Safe-SAIL: Towards a Fine-grained Safety Landscape of Large Language Models via Sparse Autoencoder Interpretation Framework
Pith reviewed 2026-05-18 18:09 UTC · model grok-4.3
The pith
Safe-SAIL introduces a pre-explanation metric to select sparse autoencoders that best reveal safety features in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
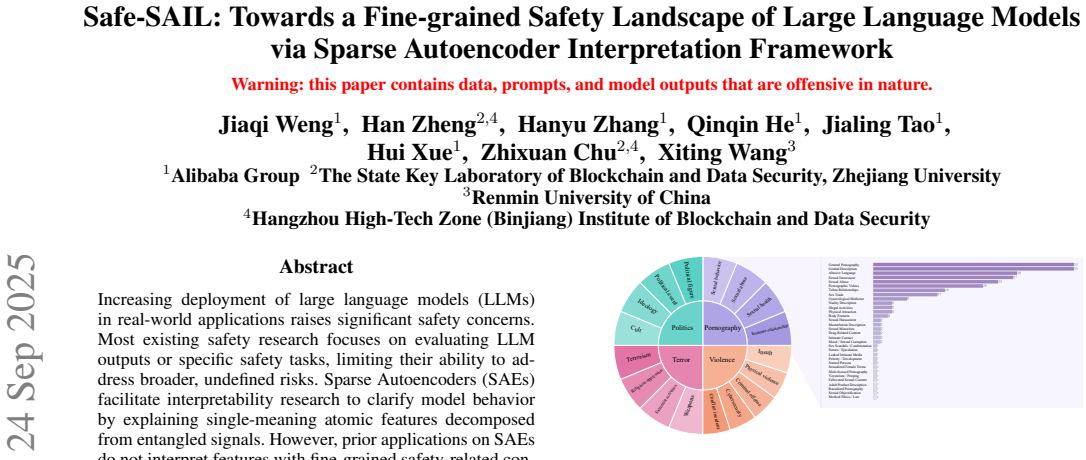
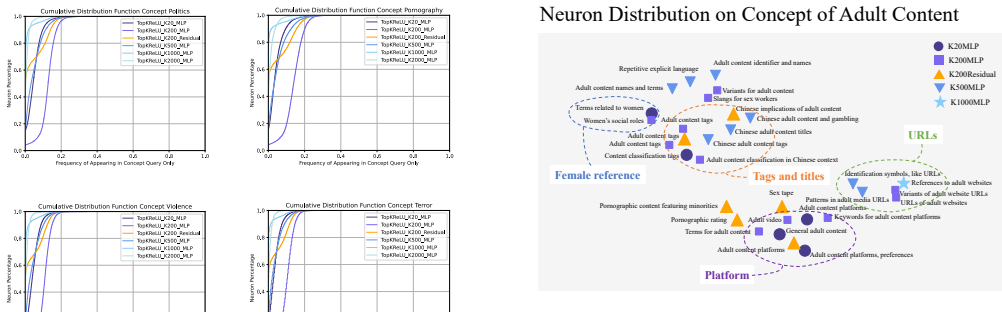
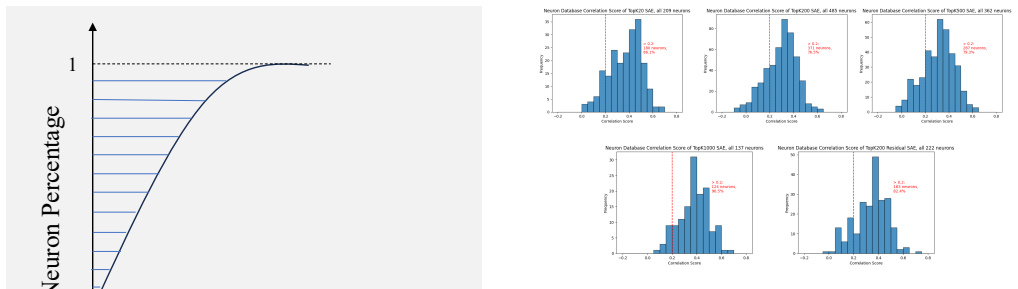
Safe-SAIL establishes a pre-explanation evaluation metric to rank SAEs by their potential for safety-specific features and employs segment-level simulation to lower the cost of detailed feature explanations by 55%. Using the framework, a suite of SAEs is trained with human-readable explanations for 1758 features in four safety domains, allowing empirical insights into risk feature identification and the encoding of safety-critical entities across model layers.
