Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key
Pith reviewed 2026-05-20 22:32 UTC · model grok-4.3
The pith
Reinforcement learning can overcome long-horizon reasoning limits in LLMs when trained on sufficiently expressive logics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
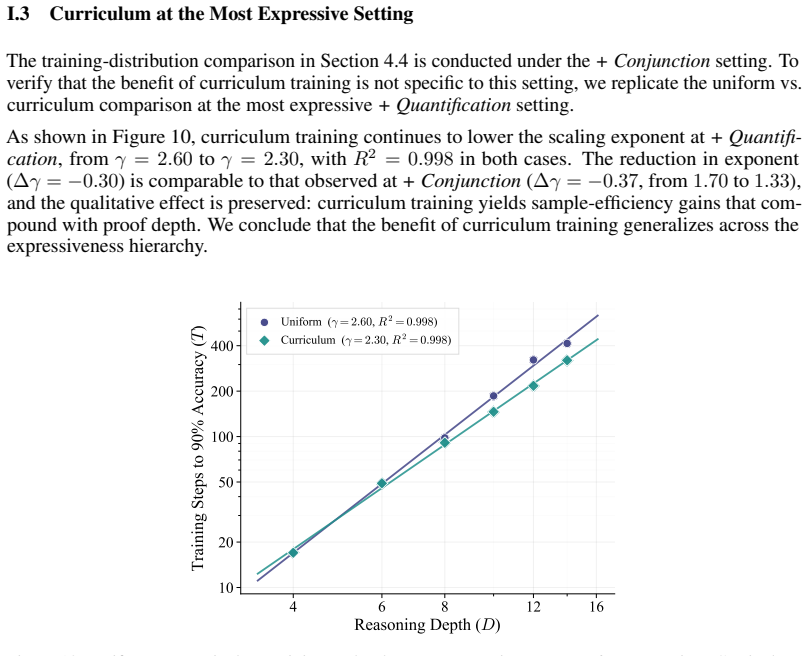
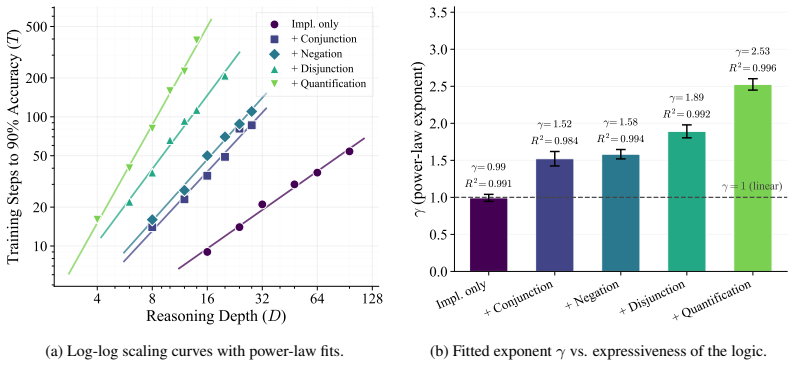
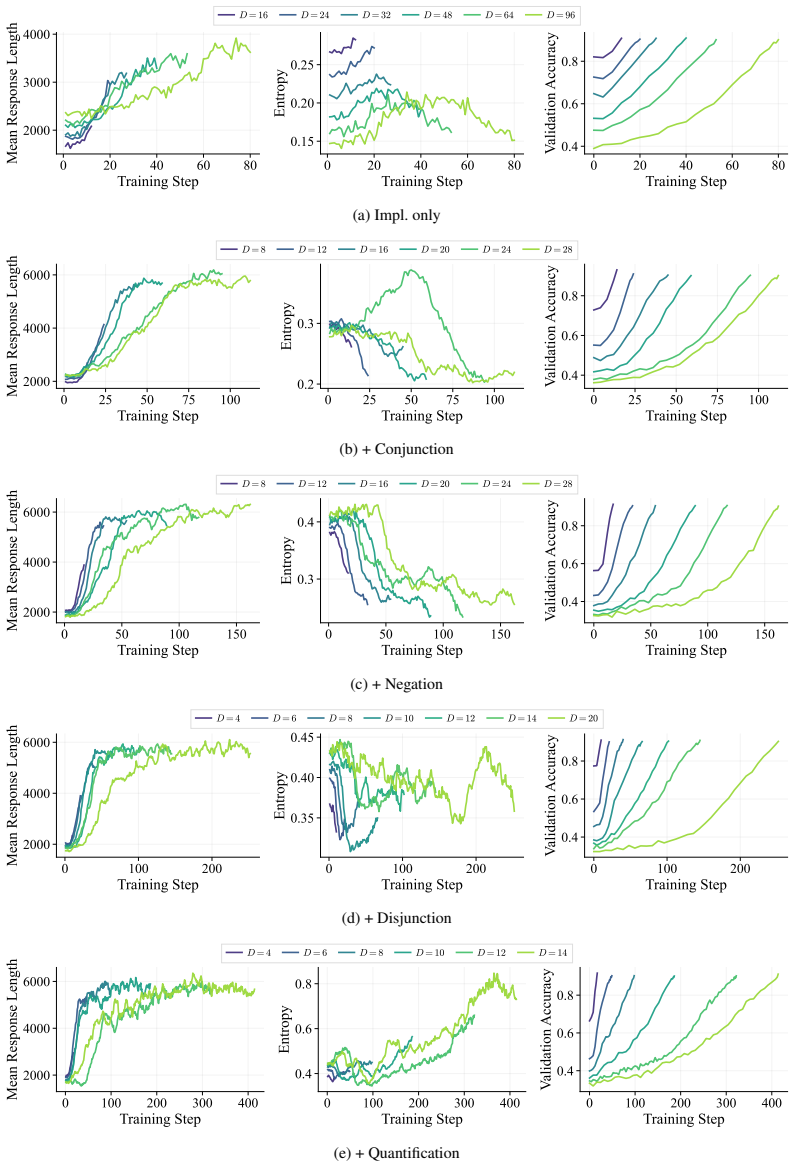
ScaleLogic provides independent control over reasoning depth and logical expressiveness, spanning from simple implication to first-order logic with and, or, not, and for-all. RL training compute scales as a power law with depth whose exponent increases monotonically from 1.04 to 2.60 as expressiveness grows. Higher-expressiveness training yields gains up to 10.66 points on downstream benchmarks and more compute-efficient transfer, while the power-law relation holds across RL methods and curriculum training improves scaling efficiency. The results establish that LLM shortcomings in long-horizon reasoning are not fundamental to the transformer architecture and can be addressed by improved data
What carries the argument
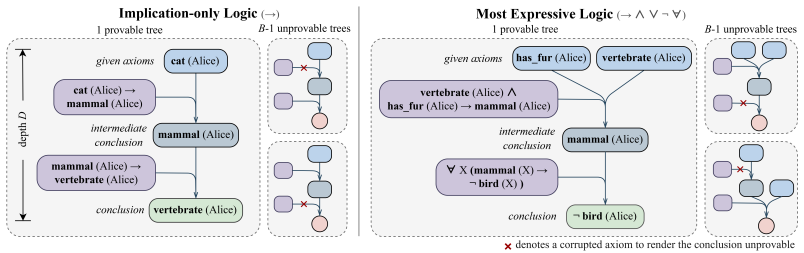
ScaleLogic, a synthetic logical reasoning environment that independently varies proof-planning depth from the expressiveness of the underlying logic (simple implication to full first-order with conjunction, disjunction, negation, and universal quantification).
If this is right
- Training compute follows a power law with reasoning depth across multiple RL methods.
- More expressive logical training produces larger performance gains on mathematics and general reasoning benchmarks.
- Curriculum-based training improves scaling efficiency for greater reasoning depths.
- The character of the training data, not merely its volume, determines how effectively skills transfer to new tasks.
Where Pith is reading between the lines
- If the synthetic scaling patterns hold outside the lab, curricula that gradually increase logical expressiveness could optimize compute allocation for complex sequential problems.
- The same controlled-variation approach could be applied to study scaling in adjacent areas such as multi-step planning or program synthesis.
- Prioritizing richer logical structures during data construction might lessen reliance on architectural modifications for stronger long-horizon performance.
Load-bearing premise
Performance improvements measured inside the controlled synthetic ScaleLogic tasks will transfer to and predict gains on real-world long-horizon reasoning problems.
What would settle it
Apply the same high-expressiveness RL training to a held-out collection of multi-step real-world tasks such as complex math word problems or planning scenarios and observe whether downstream accuracy fails to exceed that of low-expressiveness training.
