When the Majority Votes Wrong, the Intervention Timing for Test-Time Reinforcement Learning Hides in the Extinction Window
Pith reviewed 2026-05-20 07:16 UTC · model grok-4.3
The pith
Majority-vote signals in test-time RL permanently suppress correct answers after a brief active window.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
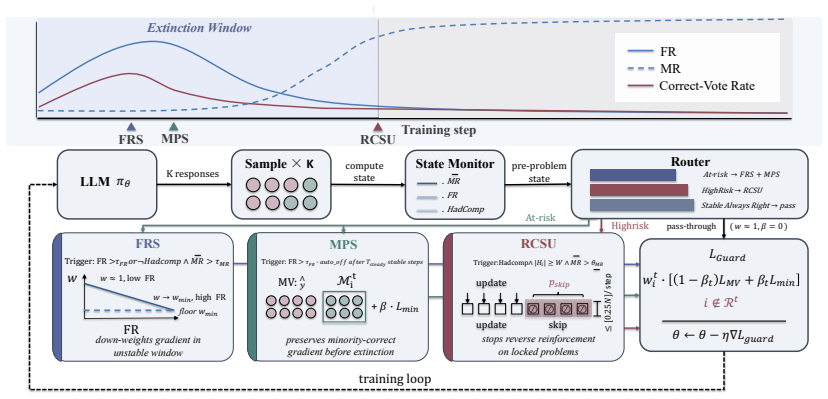
Per-problem tracking reveals that correct-answer signals in low-ability problems are briefly active before being permanently suppressed, a phenomenon termed the Correct-Answer Extinction Window, with Flip Rate as its leading indicator. This accounts for why problems corrupted from correct to incorrect outnumber truly learned ones and why the damage is irreversible once majority vote locks onto a wrong answer.
What carries the argument
The Correct-Answer Extinction Window, a brief period in low-ability problems where correct signals remain active before permanent suppression by majority vote, with declining Flip Rate as the leading indicator that signals when to intervene.
If this is right
- Accuracy gains in TTRL largely reflect sharpening of already-solvable problems rather than new learning.
- Corrupted problems outnumber truly learned ones due to irreversible locking.
- Intervention during the extinction window prevents damage and improves outcomes.
- TTRL-Guard achieves the best average pass@1 on certain models and up to +54% relative improvement on AIME 2025.
Where Pith is reading between the lines
- Similar locking effects may appear in other consensus-based pseudo-labeling methods beyond test-time RL.
- Flip rate monitoring could be adapted as a general safeguard in self-improvement loops for language models.
- Testing the framework on non-mathematical reasoning tasks would reveal if the extinction dynamic is domain-specific.
Load-bearing premise
The per-problem trajectories observed are caused by majority-vote locking rather than by other factors in the reinforcement learning update rule or model initialization.
What would settle it
A controlled experiment that replaces majority vote with ground-truth labels or a different non-majority signal and finds no brief correct-signal window or net corruption would falsify the claim.
Figures









read the original abstract
Test-time reinforcement learning (TTRL) reports substantial accuracy gains on mathematical reasoning benchmarks using majority vote as a pseudo-label signal. We argue these gains are systematically misinterpreted: most reflect sharpening of already-solvable problems rather than genuine learning, while problems corrupted from correct to incorrect outnumber truly learned ones, and this damage is irreversible once majority vote locks onto a wrong answer. Per-problem tracking reveals that correct-answer signals in low-ability problems are briefly active before being permanently suppressed, a phenomenon we term the \textit{Correct-Answer Extinction Window}, with Flip Rate (FR) as its leading indicator. We thus propose \textbf{TTRL-Guard}, a lightweight framework with three mechanisms targeting the extinction window: Flip-Rate-Aware Reward Scaling (FRS) down-weights at-risk updates as FR declines, Minority-Preserving Sampling (MPS) retains gradient signal from minority correct answers, and Risk-Conditioned Sparse Updatings (RCSU) suspends updates on polarized problems. Experiments across three models and four benchmarks show that TTRL-Guard achieves the best average pass@1 on Qwen2.5-7B-Instruct and Qwen3-4B, improves relatively over TTRL by +54\% on AIME 2025. \footnote{Our code and implementation details are available at https://github.com/linhxkkkk/TTRL-Guard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that TTRL gains from majority-vote pseudo-labels largely reflect sharpening of already-solvable problems rather than new learning; that problems corrupted from correct to incorrect outnumber truly learned ones; and that this damage is irreversible once majority vote locks. Per-problem tracking identifies a brief 'Correct-Answer Extinction Window' in low-ability problems, with Flip Rate (FR) as leading indicator. The authors propose TTRL-Guard (FRS reward scaling, MPS minority sampling, RCSU sparse updates) to intervene in the window and report best average pass@1 on Qwen2.5-7B and Qwen3-4B plus +54% relative gain on AIME 2025.