What carries the argument
The pre-explanation evaluation metric that ranks SAEs for safety-domain interpretability before any full feature explanation is performed.
If this is right
- SAEs with the strongest safety interpretability can be identified without performing full explanations on all candidates.
- The segment-level simulation strategy reduces the cost of producing human-readable safety feature explanations by 55 percent.
- A public collection of 1758 explained and evaluated safety features across four domains becomes available for further study.
- Empirical observations can be made about which layers most strongly encode particular safety-critical entities and concepts.
- The released toolkit enables systematic risk-feature identification in additional large language models.
Where Pith is reading between the lines
- The same pre-ranking approach could be adapted to identify interpretable features for other low-frequency domains such as scientific reasoning or legal reasoning.
- Layer-wise patterns revealed by the explained features may indicate the most effective points for inserting safety constraints during inference.
- The open collection of labeled safety features could serve as a benchmark for testing whether new SAE training methods improve safety coverage.
- If the metric generalizes, it could reduce the barrier to building mechanistic safety audits for models trained on new data distributions.
Load-bearing premise
The pre-explanation evaluation metric can correctly predict which SAEs will produce high-quality safety features without first running the costly full explanation on every candidate.
What would settle it
Run the pre-explanation metric on a held-out collection of SAEs, fully explain the top-ranked and bottom-ranked ones, and check whether the top-ranked set actually produces more accurate or useful safety features than the bottom-ranked set.
Figures











read the original abstract
Sparse autoencoders (SAEs) enable interpretability research by decomposing entangled model activations into monosemantic features. However, under what circumstances SAEs derive most fine-grained latent features for safety, a low-frequency concept domain, remains unexplored. Two key challenges exist: identifying SAEs with the greatest potential for generating safety domain-specific features, and the prohibitively high cost of detailed feature explanation. In this paper, we propose Safe-SAIL, a unified framework for interpreting SAE features in safety-critical domains to advance mechanistic understanding of large language models. Safe-SAIL introduces a pre-explanation evaluation metric to efficiently identify SAEs with strong safety domain-specific interpretability, and reduces interpretation cost by 55% through a segment-level simulation strategy. Building on Safe-SAIL, we train a comprehensive suite of SAEs with human-readable explanations and systematic evaluations for 1,758 safety-related features spanning four domains: pornography, politics, violence, and terror. Using this resource, we conduct empirical analyses and provide insights on the effectiveness of Safe-SAIL for risk feature identification and how safety-critical entities and concepts are encoded across model layers. All models, explanations, and tools are publicly released in our open-source toolkit and companion product.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Safe-SAIL, a unified framework for interpreting SAE features in safety-critical domains of LLMs. It introduces a pre-explanation evaluation metric to efficiently identify SAEs with strong safety domain-specific interpretability and a segment-level simulation strategy claimed to reduce interpretation costs by 55%. The authors train SAEs and generate human-readable explanations with systematic evaluations for 1,758 safety-related features across four domains (pornography, politics, violence, terror), conduct empirical analyses on risk feature identification and layer-wise encoding of safety concepts, and publicly release all models, explanations, and tools.
Significance. If the pre-explanation metric is shown to correlate with actual feature quality, the framework could meaningfully lower barriers to scalable safety interpretability research. The public release of a large annotated set of 1,758 explained safety features and associated tools is a clear strength that supports reproducibility and further community work on mechanistic understanding of safety concepts in LLMs.
major comments (2)
- [Section describing the pre-explanation evaluation metric (likely §3 or §4)] The pre-explanation evaluation metric is load-bearing for the efficiency claim, yet the manuscript provides no quantitative validation (e.g., Spearman rank correlation or precision@K) showing that metric rankings align with the quality of the subsequent full human explanations or downstream safety-feature monosemanticity for the selected SAEs.
- [Section on the segment-level simulation strategy and cost analysis] The 55% cost reduction via segment-level simulation is presented as a central contribution, but the paper does not detail the baseline (full per-feature explanation cost), the exact per-segment savings, or whether the reduction was measured on an independent hold-out set versus the same 1,758 features used for the final analyses.
minor comments (2)
- [Abstract] The abstract states that empirical analyses were conducted but supplies no quantitative highlights (e.g., key accuracy numbers, layer-wise trends, or comparison to baselines), which would help readers assess the strength of the reported insights.
