Recognition: 2 theorem links
· Lean TheoremOn the Overscaling Curse of Parallel Thinking: System Efficacy Contradicts Sample Efficiency
Pith reviewed 2026-05-16 10:35 UTC · model grok-4.3
The pith
Sample-specific budget prediction from latent states resolves the overscaling curse in parallel LLM thinking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the overscaling curse arises because a single global sampling budget chosen to maximize dataset accuracy necessarily over-allocates paths to many individual samples whose accuracy saturates earlier; this contradiction between system efficacy and sample efficiency can be broken by a Latent Budget Predictor (LanBo) that reads latent representations to assign sample-specific budgets, thereby improving utilization without accuracy loss and supporting a Pre-decoding Budget Adaptation (PreAda) scheme that allocates budgets before decoding begins.
What carries the argument
Latent Budget Predictor (LanBo), a module that probes internal model representations to forecast the smallest number of parallel paths required for each input to reach its individual accuracy peak.
If this is right
- Overall budget utilization rises while dataset-level accuracy stays constant.
- Pre-decoding allocation becomes possible, preserving full parallelization during the generation phase.
- Hardware metrics improve in both end-to-end latency and peak memory consumption.
- The same predictor can be dropped into existing multi-path decoding pipelines without retraining the base model.
Where Pith is reading between the lines
- Internal states appear to encode per-input reasoning difficulty or convergence rate, which could be exploited by other adaptive sampling schemes.
- The method may generalize to chain-of-thought or tree-of-thought variants where path count also trades off against accuracy.
- Production deployments could realize direct cost savings by avoiding over-sampling on the large fraction of easy inputs.
- Combining the predictor with early-stopping rules during generation might yield further efficiency gains.
Load-bearing premise
Model latent representations already contain enough information to predict the sample-specific optimal budget accurately without any extra labeled data or tuning steps that would themselves consume the budget being saved.
What would settle it
Measure the correlation between LanBo-predicted budgets and the true minimal budgets found by exhaustive per-sample search on a held-out test set; if accuracy falls when the predicted budgets replace the oracle budgets, the central claim is falsified.
Figures























read the original abstract
Parallel thinking improves LLM reasoning through multi-path sampling and aggregation. In standard evaluations, due to a lack of sample-specific priors, all samples share a global budget chosen to maximize dataset accuracy. However, many samples reach their best accuracy with much smaller budgets, causing low budget utilization. This contradiction between system efficacy and sample efficiency constitutes the Overscaling Curse. In this paper, we first provide a formal analysis of the overscaling curse and quantify its prevalence and severity in real-world systems. To break it, we propose Latent Budget Predictor (LanBo), which probes model latent representations to predict sample-specific optimal budgets. LanBo significantly improves budget utilization while maintaining dataset accuracy. We further integrate LanBo into the full decoding pipeline, inspiring Pre-decoding Budget Adaptation (PreAda), a paradigm that allocates budgets before decoding to preserve decoding-time parallelization. LanBo substantially improves hardware-aware efficiency in latency and memory, demonstrating both its practical value and the promise of LanBo for efficient parallel decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies the 'Overscaling Curse' in parallel thinking for LLMs, where a global budget for multi-path sampling maximizes dataset accuracy but yields low utilization because many samples saturate at much smaller per-sample budgets. It proposes the Latent Budget Predictor (LanBo) that probes model latent representations to predict sample-specific optimal budgets, integrates this into Pre-decoding Budget Adaptation (PreAda) to allocate budgets before decoding, and reports gains in budget utilization, latency, and memory while preserving dataset accuracy.
Significance. If the empirical claims hold, the work offers a practical route to reconcile system-level and sample-level efficiency in parallel reasoning methods such as self-consistency. The formal analysis of the curse, the pre-decoding paradigm, and hardware-aware metrics constitute clear strengths that could influence efficient deployment of multi-path techniques.