Significance. If the per-problem trajectory observations and the causal link to majority-vote locking hold, the work would meaningfully refine interpretation of TTRL results and supply practical safeguards against degradation. The code release supports reproducibility. However, the absence of isolating ablations and error bars leaves the headline claims about net corruption and irreversibility under-supported, limiting immediate impact.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the reported gains lack error bars, ablations that isolate FRS/MPS/RCSU, and a complete description of per-problem trajectory measurement. These omissions leave the central claims about irreversible corruption and the extinction window under-supported.
- [Proposed Method / Experiments] The claim that corrupted-from-correct problems outnumber truly learned ones and that damage is irreversible requires that the observed trajectories are specifically produced by majority-vote locking. No ablation holds the RL update rule fixed while removing or replacing the majority-vote component, so attribution remains correlational (see reader's weakest_assumption).
minor comments (2)
- [Method] Clarify the exact computation of Flip Rate (FR) and the 'decline threshold' hyper-parameter in the main text rather than relegating details to the appendix or code.
- [Experiments] Ensure all benchmark and model variants are listed with consistent pass@1 reporting; the +54% relative figure on AIME 2025 should be accompanied by absolute numbers for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical support for our claims about the Correct-Answer Extinction Window. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the reported gains lack error bars, ablations that isolate FRS/MPS/RCSU, and a complete description of per-problem trajectory measurement. These omissions leave the central claims about irreversible corruption and the extinction window under-supported.
Authors: We agree that error bars, isolating ablations, and expanded methodological details would improve support for the claims. In the revised manuscript we will add error bars computed across three independent runs with different random seeds for all reported pass@1 and relative-gain metrics. We will also include a new ablation table that evaluates FRS, MPS, and RCSU individually as well as in all pairwise and full combinations, holding all other factors fixed. Finally, we will expand the per-problem trajectory section with pseudocode, a precise definition of how answer flips and Flip Rate are computed at each TTRL step, and representative trajectory plots for both low- and high-ability problems. These additions directly address the under-support concern. revision: yes
-
Referee: [Proposed Method / Experiments] The claim that corrupted-from-correct problems outnumber truly learned ones and that damage is irreversible requires that the observed trajectories are specifically produced by majority-vote locking. No ablation holds the RL update rule fixed while removing or replacing the majority-vote component, so attribution remains correlational (see reader's weakest_assumption).
Authors: All reported trajectories are measured inside the standard TTRL loop that uses majority vote to generate the pseudo-label reward. For the low-ability problems we track, we observe an initial phase in which a minority of samples contain the correct answer; once the majority vote shifts to an incorrect answer, subsequent updates reinforce that incorrect answer and the Flip Rate falls to zero while correctness remains false. This locking behavior is therefore produced under the exact majority-vote mechanism that defines TTRL. We will add a clarifying paragraph in the revised version that explicitly links the observed irreversibility to the self-reinforcing property of the majority-vote signal rather than to the RL optimizer in isolation. A controlled ablation that replaces majority vote with an alternative pseudo-label source while keeping the rest of the update rule identical would require a non-standard baseline outside the TTRL setting; we therefore treat this as a partial revision consisting of the added discussion rather than new experiments. revision: partial
Circularity Check
No circularity: claims rest on independent per-problem tracking and novel interventions
full rationale
The paper defines the Correct-Answer Extinction Window from observed per-problem trajectories and introduces three new mechanisms (FRS, MPS, RCSU) whose performance is measured experimentally against baselines. No equation or central claim reduces by construction to a fitted parameter, self-definition, or self-citation chain. The derivation chain is self-contained against external benchmarks and does not rename known results or smuggle ansatzes via citation. This is the expected honest outcome for an empirical intervention paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- Flip-rate decline threshold for FRS
axioms (1)
- domain assumption Majority vote provides a usable pseudo-label signal for RL updates
invented entities (1)
-
Correct-Answer Extinction Window
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Per-problem tracking reveals that correct-answer signals in low-ability problems are briefly active before being permanently suppressed, a phenomenon we term the Correct-Answer Extinction Window, with Flip Rate (FR) as its leading indicator.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TTRL-Guard ... Flip-Rate-Aware Reward Scaling (FRS) ... Minority-Preserving Sampling (MPS) ... Risk-Conditioned Sparse Updatings (RCSU)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Online experiential learning for language models.arXiv preprint arXiv:2603.16856, 2026
