 1:Input:Start pointx 1 ∈R d, momentumβ 1 ∈[0,1), learning rate{η t}T t=1, weight decayλ≥0. 2:fort= 1toTdo 3:Get stochastic gradientg t 4:Update momentumm t =β 1mt−1 + (1−β 1)gt {m1 =g 1} 5:Computex t+1 =x t −η t sign (mt)−η tλxt 6:end for Algorithm 6AdamW [Kingma and Ba, 2015, Loshchilov and Hutter, 2019] 1:I...
2015
-
[69]
2:Initialize:m 0 =0,u 0 =0
8:# General Optimizer Update 9:x t+1 =x t −η t bmt√bvt+ϵ −η tλxt 10:end for Algorithm 7AdaMax with Decoupled Weight Decay [Kingma and Ba, 2015, Loshchilov and Hutter, 2019] 1:Input:Initializationx 1 ∈R d, learning rate{η t}T t=1, weight decayλ≥0,β 1, β2 ∈[0,1),ϵ≥0. 2:Initialize:m 0 =0,u 0 =0. 3:fort= 1toTdo 4:Get stochastic gradientg t 5:m t =β 1mt−1 + (1...
2015
-
[70]
8:# Sign Conversion Update 9:Sample Uniform noisen t ∼Unif [−1,1] d 10:x t+1 =x t −η t sign (bmt + (ut +ϵ)⊙n t)−η tλxt 11:end for Algorithm 10In-expectation StoSignSGD (IE-StoSignSGD) 1: Input:Initialization x1 ∈R d, momentum β1 ∈[0,1), β 2 ∈(0,1] , learning rate {ηt}T t=1, weight decay λ≥0. 2:fort= 1toTdo 3:Get stochastic gradientg t 4:Update momentumm t...
2018
-
[71]
[2020, Lemma 1]
The practical version in Algorithm 3, incorporating momentum, can share the same derivations as Algorithms 1 and 2 according to, for example, the techniques in Alacaoglu et al. [2020, Lemma 1]. However, it is highly challenging to prove the benefits of momentum (see Kidambi et al. [2018], Pan et al. [2024b] and references therein), especially in our non-s...
2020
-
[72]
Theorem 4.Under Assumptions 1 and 3, suppose StoSignSGD in (2) runs T steps
Below, we present the theoretical guarantee of StoSignSGD for SCO. Theorem 4.Under Assumptions 1 and 3, suppose StoSignSGD in (2) runs T steps. Let xT = 1 T PT t=1 xt, and ηt = D∞√ 2t , it holds that E[f( xT )−f ∗]≤ √ 2D∞ ∥L∥1√ T . The rate is known to be minimax optimal inT [Nemirovski and Yudin, 1983]. Under the common coordinate-wise Lipschitz constant...
1983
-
[73]
Concretely, the bound in Theorem 4 could be easily transferred into a pseudo-regret bound for OCO, where the elaborations are in Appendices C.3.1 and C.3.2 C.2 Proof of Theorem 4 We adopt an AdaGrad style of analysis [McMahan and Streeter, 2010, Duchi et al., 2011, Liu et al., 2025b] to prove Theorem
2010
-
[74]
TX t=1 ⟨∂f(x t),x t −x ∗⟩ # ≤E
Rearranging the above inequality and summing from 1 to T yields the following regret bound: 2E " TX t=1 ⟨∂f(x t),x t −x ∗⟩ # ≤E " TX t=1 ∥xt −x ∗∥2 Gt−1/ηt−1 − ∥xt+1 −x ∗∥2 Gt/ηt # +E " D2 ∞ TX t=1 ∥Gt∥1 ηt − ∥Gt−1∥1 ηt−1 # +E " TX t=1 ηt ∥Gt∥1 # ≤ ∥x1 −x ∗∥2 G1/η1 +D 2 ∞E ∥GT ∥1 ηT − ∥G1∥1 η1 + TX t=1 ηtE[∥G t∥1] ≤ ∥x1 −x ∗∥2 ∞ ∥G1∥1 η1 − D2 ∞ ∥G1∥1 η1 +...
