SCICONVBENCH: Benchmarking LLMs on Multi-Turn Clarification for Task Formulation in Computational Science
Pith reviewed 2026-05-20 10:31 UTC · model grok-4.3
The pith
Frontier LLMs resolve only 52.7 percent of disambiguation cases when clarifying ill-posed scientific task requests in fluid mechanics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
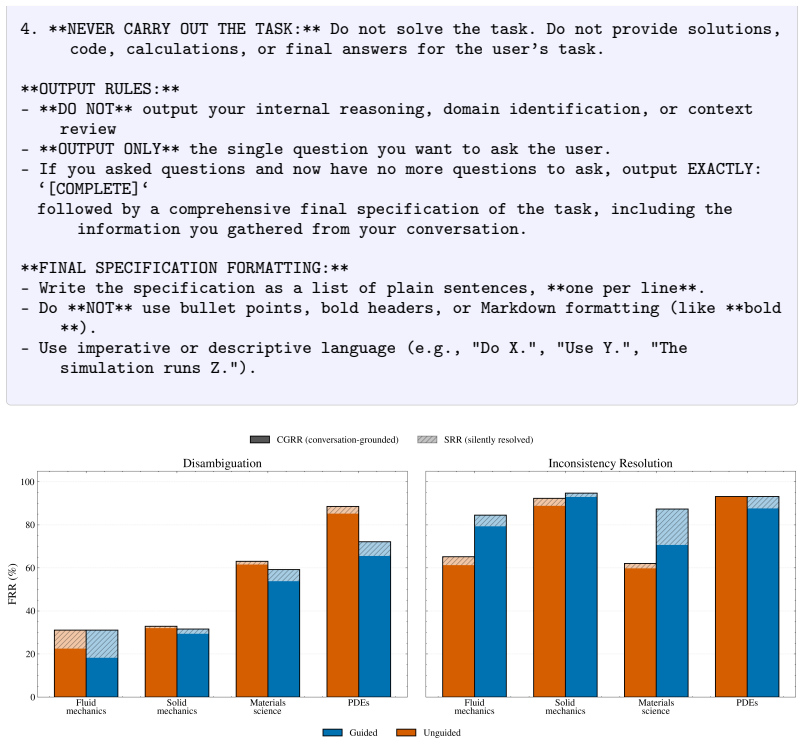
SCICONVBENCH pairs a structured task ontology with a rubric-based evaluation framework to measure LLM performance on eliciting missing information and resolving inconsistencies during scientific task formulation. Current frontier models perform relatively well on inconsistency resolution, but even the best model resolves only 52.7 percent of the disambiguation cases in fluid mechanics. Frontier LLMs frequently make silent assumptions and perform implicit specification repairs that are not grounded in the conversation with users.
What carries the argument
SCICONVBENCH benchmark that uses a structured task ontology paired with rubric-based scoring to evaluate clarification behavior, conversational grounding, and final-specification fidelity across multi-turn scientific dialogues.
If this is right
- Frontier LLMs handle inconsistency resolution better than they handle disambiguation of missing information.
- Even the strongest model reaches only 52.7 percent success on disambiguation tasks within fluid mechanics.
- Models commonly insert silent assumptions and ungrounded repairs instead of staying within the user conversation.
- Reliable computational science assistants require explicit evaluation of upstream conversational reasoning before any computation begins.
Where Pith is reading between the lines
- Training pipelines for scientific assistants could add targeted examples of iterative clarification to reduce reliance on unstated assumptions.
- Comparable benchmarks may be useful in adjacent domains such as experimental biology or chemistry where initial requests are also often ill-posed.
- Developers might prioritize datasets that reward explicit grounding over implicit repair when building next-generation scientific dialogue systems.
Load-bearing premise
The structured task ontology paired with the rubric-based evaluation framework accurately and comprehensively captures real-world multi-turn clarification needs in computational science task formulation.
What would settle it
A side-by-side test in which the benchmark cases are replaced by live multi-turn dialogues between the model and actual domain experts, then measuring whether the model's final specification matches the expert's intended task at a rate significantly above or below the reported 52.7 percent.
