PhyGenHOI: Physically-Aware 4D Generation of Dynamic Human-Object Interactions
Pith reviewed 2026-06-29 08:14 UTC · model grok-4.3
The pith
PhyGenHOI generates 4D human-object interactions that follow physics by coupling a motion diffusion model to material point simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
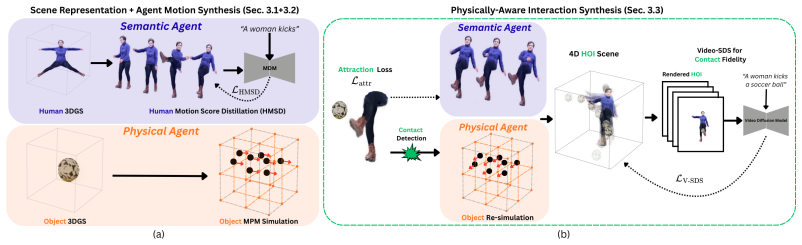
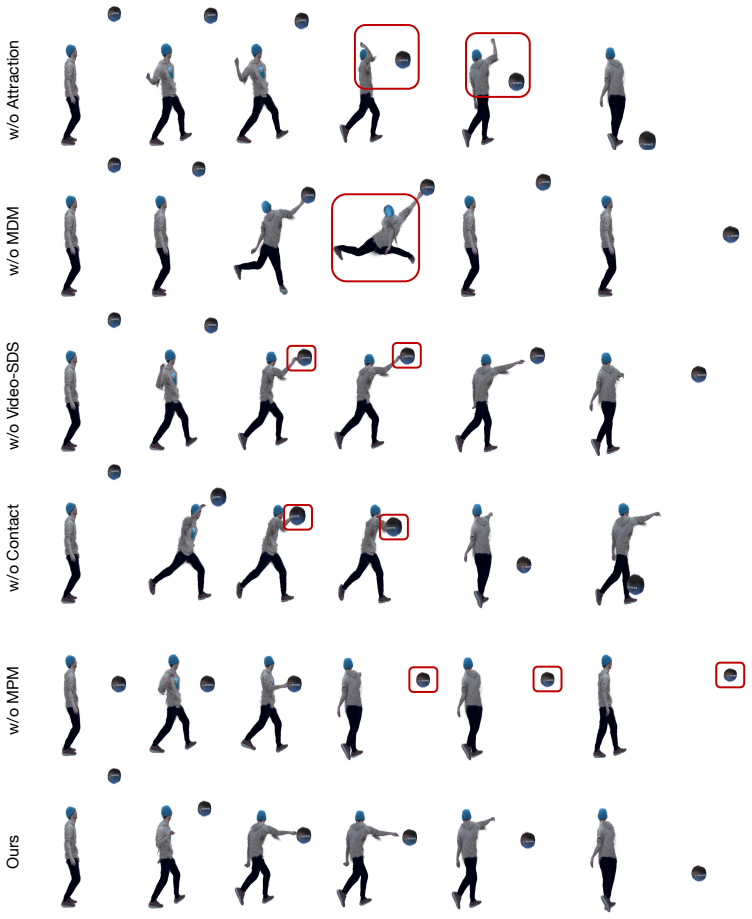
PhyGenHOI couples a Motion Diffusion Model that drives the human with a Material Point Method simulation that evolves the object, both represented as 3D Gaussian Splats. Their interaction is supervised by a Windowed Attraction Loss that aligns motion timing, a Contact-Driven Re-simulation step that transfers momentum at impact, and a Masked Video-SDS term that improves contact appearance. This produces 4D human-object interaction sequences that remain physically consistent across diverse actions, humans, and objects and that outperform prior baselines.
What carries the argument
The three supervision mechanisms—Windowed Attraction Loss, Contact-Driven Re-simulation, and Masked Video-SDS—that align generative human motion with explicit physical simulation inside a shared 3D Gaussian representation.
If this is right
- Text prompts can drive human actions that produce appropriate physical responses in the contacted object.
