Self-Predictive Representations for Combinatorial Generalization in Behavioral Cloning
Pith reviewed 2026-05-19 09:13 UTC · model grok-4.3
The pith
A self-predictive objective called BYOL-γ approximates successor representations to support combinatorial generalization in goal-conditioned behavior cloning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the BYOL-γ objective for goal-conditioned behavior cloning theoretically approximates the successor representation in the finite MDP case through self-predictive representations, thereby encouraging long-range temporal consistency in the learned state encoding and reducing the out-of-distribution gap for novel state-goal pairs.
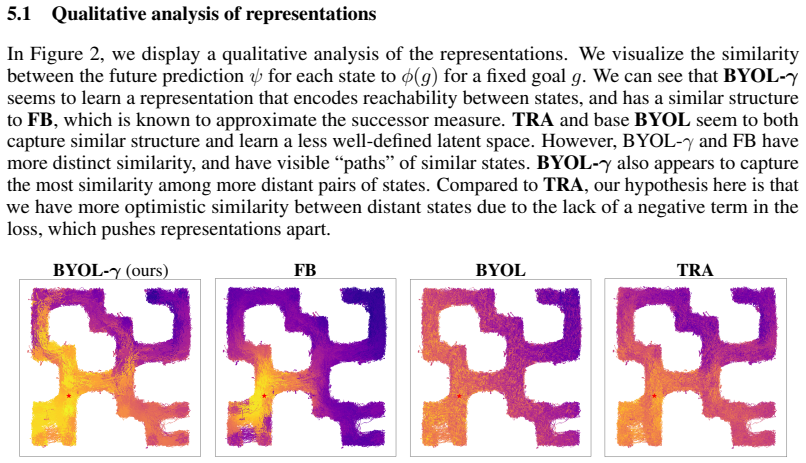
What carries the argument
BYOL-γ, a self-predictive representation learning objective that approximates the successor representation by encouraging temporally consistent encodings across future states.
If this is right
- Goal-conditioned behavior cloning can be made to generalize zero-shot to unseen combinations of states and goals by adding the BYOL-γ objective.
- Representations that encode long-range temporal consistency reduce the effective distribution shift encountered at test time.
- The method delivers competitive performance on a range of tasks that require combinatorial generalization without changing the underlying cloning loss.
- The approximation to successor representations holds exactly in finite MDPs and carries over empirically to the continuous or high-dimensional settings used in the experiments.
Where Pith is reading between the lines
- If the temporal-consistency mechanism is the main driver, similar self-prediction losses might help other imitation-learning settings that also suffer from combinatorial gaps.
- The approach suggests a practical route to importing ideas from successor representations into offline imitation without requiring explicit value-function estimation.
- One could test whether the same objective improves generalization when the goal space itself is combinatorial rather than the state-goal pairing.
Load-bearing premise
That making state representations temporally consistent via successor approximation will be enough to close the distribution gap for novel state-goal pairs in goal-conditioned behavior cloning.
What would settle it
A controlled experiment on a finite MDP where BYOL-γ is trained but the learned representations fail to produce higher success rates on held-out state-goal pairs than a plain behavior-cloning baseline.
Figures



read the original abstract
While goal-conditioned behavior cloning (GCBC) methods can perform well on in-distribution training tasks, they do not necessarily generalize zero-shot to tasks that require conditioning on novel state-goal pairs, i.e. combinatorial generalization. In part, this limitation can be attributed to a lack of temporal consistency in the state representation learned by BC; if temporally correlated states are properly encoded to similar latent representations, then the out-of-distribution gap for novel state-goal pairs would be reduced. We formalize this notion by demonstrating how encouraging long-range temporal consistency via successor representations (SR) can facilitate generalization. We then propose a simple yet effective representation learning objective, $\text{BYOL-}\gamma$ for GCBC, which theoretically approximates the successor representation in the finite MDP case through self-predictive representations, and achieves competitive empirical performance across a suite of challenging tasks requiring combinatorial generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that goal-conditioned behavior cloning (GCBC) fails to generalize zero-shot to novel state-goal pairs due to insufficient temporal consistency in learned state representations. It formalizes the benefit of long-range consistency via successor representations (SR), then introduces the BYOL-γ self-predictive objective, which is asserted to theoretically approximate the SR in the finite-MDP case, and reports competitive empirical results on tasks requiring combinatorial generalization.