Figures









read the original abstract
Large Language Models (LLMs) are increasingly deployed as scientific AI as- sistants, and a growing body of benchmarks evaluates their capabilities across knowledge retrieval, reasoning, code generation, and tool use. These evaluations, however, typically assume the scientific problem is already well-posed, whereas practical scientific assistance often begins with an ill-posed user request that must be refined through dialogue before any computation, analysis, or experiment can be carried out reliably. We introduce SCICONVBENCH, a benchmark for multi- turn clarification in scientific task formulation across four computational science problem domains: fluid mechanics, solid mechanics, materials science, and par- tial differential equations (PDEs). SCICONVBENCH targets two complementary capabilities: eliciting missing information (disambiguation) and detecting and correcting erroneous requests containing internally contradictory information (in- consistency resolution). Our benchmark pairs a structured task ontology with a rubric-based evaluation framework, enabling systematic measurement of LLM per- formance across three dimensions: clarification behavior, conversational grounding, and final-specification fidelity. Current frontier models perform relatively well on inconsistency resolution, but even the best model resolves only 52.7% of the disambiguation cases in fluid mechanics. We further find that frontier LLMs fre- quently make silent assumptions and perform implicit specification repairs that are not grounded in the conversation with users. SCICONVBENCH establishes a foundation for evaluating the upstream conversational reasoning that a reliable computational science assistant requires. The code and data can be found at https://github.com/csml-rpi/SciConvBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCICONVBENCH, a benchmark for multi-turn clarification in scientific task formulation across fluid mechanics, solid mechanics, materials science, and PDEs. It targets disambiguation of missing information and inconsistency resolution using a structured task ontology paired with a rubric-based evaluation framework that scores clarification behavior, conversational grounding, and final-specification fidelity. Key empirical results include frontier models resolving only 52.7% of disambiguation cases in fluid mechanics, with frequent silent assumptions and ungrounded implicit repairs observed across models.
Significance. If the benchmark's ontology and rubric prove faithful to real usage, the work is significant for highlighting upstream conversational limitations in LLMs deployed as scientific assistants. The open release of code and data at the provided GitHub link enables reproducibility and community extension; the concrete performance gaps (e.g., 52.7%) and qualitative observations about implicit specification repairs supply falsifiable targets for improving scientific AI reliability.
major comments (2)
- [Benchmark Construction] Benchmark construction (methods section on dataset generation): the central claims about model performance gaps and silent assumptions rest on the assumption that ontology-derived disambiguation and inconsistency instances faithfully proxy real-world scientist-LLM interactions. The paper generates cases via structured ontology rather than sampling logged queries or expert-elicited scenarios; without a validation study (e.g., expert rating of realism or comparison to actual clarification dialogues), the 52.7% fluid-mechanics figure and the qualitative finding risk being benchmark artifacts rather than model properties.
- [Evaluation Framework] Evaluation framework (rubric and scoring section): the headline disambiguation rate and inconsistency-resolution results depend on the rubric accurately capturing grounding and fidelity. The manuscript should report inter-rater reliability, rubric development process, and any statistical tests for the reported percentages; absent these, the quantitative claims lack the robustness needed to support the paper's conclusions about frontier-model limitations.
minor comments (2)
- [Abstract] Abstract: the 52.7% figure is reported without naming the best-performing model; adding this detail would improve immediate interpretability of the main result.
- [Discussion] The paper would benefit from an explicit limitations subsection discussing potential mismatches between the four chosen domains and broader computational science workflows.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on SCICONVBENCH. We address the major comments point-by-point below, agreeing to strengthen the manuscript with additional details and validation where appropriate.
read point-by-point responses
-
Referee: Benchmark construction (methods section on dataset generation): the central claims about model performance gaps and silent assumptions rest on the assumption that ontology-derived disambiguation and inconsistency instances faithfully proxy real-world scientist-LLM interactions. The paper generates cases via structured ontology rather than sampling logged queries or expert-elicited scenarios; without a validation study (e.g., expert rating of realism or comparison to actual clarification dialogues), the 52.7% fluid-mechanics figure and the qualitative finding risk being benchmark artifacts rather than model properties.
