SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Pith reviewed 2026-06-27 06:47 UTC · model grok-4.3
The pith
A stateful code-based action interface enables vision-language agents to achieve higher accuracy on complex 3D and 4D spatial reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
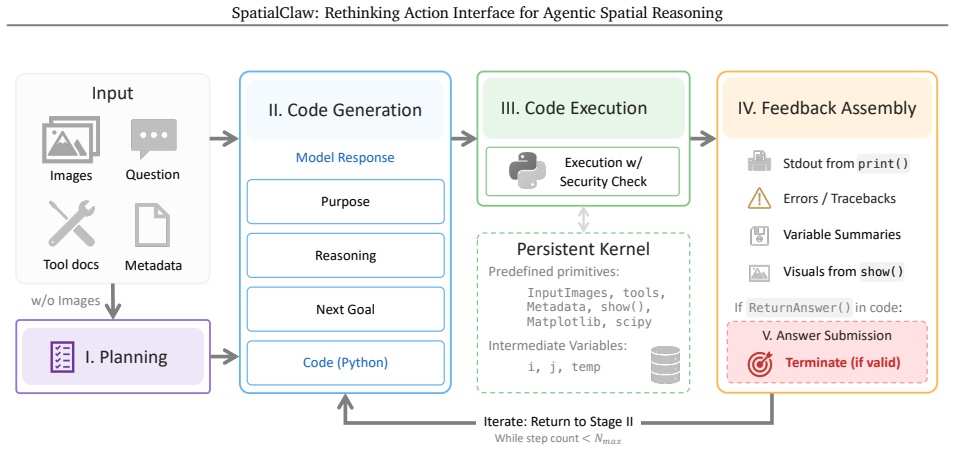
SpatialClaw is a framework that equips a vision-language model with a stateful Python kernel containing input data and perception primitives. The agent generates one executable code cell at a time, using outputs from previous steps to inform the next, which allows flexible composition of operations tailored to each task's demands in open-ended spatial reasoning.
What carries the argument
The stateful Python kernel pre-loaded with frames and primitives, serving as the action interface that supports iterative, conditioned code execution.
If this is right
- The agent can revise its spatial analysis strategy based on intermediate visual and textual observations.
- Performance gains appear across multiple vision-language model families without task-specific tuning.
- The method applies uniformly to both static image and dynamic video spatial tasks.
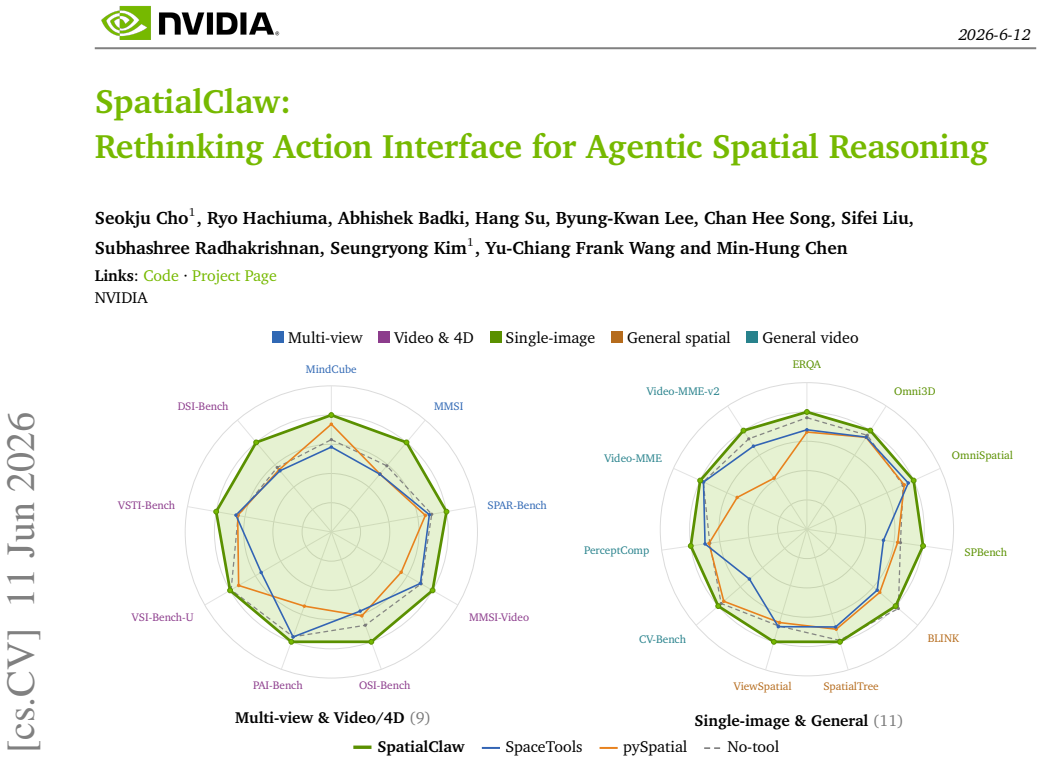
- Overall accuracy reaches 59.9 percent on a suite of twenty benchmarks.