Figures




















read the original abstract
Reinforcement learning (RL) has been applied to improve large language model (LLM) reasoning, yet the systematic study of how training scales with task difficulty has been hampered by the lack of controlled, scalable environments. Observed LLM shortcomings in long-horizon reasoning have raised the prospect that they are fundamental to the autoregressive transformer architecture. To address this, we introduce ScaleLogic, a synthetic logical reasoning framework that offers independent control over two axes of difficulty: the depth of the required proof planning (i.e., the horizon) and the expressiveness of the underlying logic. Our proposed framework supports a wide range of logics: from simple implication-only logic ("if-then") towards more expressive first-order reasoning with conjunction ("and"), disjunction ("or"), negation ("not"), and universal quantification ("for all"). Using this framework, we show that the RL training compute $T$ follows a power law with respect to reasoning depth $D$ ($T \propto D^{\gamma}$, $R^{2} > 0.99$), and that the scaling exponent $\gamma$ increases monotonically with logical expressiveness, from $1.04$ to $2.60$. On downstream mathematics and general reasoning benchmarks, more expressive training settings yield both larger performance gains (up to $+10.66$ points) and more compute-efficient transfer compared to less expressive settings, demonstrating that what a model is trained on, not just how much it is trained, shapes downstream transfer. We further show that the power-law relationship holds across multiple RL methods, and curriculum-based training substantially improves scaling efficiency. More broadly, our results demonstrate that LLM shortcomings in long-horizon reasoning are not fundamental to the underlying architecture, and can be addressed by improved training methodology and data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScaleLogic, a synthetic logical reasoning framework that independently varies proof depth (horizon) and logical expressiveness (from implication-only to full FOL with quantifiers). It reports that RL training compute T scales as a power law with depth D (T ∝ D^γ, R² > 0.99), that the exponent γ rises monotonically from 1.04 to 2.60 with increasing expressiveness, and that more expressive training yields larger downstream gains (up to +10.66 points) and better compute-efficient transfer on mathematics and general reasoning benchmarks. The central claim is that long-horizon reasoning deficits are not fundamental to autoregressive transformers and can be addressed through improved training methodology and data; the power-law relationship is shown to hold across multiple RL methods and to improve under curriculum training.
Significance. If the empirical scaling laws and transfer results hold under rigorous controls, the work would provide a valuable controlled testbed for studying how training data expressiveness affects long-horizon reasoning scaling, offering evidence against purely architectural explanations of LLM limitations. The reproducible power-law fits across RL methods and the curriculum improvement are concrete strengths that could inform future data-curation strategies.
major comments (3)
- [Abstract / Results] Abstract and methods (inferred from reported fits): the power-law claim T ∝ D^γ with R² > 0.99 is presented without specifying the number of depth points fitted, the regression procedure (ordinary least squares on log-log or otherwise), error bars on γ, or controls for confounding factors such as total tokens or model size; this makes it impossible to assess whether the reported monotonic increase in γ with expressiveness is robust or sensitive to fitting choices.
- [Abstract] Abstract: the downstream transfer gains of up to +10.66 points and 'more compute-efficient transfer' are reported without naming the exact benchmarks, the base model sizes, the number of runs, or any statistical significance tests; without these details the claim that expressiveness shapes transfer more than compute volume cannot be evaluated for load-bearing status.
- [Abstract / Conclusion] Abstract / Discussion: the conclusion that shortcomings 'are not fundamental to the underlying architecture' rests on transfer from ScaleLogic to real-world mathematics and reasoning benchmarks, yet the manuscript supplies no analysis of how closely those benchmarks match the controlled depth and expressiveness axes or whether gains survive distribution shift to noisy, open-ended problems.
minor comments (2)
- [Abstract] Notation: the scaling exponent is introduced as γ but later referenced in the abstract as both γ and the 'scaling exponent'; consistent symbol use would improve readability.
- [Abstract] The abstract states that the power-law 'holds across multiple RL methods' but does not list which methods were tested; adding this enumeration would clarify the generality claim.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify important points of clarification that will improve the accessibility and rigor of the presentation. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and methods (inferred from reported fits): the power-law claim T ∝ D^γ with R² > 0.99 is presented without specifying the number of depth points fitted, the regression procedure (ordinary least squares on log-log or otherwise), error bars on γ, or controls for confounding factors such as total tokens or model size; this makes it impossible to assess whether the reported monotonic increase in γ with expressiveness is robust or sensitive to fitting choices.