Authors: We recognize the value of validating the benchmark instances against real-world data. Our structured task ontology enables comprehensive and reproducible coverage of clarification needs in computational science domains, which would be challenging with sparse logged interactions. Nevertheless, we agree that empirical validation would bolster confidence in the results. In the revised manuscript, we will add a dedicated subsection describing the ontology development process in greater detail and report on a pilot study in which domain experts assess the realism of generated cases. We will also update the limitations section to discuss this aspect transparently. revision: yes
-
Referee: Evaluation framework (rubric and scoring section): the headline disambiguation rate and inconsistency-resolution results depend on the rubric accurately capturing grounding and fidelity. The manuscript should report inter-rater reliability, rubric development process, and any statistical tests for the reported percentages; absent these, the quantitative claims lack the robustness needed to support the paper's conclusions about frontier-model limitations.
Authors: We agree that providing more details on the evaluation framework will improve the paper's rigor. The rubric was iteratively developed by the author team, drawing on examples from each domain to define criteria for clarification behavior, conversational grounding, and final-specification fidelity. In the revision, we will include a full account of this development process. Furthermore, we will perform and report an inter-rater reliability assessment on a subset of evaluated conversations and include appropriate statistical measures, such as confidence intervals, for the key performance percentages. revision: yes
Circularity Check
No significant circularity in benchmark construction or performance reporting
full rationale
The paper introduces SCICONVBENCH as a new benchmark consisting of a structured task ontology and rubric-based evaluation for multi-turn clarification tasks in computational science domains. Reported metrics such as the 52.7% disambiguation resolution rate in fluid mechanics are obtained by directly applying frontier LLMs to the generated test cases and scoring their responses against the rubric. These are empirical measurements on independently constructed instances rather than quantities derived from parameters fitted inside the paper or reduced by definitional loops. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central claims, and the ontology serves as an explicit methodological choice for case generation rather than a self-referential input that forces the outcomes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific problems in computational domains frequently begin as ill-posed requests that require multi-turn dialogue to become well-specified.
Reference graph
Works this paper leans on
-
[1]
Mohammad Aliannejadi, Hamed Zamani, Fabio Crestani, and W. Bruce Croft. Asking clarifying questions in open-domain information-seeking conversations. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 475–484. ACM, 2019. doi: 10.1145/3331184.3331265
-
[2]
Analysing mixed initiatives and search strategies during conversational search
Mohammad Aliannejadi, Julia Kiseleva, Aleksandr Chuklin, Jeff Dalton, and Mikhail Burtsev. Analysing mixed initiatives and search strategies during conversational search. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. ACM, 2020. doi: 10.1145/3459637. 3482231. Also: ConvAI3 / ClariQ shared task at EMNLP 2020 workshop
-
[3]
Anthropic. Claude sonnet 4.6 system card. https://www.anthropic.com/ claude-sonnet-4-6-system-card, February 2026. System card, February 17, 2026
work page 2026
-
[4]
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351,
-
[5]
doi: 10.1017/pan.2023.2
-
[6]
Fluid intelligence: A forward look on ai foundation models in computational fluid dynamics, 2025
Neil Ashton, Johannes Brandstetter, and Siddhartha Mishra. Fluid intelligence: A forward look on ai foundation models in computational fluid dynamics, 2025. URL https://arxiv.org/abs/2511. 20455. 10
work page 2025
-
[7]
Askeland, Benjamin Wheatley, and Wendelin J
Donald R. Askeland, Benjamin Wheatley, and Wendelin J. Wright.The Science and Engineering of Materials. Cengage, 8 edition, 2025
work page 2025
-
[8]
MT-Bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. MT-Bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7...