Where Pith is reading between the lines
- Similar stateful interfaces could improve agent performance in other domains requiring sequential decision-making, such as mathematical problem solving.
- The emphasis on code flexibility might reduce reliance on hand-crafted tool schemas in agent design.
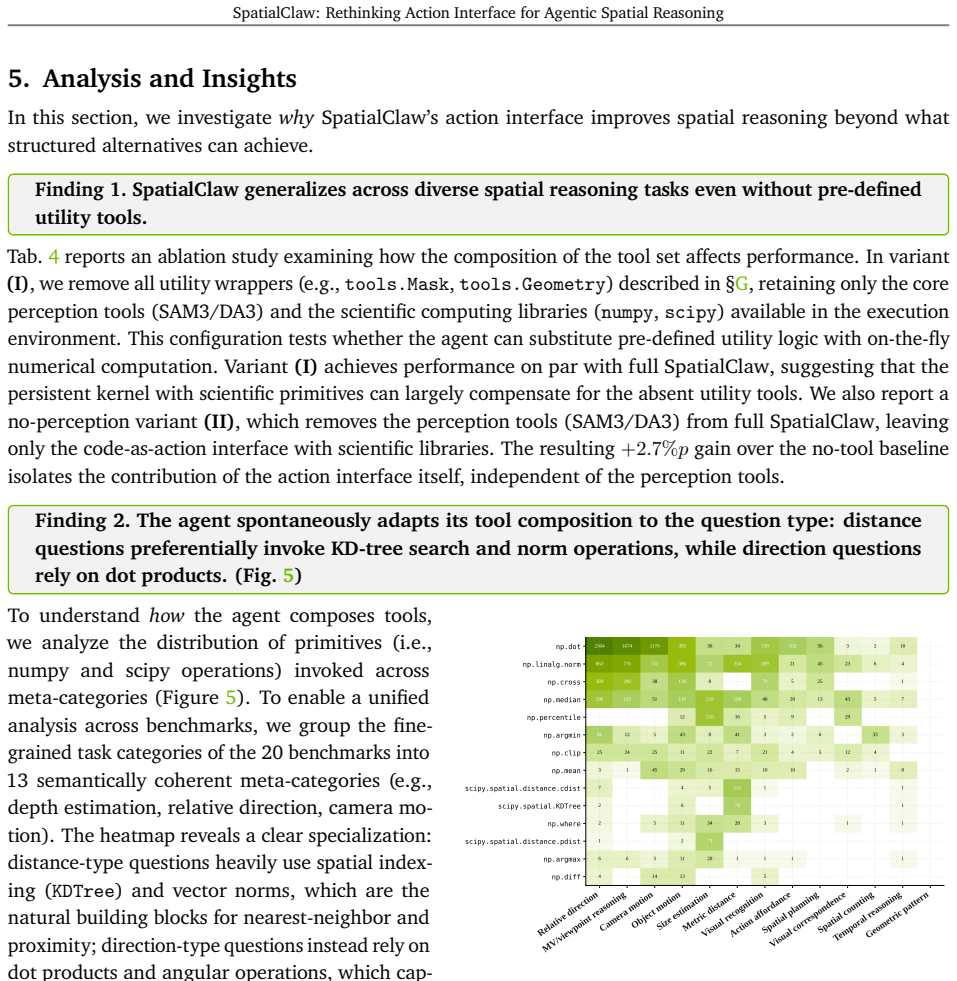
- Future work could explore scaling the number of primitives available in the kernel to handle more intricate scenes.