Online Experiential Learning for Language Models , author=. arXiv preprint arXiv:2603.16856 , year=
-
[2]
arXiv preprint arXiv:2601.21590 , year =
Ji, Xiaotong and Tutunov, Rasul and Zimmer, Matthieu and Bou Ammar, Haitham , title =. arXiv preprint arXiv:2601.21590 , year =
-
[4]
arXiv preprint arXiv:2603.17775 , year =
Pan, Teng and Yan, Yuchen and Wang, Zixuan and Zhang, Ruiqing and Hou, Guiyang and Zhang, Wenqi and Lu, Weiming and Xiao, Jun and Shen, Yongliang , title =. arXiv preprint arXiv:2603.17775 , year =
-
[5]
arXiv preprint arXiv:2512.13106 , year =
Yang, Shenzhi and others , title =. arXiv preprint arXiv:2512.13106 , year =
-
[6]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Meta-Harness: End-to-End Optimization of Model Harnesses
Lee, Yoonho and Nair, Roshen and Zhang, Qizheng and Lee, Kangwook and Khattab, Omar and Finn, Chelsea , title =. arXiv preprint arXiv:2603.28052 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Reflexion: Language Agents with Verbal Reinforcement Learning
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik R and Yao, Shunyu , title =. arXiv preprint arXiv:2303.11366 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2603.02203 , year=
Tool Verification for Test-Time Reinforcement Learning , author=. arXiv preprint arXiv:2603.02203 , year=
-
[11]
Beyond Majority Voting: Towards Fine-grained and More Reliable Reward Signal for Test-Time Reinforcement Learning , author=. arXiv preprint arXiv:2512.15146 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Learning to Reason without External Rewards
Learning to reason without external rewards , author=. arXiv preprint arXiv:2505.19590 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2506.06395 , year=
Confidence is all you need: Few-shot rl fine-tuning of language models , author=. arXiv preprint arXiv:2506.06395 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
The unreasonable effectiveness of entropy minimization in llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Hugging Face repository , volume=
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author=. Hugging Face repository , volume=
-
[18]
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment , author=. arXiv preprint arXiv:2601.21484 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2603.15724 , year=
Meta-TTRL: A Metacognitive Framework for Self-Improving Test-Time Reinforcement Learning in Unified Multimodal Models , author=. arXiv preprint arXiv:2603.15724 , year=
-
[22]
International Conference on Learning Representations , volume=
Test-time training on nearest neighbors for large language models , author=. International Conference on Learning Representations , volume=
-
[23]
No free lunch: Rethinking internal feedback for llm reasoning.arXiv preprint arXiv:2506.17219, 2025
No free lunch: Rethinking internal feedback for llm reasoning , author=. arXiv preprint arXiv:2506.17219 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Absolute zero: Reinforced self-play reasoning with zero data , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2509.20186 , year=
Thinking augmented pre-training , author=. arXiv preprint arXiv:2509.20186 , year=
-
[27]
arXiv preprint arXiv:2503.00735 , year=
Ladder: Self-improving llms through recursive problem decomposition , author=. arXiv preprint arXiv:2503.00735 , year=
-
[28]
arXiv preprint arXiv:2508.12338 , year=
Wisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback , author=. arXiv preprint arXiv:2508.12338 , year=
-
[29]
arXiv preprint arXiv:2506.08007 , year=
Reinforcement pre-training , author=. arXiv preprint arXiv:2506.08007 , year=
-
[30]
arXiv preprint arXiv:2509.15194 , year =
Evolving language models without labels: Majority drives selection, novelty promotes variation , author=. arXiv preprint arXiv:2509.15194 , year=
-
[31]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Advances in neural information processing systems , volume=
Right question is already half the answer: Fully unsupervised llm reasoning incentivization , author=. Advances in neural information processing systems , volume=
-
[33]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
TTRL: Test-Time Reinforcement Learning
Zuo, Yuxin and Zhang, Kaiyan and Qu, Shang and Sheng, Li and Zhu, Xuekai and Huang, Biqing and others , title =. arXiv preprint arXiv:2504.16084 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Sun, Yu and Gao, Xinyu and others , title =. arXiv preprint arXiv:2407.04620 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Test-time training done right , author=. arXiv preprint arXiv:2505.23884 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2601.22628 , year=
TTCS: Test-Time Curriculum Synthesis for Self-Evolving , author=. arXiv preprint arXiv:2601.22628 , year=
-
[40]
arXiv preprint arXiv:2603.05357 , year=
DiSCTT: Consensus-Guided Self-Curriculum for Efficient Test-Time Adaptation in Reasoning , author=. arXiv preprint arXiv:2603.05357 , year=
-
[41]
arXiv preprint arXiv:2603.08660 , year=
How Far Can Unsupervised RLVR Scale LLM Training? , author=. arXiv preprint arXiv:2603.08660 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.