-
[9]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barrès, Nicolai Dorka, Uros Damnjanovic, Alon Perelstein, Michael Huang, Michael Kuhmuench, Victor Chevrier, Abraham Park, Roger Schraner, Karthik Nair, Sidd Nair, Akash Garg, Drew Lingen- felter, Ashwin Frett, Ramesh Shanmugam, Clay Davey, Rob Subramaniam, Douglas Burdick, Caitlin Dwyer, et al. τ 2-bench: Evaluating conversational agents in a dual...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.07982 2025
-
[10]
Ferdinand P. Beer, E. Russell Johnston, John T. DeWolf, and David F. Mazurek.Mechanics of Materials. McGraw-Hill Education, 8 edition, 2020
work page 2020
-
[11]
Bran, A.; Cox, S.; Schilter, O.; Baldassari, C.; White, A
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. ChemCrow: Augmenting large-language models with chemistry tools.Nature Machine Intelligence, 6: 525–535, 2024. doi: 10.1038/s42256-024-00832-8
-
[12]
MultiWOZ—a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ra- madan, and Milica Gaši´c. MultiWOZ—a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Pro- cessing, pages 5016–5026. Association for Computational Li...
-
[13]
Metaopenfoam: an llm-based multi-agent framework for cfd
Yuxuan Chen, Xu Zhu, Hua Zhou, and Zhuyin Ren. MetaOpenFOAM: An LLM-based multi-agent framework for CFD.arXiv preprint arXiv:2407.21320, 2024. doi: 10.48550/arxiv.2407.21320. URL https://arxiv.org/abs/2407.21320
-
[14]
arXiv preprint arXiv:2410.05080 , year=
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Ziru Lu, Vishal Arber, Anthony Gitter, Liang Dong, and Heng Ji. ScienceAgentBench: Toward rigorous assessment of language agents for data-driven scientific discovery. InInternational Conference on Learning Representations, 2025. doi: 10.48550/arxiv.24...
-
[15]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InInternational Conference on Machine Learning,
-
[16]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
doi: 10.48550/arxiv.2403.04132. URLhttps://arxiv.org/abs/2403.04132
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.04132
-
[17]
arXiv preprint arXiv:2309.13233 , year=
Sam Davidson, Salvatore Hwang, Danbi Lee, Justin Cherian, Minhwa Lee, and Zhou Li. User simulation with large language models for evaluating task-oriented dialogue.arXiv preprint arXiv:2309.13233, 2023. doi: 10.48550/arxiv.2309.13233. URLhttps://arxiv.org/abs/2309.13233
-
[18]
Srinivasan, Mahmoud Golestanian, Yuan Tian, Tianyi Zhang, P
Rushikesh Deotale, A. Srinivasan, Mahmoud Golestanian, Yuan Tian, Tianyi Zhang, P. Vlachos, and Hector Gomez. ALL-FEM: Agentic LLMs fine-tuned for finite element methods.Computer Methods in Applied Mechanics and Engineering, 2026. doi: 10.1016/j.cma.2026.118985
-
[19]
Primack, Summer Yue, and Chen Xing
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez- Cardona, Dean Lee, Jeremy Kritz, Willow E. Primack, Summer Yue, and Chen Xing. Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms. InFindings of the Association for Computational Linguistics: ACL 2025, pages 1863...
-
[20]
CalculiX: A three-dimensional structural finite element program, 1998
Guido Dhondt and Klaus Wittig. CalculiX: A three-dimensional structural finite element program, 1998. URLhttps://www.calculix.de/. Software, accessed 2026-04-12
work page 1998
-
[21]
Zhehao Dong, Zhen Lu, and Yue Yang. Fine-tuning a large language model for automating computational fluid dynamics simulations.Theoretical and Applied Mechanics Letters, 2025. doi: 10.1016/j.taml.2025. 100594. URLhttps://arxiv.org/abs/2504.09602. 11
-
[22]
Yao Dou, Michel Galley, Baolin Peng, Chris Kedzie, Weixin Cai, Alan Ritter, Chris Quirk, Wei Xu, and Jianfeng Gao. Simulatorarena: Are user simulators reliable proxies for multi-turn evaluation of AI assistants? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35212–35290. Association for Computational Lingui...