Load-bearing premise
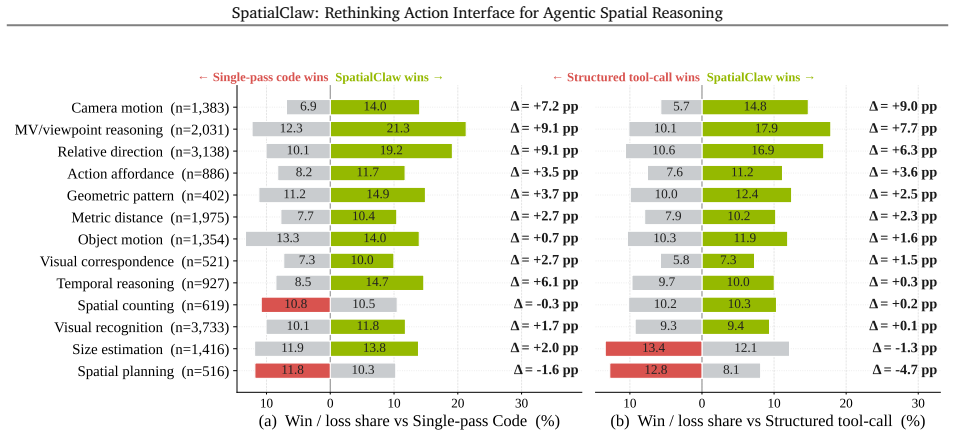
The performance advantage results from the stateful per-step code interface itself rather than from variations in prompts, primitive selection, or benchmark characteristics.
What would settle it
Running the same agent with single-pass code execution versus the stateful interface on identical benchmarks while keeping all other components fixed, and observing whether the accuracy difference disappears.
Figures


read the original abstract
Spatial reasoning, the ability to determine where objects are, how they relate, and how they move in 3D, remains a fundamental challenge for vision-language models (VLMs). Tool-augmented agents attempt to address this by augmenting VLMs with specialist perception modules, yet their effectiveness is bounded by the action interface through which those tools are invoked. In this work, we study how the design of this interface shapes the agent's capacity for open-ended spatial reasoning. Existing spatial agents either employ single-pass code execution, which commits to a full analysis strategy before any intermediate result is observed, or rely on a structured tool-call interface that often offers less flexibility for freely composing operations or tailoring the analysis to each task. Both designs offer limited flexibility for open-ended, complex 3D/4D spatial reasoning. We therefore propose SpatialClaw, a training-free framework for spatial reasoning that adopts code as the action interface. SpatialClaw maintains a stateful Python kernel pre-loaded with input frames and a suite of perception and geometry primitives, letting a VLM-backed agent write one executable cell per step conditioned on all prior outputs, enabling the agent to flexibly compose and manipulate perception results and adapt its analysis to both intermediate text and visual observations and the demands of each problem. Evaluated across 20 spatial reasoning benchmarks spanning a broad range of static and dynamic 3D/4D spatial reasoning tasks, SpatialClaw achieves 59.9% average accuracy, outperforming the recent spatial agent by +11.2 points, with consistent gains across six VLM backbones from two model families without any benchmark- or model-specific adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SpatialClaw, a training-free framework for agentic spatial reasoning that uses code as the action interface: a stateful Python kernel pre-loaded with input frames and perception/geometry primitives, allowing a VLM to emit one executable cell per step conditioned on prior outputs. This is contrasted with single-pass code execution and structured tool-call interfaces. The central empirical claim is that SpatialClaw attains 59.9% average accuracy across 20 static and dynamic 3D/4D spatial reasoning benchmarks, outperforming a recent spatial agent baseline by +11.2 points with consistent gains across six VLM backbones from two families and no benchmark- or model-specific adaptation.