Significance. If the approximation result holds under the function-approximation regimes actually used and the empirical gains are shown to be robust, the work would supply a lightweight, self-supervised route to inject temporal structure into GCBC representations, potentially narrowing the OOD gap for combinatorial tasks without requiring explicit dynamics models or additional supervision.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical section: the claim that BYOL-γ 'theoretically approximates the successor representation in the finite MDP case' is stated without an explicit derivation or fixed-point analysis; the standard BYOL fixed point equals the SR only under linear encoders or fully enumerated tabular states, yet the experiments employ deep networks on high-dimensional or continuous observations, leaving the approximation error uncharacterized and the link to reduced OOD gap for novel state-goal pairs unsupported.
- [Experiments] Empirical section: no error bars, dataset statistics, or explicit controls for post-hoc task selection are reported, so it is impossible to determine whether the 'competitive performance' on combinatorial-generalization suites is statistically reliable or could be explained by favorable task partitioning.
minor comments (2)
- [Notation] Notation for the discount parameter γ and the precise form of the BYOL-γ loss should be introduced earlier and kept consistent across the theoretical and experimental sections.
- [Introduction] The manuscript should include a short related-work paragraph contrasting BYOL-γ with prior SR approximations (e.g., linear SR, deep SR, or other self-predictive objectives) to clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below and have revised the paper accordingly to strengthen the theoretical presentation and empirical reporting.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical section: the claim that BYOL-γ 'theoretically approximates the successor representation in the finite MDP case' is stated without an explicit derivation or fixed-point analysis; the standard BYOL fixed point equals the SR only under linear encoders or fully enumerated tabular states, yet the experiments employ deep networks on high-dimensional or continuous observations, leaving the approximation error uncharacterized and the link to reduced OOD gap for novel state-goal pairs unsupported.
Authors: We agree that an explicit derivation strengthens the claim. In the revised manuscript we add a dedicated subsection deriving the fixed point of the BYOL-γ objective for finite MDPs under tabular representations and showing equivalence to the successor representation. For the function-approximation regime used in the experiments we acknowledge that the approximation error remains uncharacterized in general; we have added a limitations paragraph discussing this gap and emphasizing that the theoretical result is intended to motivate the objective rather than to guarantee performance under arbitrary deep encoders. The empirical link to improved combinatorial generalization is supported by the reported results, which we now accompany with additional analysis of representation similarity across temporally distant states. revision: yes
-
Referee: [Experiments] Empirical section: no error bars, dataset statistics, or explicit controls for post-hoc task selection are reported, so it is impossible to determine whether the 'competitive performance' on combinatorial-generalization suites is statistically reliable or could be explained by favorable task partitioning.
Authors: We accept this criticism. The revised version includes error bars computed over multiple random seeds for all quantitative results, a table of dataset statistics (number of trajectories, state-goal pair coverage, etc.), and an explicit statement of the task-partitioning procedure together with a sensitivity check that varies the held-out combinations. These additions make the reliability of the reported gains transparent. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper motivates the use of successor representations to encourage temporal consistency for better combinatorial generalization in GCBC, then proposes BYOL-γ as a self-predictive objective that is claimed to approximate SR under finite-MDP assumptions. This is presented as a theoretical derivation separate from the empirical evaluation on challenging tasks. No load-bearing step reduces by construction to a fitted parameter, self-definition, or unverified self-citation chain; the approximation claim is stated as a first-principles result for the tabular case, with experiments serving as independent validation. The derivation remains self-contained against external benchmarks like standard SR definitions and BC baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- gamma
axioms (1)
- domain assumption Finite MDP setting is sufficient for the theoretical approximation of successor representations by self-prediction.