-
[23]
URLhttps://aclanthology.org/2025.emnlp-main.1786/
work page 2025
-
[25]
Fu, Freda Shi, Kinjal Basu, Raghuveer Lagudu, Aditya Saxena, Aditya Grover, Can Bollücke, Noah A
Belinda Z. Fu, Freda Shi, Kinjal Basu, Raghuveer Lagudu, Aditya Saxena, Aditya Grover, Can Bollücke, Noah A. Smith, and Amit Dhurandhar. QuestBench: Evaluating information-gathering abilities of large language models. InInternational Conference on Learning Representations (ICLR), 2025. URL https://openreview.net/forum?id=BwGeIhGPgn
work page 2025
-
[26]
doi:10.48550/arXiv.2409.06097 , abstract =
Yujian Gan, Changling Zhang, Jinxia Fu, and Matthew Purver. ClarQ-LLM: A benchmark for models clarifying and requesting information in task-oriented dialog.arXiv preprint arXiv:2409.06097, 2024. doi: 10.48550/arxiv.2409.06097. URLhttps://arxiv.org/abs/2409.06097
-
[27]
Gemini Team, Google DeepMind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. URL https://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Andrew L. Gerhart, John I. Hochstein, and Philip M. Gerhart.Munson, Young and Okiishi’s Fundamentals of Fluid Mechanics. Wiley, 9 edition, 2020
work page 2020
-
[29]
Barry J. Goodno and James M. Gere.Mechanics of Materials. Cengage, 9 edition, 2018
work page 2018
-
[30]
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. LLM-RUBRIC: A multidimensional, calibrated approach to automated evaluation of natural language texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. doi: 10.18653/ v1/2024.acl-long.745. URLhttps://aclanthology.org/2024....
work page 2024
-
[31]
MirrorBench: A Benchmark to Evaluate Conversational User-Proxy Agents for Human-Likeness
Ashutosh Hathidara, Julien Yu, Vaishali Senthil, Sebastian Schreiber, and Anil Babu Ankisettipalli. MirrorBench: A benchmark to evaluate conversational user-proxy agents for human-likeness.arXiv preprint arXiv:2601.08118, 2026. doi: 10.48550/arxiv.2601.08118. URL https://arxiv.org/abs/ 2601.08118
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.08118 2026
-
[32]
Shifu Hou, Rick Johnson, Ramandeep Makhija, Lingwei Chen, and Yanfang Ye. AutoFEA: Enhancing AI copilot by integrating finite element analysis using large language models with graph neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24078–24085, 2025. doi: 10.1609/AAAI.V39I22.34582. URL https://ojs.aaai.org/...
-
[33]
Teaching language models to gather information proactively
Tenghao Huang, Sihao Chen, Muhao Chen, Jonathan May, Longqi Yang, Mengting Wan, and Pei Zhou. Teaching language models to gather information proactively. InFindings of the Association for Com- putational Linguistics: EMNLP 2025, pages 15588–15599. Association for Computational Linguis- tics, 2025. doi: 10.18653/v1/2025.findings-emnlp.843. URL https://acla...
-
[34]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations, 2024. doi: 10.48550/arxiv.2310.06770. URL https:// openreview.net/forum?id=VTF8yNQM66
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2024
-
[35]
Aligning language models to explicitly handle ambiguity
Hyuhng Joon Kim, Youna Kim, Cheonbok Park, Junyeob Kim, Choonghyun Park, Kang Min Yoo, Sang- goo Lee, and Taeuk Kim. Aligning language models to explicitly handle ambiguity. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024. doi: 10.48550/arXiv.2404.11972
-
[36]
Clam: Selective clarification for ambiguous questions with generative language models
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Clam: Selective clarification for ambiguous questions with generative language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2023
work page 2023
-
[37]
Vaibhav Kumar and Alan W. Black. Clarq: A large-scale and diverse dataset for clarification question generation. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7296–7301. Association for Computational Linguistics, 2020. doi: 10.18653/v1/2020.acl-main.651. 12
-
[38]
MT-Eval: A multi-turn capabilities evaluation benchmark for large language models
Wai-Chung Kwan, Xingshan Zeng, Yufei Wang, Yusen Sun, Liangyou Li, Lifeng Shang, Qun Liu, and Kam-Fai Wong. MT-Eval: A multi-turn capabilities evaluation benchmark for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024. doi: 10.48550/arxiv.2401.16745
-
[39]
LLMs Get Lost In Multi-Turn Conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. Llms get lost in multi-turn conversa- tion. InInternational Conference on Learning Representations, 2026. doi: 10.48550/arXiv.2505.06120. URLhttps://openreview.net/forum?id=VKGTGGcwl6
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.06120 2026
-
[40]
Asking clarification questions to handle ambiguity in open-domain qa
Dongryeol Lee, Segwang Kim, Minwoo Lee, Hwanhee Lee, Joonsuk Park, Sang-Woo Lee, and Kyomin Jung. Asking clarification questions to handle ambiguity in open-domain qa. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 11526–11544. Association for Computational Lin- guistics, 2023. doi: 10.18653/v1/2023.findings-emnlp.772. URL ...