Significance. If the reported gains can be isolated to the stateful per-step code interface after appropriate controls, the result would provide concrete evidence that interface flexibility matters for open-ended spatial reasoning and could guide the design of future VLM agents. The work is notable for its breadth (20 benchmarks, multiple backbones) and training-free nature.
major comments (1)
- [Experiments / Results] The central attribution of the +11.2 point gain to the stateful code interface (as opposed to differences in primitives, prompts, or observation handling) is load-bearing for the headline result, yet the manuscript provides no information on whether the compared recent spatial agent baseline employs identical perception/geometry primitives, identical VLM prompt templates, or the same handling of intermediate visual/text outputs. Without these controls or ablations, the causal claim cannot be verified from the reported numbers alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding experimental controls and attribution of gains below.
read point-by-point responses
-
Referee: [Experiments / Results] The central attribution of the +11.2 point gain to the stateful code interface (as opposed to differences in primitives, prompts, or observation handling) is load-bearing for the headline result, yet the manuscript provides no information on whether the compared recent spatial agent baseline employs identical perception/geometry primitives, identical VLM prompt templates, or the same handling of intermediate visual/text outputs. Without these controls or ablations, the causal claim cannot be verified from the reported numbers alone.
Authors: We agree that the attribution of gains to the stateful code interface requires explicit controls to rule out confounding factors from primitives, prompts, or observation handling. The baseline comparison follows the original implementation and reported numbers from the cited spatial agent paper, with our reimplementation matching their described perception/geometry primitives and prompt structure as closely as possible. To address this directly, the revised manuscript will add a new subsection detailing the exact primitives, VLM prompt templates, and intermediate output handling used in both SpatialClaw and the baseline. We will also include a controlled ablation that applies our stateful per-step code interface to the baseline's primitives and prompts on a subset of benchmarks to better isolate the interface contribution. revision: yes
Circularity Check
No circularity: empirical comparison with no mathematical derivation or self-referential reduction
full rationale
The paper reports experimental results from a training-free agent framework evaluated on 20 benchmarks, claiming accuracy gains over a baseline spatial agent. No equations, fitted parameters, or derivation steps are present in the provided text. Performance attribution rests on direct comparison rather than any self-definitional, fitted-input, or self-citation load-bearing structure. The central claim does not reduce to its inputs by construction; external benchmark results serve as independent evidence. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
ZPPO improves distillation to small vision-language models by using binary and negative candidate prompts plus a replay buffer for hard questions, outperforming standard distillation and GRPO on a 31-benchmark suite w...
Reference graph
Works this paper leans on
-
[1]
train on the test set
Ellis Brown, Jihan Yang, Shusheng Yang, Rob Fergus, and Saining Xie. Benchmark designers should “train on the test set” to expose exploitable non-visual shortcuts.ArXiv Preprint, 2025. 7, 8, 13, 14
2025
-
[2]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision (ECCV), 2020. 2
2020
-
[3]
Sam 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts. InInternational Conference on Learning Representations (ICLR), 2026. 2, 3, 5, 16, 22
2026
-
[4]
Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 13
2024
-
[5]
Eagle 2.5: Boosting long-context post-training for frontier vision-language models
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Max Ehrlich, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, and Guilin Liu. Eagle 2.5: Boosting long-context post-training for frontier vision-language models. In Advances in Neural Information Processing Systems (NeurI...