Forward citations
Cited by 2 Pith papers
-
Multi-scale Predictive Representations for Goal-conditioned Reinforcement Learning
Ms.PR applies multi-scale predictive supervision to enforce goal-directed alignment in latent spaces for offline GCRL, yielding improved representation quality and performance on vision and state-based tasks.
-
Improving Zero-Shot Offline RL via Behavioral Task Sampling
Extracting task vectors from the offline dataset for policy training improves zero-shot offline RL performance by an average of 20% over random sampling baselines.
Reference graph
Works this paper leans on
-
[1]
Successor Features for Transfer in Reinforcement Learning
André Barreto, Will Dabney, Rémi Munos, Jonathan J Hunt, Tom Schaul, Hado P van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. Advances in neural information processing systems, 30, 2017. URL https://arxiv.org/abs/1606.05312. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
arXiv preprint arXiv:2101.07123 , year=
Léonard Blier, Corentin Tallec, and Yann Ollivier. Learning successor states and goal-dependent values: A mathematical viewpoint, 2021. URL https://arxiv.org/abs/2101.07123. 1, 2, 3, C
-
[3]
When does return-conditioned supervised learning work for offline reinforcement learning? In Alice H
David Brandfonbrener, Alberto Bietti, Jacob Buckman, Romain Laroche, and Joan Bruna. When does return-conditioned supervised learning work for offline reinforcement learning? In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id= XByg4kotW5. 2
work page 2022
-
[4]
Walk in the cloud: Learning curves for point clouds shape analysis, pp
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9630–9640, 2021. doi: 10.1109/ICCV48922.2021.00951. 4.2
-
[5]
Tomov, William de Cothi, Caswell Barry, and Samuel J
Wilka Carvalho, Momchil S. Tomov, William de Cothi, Caswell Barry, and Samuel J. Gershman. Predictive representations: Building blocks of intelligence. Neural Computation, 36(11):2225– 2298, 10 2024. ISSN 0899-7667. doi: 10.1162/neco_a_01705. URL https://doi.org/10. 1162/neco_a_01705. 2
-
[6]
Representations and exploration for deep reinforcement learning using singular value decomposition
Yash Chandak, Shantanu Thakoor, Zhaohan Daniel Guo, Yunhao Tang, Remi Munos, Will Dabney, and Diana L Borsa. Representations and exploration for deep reinforcement learning using singular value decomposition. In International Conference on Machine Learning, pages 4009–4034. PMLR, 2023. URL https://arxiv.org/abs/2305.00654. D.1
-
[7]
Ian Char, Viraj Mehta, Adam Villaflor, John M. Dolan, and Jeff Schneider. Bats: Best action trajectory stitching, 2022. URL https://arxiv.org/abs/2204.12026. 2
-
[8]
Decision transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021. URL https://openreview...