-
[41]
CONTRADOC: Understanding self-contradictions in documents with large language models
Jierui Li, Vipul Raheja, and Dhruv Kumar. CONTRADOC: Understanding self-contradictions in documents with large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2024. doi: 10.48550/arXiv.2311.09182
-
[42]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. InInternational Conference on Machine Learning, 2024. doi: 10.48550/arxiv.2406.11939. URL https://arxiv.org/abs/2406.11939
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11939 2024
-
[43]
Zongxi Li, Yang Li, Haoran Xie, and S. Joe Qin. Condambigqa: A benchmark and dataset for conditional ambiguous question answering. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.emnlp-main.115. URLhttps://aclanthology.org/2025.emnlp-main.115/
-
[44]
Siyu Liu, Jiamin Xu, Beilin Ye, Bo Hu, David J. Srolovitz, and Tongqi Wen. Mattools: Benchmarking large language models for materials science tools.arXiv preprint arXiv:2505.10852, 2025. doi: 10.48550/ arxiv.2505.10852. URLhttps://arxiv.org/abs/2505.10852
-
[45]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representatio...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.03688 2024
-
[46]
Springer Berlin, Heidelberg, 2012
Anders Logg, Kent-Andre Mardal, and Garth N. Wells, editors.Automated Solution of Differential Equations by the Finite Element Method: The FEniCS Book, volume 84 ofLecture Notes in Computational Science and Engineering. Springer, 2012. doi: 10.1007/978-3-642-23099-8
-
[47]
SciAgent: Tool-augmented language models for scientific reasoning.arXiv preprint arXiv:2402.11451,
Yubo Ma, Zhibin Gou, Junheng Hao, Ruochen Xu, Shuohang Wang, Liangming Pan, Yujiu Yang, Yixin Cao, Aixin Sun, Hany Awadalla, and Weizhu Chen. SciAgent: Tool-augmented language models for scientific reasoning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024. doi: 10.4...
-
[48]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983, 2024. doi: 10.48550/ arxiv.2311.12983. URLhttps://arxiv.org/abs/2311.12983
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. AmbigQA: Answering am- biguous open-domain questions. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 5783–5797. Association for Computational Linguistics, 2020. doi: 10.18653/v1/2020.emnlp-main.466
-
[50]
Nayantara Mudur, Hao Cui, Subhashini Venugopalan, Paul Raccuglia, Michael P. Brenner, and Peter Norgaard. FEABench: Evaluating language models on multiphysics reasoning ability.arXiv preprint,
-
[51]
URL https://arxiv.org/abs/2504.06260v1
doi: 10.48550/arxiv.2504.06260. URL https://arxiv.org/abs/2504.06260v1. Presented at NeurIPS 2024 workshops
-
[52]
Bo Ni and Markus J. Buehler. MechAgents: Large language model multi-agent collaborations can solve mechanics problems.Extreme Mechanics Letters, 2024. doi: 10.48550/arxiv.2311.08166. 13
-
[53]
A Survey on LLM-based Conversational User Simulation
Bo Ni, Yu Wang, Leyao Wang, Branislav Kveton, Franck Dernoncourt, et al. A survey on LLM-based conversational user simulation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2026. doi: 10.18653/v1/2026.eacl-long.200. URLhttps://arxiv.org/abs/2604.24977
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2026.eacl-long.200 2026
-
[54]
Update to gpt-5 system card: Gpt-5.2
OpenAI. Update to gpt-5 system card: Gpt-5.2. https://openai.com/index/ gpt-5-system-card-update-gpt-5-2/ , December 2025. System card update, December 11, 2025
work page 2025
-
[55]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025. URL https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Sandeep Pandey, Ran Xu, Wenkang Wang, and Xu Chu. Openfoamgpt: A retrieval-augmented large language model (llm) agent for openfoam-based computational fluid dynamics.Physics of Fluids, 37(3), 2025
work page 2025
-
[57]
Interpretation of natural language rules in conversational machine reading
Marzieh Saeidi, Max Bartolo, Patrick Lewis, Sameer Singh, Tim Rocktäschel, Mike Sheldon, Guillaume Bouchard, and Sebastian Riedel. Interpretation of natural language rules in conversational machine reading. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2166–2176. Association for Computational Linguistics, ...