2025
-
[6]
Spacetools: Tool-augmented spatial reasoning via double interactive rl
Siyi Chen, Mikaela Angelina Uy, Chan Hee Song, Faisal Ladhak, Adithyavairavan Murali, Qing Qu, Stan Birchfield, Valts Blukis, and Jonathan Tremblay. Spacetools: Tool-augmented spatial reasoning via double interactive rl. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 1, 2, 3, 4, 8, 9, 13
2026
-
[7]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 2, 13
2024
-
[8]
4dp-qa: Scalable qa for 4d perception in vision language models
Seokju Cho, Abhishek Badki, Hang Su, Jindong Jiang, Ziyao Zeng, Seungryong Kim, Sifei Liu, and Orazio Gallo. 4dp-qa: Scalable qa for 4d perception in vision language models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 2
2026
-
[9]
Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 7, 8, 9, 13, 14
2026
-
[10]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395,
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395,
-
[11]
GPTQ: Accurate post-training compres- sion for generative pretrained transformers.ArXiv Preprint, 2022
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training compres- sion for generative pretrained transformers.ArXiv Preprint, 2022. 19
2022
-
[12]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 7, 8, 13, 14
2025
-
[13]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. In European Conference on Computer Vision (ECCV), 2024. 7, 8, 9, 13, 14 26 SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
2024
-
[14]
Gemma 4.https://deepmind.google/models/gemma/gemma-4/, 2026
Google DeepMind. Gemma 4.https://deepmind.google/models/gemma/gemma-4/, 2026. Accessed: 2026-04-14. 2, 3, 4, 7, 8, 9, 19
2026
-
[15]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2, 13
2023
-
[16]
Tiger: Tool-integrated geometric reasoning in vision-language models for robotics
Yi Han, Enshen Zhou, Shanyu Rong, Jingkun An, Pengwei Wang, Zhongyuan Wang, Cheng Chi, Lu Sheng, and Shanghang Zhang. Tiger: Tool-integrated geometric reasoning in vision-language models for robotics. ArXiv Preprint, 2025. 2
2025
-
[17]
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin Shepp...
-
[18]
G2vlm: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning
Wenbo Hu, Jingli Lin, Yilin Long, Yunlong Ran, Lihan Jiang, Yifan Wang, Chenming Zhu, Runsen Xu, Tai Wang, and Jiangmiao Pang. G2vlm: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 13
2026
-
[19]
J. D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9(3):90–95,
-
[20]
doi: 10.1109/MCSE.2007.55. 4
-
[21]
Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models. In International Conference on Learning Representations (ICLR), 2026. 7, 8, 9, 13, 14
2026
-
[22]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles,
-
[23]
Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models.ArXiv Preprint, 2025
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, Weiming Lu, and Yueting Zhuang. Viewspatial-bench: Evaluating multi-perspective spatial localization in vision-language models.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[24]
PerceptionComp: A video benchmark for complex perception-centric reasoning.ArXiv Preprint, 2026
Shaoxuan Li, Zhixuan Zhao, Hanze Deng, Zirun Ma, Shulin Tian, Zuyan Liu, Yushi Hu, Haoning Wu, Yuhao Dong, Benlin Liu, Ziwei Liu, and Ranjay Krishna. PerceptionComp: A video benchmark for complex perception-centric reasoning.ArXiv Preprint, 2026. 7, 8, 13, 14
2026
-
[25]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. InInternational Conference on Learning Representations (ICLR), 2026. 3, 5, 16, 21
