Task-conditioned probing of instruction-tuned multimodal LLMs: Region-specific brain alignment patterns under naturalistic stimuli
Pith reviewed 2026-05-21 23:58 UTC · model grok-4.3
The pith
Instruction-tuned multimodal LLMs produce task-specific representations that align more strongly with brain activity than other models during naturalistic movie watching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
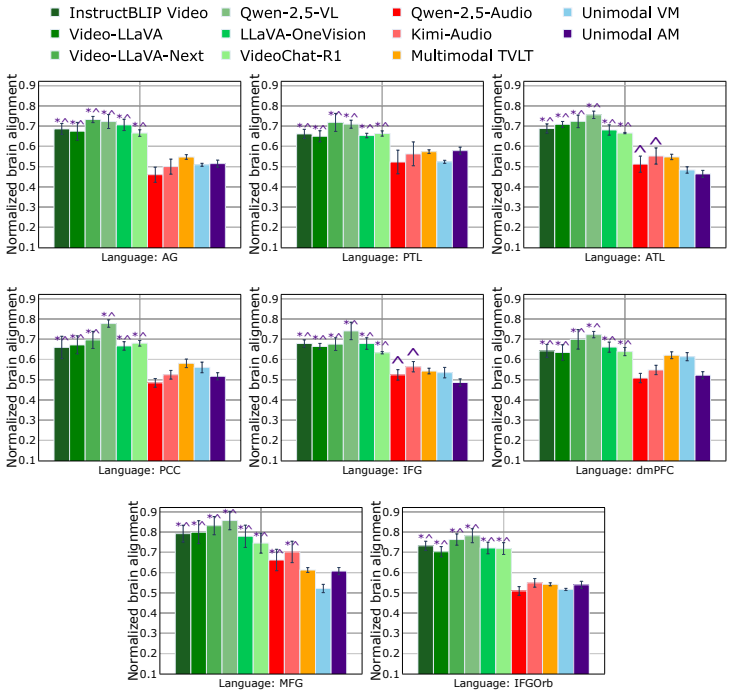
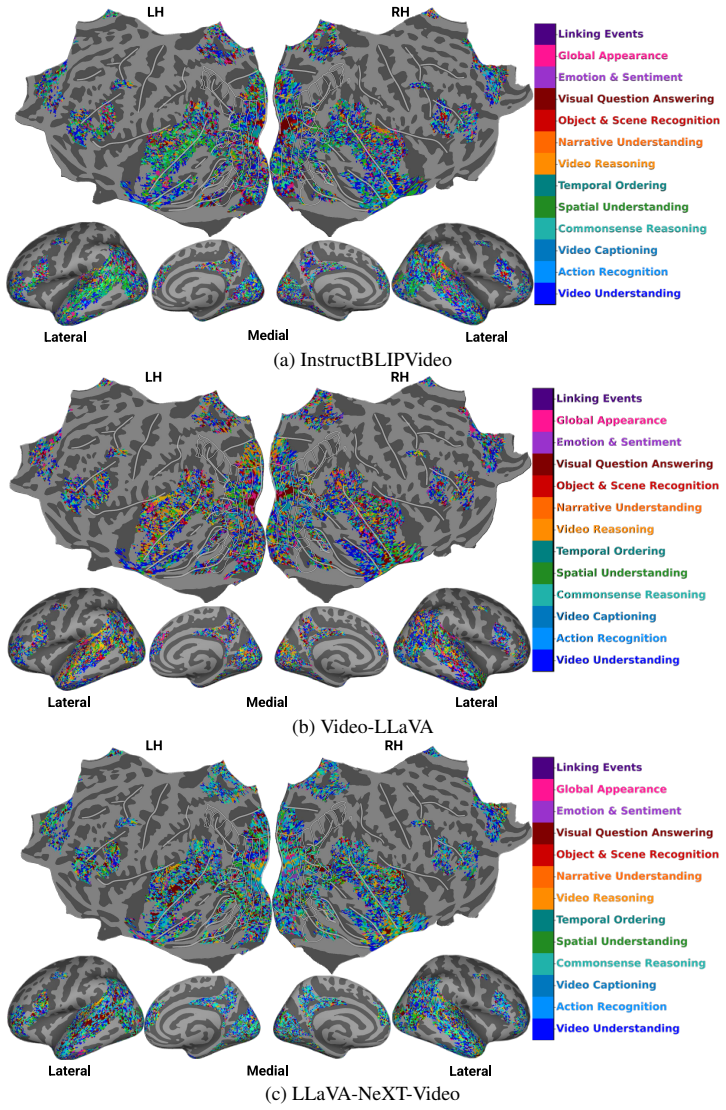
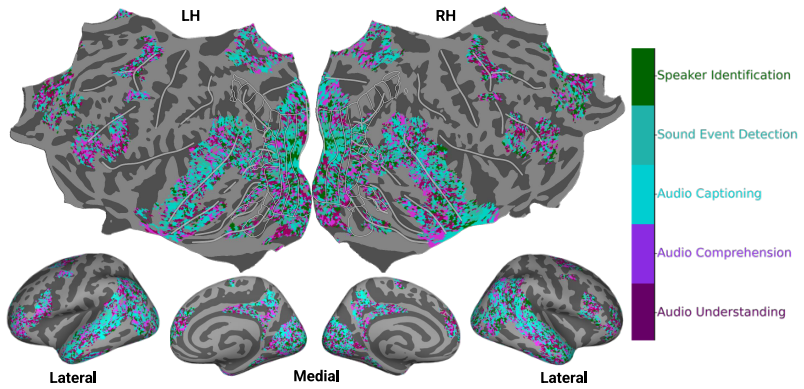
The authors demonstrate that instruction-tuned video MLLMs, when using instruction-specific embeddings across 13 video task instructions, achieve higher prediction accuracy for fMRI responses recorded during naturalistic movie watching compared to ICL multimodal models by approximately 9%, non-instruction-tuned multimodal models by 15%, and unimodal baselines by 20%. They observe that these models generate distinct task-specific representations that vary across brain regions, with IT models showing weak coupling to instruction-text semantics unlike ICL models which show strong semantic organization.
What carries the argument
Instruction-specific embeddings from instruction-tuned MLLMs under task-conditioned probing to predict voxel-wise fMRI responses.
If this is right
- Task-conditioned subspaces in IT models associate with higher brain alignment.
- IT models show weak coupling to instruction-text semantics (r=0.14) compared to strong coupling in ICL models (r=0.78).
- Distinct task-specific representations emerge across brain regions for video and audio tasks.
- Findings indicate an association between task-specific instructions and stronger brain-MLLM alignment.
Where Pith is reading between the lines
- Task conditioning in AI models could be used to create systems that more closely resemble human brain information processing.
- This approach might allow better mapping of how the brain integrates multimodal information in real-world scenarios.
- Testing the method on non-movie naturalistic stimuli could reveal if the advantages are specific to certain types of experiences.
Load-bearing premise
Differences in alignment arise specifically from instruction-tuning and task conditioning rather than from uncontrolled differences in model scale, pretraining data, or layer selection.
What would settle it
A direct comparison of instruction-tuned and non-tuned models matched for scale, pretraining data, and architecture that shows no alignment difference would falsify the role of instruction-tuning.