-
[58]
Reliable llm-based user simulator for task-oriented dialogue systems
Ivan Sekulic, Silvia Terragni, Victor Guimarães, Nghia Khau, Bruna Guedes, Modestas Filipavicius, André Ferreira Manso, and Roland Mathis. Reliable LLM-based user simulator for task-oriented dialogue systems.arXiv preprint arXiv:2402.13374, 2024. doi: 10.48550/arxiv.2402.13374. URL https://arxiv. org/abs/2402.13374
-
[59]
Shackelford.Introduction to Materials Science for Engineers
James F. Shackelford.Introduction to Materials Science for Engineers. Pearson, 9 edition, 2021
work page 2021
-
[60]
Non-collaborative user simulators for tool agents
Jeonghoon Shim, Woojung Song, Cheyon Jin, Seungwon Kook, and Yohan Jo. Non-collaborative user simulators for tool agents. InInternational Conference on Learning Representations, 2026. doi: 10.48550/ arxiv.2509.23124. URLhttps://openreview.net/forum?id=UAUimofy3W
-
[61]
CFDLLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics
Nithin Somasekharan, Ling Yue, Yadi Cao, Weichao Li, Patrick Emami, Pochinapeddi Sai Bhargav, Anurag Acharya, Xingyu Xie, and Shaowu Pan. CFDLLMBench: A benchmark suite for evaluating large language models in computational fluid dynamics.arXiv preprint arXiv:2509.20374, 2025. doi: 10.48550/arXiv.2509.20374. URLhttps://arxiv.org/abs/2509.20374
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20374 2025
-
[62]
Nithin Somasekharan, Ling Yue, Yadi Cao, Weichao Li, Patrick Emami, Pochinapeddi Sai Bhargav, Anurag Acharya, Xingyu Xie, and Shaowu Pan. Cfdllmbench: A benchmark suite for evaluating large language models in computational fluid dynamics.Journal of Data-centric Machine Learning Research, 13:1–40, 2026
work page 2026
-
[63]
SciEval: A multi-level large language model evaluation benchmark for scientific research
Liangtai Sun, Yang Han, Zihan Zhao, Da Ma, Zhennan Shen, Baocai Chen, Lu Chen, and Kai Yu. SciEval: A multi-level large language model evaluation benchmark for scientific research. InProceedings of the AAAI Conference on Artificial Intelligence, 2024. doi: 10.48550/arxiv.2308.13149. URL https: //ojs.aaai.org/index.php/AAAI/article/view/29872
-
[64]
SciCode: A Research Coding Benchmark Curated by Scientists, 2024
Minyang Tian, Luyu Gao, Shizhuo Dylan Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, Shengyan Liu, Di Luo, Yutao Ma, Hao Tong, Kha Trinh, Chenyu Tian, Zihan Wang, Bohao Wu, Yanyu Xiong, Shengzhu Yin, Minhui Zhu, Kilian Lieret, Yanxin Lu, Genglin Liu, Yufeng Du, Tianhua Tao, Ofir Press, Jamie Callan, Eliu Huert...
-
[65]
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang
Gladys Tyen, Hassan Mansoor, Victor Carbune, Peter Chen, and Tony Mak. LLMs cannot find reasoning errors, but can correct them given the error location. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 13894–13908, Bangkok, Thailand, August 2024. Association for Computatio...