2026
-
[26]
Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence.ArXiv Preprint, 2025
Jingli Lin, Runsen Xu, Shaohao Zhu, Sihan Yang, Peizhou Cao, Yunlong Ran, Miao Hu, Chenming Zhu, Yiman Xie, Yilin Long, Wenbo Hu, Dahua Lin, Tai Wang, and Jiangmiao Pang. Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence.ArXiv Preprint, 2025. 7, 8, 13, 14
2025
-
[27]
Octotools: An agentic framework with extensible tools for complex reasoning
Pan Lu, Bowen Chen, Sheng Liu, Rahul Thapa, Joseph Boen, and James Zou. Octotools: An agentic framework with extensible tools for complex reasoning. InProceedings of the Association for Computational Linguistics (ACL), 2026. 2, 13 27 SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
2026
-
[28]
pyspatial: Generating 3d visual programs for zero-shot spatial reasoning
Zhanpeng Luo, Ce Zhang, Silong Yong, Cunxi Dai, Qianwei Wang, Haoxi Ran, Guanya Shi, Katia Sycara, and Yaqi Xie. pyspatial: Generating 3d visual programs for zero-shot spatial reasoning. InInternational Conference on Learning Representations (ICLR), 2026. 1, 2, 4, 8, 9, 13
2026
-
[29]
Visual agentic ai for spatial reasoning with a dynamic api
Damiano Marsili, Rohun Agrawal, Yisong Yue, and Georgia Gkioxari. Visual agentic ai for spatial reasoning with a dynamic api. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 4, 7, 8, 9, 13, 14
2025
-
[30]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URLhttps://qwen.ai/blog ?id=qwen3.5. 2, 3, 4, 7, 8, 19
2026
-
[31]
Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026
Qwen Team. Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026. URLhttps: //qwen.ai/blog?id=qwen3.6-27b. 3, 7, 8, 19
2026
-
[32]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026. URLhttps: //qwen.ai/blog?id=qwen3.6-35b-a3b. 3, 7, 19
2026
-
[33]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. In International Conference on Learning Representations (ICLR), 2025. 2
2025
-
[34]
Riemind: Geometry-grounded spatial agent for scene understanding.ArXiv Preprint, 2026
FernandoRopero, ErkinTurkoz, DanielMatos, JunqingDu, AntonioRuiz, YanfengZhang, LuLiu, Mingwei Sun, and Yongliang Wang. Riemind: Geometry-grounded spatial agent for scene understanding.ArXiv Preprint, 2026. 3, 4, 13
2026
-
[35]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2, 13
2023
-
[36]
RoboSpatial: Teaching spatial understanding to 2D and 3D vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. RoboSpatial: Teaching spatial understanding to 2D and 3D vision-language models for robotics. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 13
2025
-
[37]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning. InIEEE International Conference on Computer Vision (ICCV), 2023. 2, 13
2023
-
[38]
Gemini: afamilyofhighlycapablemultimodal models.ArXiv Preprint, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk,AndrewMDai,AnjaHauth,KatieMillican,etal. Gemini: afamilyofhighlycapablemultimodal models.ArXiv Preprint, 2023. 15
2023
-
[39]
Gemini robotics: Bringing ai into the physical world.ArXiv Preprint, 2025
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[40]
Video-mme-v2: Evaluating true understanding and reasoning in video mllms.ArXiv Preprint, 2026
Video-MME Team. Video-mme-v2: Evaluating true understanding and reasoning in video mllms.ArXiv Preprint, 2026. URLhttps://github.com/Video-MME/Video-MME-v2. 7, 8, 13, 14
2026
-
[41]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, İlhan Polat, Yu Feng, Eric W. Mo...