Authors: We agree that the abstract would benefit from these details to allow readers to evaluate the robustness of the reported scaling. The regressions were performed via ordinary least squares on log-log coordinates using the depth points shown in the main figures; model size was held fixed and total training tokens were controlled by adjusting episode count per depth. In the revision we will state the number of fitted points, the regression method, and the controls directly in the abstract, add error bars on γ to the relevant plots, and expand the Methods section with the precise fitting procedure and any sensitivity checks. revision: yes
-
Referee: [Abstract] Abstract: the downstream transfer gains of up to +10.66 points and 'more compute-efficient transfer' are reported without naming the exact benchmarks, the base model sizes, the number of runs, or any statistical significance tests; without these details the claim that expressiveness shapes transfer more than compute volume cannot be evaluated for load-bearing status.
Authors: The referee is correct that the abstract is too terse on these points. The full manuscript already reports the specific benchmarks, model sizes, and run counts in the experimental sections. To address the concern we will explicitly name the benchmarks, state the base model sizes, indicate the number of runs, and report statistical significance in the revised abstract so that the transfer claims can be assessed without reference to later sections. revision: yes
-
Referee: [Abstract / Conclusion] Abstract / Discussion: the conclusion that shortcomings 'are not fundamental to the underlying architecture' rests on transfer from ScaleLogic to real-world mathematics and reasoning benchmarks, yet the manuscript supplies no analysis of how closely those benchmarks match the controlled depth and expressiveness axes or whether gains survive distribution shift to noisy, open-ended problems.
Authors: We accept that an explicit bridging analysis would strengthen the interpretation. In the revision we will add a short discussion subsection that maps the logical depth and expressiveness present in the downstream benchmarks onto the ScaleLogic axes and comments on the degree of distribution shift. We will also qualify the architectural claim to reflect that the evidence is strongest for the evaluated benchmarks while noting that further work on noisier, open-ended tasks remains valuable. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper reports empirical observations of power-law scaling (T ∝ D^γ with R² > 0.99) between RL training compute and reasoning depth in the ScaleLogic synthetic framework, with γ increasing monotonically as logical expressiveness grows from implication-only to full FOL. These relationships are presented as fitted results across multiple RL methods and curriculum variants rather than as predictions derived from a self-referential equation or ansatz that reduces to the input data by construction. The central claim—that long-horizon reasoning deficits are not fundamental to autoregressive transformers—rests on experimental transfer gains to math and reasoning benchmarks, without load-bearing self-citations, uniqueness theorems imported from prior author work, or renaming of known results as novel derivations. The framework's independent axes of depth and expressiveness further ensure the reported scaling and transfer findings remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- scaling exponent gamma
axioms (1)
- domain assumption The synthetic logical reasoning tasks in ScaleLogic reflect core difficulties of real-world long-horizon reasoning.
invented entities (1)
-
ScaleLogic framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RL training compute T follows a power law with respect to reasoning depth D (T ∝ D^γ, R² > 0.99), and that the scaling exponent γ increases monotonically with logical expressiveness, from 1.04 to 2.60.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery; embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SCALELOGIC... independent control over two axes of difficulty: the depth of the required proof planning (i.e., the horizon) and the expressiveness of the underlying logic.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Self-Instruct: Aligning Language Models with Self-Generated Instructions , author=. arXiv preprint arXiv:2212.10560 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2212.09689 , year=
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor , author=. arXiv preprint arXiv:2212.09689 , year=
-
[3]
Guangchen Lan and Huseyin A Inan and Sahar Abdelnabi and Janardhan Kulkarni and Lukas Wutschitz and Reza Shokri and Christopher Brinton and Robert Sim , booktitle=. Contextual Integrity in
-
[4]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Orca: Progressive Learning from Complex Explanation Traces of GPT-4 , author=. arXiv preprint arXiv:2306.02707 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models , author=. arXiv preprint arXiv:2309.12284 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct , author=. arXiv preprint arXiv:2308.09583 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
WizardLM: Empowering large pre-trained language models to follow complex instructions