Figures




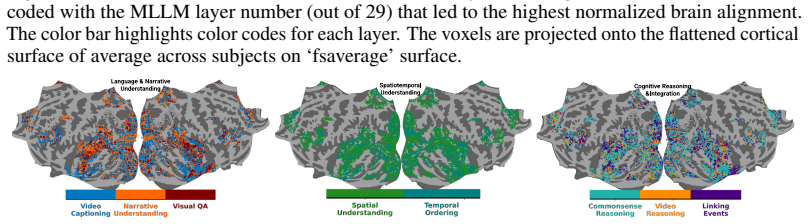












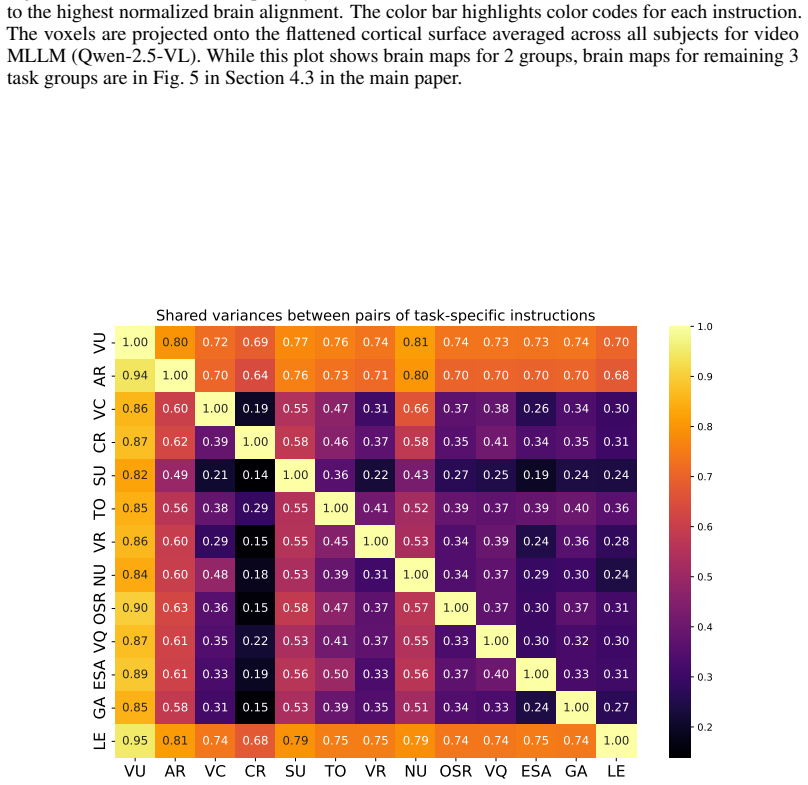

read the original abstract
Recent voxel-wise multimodal brain encoding studies have shown that multimodal large language models (MLLMs) exhibit a higher degree of brain alignment compared to unimodal models. More recently, instruction-tuned multimodal (IT) models have been shown to generate task-specific representations that align strongly with brain activity, yet most prior evaluations focus on unimodal stimuli or non-instruction-tuned models under multimodal stimuli. We still lack a clear understanding of whether instruction-tuning is associated with IT-MLLMs organizing their representations around functional task demands or if they simply reflect surface semantics. To address this, we estimate brain alignment by predicting fMRI responses recorded during naturalistic movie watching (video with audio) from MLLM representations. Using instruction-specific embeddings from six video and two audio IT-MLLMs, across 13 video task instructions, we find that instruction-tuned video MLLMs show higher brain alignment than in-context learning (ICL) multimodal models (~9%), non-instruction-tuned multimodal models (~15%), and unimodal baselines (~20%). Our evaluation of MLLMs across video and audio tasks, and language-guided probing produces distinct task-specific MLLM representations that vary across brain regions. We also find that ICL models show strong semantic organization (r=0.78), while IT models show weak coupling to instruction-text semantics (r=0.14), consistent with task-conditioned subspaces associated with higher brain alignment. These findings are consistent with an association between task-specific instructions and stronger brain-MLLM alignment, and open new avenues for mapping joint information processing in both systems. We make the code publicly available [https://github.com/subbareddy248/mllm_videos].
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instruction-tuned video MLLMs produce task-conditioned representations that align more strongly with voxel-wise fMRI responses recorded during naturalistic movie watching (video+audio) than ICL multimodal models (~9% higher), non-instruction-tuned multimodal models (~15%), or unimodal baselines (~20%). Using instruction-specific embeddings from six video and two audio IT-MLLMs across 13 task instructions, it reports that IT models exhibit weak coupling to instruction-text semantics (r=0.14) while ICL models show strong semantic organization (r=0.78), interpreting the pattern as evidence that task subspaces rather than surface semantics drive the alignment advantage. Code is released publicly.
Significance. If the central attribution to instruction-tuning survives controls, the result would indicate that IT-MLLMs organize representations around functional task demands in a manner that better matches human brain activity under naturalistic conditions, extending prior multimodal brain-encoding work and suggesting a concrete link between tuning objectives and cross-system information processing. Public code is a clear reproducibility strength.
major comments (2)
- [Results and Methods] Results (quantitative gains paragraph) and Methods (model comparison setup): the ~9–20% alignment advantages are reported without matching or covariate adjustment on parameter count, pretraining corpus size/composition, or the precise layers used for embedding extraction across IT-MLLMs versus ICL/non-IT/unimodal baselines. This is load-bearing for the claim that differences arise specifically from instruction-tuning and task conditioning rather than scale or data confounds.