-
[42]
Spatial mental modeling from limited views.ArXiv Preprint, 2025
Qineng Wang, Baiqiao Yin, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, Saining Xie, Manling Li, Jiajun Wu, and Li Fei-Fei. Spatial mental modeling from limited views.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[43]
Executable code actions elicit better llm agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InInternational Conference on Machine Learning (ICML), 2024. 13
2024
-
[44]
𝜋3: Permutation-equivariantvisualgeometrylearning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, ChunhuaShen, andTongHe. 𝜋3: Permutation-equivariantvisualgeometrylearning. InInternational Conference on Learning Representations (ICLR), 2026. 2
2026
-
[45]
From indoor to open world: Revealing the spatial reasoning gap in mllms.ArXiv Preprint, 2025
Mingrui Wu, Zhaozhi Wang, Fangjinhua Wang, Jiaolong Yang, Marc Pollefeys, and Tong Zhang. From indoor to open world: Revealing the spatial reasoning gap in mllms.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[46]
Spatialtree: How spatial abilities branch out in mllms.ArXiv Preprint, 2025
Yuxi Xiao, Longfei Li, Shen Yan, Xinhang Liu, Sida Peng, Yunchao Wei, Xiaowei Zhou, and Bingyi Kang. Spatialtree: How spatial abilities branch out in mllms.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[47]
Spatialbench: Benchmarking multimodal large language models for spatial cognition.ArXiv Preprint, 2025
Peiran Xu, Sudong Wang, Yao Zhu, Jianing Li, and Yunjian Zhang. Spatialbench: Benchmarking multimodal large language models for spatial cognition.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[48]
Thinking in Space: How Multimodal Large Language Models See, Remember and Recall Spaces
Jihan Yang, Shusheng Yang, Anjali Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in Space: How Multimodal Large Language Models See, Remember and Recall Spaces. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 4, 14
2025
-
[49]
Mmsi-bench: A benchmark for multi-image spatial intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. Mmsi-bench: A benchmark for multi-image spatial intelligence. InICLR, 2025. 7, 8, 9, 13, 14
2025
-
[50]
Geometrically-constrained agent for spatial reasoning.ArXiv Preprint, 2025
Chen Zeren, Lu Xiaoya, Zheng Zhijie, Li Pengrui, He Lehan, Zhou Yijin, Shao Jing, Zhuang Bohan, and Sheng Lu. Geometrically-constrained agent for spatial reasoning.ArXiv Preprint, 2025. 3, 4, 13
2025
-
[51]
From flatland to space: Teaching vision-language models to perceive and reason in 3d
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yujie Yuan, Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, and Li Zhang. From flatland to space: Teaching vision-language models to perceive and reason in 3d. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 7, 8, 9, 13, 14
2025
-
[52]
Make geometry matter for spatial reasoning.ArXiv Preprint, 2026
Shihua Zhang, Qiuhong Shen, Shizun Wang, Tianbo Pan, and Xinchao Wang. Make geometry matter for spatial reasoning.ArXiv Preprint, 2026. 13
2026
-
[53]
Think3d: Thinking with space for spatial reasoning.ArXiv Preprint,
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning.ArXiv Preprint,
-
[54]
Dsi-bench: A benchmark for dynamic spatial intelligence.ArXiv Preprint, 2025
Ziang Zhang, Zehan Wang, Guanghao Zhang, Weilong Dai, Yan Xia, Ziang Yan, Minjie Hong, and Zhou Zhao. Dsi-bench: A benchmark for dynamic spatial intelligence.ArXiv Preprint, 2025. 7, 8, 9, 13, 14
2025
-
[55]
Pyvision: Agentic vision with dynamic tooling.ArXiv Preprint, 2025
Shitian Zhao, Haoquan Zhang, Shaoheng Lin, Ming Li, Qilong Wu, Kaipeng Zhang, and Chen Wei. Pyvision: Agentic vision with dynamic tooling.ArXiv Preprint, 2025. 13
2025
-
[56]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 15
2023
-
[57]
Pai-bench: Acomprehensive benchmark for physical ai.ArXiv Preprint, 2025
FengzheZhou, JiannanHuang, JialuoLi, DevaRamanan, andHumphreyShi. Pai-bench: Acomprehensive benchmark for physical ai.ArXiv Preprint, 2025. 7, 8, 9, 13, 14 29 SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
2025
-
[58]
Cvbench: Benchmarking cross-video synergies for complex multimodal reasoning.ArXiv Preprint, 2025
Nannan Zhu, Yonghao Dong, Teng Wang, Xueqian Li, Shengjun Deng, Yijia Wang, Zheng Hong, Tiantian Geng, Guo Niu, Hanyan Huang, et al. Cvbench: Benchmarking cross-video synergies for complex multimodal reasoning.ArXiv Preprint, 2025. 7, 8, 9, 13, 14 30
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.