major comments (2)
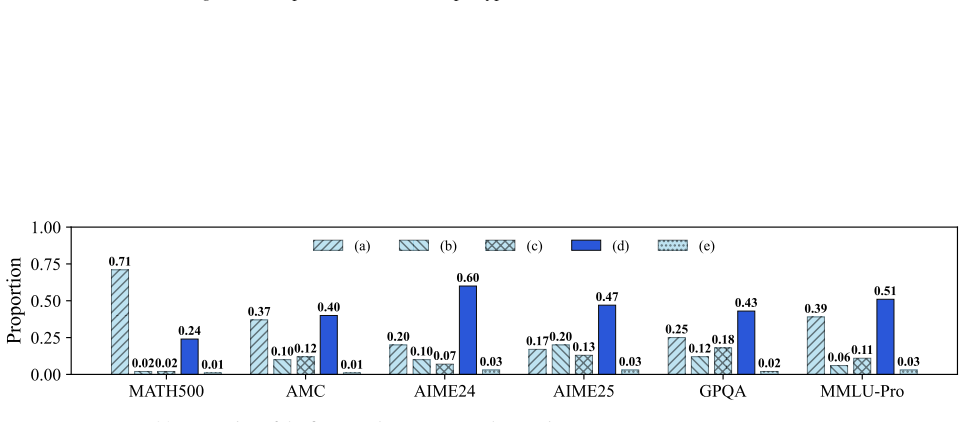
- [§3.2] §3.2 (LanBo training protocol): the supervision signal for optimal per-sample budgets is not specified. If labels are obtained via exhaustive per-sample sweeps over budget values, the pre-computation cost must be measured and shown to be amortized or negligible; otherwise the net efficiency gain is unclear.
- [§5.1, Table 2] §5.1, Table 2 (utilization results): the reported utilization improvement depends on LanBo prediction accuracy, yet no error analysis (e.g., fraction of over- or under-predictions, MAE on budget) is provided. Without this, it is impossible to determine whether gains arise from latent information or from test-set characteristics.
minor comments (2)
- [Figure 3] Figure 3 (latency/memory plots): axis labels and legend entries are too small for readability; enlarge fonts and add error bars if multiple runs were performed.
- [§2.1] Notation: the symbol B* for optimal budget is introduced without an explicit equation; add a short definition in §2.1 for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our work. We address the major comments point by point below, and we will incorporate the suggested clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (LanBo training protocol): the supervision signal for optimal per-sample budgets is not specified. If labels are obtained via exhaustive per-sample sweeps over budget values, the pre-computation cost must be measured and shown to be amortized or negligible; otherwise the net efficiency gain is unclear.
Authors: We appreciate this observation. The supervision signal for LanBo is derived from per-sample sweeps on a validation set to determine the smallest budget achieving maximum accuracy for each sample. We acknowledge that the pre-computation cost was not explicitly quantified in the original submission. In the revision, we will report the time required for these sweeps and demonstrate that it is amortized over repeated use of the model on similar data distributions, leading to net efficiency gains. We will also discuss how this cost compares to the savings in inference time. revision: yes
-
Referee: [§5.1, Table 2] §5.1, Table 2 (utilization results): the reported utilization improvement depends on LanBo prediction accuracy, yet no error analysis (e.g., fraction of over- or under-predictions, MAE on budget) is provided. Without this, it is impossible to determine whether gains arise from latent information or from test-set characteristics.
Authors: We agree that providing an error analysis is important to substantiate the source of the gains. In the revised manuscript, we will add an analysis including the Mean Absolute Error (MAE) between predicted and optimal budgets, the percentages of over-predictions and under-predictions, and an ablation study comparing LanBo to random budget assignment. This will clarify that the improvements are due to the predictive power of the latent representations rather than inherent properties of the test set. revision: yes
Circularity Check
No circularity: LanBo prediction from latents is independent of the accuracy metric it targets
full rationale
The paper's core claim is a formal analysis of the overscaling curse followed by a proposal to predict per-sample budgets from existing model latent representations. No equations in the provided text define the predictor output in terms of the accuracy or utilization it is meant to improve, nor do any steps reduce a 'prediction' to a fitted input by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming is smuggled through citations. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Latent Budget Predictor (LanBo)
no independent evidence
-
Pre-decoding Budget Adaptation (PreAda)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LanBo probes model latent representations to predict sample-specific optimal budgets... trainable layer-wise estimators ϕθl(h(l)T(x))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Overscaling Index MD = N*D / ND; five sample types based on monotonicity of Ax(N)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with llms
Aggarwal, P., Madaan, A., Yang, Y ., et al. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with llms. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12375–12396,
work page 2023
-
[3]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Brown, B., Juravsky, J., Ehrlich, R., Clark, R., Le, Q. V ., Ré, C., and Mirhoseini, A. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[5]
Parallel scaling law for language models
Chen, M., Hui, B., Cui, Z., Yang, J., Liu, D., Sun, J., Lin, J., and Liu, Z. Parallel scaling law for language models. arXiv preprint arXiv:2505.10475, 2025a. Chen, X., Xu, J., Liang, T., He, Z., Pang, J., Yu, D., Song, L., Liu, Q., Zhou, M., Zhang, Z., et al. Do not think that much for 2+ 3=? on the overthinking of long reasoning models. InForty-second I...