- [Evaluation] Evaluation section (task-specific embeddings and probing): instruction-specific embeddings are used only for the IT models, yet no ablation or layer-wise analysis is described that isolates the contribution of tuning from the choice of embedding source or from uncontrolled architectural differences. Without this, the task-conditioned subspace interpretation cannot be cleanly separated from the listed confounds.
minor comments (2)
- [Abstract] Abstract: specify the exact statistical tests, correction procedures, and number of subjects/voxels underlying the reported percentage gains and correlation values (r=0.78, r=0.14).
- [Methods] Throughout: provide a supplementary table listing all compared models with parameter counts, layer indices, and pretraining details to support the comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help strengthen the attribution of our findings to instruction-tuning. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [Results and Methods] Results (quantitative gains paragraph) and Methods (model comparison setup): the ~9–20% alignment advantages are reported without matching or covariate adjustment on parameter count, pretraining corpus size/composition, or the precise layers used for embedding extraction across IT-MLLMs versus ICL/non-IT/unimodal baselines. This is load-bearing for the claim that differences arise specifically from instruction-tuning and task conditioning rather than scale or data confounds.
Authors: We agree that explicit controls for scale and data composition would strengthen causal attribution to instruction-tuning. Our design compared multiple representative models per category (six IT video MLLMs plus two audio IT-MLLMs against ICL, non-IT multimodal, and unimodal baselines) to reduce reliance on any single model, and the alignment advantage was consistent across this set. However, we did not perform formal matching or regression-based covariate adjustment. In revision we will add a supplementary table listing approximate parameter counts, known pretraining corpus characteristics, and the exact layer(s) chosen for each model, with justification drawn from prior brain-encoding literature on intermediate-layer optimality. We will also expand the Limitations section to note that residual scale confounds cannot be fully ruled out without larger-scale controlled experiments. revision: yes
-
Referee: [Evaluation] Evaluation section (task-specific embeddings and probing): instruction-specific embeddings are used only for the IT models, yet no ablation or layer-wise analysis is described that isolates the contribution of tuning from the choice of embedding source or from uncontrolled architectural differences. Without this, the task-conditioned subspace interpretation cannot be cleanly separated from the listed confounds.
Authors: Instruction-specific embeddings are the natural input for IT models given their training objective; for ICL and non-IT models we followed standard embedding protocols appropriate to each architecture, as stated in Methods. We acknowledge the absence of a dedicated ablation that fully disentangles instruction-tuning from architectural variation. In the revised manuscript we will include a new layer-wise analysis for a representative subset of models (one IT, one ICL, one non-IT) showing that the alignment advantage persists across multiple layers rather than being confined to a single extraction point. We will also emphasize that the observed dissociation in semantic coupling (r=0.14 for IT vs. r=0.78 for ICL) provides convergent evidence that the alignment gain is not driven by surface-level instruction semantics alone. revision: partial
Circularity Check
No significant circularity: empirical comparisons of brain alignment are self-contained
full rationale
The paper reports direct empirical measurements of voxel-wise fMRI prediction accuracy using embeddings extracted from various MLLM classes under naturalistic video stimuli. The central claim of higher alignment (~9-20%) for instruction-tuned models is presented as an observed outcome from cross-model comparisons, not as a quantity derived from an equation or parameter that is itself defined by the alignment result. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text; the evaluation relies on external model families and standard correlation metrics without reducing the task-conditioned advantage to a tautology. The derivation chain consists of standard encoding-model fitting followed by group-level statistical comparison and is therefore independent of the reported findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear regression models suffice to map MLLM embeddings to voxel-wise fMRI responses.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We utilize instruction-specific embeddings from six video and two audio instruction-tuned MLLMs... banded ridge regression... variance partitioning approach
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
instruction-tuned video MLLMs show higher brain alignment than... non-instruction-tuned multimodal models (~15%)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, August
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mae-ast: Masked autoencoding audio spectrogram transformer
Alan Baade, Puyuan Peng, and David Harwath. Mae-ast: Masked autoencoding audio spectrogram transformer. Interspeech 2022,
work page 2022
-
[3]
URL https://publications.polymtl.ca/50613/. 10 Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Colin Conwell, Jacob S Prince, Kendrick N Kay, George A Alvarez, and Talia Konkle. What can 1.8 billion regressions tell us about the pressures shaping high-level visual representation in brains and machines? bioRxiv, pp. 2022–03,
work page 2022
-
[5]
Visual representations in the human brain are aligned with large language models
Adrien Doerig, Tim C Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, and Ian Charest. Semantic scene descriptions as an objective of human vision. arXiv preprint arXiv:2209.11737,
-
[6]
Interpreting multimodal video transformers using brain recordings
Dota Tianai Dong and Mariya Toneva. Interpreting multimodal video transformers using brain recordings. In ICLR 2023 Workshop on Multimodal Representation Learning: Perks and Pitfalls, 2023a. Dota Tianai Dong and Mariya Toneva. Vision-language integration in multimodal video transformers (partially) aligns with the brain. arXiv preprint arXiv:2311.07766, 2...
