LISA: Likelihood Score Alignment for Visual-condition Controllable Generation
Pith reviewed 2026-06-26 05:43 UTC · model grok-4.3
The pith
Aligning side-network features to an approximated likelihood score accelerates convergence and improves conditional results in dual-branch diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
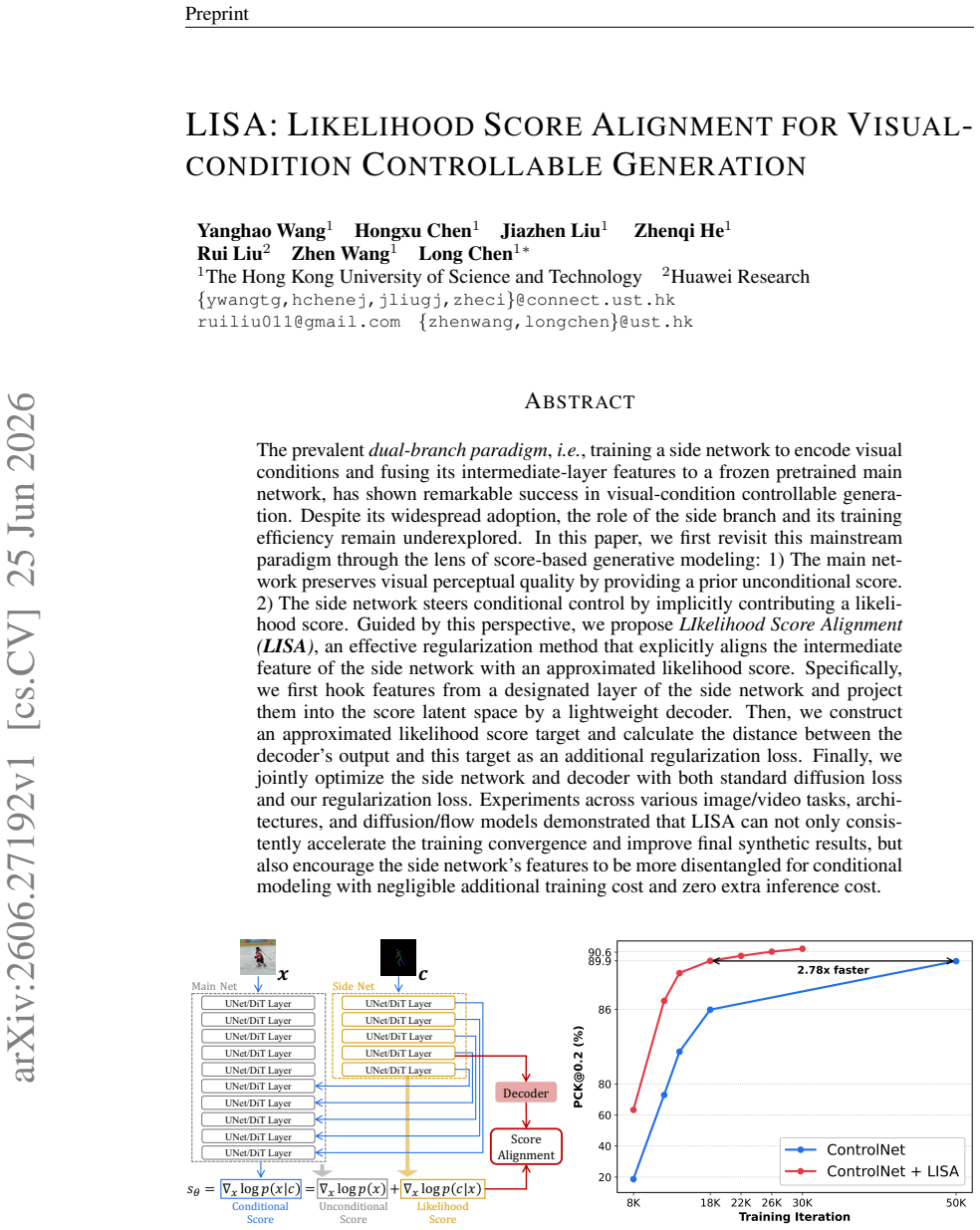
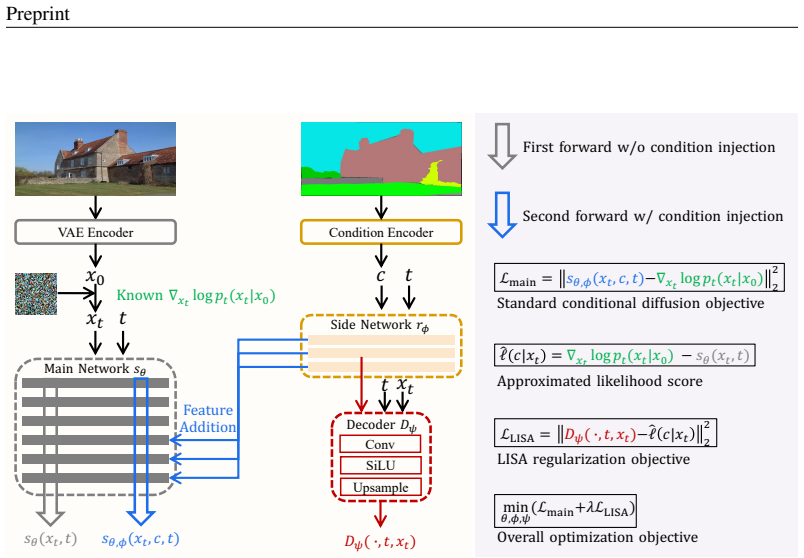
LISA is a regularization method that hooks intermediate features from a chosen layer of the side network, projects them into the score latent space with a lightweight decoder, constructs an approximated likelihood score target from the diffusion process, and minimizes the distance between the decoder output and this target as an added loss term while jointly training the side network and decoder alongside the standard diffusion objective.