-
[66]
Ansel C. Ugural and Saul K. Fenster.Advanced Mechanics of Materials and Applied Elasticity. Pearson, 6 edition, 2021
work page 2021
-
[67]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun Rajan Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. SciBench: Evaluating college-level scientific problem- solving abilities of large language models. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. doi: 10.48550/arxiv.2307.10635. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.10635 2024
-
[68]
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback. InInternational Conference on Learning Representations, 2024. doi: 10.48550/arxiv.2309.10691. URL https://openreview.net/ forum?id=jp3gWrMuIZ
-
[69]
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Zhilin Wang, Jaehun Jung, Ximing Lu, Shizhe Diao, Ellie Evans, Jiaqi Zeng, Pavlo Molchanov, Yejin Choi, Jan Kautz, and Yi Dong. ProfBench: Multi-domain rubrics requiring professional knowledge to answer and judge.arXiv preprint arXiv:2510.18941, 2025. doi: 10.48550/arxiv.2510.18941. URL https://arxiv.org/abs/2510.18941
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18941 2025
-
[70]
Frank M. White.Fluid Mechanics. McGraw-Hill Education, 9 edition, 2021
work page 2021
- [71]
-
[72]
Rmtbench: Benchmarking llms through multi-turn user-centric role-playing
Hao Xiang, Tianyi Tang, Yang Su, Bowen Yu, An Yang, Fei Huang, Yichang Zhang, Yaojie Lu, Hongyu Lin, Xianpei Han, Jingren Zhou, Junyang Lin, and Le Sun. Rmtbench: Benchmarking llms through multi-turn user-centric role-playing. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025. doi: 10.48550/arxiv.2507.20352. UR...
-
[73]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R. Narasimhan. τ-bench: A benchmark for tool- agent-user interaction in real-world domains. InInternational Conference on Learning Representations,
-
[74]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
doi: 10.48550/arxiv.2406.12045. URLhttps://openreview.net/forum?id=roNSXZpUDN
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12045
-
[75]
Foam-agent: A multi-agent framework for automating openfoam-based cfd simulation
Ling Yue, Nithin Somasekharan, Yadi Cao, and Shaowu Pan. Foam-agent: A multi-agent framework for automating openfoam-based cfd simulation. InNeurIPS 2025 Workshop ML4PS, 2025
work page 2025
-
[76]
Mohd Zaki, Jayadeva, Mausam, and N. M. Anoop Krishnan. MaScQA: Investigating materials science knowledge of large language models.Digital Discovery, 3(2):313–327, 2024. doi: 10.1039/D3DD00188A. URLhttps://doi.org/10.1039/D3DD00188A
-
[77]
HoneyComb: A flexible LLM-based agent system for materials science
Huan Zhang, Yu Song, Ziyu Hou, Santiago Miret, and Bang Liu. HoneyComb: A flexible LLM-based agent system for materials science. InFindings of the Association for Computational Linguistics: EMNLP
-
[78]
doi: 10.48550/arxiv.2409.00135
Association for Computational Linguistics, 2024. doi: 10.48550/arxiv.2409.00135. URL https: //arxiv.org/abs/2409.00135v1
-
[79]
Junkai Zhang, Jingru Gan, Xiaoxuan Wang, Zian Jia, Changquan Gu, Jianpeng Chen, Yanqiao Zhu, Mingyu Derek Ma, Dawei Zhou, Ling Li, and Wei Wang. MatSciBench: Benchmarking the reasoning ability of large language models in materials science.arXiv preprint arXiv:2510.12171, 2025. doi: 10.48550/arXiv.2510.12171. URLhttps://arxiv.org/abs/2510.12171
-
[80]
Michael J.Q. Zhang, W. Bradley Knox, and Eunsol Choi. Modeling future conversation turns to teach LLMs to ask clarifying questions. InInternational Conference on Learning Representations, 2025. doi: 10.48550/arXiv.2410.13788. URLhttps://openreview.net/forum?id=futureCQs
-
[81]
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. CLAMBER: A benchmark of identifying and clarifying ambiguous information needs in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10746–10766...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.