2006
-
[75]
best” action is only defined w.r.t. the expectation and is not random. The randomness only plays a role once the “deterministic
For completeness, we still present its proof. Following Appendix C.2, for any fixed x∈ X , we have E h ∥xt+1 −x∥ 2 Gt/ηt i Lemma C.4 ≤E h ∥xt −η t · SGt(gt)−x∥ 2 Gt/ηt i =E h ∥xt −x∥ 2 Gt/ηt −2⟨diag(G t)S Gt(gt),x t −x⟩+η 2 t ∥SGt(gt)∥2 Gt/ηt i =E h ∥xt −x∥ 2 Gt/ηt i −E[2⟨E St [Gt ⊙ SGt(gt)],x t −x⟩] +E[η t ∥Gt∥1] =E h ∥xt −x∥ 2 Gt−1/ηt−1 +∥x t −x∥ 2 Gt/η...
2012
-
[76]
TX t=1 Vt # =E
Hence, we conclude that E " TX t=1 Vt # =E " TX t=1 Mt # +E " TX t=1 ⟨et,y t −exT ⟩ # =E " TX t=1 ⟨et,y t −exT ⟩ # ≤2D ∞ ∥L∥1 √ T . Finally, we arrive at E " TX t=1 ⟨gt,x t −exT ⟩ # ≤E " TX t=1 Vt # + D2 ∞ ∥L∥1 2ηT + TX t=1 ηt ∥L∥1 2 ≤2D∞ ∥L∥1 √ T+∥L∥ 1 D2 ∞ 2ηT + TX t=1 ηt 2 ! . Plugging inη t =D ∞/ √ 2tandη t ≡D ∞/ √ Trespectively completes the proof. C...
2010
-
[77]
TX t=1 ⟨gt,∆ t −u t⟩ # = KX k=1 E
Next, we control the linear regret term in (6). Similarly, we first decompose it into the K-shifting regret [Cutkosky et al., 2023] of online stochastic sign gradient descent, and then apply the expected regret bound in Theorem 1 to obtain the final result4. E " TX t=1 ⟨gt,∆ t −u t⟩ # = KX k=1 E " NX n=1 g(k−1)N+n ,∆ (k−1)N+n −u k # ≤ KX k=1 2 + √ 2 ·(2D ...
2023
-
[78]
NX n=1 1 N ∇f(x (k−1)N+n ) 1 # + 2δN 2D2 ∞. Since x∼Unif x1,· · ·, xk , we have E h ∥∇f(x)∥[δ] 1,∞ i = 1 K KX k=1 E h ∇f(xk) [δ] 1,∞ i ≤ 1 K KX k=1 E
35 (12) ≤E " NX n=1 1 N ∇f(x (k−1)N+n ) 1 # + 2δN 2D2 ∞. Since x∼Unif x1,· · ·, xk , we have E h ∥∇f(x)∥[δ] 1,∞ i = 1 K KX k=1 E h ∇f(xk) [δ] 1,∞ i ≤ 1 K KX k=1 E " NX n=1 1 N ∇f(x (k−1)N+n ) 1 # + 2δN 2D2 ∞ (10) ≤ ∆f D∞KN + 5 + 2 √ 2 ∥L∥1√ N + 2δN 2D2 ∞ ≤2 7 ϵ+ 4 7 ϵ+ 1 7 ϵ=ϵ, where the last step follows from N= & 49 33 + 20 √ 2 ∥L∥2 1 16ϵ2 ' , K= & 7∆f ...
2007
-
[79]
We also discuss the relationship between Definitions 2 and 3 in Appendix D.2, following the similar recipe as Zhang and Cutkosky [2026]
Analogously to Definition 2, Definition 3 is more general and capable of fitting diverse problem geometries compared to the Euclidean notion in previous literature [Cutkosky et al., 2023, Definition 12]. We also discuss the relationship between Definitions 2 and 3 in Appendix D.2, following the similar recipe as Zhang and Cutkosky [2026]. Next, we introdu...
2023
-
[80]
[2023, Algorithm 1]
The above alterations stem from the original online-to-nonconvex conversion framework in Cutkosky et al. [2023, Algorithm 1]. Algorithm 12 can be viewed as replacing their online gradient descent [Zinkevich, 2003] base algorithm with online StoSignSGD in Algorithm
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.