What carries the argument
Likelihood Score Alignment (LISA) regularization, which projects side-network features via a decoder and aligns them to an approximated likelihood score target derived from the diffusion process.
If this is right
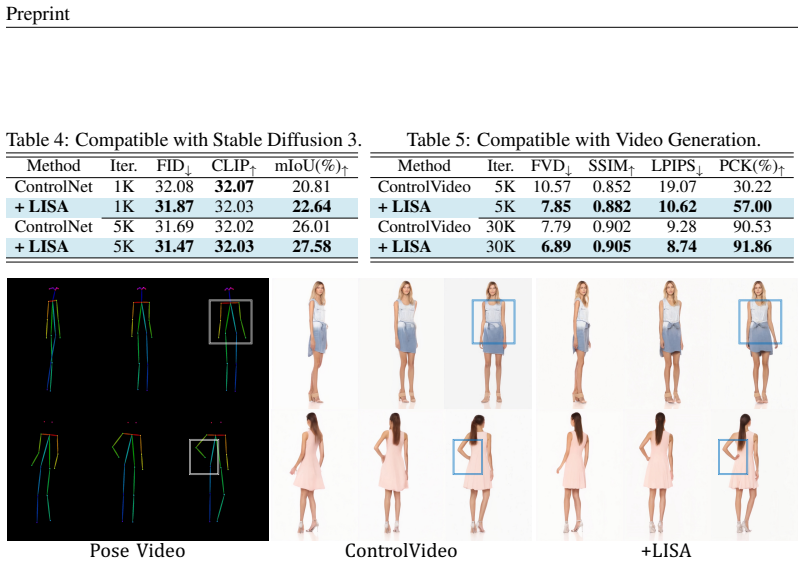
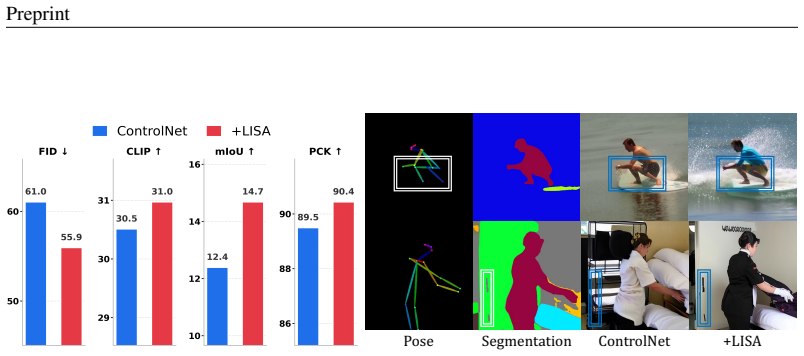
- Training convergence accelerates consistently across image and video tasks, architectures, and diffusion or flow models.
- Final synthetic image and video quality improves under visual conditioning.
- Side-network features become more disentangled, supporting better conditional modeling.
- The added cost remains negligible during training and zero at inference time.
Where Pith is reading between the lines
- The same alignment idea might extend to conditioning signals other than visual inputs if an appropriate score target can be approximated.
- More disentangled features could allow designers to shrink the side network without losing control strength.
- Varying which layer is hooked for the projection might yield further gains in efficiency or performance.
Load-bearing premise
The approximated likelihood score target constructed from the diffusion process is a faithful and stable training signal for the side-network features.
What would settle it
A controlled experiment in which the LISA regularization loss is added but training convergence does not accelerate, final results do not improve, or side features do not become more disentangled would falsify the central claim.