-
[7]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning. arXiv preprint arXiv:2504.06958,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 5971–5984,
work page 2024
-
[10]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024),
work page 2024
-
[11]
URL https://openreview.net/forum?id=KL8Sm4xRn7. Yuko Nakagi, Takuya Matsuyama, Naoko Koide-Majima, Hiroto Yamaguchi, Rieko Kubo, Shinji Nishimoto, and Yu Takagi. Unveiling multi-level and multi-modal semantic representations in the human brain using large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Proce...
work page 2024
-
[12]
Satya Sai Srinath Namburi, Makesh Sreedhar, Srinath Srinivasan, and Frederic Sala. The cost of compression: Investigating the impact of compression on parametric knowledge in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December
work page 2023
-
[13]
Association for Computational Linguistics. URL https://aclanthology. org/2023.findings-emnlp.349/. Subba Reddy Oota, Jashn Arora, Veeral Agarwal, Mounika Marreddy, Manish Gupta, and Bapi Surampudi. Neural language taskonomy: Which nlp tasks are the most predictive of fmri brain activity? In Proceedings of the 2022 Conference of the North American Chapter ...
work page 2023
-
[14]
Jingyuan Sun, Xiaohan Zhang, and Marie-Francine Moens. Tuning in to neural encoding: Linking human brain and artificial supervised representations of language. In ECAI 2023, pp. 2258–2265. IOS Press,
work page 2023
-
[15]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Brain- wavlm: Fine-tuning speech representations with brain responses to language
Nishitha Vattikonda, Aditya R Vaidya, Richard J Antonello, and Alexander G Huth. Brain- wavlm: Fine-tuning speech representations with brain responses to language. arXiv preprint arXiv:2502.08866,
-
[17]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URL https://llava-vl.github.io/blog/2024-04-30-llava-next-video/ . 14 Overview of Appendix Sections • Appendix A: Overview of multimodal model evaluation settings in brain encoding studies • Appendix B: Related work • Appendix C: Detailed sub-ROIs of language, visual and auditory regions • Appendix D: Cross-subject prediction accuracy • Appendix E: Model ...
work page 2024
-
[19]
to predict one participant’s response from others. For every combination, one participant was randomly chosen as the target, and the model was trained to predict their brain responses using data from the remaining s − 1 participants. This gave us an average prediction score (correlation) for each voxel at each participant. To extrapolate to infinitely man...
work page 2021
-
[20]
Characters: - The character on the left is wearing a suit with a patterned tie and is holding a glass in his hand. Video reasoning The video appears to be from a scene in a movie or TV show, featuring two characters engaged in a conversation. The setting looks like a bar or a similar social environment, with dim lighting and a relaxed atmosphere. What mig...
work page 2019
-
[21]
is used for all the tests (appropriate because fMRI data is considered to have positive dependence (Genovese, 2000)). H Effectiveness of instruction-tuned video MLLMs vs audio MLLMs vs multimodal vs unimodal representations for various brain regions Fig. 8 show average normalized brain alignment of instruction-tuned video MLLMs vs instruction- tuned audio...
work page 2000
-
[22]
Engagement: The character might be trying to show interest or engagement in the conversation by leaning closer. Spatial Understanding The video appears to be from a movie or TV show set in a bar or restaurant. The setting includes a bar counter with bottles and glasses, suggesting it could be a scene from a film or series that takes place in a social or d...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.