- [Methods section] Clarify the exact definition and components of the pre-explanation metric (activation statistics, reconstruction loss on safety prompts, etc.) with an equation or pseudocode to avoid ambiguity in how it avoids the full explanation step.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps improve the clarity and rigor of our presentation of Safe-SAIL. Below we respond point-by-point to the major comments, proposing specific revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Section describing the pre-explanation evaluation metric (likely §3 or §4)] The pre-explanation evaluation metric is load-bearing for the efficiency claim, yet the manuscript provides no quantitative validation (e.g., Spearman rank correlation or precision@K) showing that metric rankings align with the quality of the subsequent full human explanations or downstream safety-feature monosemanticity for the selected SAEs.
Authors: We appreciate this observation. The pre-explanation metric was developed as an efficient proxy based on activation statistics over safety-related prompts and a domain-specific interpretability score derived from feature sparsity and relevance. Although the original manuscript does not report direct quantitative validation such as Spearman rank correlation or precision@K between metric rankings and post-explanation quality or monosemanticity, the SAEs prioritized by the metric produced coherent human-readable explanations that supported the subsequent empirical analyses. To strengthen this claim, we will add a dedicated validation subsection in the revised manuscript that computes Spearman correlations and precision@K on a held-out subset of features, directly comparing metric rankings against explanation fidelity and downstream monosemanticity measures. revision: yes
-
Referee: [Section on the segment-level simulation strategy and cost analysis] The 55% cost reduction via segment-level simulation is presented as a central contribution, but the paper does not detail the baseline (full per-feature explanation cost), the exact per-segment savings, or whether the reduction was measured on an independent hold-out set versus the same 1,758 features used for the final analyses.
Authors: We agree that greater transparency on the cost analysis is warranted. The baseline corresponds to the average human effort (time and resources) for complete per-feature explanations, established through pilot studies. The segment-level simulation approximates full explanations by focusing on representative segments, yielding the reported 55% reduction. This calculation was performed on the features explained in the study. In the revision we will explicitly define the baseline, report per-segment time savings with supporting measurements, and clarify that while the primary figure derives from the main set of 1,758 features, we will include results from an independent hold-out set to confirm generalizability of the savings. revision: yes
Circularity Check
Empirical framework with pre-explanation metric; no load-bearing circularity in derivation
full rationale
The paper presents Safe-SAIL as an empirical framework that trains SAEs, generates explanations for 1,758 safety features across four domains, and reports a 55% cost reduction via segment-level simulation. The pre-explanation evaluation metric is introduced to rank SAEs for safety interpretability prior to full labeling. No equations or self-citations are shown that define the metric in terms of the final explanations or reduce the cost-saving claim to a fitted parameter on the same data. The work is described as self-contained with public artifact release, satisfying the criteria for a low circularity score. The central claims rest on reported training and evaluation steps rather than definitional equivalence or self-referential justification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders decompose entangled activations into monosemantic features suitable for safety concepts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Safe-SAIL, a Sparse Autoencoder Interpretation Framework... pre-explanation evaluation metric... segment-level simulation strategy... 1,758 safety-related features spanning four domains
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Why Does Reinforcement Learning Generalize? A Feature-Level Mechanistic Study of Post-Training in Large Language Models
RL generalizes better than SFT by preserving and slowly evolving a compact set of task-agnostic features from the base model rather than introducing many specialized ones.
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Anthropic . 2025. Claude 3.7 Sonnet and Claude Code
work page 2025
-
[4]
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Baker, B.; Huizinga, J.; Gao, L.; Dou, Z.; Guan, M. Y.; Madry, A.; Zaremba, W.; Pachocki, J.; and Farhi, D. 2025. Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation. arXiv:2503.11926
work page internal anchor Pith review arXiv 2025
-
[5]
Bills, S.; Cammarata, N.; Mossing, D.; Tillman, H.; Gao, L.; Goh, G.; Sutskever, I.; Leike, J.; Wu, J.; and Saunders, W. 2023. Language models can explain neurons in language models. URL https://openaipublic. blob. core. windows. net/neuron-explainer/paper/index. html.(Date accessed: 14.05. 2023), 2
work page 2023
-
[6]
E.; Hume, T.; Carter, S.; Henighan, T.; and Olah, C
Bricken, T.; Templeton, A.; Batson, J.; Chen, B.; Jermyn, A.; Conerly, T.; Turner, N.; Anil, C.; Denison, C.; Askell, A.; Lasenby, R.; Wu, Y.; Kravec, S.; Schiefer, N.; Maxwell, T.; Joseph, N.; Hatfield-Dodds, Z.; Tamkin, A.; Nguyen, K.; McLean, B.; Burke, J. E.; Hume, T.; Carter, S.; Henighan, T.; and Olah, C. 2023. Towards Monosemanticity: Decomposing L...