work page 2021
-
[9]
Dynamo: In- domain dynamics pretraining for visuo-motor control
Zichen Jeff Cui, Hengkai Pan, Aadhithya Iyer, Siddhant Haldar, and Lerrel Pinto. Dynamo: In- domain dynamics pretraining for visuo-motor control. In The Thirty-eighth Annual Conference on Neural Information Processing Systems , 2024. URL https://arxiv.org/abs/2409. 12192. 2
work page 2024
-
[10]
Improving Generalization for Temporal Difference Learning : The Successor Representation
Peter Dayan. Improving generalization for temporal difference learning: The successor rep- resentation. Neural Computation, 5(4):613–624, 1993. doi: 10.1162/neco.1993.5.4.613. 2, 3
-
[11]
Scott Emmons, Benjamin Eysenbach, Ilya Kostrikov, and Sergey Levine. Rvs: What is essential for offline RL via supervised learning? In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=S874XAIpkR-. 2 10
work page 2022
-
[12]
Contrastive learning as goal-conditioned reinforcement learning
Benjamin Eysenbach, Tianjun Zhang, Sergey Levine, and Russ R Salakhutdinov. Contrastive learning as goal-conditioned reinforcement learning. Advances in Neural Information Process- ing Systems, 35:35603–35620, 2022. 3.1, 5
work page 2022
-
[13]
Proto-value networks: Scaling representa- tion learning with auxiliary tasks
Jesse Farebrother, Joshua Greaves, Rishabh Agarwal, Charline Le Lan, Ross Goroshin, Pablo Samuel Castro, and Marc G Bellemare. Proto-value networks: Scaling representa- tion learning with auxiliary tasks. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=oGDKSt9JrZi. 2
work page 2023
-
[14]
Combined Reinforcement Learning via Abstract Representations
Vincent François-Lavet, Yoshua Bengio, Doina Precup, and Joelle Pineau. Combined rein- forcement learning via abstract representations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 3582–3589, 2019. URL https://arxiv.org/abs/ 1809.04506. 2
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
Quentin Garrido, Mahmoud Assran, Nicolas Ballas, Adrien Bardes, Laurent Najman, and Yann LeCun. Learning and leveraging world models in visual representation learning, 2024. URL https://arxiv.org/abs/2403.00504. 3.1
-
[16]
DeepMDP: Learning Continuous Latent Space Models for Representation Learning
Carles Gelada, Saurabh Kumar, Jacob Buckman, Ofir Nachum, and Marc G Bellemare. Deepmdp: Learning continuous latent space models for representation learning. In Inter- national conference on machine learning , pages 2170–2179. PMLR, 2019. URL https: //arxiv.org/abs/1906.02736. 2, 3.1
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Quan Vuong, Ted Xiao, Pannag R. Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. In Robotics: Science and Systems, 2024. URL htt...
-
[18]
Closing the gap between TD learning and supervised learning - a generalisation point of view
Raj Ghugare, Matthieu Geist, Glen Berseth, and Benjamin Eysenbach. Closing the gap between TD learning and supervised learning - a generalisation point of view. In The Twelfth International Conference on Learning Representations, 2024. URL https://arxiv.org/ abs/2401.11237. 1, 2, 3.2, 3.2
-
[19]
Bootstrap your own latent: A new approach to self-supervised learn- ing
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020. URL https://arxiv.org/abs/ ...
-
[20]
Bootstrap latent-predictive representations for multitask reinforcement learning
Zhaohan Daniel Guo, Bernardo Avila Pires, Bilal Piot, Jean-Bastien Grill, Florent Altché, Remi Munos, and Mohammad Gheshlaghi Azar. Bootstrap latent-predictive representations for multitask reinforcement learning. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of M...
work page 2020
-
[21]
Temporal difference learning for model predictive control
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predictive control. In International Conference on Machine Learning (ICML) , 2022. URL https: //arxiv.org/abs/2203.04955. 2
-
[22]
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, You...
work page 2024
-
[23]
A unifying framework for action-conditional self-predictive reinforcement learning
Khimya Khetarpal, Zhaohan Daniel Guo, Bernardo Avila Pires, Yunhao Tang, Clare Lyle, Mark Rowland, Nicolas Heess, Diana L Borsa, Arthur Guez, and Will Dabney. A unifying framework for action-conditional self-predictive reinforcement learning. In The 28th International Con- ference on Artificial Intelligence and Statistics, 2025. URL https://arxiv.org/abs/...