Figures

read the original abstract
The prevalent dual-branch paradigm, i.e., training a side network to encode visual conditions and fusing its intermediate-layer features to a frozen pretrained main network, has shown remarkable success in visual-condition controllable generation. Despite its widespread adoption, the role of the side branch and its training efficiency remain underexplored. In this paper, we first revisit this mainstream paradigm through the lens of score-based generative modeling: 1) The main network preserves visual perceptual quality by providing a prior unconditional score. 2) The side network steers conditional control by implicitly contributing a likelihood score. Guided by this perspective, we propose LIkelihood Score Alignment (LISA), an effective regularization method that explicitly aligns the intermediate feature of the side network with an approximated likelihood score. Specifically, we first hook features from a designated layer of the side network and project them into the score latent space by a lightweight decoder. Then, we construct an approximated likelihood score target and calculate the distance between the decoder's output and this target as an additional regularization loss. Finally, we jointly optimize the side network and decoder with both standard diffusion loss and our regularization loss. Experiments across various image/video tasks, architectures, and diffusion/flow models demonstrated that LISA can not only consistently accelerate the training convergence and improve final synthetic results, but also encourage the side network's features to be more disentangled for conditional modeling with negligible additional training cost and zero extra inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper revisits the dual-branch paradigm for visual-condition controllable generation in diffusion models, interpreting the frozen main network as supplying an unconditional score and the side network as implicitly contributing a likelihood score. It proposes LISA, which hooks features from a designated layer of the side network, projects them via a lightweight decoder into score space, constructs an approximated likelihood score target from the diffusion process and main-network predictions, and adds a regularization loss aligning the projected features to this target. The method is claimed to accelerate convergence, improve synthesis quality, and yield more disentangled side-network features across image/video tasks, architectures, and diffusion/flow models, at negligible training cost and zero inference overhead.
Significance. If the approximated target is shown to be a stable and faithful proxy for the conditional score contribution, LISA would supply a lightweight, theoretically motivated regularizer that improves training dynamics without architectural changes or inference cost. This could influence practice in controllable generation pipelines that rely on side networks for conditioning.
major comments (3)
- [Abstract / Method] Abstract and method description: the construction of the 'approximated likelihood score target' from the diffusion forward process, main-network predictions, and a designated layer is presented as a practical construction without a derivation establishing that it is a close proxy to the true conditional likelihood score contribution or that it remains stable across training steps and condition types; this is load-bearing because the regularization loss is justified only if the target supplies a useful rather than misaligned signal.
- [Experiments] Experiments section: the claims of accelerated convergence, improved final results, and more disentangled features rest on empirical outcomes, but no ablation isolates whether performance gains arise from the specific form of the likelihood-score target versus generic regularization or decoder capacity; without such controls the causal role of the proposed alignment remains unclear.
- [Method] Method: the paper states that the side network 'implicitly contributing a likelihood score' is an interpretive perspective, yet the regularization is derived from this view; if the perspective does not hold exactly, the added loss could amount to fitting an auxiliary quantity rather than enforcing the intended decomposition.
minor comments (2)
- [Method] Notation for the projected features and the target score should be introduced with explicit equations rather than descriptive prose to allow readers to verify the distance computation.
- [Method] The choice of 'designated layer' for feature hooking is not motivated; a brief justification or sensitivity analysis would clarify reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the construction of the 'approximated likelihood score target' from the diffusion forward process, main-network predictions, and a designated layer is presented as a practical construction without a derivation establishing that it is a close proxy to the true conditional likelihood score contribution or that it remains stable across training steps and condition types; this is load-bearing because the regularization loss is justified only if the target supplies a useful rather than misaligned signal.
Authors: The target is constructed from the explicit diffusion forward process and the unconditional score of the frozen main network, following the standard additive decomposition of conditional scores in score-based models. While no full proof of closeness to the true conditional contribution is provided, the construction is deterministic given the known noising schedule. We will revise the method section to include a detailed step-by-step derivation of the approximation and additional plots showing stability of the target across training steps and condition types. revision: partial
-
Referee: [Experiments] Experiments section: the claims of accelerated convergence, improved final results, and more disentangled features rest on empirical outcomes, but no ablation isolates whether performance gains arise from the specific form of the likelihood-score target versus generic regularization or decoder capacity; without such controls the causal role of the proposed alignment remains unclear.
Authors: We agree that isolating the specific contribution of the likelihood-score target is important. In the revision we will add ablations that replace the target with random vectors or a standard feature regression loss while keeping the decoder identical, as well as varying decoder capacity, to demonstrate that the particular form of the target drives the reported gains. revision: yes
-
Referee: [Method] Method: the paper states that the side network 'implicitly contributing a likelihood score' is an interpretive perspective, yet the regularization is derived from this view; if the perspective does not hold exactly, the added loss could amount to fitting an auxiliary quantity rather than enforcing the intended decomposition.