work page 2023
- [7]
- [8]
-
[9]
Chacko, S. J.; Biswas, S.; Islam, C. M.; Liza, F. T.; and Liu, X. 2024. Adversarial Attacks on Large Language Models Using Regularized Relaxation. arXiv:2410.19160
-
[10]
D.; Steinhardt, J.; and Schwettmann, S
Choi, D.; Huang, V.; Meng, K.; Johnson, D. D.; Steinhardt, J.; and Schwettmann, S. 2024. Scaling Automatic Neuron Description. https://transluce.org/neuron-descriptions
work page 2024
-
[11]
Cunningham, H.; Ewart, A.; Riggs, L.; Huben, R.; and Sharkey, L. 2023. Sparse Autoencoders Find Highly Interpretable Features in Language Models. arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; Zhang, X.; Yu, X.; Wu, Y.; Wu, Z. F.; Gou, Z.; Shao, Z.; Li, Z.; Gao, Z.; Liu, A.; Xue, B.; Wang, B.; Wu, B.; Feng, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; Ruan, C.; Dai, D.; Chen, D.; Ji, D.; Li, E.; Lin, F.; Dai, F.; Luo, F.; Hao, G.; Chen, G.; ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Gallegos, I. O.; Rossi, R. A.; Barrow, J.; Tanjim, M. M.; Kim, S.; Dernoncourt, F.; Yu, T.; Zhang, R.; and Ahmed, N. K. 2024. Bias and Fairness in Large Language Models: A Survey. arXiv:2309.00770
-
[15]
Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; Presser, S.; and Leahy, C. 2020. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv:2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[16]
Scaling and evaluating sparse autoencoders
Gao, L.; la Tour, T. D.; Tillman, H.; Goh, G.; Troll, R.; Radford, A.; Sutskever, I.; Leike, J.; and Wu, J. 2024. Scaling and evaluating sparse autoencoders. arXiv preprint arXiv:2406.04093
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Hanu, L.; and Unitary team . 2020. Detoxify. Github. https://github.com/unitaryai/detoxify
work page 2020
- [19]
-
[20]
Karvonen, A.; Rager, C.; Lin, J.; Tigges, C.; Bloom, J.; Chanin, D.; Lau, Y.-T.; Farrell, E.; McDougall, C.; Ayonrinde, K.; Till, D.; Wearden, M.; Conmy, A.; Marks, S.; and Nanda, N. 2025. SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability. arXiv:2503.09532
-
[21]
Karvonen, A.; Wright, B.; Rager, C.; Angell, R.; Brinkmann, J.; Smith, L.; Verdun, C. M.; Bau, D.; and Marks, S. 2024. Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models. arXiv:2408.00113
-
[22]
Lees, A.; Tran, V. Q.; Tay, Y.; Sorensen, J.; Gupta, J.; Metzler, D.; and Vasserman, L. 2022. A New Generation of Perspective API: Efficient Multilingual Character-level Transformers. arXiv:2202.11176
- [23]
-
[24]
Lieberum, T.; Rajamanoharan, S.; Conmy, A.; Smith, L.; Sonnerat, N.; Varma, V.; Kramár, J.; Dragan, A.; Shah, R.; and Nanda, N. 2024. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2. arXiv:2408.05147
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [25]
-
[26]
Qwen; :; Yang, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Li, C.; Liu, D.; Huang, F.; Wei, H.; Lin, H.; Yang, J.; Tu, J.; Zhang, J.; Yang, J.; Yang, J.; Zhou, J.; Lin, J.; Dang, K.; Lu, K.; Bao, K.; Yang, K.; Yu, L.; Li, M.; Xue, M.; Zhang, P.; Zhu, Q.; Men, R.; Lin, R.; Li, T.; Tang, T.; Xia, T.; Ren, X.; Ren, X.; Fan, Y.; Su, Y.; Zhang, Y.; Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Qwen Team . 2025. QwQ-32B: Embracing the Power of Reinforcement Learning
work page 2025
-
[28]
Rajamanoharan, S.; Lieberum, T.; Sonnerat, N.; Conmy, A.; Varma, V.; Kramár, J.; and Nanda, N. 2024. Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders. arXiv:2407.14435
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
-
[30]
Xu, Z.; Huang, R.; Chen, C.; and Wang, X. 2025. Uncovering safety risks of large language models through concept activation vector. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24. Red Hook, NY, USA: Curran Associates Inc. ISBN 9798331314385
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.