-
[6]
Dong, H., Brandfonbrener, D., Helenowski, E., He, Y ., Ku- mar, M., Fang, H., Chi, Y ., and Sankararaman, K. A. Generalized parallel scaling with interdependent genera- tions.arXiv preprint arXiv:2510.01143, 2025a. Dong, Z., Zhou, Z., Liu, Z., Yang, C., and Lu, C. Emergent response planning in llms.arXiv preprint arXiv:2502.06258, 2025b. Fan, A., Lewis, M...
-
[7]
Fu, Y ., Wang, X., Tian, Y ., and Zhao, J. Deep think with confidence.arXiv preprint arXiv:2508.15260,
work page internal anchor Pith review arXiv
- [8]
-
[9]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
L., Liu, Y ., Shang, N., Sun, Y ., Zhu, Y ., Yang, F., and Yang, M
Guan, X., Zhang, L. L., Liu, Y ., Shang, N., Sun, Y ., Zhu, Y ., Yang, F., and Yang, M. rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519,
-
[11]
He, Z., Liang, T., Xu, J., Liu, Q., Chen, X., Wang, Y ., Song, L., Yu, D., Liang, Z., Wang, W., et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
The Curious Case of Neural Text Degeneration
Holtzman, A., Buys, J., Du, L., Forbes, M., and Choi, Y . The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[15]
C., Choukse, E., and Ustiugov, D
Hong, C., Guo, X., Singh, A. C., Choukse, E., and Ustiugov, D. Slim-sc: Thought pruning for efficient scaling with self-consistency. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 34488–34505,
work page 2025
-
[16]
Kang, Z., Zhao, X., and Song, D. Scalable best-of-n selec- tion for large language models via self-certainty.arXiv preprint arXiv:2502.18581,
-
[17]
Li, B., Zhang, D., Wu, J., Yin, W., Tao, Z., Zhao, Y ., Zhang, L., Shen, H., Fang, R., Xie, P., et al. Parallelmuse: Agen- tic parallel thinking for deep information seeking.arXiv preprint arXiv:2510.24698, 2025a. Li, Y ., Yuan, P., Feng, S., Pan, B., Wang, X., Sun, B., Wang, H., and Li, K. Escape sky-high cost: Early-stopping self-consistency for multi-s...
-
[18]
Li, Y ., Gu, Q., Wen, Z., Li, Z., Xing, T., Guo, S., Zheng, T., Zhou, X., Qu, X., Zhou, W., et al. Treepo: Bridging the gap of policy optimization and efficacy and inference effi- ciency with heuristic tree-based modeling.arXiv preprint arXiv:2508.17445, 2025b. Liang, T., He, Z., Jiao, W., Wang, X., Wang, Y ., Wang, R., Yang, Y ., Shi, S., and Tu, Z. Enco...
-
[19]
Muennighoff, N., Yang, Z., Shi, W., Li, X
URL https://maa.org/ maa-invitational-competitions/. Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Candès, E., and Hashimoto, T. B. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 20286– 20332,
work page 2025
-
[20]
Ning, X., Lin, Z., Zhou, Z., Wang, Z., Yang, H., and Wang, Y . Skeleton-of-thought: Prompting llms for efficient parallel generation.arXiv preprint arXiv:2307.15337,
-
[21]
Rodionov, G., Garipov, R., Shutova, A., Yakushev, G., Schultheis, E., Egiazarian, V ., Sinitsin, A., Kuznedelev, D., and Alistarh, D. Hogwild! inference: Parallel llm generation via concurrent attention.arXiv preprint arXiv:2504.06261,
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Layer by Layer: Uncovering Hidden Representations in Language Models
Skean, O., Arefin, M. R., Zhao, D., Patel, N., Naghiyev, J., LeCun, Y ., and Shwartz-Ziv, R. Layer by layer: Uncov- ering hidden representations in language models.arXiv preprint arXiv:2502.02013,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Wang, H., Xiong, W., Xie, T., Zhao, H., and Zhang, T. Inter- pretable preferences via multi-objective reward modeling and mixture-of-experts.arXiv preprint arXiv:2406.12845, 2024a. Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., and Wei, F. Improving text embeddings with large language models. InProceedings of the 62nd Annual Meeting of the Associa...