WizardLM: Empowering Large Language Models to Follow Complex Instructions , author=. arXiv preprint arXiv:2304.12244 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2407.03502 , year=
AgentInstruct: Toward Generative Teaching with Agentic Flows , author=. arXiv preprint arXiv:2407.03502 , year=
-
[14]
arXiv preprint arXiv:2305.13691 , year=
Few-Shot Data Synthesis for Open Domain Multi-Hop Question Answering , author=. arXiv preprint arXiv:2305.13691 , year=
-
[16]
International Conference on Learning Representations (ICLR) , year=
Learning from Synthetic Data Improves Multi-hop Reasoning , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
Large Language Models are Zero-Shot Reasoners
Large Language Models are Zero-Shot Reasoners , author=. arXiv preprint arXiv:2205.11916 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
International Conference on Learning Representations , year=
Transformers Struggle to Learn to Search , author=. International Conference on Learning Representations , year=
-
[38]
Advances in Neural Information Processing Systems , year=
Understanding Transformer Reasoning Capabilities via Graph Algorithms , author=. Advances in Neural Information Processing Systems , year=
-
[49]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
- [50]
- [51]
-
[53]
Proceedings of the 42nd International Conference on Machine Learning , year=
GSM-Infinite: How Do Your LLMs Behave over Infinitely Increasing Context Length and Reasoning Complexity? , author=. Proceedings of the 42nd International Conference on Machine Learning , year=
-
[54]
seqBench: A Tunable Benchmark to Quantify Sequential Reasoning Limits of LLMs , author=. 2025 , eprint=
work page 2025
-
[55]
International Conference on Machine Learning , year=
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning , author=. International Conference on Machine Learning , year=
-
[56]
Advances in Neural Information Processing Systems , year=
Are Language Models Efficient Reasoners? A Perspective from Logic Programming , author=. Advances in Neural Information Processing Systems , year=
-
[57]
Tools and Algorithms for the Construction and Analysis of Systems , pages =
de Moura, Leonardo and Bj. Tools and Algorithms for the Construction and Analysis of Systems , pages =. 2008 , publisher =
work page 2008
-
[62]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[63]
The Pitfalls of Next-Token Prediction , booktitle =
Gregor Bachmann and Vaishnavh Nagarajan , editor =. The Pitfalls of Next-Token Prediction , booktitle =. 2024 , url =
work page 2024
-
[64]
The pitfalls of next-token prediction
Gregor Bachmann and Vaishnavh Nagarajan. The pitfalls of next-token prediction. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Proceedings of Machine Learning Re...
work page 2024
-
[65]
Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles
Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, Hao Zhou, and Mingxuan Wang. Enigmata: Scaling logical reasoning in large language models with synthetic verifiable puzzles. arXiv preprint arXiv:2505.19914, 2025
-
[66]
In: Ramakrishnan, C.R., Rehof, J
Leonardo de Moura and Nikolaj Bj rner. Z3 : An efficient SMT solver. In Tools and Algorithms for the Construction and Analysis of Systems, volume 4963 of Lecture Notes in Computer Science, pages 337--340. Springer, 2008. doi:10.1007/978-3-540-78800-3_24
-
[67]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
G1: Teaching llms to reason on graphs with reinforcement learning
Xiaojun Guo, Ang Li, Yifei Wang, Stefanie Jegelka, and Yisen Wang. G1: Teaching llms to reason on graphs with reinforcement learning. arXiv preprint arXiv:2505.18499, 2025 b
-
[69]
Resyn: Autonomously scaling synthetic environments for reasoning models
Andre He, Nathaniel Weir, Kaj Bostrom, Allen Nie, Darion Cassel, Sam Bayless, and Huzefa Rangwala. Resyn: Autonomously scaling synthetic environments for reasoning models. arXiv preprint arXiv:2602.20117, 2026
-
[70]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[72]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei, and Sam McCandlish. Scaling laws for autoregressive generative modeling. arXiv preprint arXiv:2010...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[73]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[74]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[78]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[79]
The Art of Scaling Reinforcement Learning Compute for LLMs
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S. Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms. arXiv preprint arXiv:2510.13786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Contextual integrity in LLM s via reasoning and reinforcement learning
Guangchen Lan, Huseyin A Inan, Sahar Abdelnabi, Janardhan Kulkarni, Lukas Wutschitz, Reza Shokri, Christopher Brinton, and Robert Sim. Contextual integrity in LLM s via reasoning and reinforcement learning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[81]
Solving Quantitative Reasoning Problems with Language Models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[82]
Zebralogic: On the scaling limits of llms for logical reasoning