work page 2025
-
[24]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Open- VLA: An open-source vision-language-action model. In 8th Annual Conference on Robot Lear...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations , 2022. URL https: //arxiv.org/abs/2110.06169. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [26]
-
[27]
A path towards autonomous machine intelligence version, 2022
Yann LeCun. A path towards autonomous machine intelligence version, 2022. URL https: //openreview.net/forum?id=BZ5a1r-kVsf. 3.1
work page 2022
-
[28]
GTA: Generative trajectory augmen- tation with guidance for offline reinforcement learning
Jaewoo Lee, Sujin Yun, Taeyoung Yun, and Jinkyoo Park. GTA: Generative trajectory augmen- tation with guidance for offline reinforcement learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=kZpNDbZrzy. 2
work page 2024
-
[29]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems, 2020. URL https://arxiv.org/abs/ 2005.01643. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
Metric residual network for sample efficient goal-conditioned reinforcement learning
Bo Liu, Yihao Feng, Qiang Liu, and Peter Stone. Metric residual network for sample efficient goal-conditioned reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 8799–8806, 2023. URL https://arxiv.org/abs/2208. 08133. 2
work page 2023
-
[31]
Ball, Yee Whye Teh, and Jack Parker-Holder
Cong Lu, Philip J. Ball, Yee Whye Teh, and Jack Parker-Holder. Synthetic experience replay. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https: //openreview.net/forum?id=6jNQ1AY1Uf. 2
work page 2023
-
[32]
Mishra, Yilun Du, and Danfei Xu
Yunhao Luo, Utkarsh A. Mishra, Yilun Du, and Danfei Xu. Generative trajectory stitching through diffusion composition, 2025. URL https://arxiv.org/abs/2503.05153. 2
-
[33]
Arjun Majumdar, Karmesh Yadav, Sergio Arnaud, Yecheng Jason Ma, Claire Chen, Sneha Silwal, Aryan Jain, Vincent-Pierre Berges, Tingfan Wu, Jay Vakil, Pieter Abbeel, Jitendra Malik, Dhruv Batra, Yixin Lin, Oleksandr Maksymets, Aravind Rajeswaran, and Franziska Meier. Where are we in the search for an artificial visual cortex for embodied intelligence? In Th...
-
[34]
Vivek Myers, Chongyi Zheng, Anca Dragan, Sergey Levine, and Benjamin Eysenbach. Learning temporal distances: Contrastive successor features can provide a metric structure for decision- making. In Forty-first International Conference on Machine Learning, 2024. URL https: //openreview.net/forum?id=xQiYCmDrjp. 2 12
work page 2024
-
[35]
Horizon Generalization in Reinforcement Learning
Vivek Myers, Catherine Ji, and Benjamin Eysenbach. Horizon Generalization in Reinforcement Learning. In International Conference on Learning Representations , January 2025. URL https://arxiv.org/pdf/2501.02709. 2
-
[36]
Vivek Myers, Bill Chunyuan Zheng, Anca Dragan, Kuan Fang, and Sergey Levine. Tempo- ral representation alignment: Successor features enable emergent compositionality in robot instruction following, 2025. URL https://arxiv.org/abs/2502.05454. 1, 2, 4, 5, A.5
-
[37]
R3M: A Universal Visual Representation for Robot Manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhi Gupta. R3m: A universal visual representation for robot manipulation. In Conference on Robot Learning, 2022. URL https://arxiv.org/abs/2203.12601. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Bridging state and history representations: Understanding self-predictive rl
Tianwei Ni, Benjamin Eysenbach, Erfan Seyedsalehi, Michel Ma, Clement Gehring, Aditya Mahajan, and Pierre-Luc Bacon. Bridging state and history representations: Understanding self-predictive rl. In The Twelfth International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2401.08898. 2, 3.1
-
[39]
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, Albert Tung, Alex Bewley, Alex Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anchit Gupta, Andrew Wang, Anikait Singh, Animesh Garg, Aniruddha Kembhavi, Annie Xie, Anthony Brohan, Antonin Raffin, Arc...