-
[27]
Make every penny count: Difficulty-adaptive self-consistency for cost-efficient rea- soning
10 Breaking the Overscaling Curse: Thinking Parallelism Before Parallel Thinking Wang, X., Feng, S., Li, Y ., Yuan, P., Zhang, Y ., Tan, C., Pan, B., Hu, Y ., and Li, K. Make every penny count: Difficulty-adaptive self-consistency for cost-efficient rea- soning. InFindings of the Association for Computational Linguistics: NAACL 2025, pp. 6904–6917, 2025a....
-
[28]
Sequence-to-Sequence Learning as Beam-Search Optimization
Wiseman, S. and Rush, A. M. Sequence-to-sequence learning as beam-search optimization.arXiv preprint arXiv:1606.02960,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
Wu, T., Liu, Y ., Bai, J., Jia, Z., Zhang, S., Lin, Z., Wang, Y ., Zhu, S.-C., and Zheng, Z. Native parallel reasoner: Reasoning in parallelism via self-distilled reinforcement learning.arXiv preprint arXiv:2512.07461,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Xiong, M., Hu, Z., Lu, X., Li, Y ., Fu, J., He, J., and Hooi, B. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, X., An, Y ., Liu, H., Chen, T., and Chen, B. Multiverse: Your language models secretly decide how to parallelize and merge generation.arXiv preprint arXiv:2506.09991, 2025b. Yao, S., Yu,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Limo: Less is more for reasoning
Ye, Y ., Huang, Z., Xiao, Y ., Chern, E., Xia, S., and Liu, P. Limo: Less is more for reasoning.arXiv preprint arXiv:2502.03387,
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Zeng, W., He, K., Kuang, C., Li, X., and He, J. Pushing test-time scaling limits of deep search with asymmetric verification.arXiv preprint arXiv:2510.06135,
-
[36]
Zhang, D., Huang, X., Zhou, D., Li, Y ., and Ouyang, W. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b.arXiv preprint arXiv:2406.07394,
-
[37]
Zheng, T., Zhang, H., Yu, W., Wang, X., Dai, R., Liu, R., Bao, H., Huang, C., Huang, H., and Yu, D. Parallel- r1: Towards parallel thinking via reinforcement learning. arXiv preprint arXiv:2509.07980,
-
[38]
11 Breaking the Overscaling Curse: Thinking Parallelism Before Parallel Thinking A. Related Work A.1. Parallel Thinking Parallel thinking is a test-time scaling paradigm that mainly consists of two stages:exploratory samplingandanswer generation(Li et al., 2025a). In the first stage, the most brute-force strategy is stochastic methods, where each reasonin...
work page 2022
-
[39]
increases the effective lookahead by maintaining multiple hypotheses at each decoding step. Other strategies, such as Tree-of-Thought (ToT) (Yao et al., 2023), Skeleton-of-Thought (SoT) (Ning et al., 2023), and Monte Carlo Tree Search (MCTS) (Zhang et al., 2024; Guan et al., 2025; Li et al., 2025b; Ding et al., 2025), build on stochastic rollouts or struc...
work page 2023
-
[40]
aims to enhance reasoning performance by increasing computation at inference time. This paradigm follows two main research directions (Muennighoff et al., 2025):sequential scalingandparallel scaling. Sequential scaling focuses on extending the length of a single chain-of-thought to induce slower, more deliberate thinking, thereby eliciting cognitive mecha...
work page 2025
-
[41]
that increase the likelihood of reaching the correct answer, through RL (Shao et al., 2024; Guo et al., 2025; Yu et al., 2025), SFT (Muennighoff et al., 2025; Ye et al., 2025; Yang et al., 2025a), or inference-time prompt forcing (Muennighoff et al., 2025; Wang et al., 2025c). Parallel scaling corresponds to parallel thinking, which is discussed in detail...
work page 2024
-
[42]
In the original paper, w= 4 , k= 32 , and L= 40
In Stage 3, using the stopping point as a threshold, DSC draws one sample for each easier question, while for harder questions it adaptively increases the budget by doubling the number of w-sample blocks, up to a maximum of L samples. In the original paper, w= 4 , k= 32 , and L= 40 . We adopt the same settings in our implementation. DeepConf (Fu et al., 2...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.