Authors: The manuscript already qualifies the view as interpretive. The loss is a practical regularizer motivated by that perspective rather than a claim of exact decomposition. The consistent improvements in convergence speed, sample quality, and feature disentanglement across multiple architectures and tasks provide empirical support for its utility. We will clarify the wording to emphasize the heuristic nature of the alignment. revision: partial
Circularity Check
No significant circularity; derivation is interpretive and empirically validated.
full rationale
The paper offers an interpretive lens on dual-branch diffusion models (main network as unconditional score provider, side network as implicit likelihood contributor) and then introduces LISA as a regularization that aligns projected side-network features to a constructed approximation of the likelihood score. No equations, self-citations, or derivations are exhibited that reduce the target construction, the alignment loss, or the claimed improvements to the inputs by definition. The approximation is presented as a practical engineering choice whose utility is assessed through experiments on multiple tasks, architectures, and models rather than by algebraic identity or self-referential fitting. This is the normal case of an independent empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
SPAR: Semantic-Pixel Self-Alignment and Adaptive Routing for Unified Multimodal Models
SPAR introduces semantic-pixel self-alignment via asymmetric tokenizer and adaptive routing for unified MLLMs that achieve SOTA generation and reconstruction while retaining understanding.
-
SPAR: Semantic-Pixel Self-Alignment and Adaptive Routing for Unified Multimodal Models
SPAR introduces a semantic-pixel self-alignment tokenizer and dynamic token routing to create a unified multimodal model that performs both understanding and generation at claimed state-of-the-art levels.
Reference graph
Works this paper leans on
-
[1]
Conditional image generation with score-based diffusion models.arXiv preprint arXiv:2111.13606,
Georgios Batzolis, Jan Stanczuk, Carola-Bibiane Sch ¨onlieb, and Christian Etmann. Conditional image generation with score-based diffusion models.arXiv preprint arXiv:2111.13606,
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Jog3r: Towards 3d-consistent video generators.arXiv preprint arXiv:2501.01409,
Chun-Hao Paul Huang, Niloy Mitra, Hyeonho Jeong, Jae Shin Yoon, and Duygu Ceylan. Jog3r: Towards 3d-consistent video generators.arXiv preprint arXiv:2501.01409,
-
[6]
Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Composer: Creative and controllable image synthesis with composable conditions.arXiv preprint arXiv:2302.09778,
-
[7]
Gotta go fast when generating data with score-based models.arXiv preprint arXiv:2105.14080,
Alexia Jolicoeur-Martineau, Ke Li, R ´emi Pich ´e-Taillefer, Tal Kachman, and Ioannis Mitliagkas. Gotta go fast when generating data with score-based models.arXiv preprint arXiv:2105.14080,
-
[8]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming-Chang Yang, and Jiaya Jia. Controlnext: Powerful and efficient control for image and video generation.arXiv preprint arXiv:2408.06070,
-
[13]
W¨urstchen: An efficient architecture for large-scale text-to-image diffusion models
Pablo Pernias, Dominic Rampas, Mats L Richter, Christopher Pal, and Marc Aubreville. W¨urstchen: An efficient architecture for large-scale text-to-image diffusion models. InInternational Confer- ence on Learning Representations, volume 2024, pp. 25097–25109,
2024
-
[14]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations, volume 2024, pp. 1862– 1874,
2024
-
[15]
Score-Based Generative Modeling through Stochastic Differential Equations
12 Preprint Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[16]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, and Jiang Bian. Geometry forcing: Marrying video diffusion and 3d representation for consistent world modeling.arXiv preprint arXiv:2507.07982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Articulated pose estimation with flexible mixtures-of-parts
Yi Yang and Deva Ramanan. Articulated pose estimation with flexible mixtures-of-parts. InCVPR 2011, pp. 1385–1392. IEEE,
2011
-
[20]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Polina Zablotskaia, Aliaksandr Siarohin, Bo Zhao, and Leonid Sigal. Dwnet: Dense warp-based network for pose-guided human video generation.arXiv preprint arXiv:1910.09139,
-
[22]
Endless world: Real-time 3d-aware long video generation.arXiv preprint arXiv:2512.12430,
Ke Zhang, Yiqun Mei, Jiacong Xu, and Vishal M Patel. Endless world: Real-time 3d-aware long video generation.arXiv preprint arXiv:2512.12430,
-
[23]
Controlvideo: Training-free controllable text-to-video generation
Yabo Zhang, Yuxiang Wei, XIAOPENG ZHANG, Wangmeng Zuo, Qi Tian, et al. Controlvideo: Training-free controllable text-to-video generation. InInternational Conference on Learning Rep- resentations, volume 2024, pp. 54441–54461,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.