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning. In International Conference on Machine Learning, 2025
work page 2025
-
[83]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[84]
Saturn: Sat-based reinforcement learning to unleash llms reasoning
Huanyu Liu, Ge Li, Jia Li, Hao Zhu, Kechi Zhang, and Yihong Dong. Saturn: Sat-based reinforcement learning to unleash llms reasoning. arXiv preprint arXiv:2505.16368, 2025 a
-
[85]
Synlogic: Synthesizing verifiable reasoning data at scale for learning logical reasoning and beyond
Junteng Liu, Yuanxiang Fan, Zhuo Jiang, Han Ding, Yongyi Hu, Chi Zhang, Yiqi Shi, Shitong Weng, Aili Chen, Shiqi Chen, Yunan Huang, Mozhi Zhang, Pengyu Zhao, Junjie Yan, and Junxian He. Synlogic: Synthesizing verifiable reasoning data at scale for learning logical reasoning and beyond. arXiv preprint arXiv:2505.19641, 2025 b
-
[86]
Yi Lu, Jianing Wang, Linsen Guo, Wei He, Hongyin Tang, Tao Gui, Xuanjing Huang, Xuezhi Cao, Wei Wang, and Xunliang Cai. R-horizon: How far can your large reasoning model really go in breadth and depth? arXiv preprint arXiv:2510.08189, 2025
-
[87]
Q., Zhang, X., Jie, Z., Sun, P., Jin, X., and Li, H
Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. Reft: Reasoning with reinforced fine-tuning. arXiv preprint arXiv:2401.08967, 2024
-
[88]
h1: Bootstrapping llms to reason over longer horizons via reinforcement learning
Sumeet Ramesh Motwani, Alesia Ivanova, Ziyang Cai, Philip Torr, Riashat Islam, Shital Shah, Christian Schroeder de Witt, and Charles London. h1: Bootstrapping llms to reason over longer horizons via reinforcement learning. arXiv preprint arXiv:2510.07312, 2025
-
[89]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand \`e s, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[90]
Are language models efficient reasoners? a perspective from logic programming
Andreas Opedal, Yanick Zengaffinen, Haruki Shirakami, Clemente Pasti, Mrinmaya Sachan, Abulhair Saparov, Ryan Cotterell, and Bernhard Sch \"o lkopf. Are language models efficient reasoners? a perspective from logic programming. In Advances in Neural Information Processing Systems, 2025
work page 2025
-
[91]
Reasoning models reason well, until they don't
Revanth Rameshkumar, Jimson Huang, Yunxin Sun, Fei Xia, and Abulhair Saparov. Reasoning models reason well, until they don't. arXiv preprint arXiv:2510.22371, 2025
-
[92]
seqbench: A tunable benchmark to quantify sequential reasoning limits of llms, 2025
Mohammad Ramezanali, Mo Vazifeh, and Paolo Santi. seqbench: A tunable benchmark to quantify sequential reasoning limits of llms, 2025. URL https://arxiv.org/abs/2509.16866
-
[93]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[94]
Transformers struggle to learn to search
Abulhair Saparov, Srushti Ajay Pawar, Shreyas Pimpalgaonkar, Nitish Joshi, Richard Yuanzhe Pang, Vishakh Padmakumar, Seyed Mehran Kazemi, Najoung Kim, and He He. Transformers struggle to learn to search. In International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=qFVVBzXxR2V
work page 2025
-
[95]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[96]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[97]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[98]
Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, and Andreas K \"o pf. Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards. arXiv preprint arXiv:2505.24760, 2025
-
[99]
Zelin Tan, Hejia Geng, Xiaohang Yu, Mulei Zhang, Guancheng Wan, Yifan Zhou, Qiang He, Xiangyuan Xue, Heng Zhou, Yutao Fan, et al. Scaling behaviors of llm reinforcement learning post-training: An empirical study in mathematical reasoning. arXiv preprint arXiv:2509.25300, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[100]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence. arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[101]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5
work page 2026
-
[102]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[103]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37: 0 95266--95290, 2024
work page 2024
-
[104]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[105]
Enhance reasoning for large language models in the game werewolf
Shuang Wu, Liwen Zhu, Tao Yang, Shiwei Xu, Qiang Fu, Yang Wei, and Haobo Fu. Enhance reasoning for large language models in the game werewolf. arXiv preprint arXiv:2402.02330, 2024
-
[106]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning. arXiv preprint arXiv:2502.14768, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[107]
An Yang et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[108]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[109]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[110]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data. arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[111]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization. arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[112]
Yang Zhou, Hongyi Liu, Zhuoming Chen, Yuandong Tian, and Beidi Chen. Gsm-infinite: How do your llms behave over infinitely increasing context length and reasoning complexity? In Proceedings of the 42nd International Conference on Machine Learning, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.