work page 2024
-
[40]
doi: 10.1109/ICRA57147.2024.10611477. 1
-
[41]
Ogbench: Benchmarking offline goal-conditioned rl
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl. In International Conference on Learning Representations (ICLR),
-
[43]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Interna- tional Conference on Machine Learning, 2021. URL https://arxiv.org/abs/2103.00020. A.3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Masked visual pre-training for motor control.arXiv preprint arXiv:2203.06173, 2022
Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learning with masked visual pre-training. In 6th Annual Conference on Robot Learning, 2022. URL https://arxiv.org/abs/2203.06173. 2
-
[45]
Reinforcement learning upside down: Don’t predict rewards – just map them to actions, 2020
Juergen Schmidhuber. Reinforcement learning upside down: Don’t predict rewards – just map them to actions, 2020. URL https://arxiv.org/abs/1912.02875. 2
-
[46]
D., Courville, A., and Bachman, P
Max Schwarzer, Ankesh Anand, Rishab Goel, R. Devon Hjelm, Aaron C. Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations. In International Conference on Learning Representations, 2020. URL https://arxiv.org/ abs/2007.05929. 1, 2, 3.1, 4.2
- [47]
-
[48]
Yunhao Tang, Zhaohan Daniel Guo, Pierre H. Richemond, Bernardo Ávila Pires, Yash Chandak, Rémi Munos, Mark Rowland, Mohammad Gheshlaghi Azar, Charline Le Lan, Clare Lyle, Andr’as Gyorgy, Shantanu Thakoor, Will Dabney, Bilal Piot, Daniele Calandriello, and M. Va´lko. Understanding self-predictive learning for reinforcement learning. In International Confer...
-
[49]
Ahmed Touati, Jérémy Rapin, and Yann Ollivier. Does zero-shot reinforcement learning exist? In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=MYEap_OcQI. 3.1, 4, A.4, C, D.1
work page 2023
-
[50]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding, 2019. URL https://arxiv.org/abs/1807.03748. 1, 3.1
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[51]
V oelcker, Tyler Kastner, Igor Gilitschenski, and Amir-massoud Farahmand
Claas A. V oelcker, Tyler Kastner, Igor Gilitschenski, and Amir-massoud Farahmand. When does self-prediction help? understanding auxiliary tasks in reinforcement learning. Reinforcement Learning Conference, August 2024. URL https://arxiv.org/abs/2406.17718. 2
-
[52]
Tongzhou Wang and Phillip Isola. Improved representation of asymmetrical distances with interval quasimetric embeddings. In NeurIPS 2022 Workshop on Symmetry and Geometry in Neural Representations, 2022. URL https://arxiv.org/abs/2211.15120. 2
-
[53]
Optimal goal-reaching reinforcement learning via quasimetric learning
Tongzhou Wang, Antonio Torralba, Phillip Isola, and Amy Zhang. Optimal goal-reaching reinforcement learning via quasimetric learning. In International Conference on Machine Learning. PMLR, 2023. URL https://arxiv.org/abs/2304.01203. 2, 5
-
[54]
Taku Yamagata, Ahmed Khalil, and Raúl Santos-Rodríguez. Q-learning decision transformer: leveraging dynamic programming for conditional sequence modelling in offline rl. In Proceed- ings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023. 1, 2 14
work page 2023
-
[55]
Mastering atari games with limited data
Weirui Ye, Shaohuai Liu, Thanard Kurutach, Pieter Abbeel, and Yang Gao. Mastering atari games with limited data. Advances in neural information processing systems, 34:25476–25488,
- [56]
-
[57]
Zhaoyi Zhou, Chuning Zhu, Runlong Zhou, Qiwen Cui, Abhishek Gupta, and Simon Shaolei Du. Free from bellman completeness: Trajectory stitching via model-based return-conditioned supervised learning. In The Twelfth International Conference on Learning Representations,
-
[58]
URL https://arxiv.org/abs/2310.19308. 2 15 A Experimental Setup Table 3: Hyperparameters for BYOL-γ Hyperparameter Shared actor head MLP (512,512,512) representation encoder (ϕ) MLP (64,64,64) predictor (ψ) MLP (64,64,64) encoder ensemble 2 learning rate 3 × 10−4 optimizer Adam Non-visual Visual Gradient steps 1000k 500k Batch size 1024 256 τ (EMA) 1.0 0....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.