- The generated interactions remain consistent across different human shapes, object types, and action categories.
- Both physical correctness and visual quality exceed those of methods lacking explicit object simulation.
- The pipeline accepts static 3D Gaussian splat inputs and directly outputs dynamic 4D scenes.
Where Pith is reading between the lines
- The hybrid generative-plus-physical design could supply more reliable training data for robotic manipulation policies.
- Extending the re-simulation step to chains of contacts might handle multi-step actions without drift.
- Similar separation of agents could be tested on scenes that include multiple objects or non-rigid bodies.
Load-bearing premise
The three supervision mechanisms together produce physically accurate momentum transfer and contact without creating visual or dynamic artifacts that would need extra correction.
What would settle it
Generate a kick sequence, measure the object's velocity and path immediately after contact, and check whether those values match the outcome predicted by conservation of momentum given the recorded contact velocity and object mass.
Figures
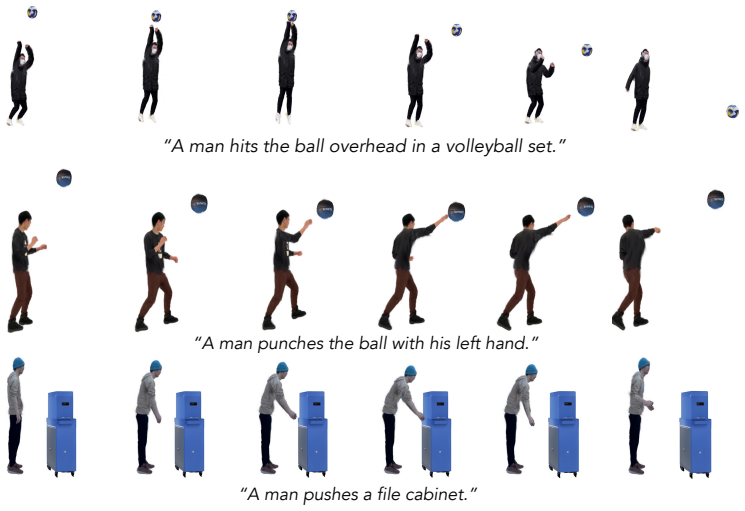
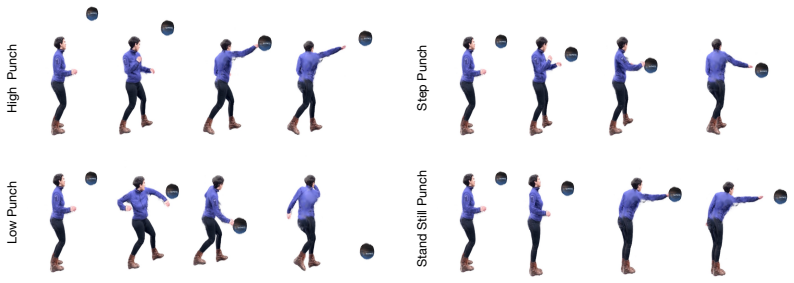


read the original abstract
We address the task of generating physically accurate and visually faithful 4D Human-Object Interaction (HOI). Given a static 3D human and target object represented as 3D Gaussian Splats (3DGS), our goal is to synthesize dynamic scenes where the human actively engages with the object through actions, such as punching or kicking, in accordance with a given input text. To this end, we introduce PhyGenHOI, a novel framework that couples generative human motion with an explicit physical object simulation. We model the human as a semantic agent driven by a Motion Diffusion Model (MDM) and the object as a physical agent simulated via the Material Point Method (MPM), utilizing 3D Gaussians as a unified, differentiable representation. We supervise their interaction through three coupled mechanisms: (1) A Windowed Attraction Loss that temporally synchronizes generative motion to intercept the object; (2) A Contact-Driven Re-simulation step that triggers physically consistent momentum transfer upon impact; and (3) A Masked Video-SDS objective that injects video-based priors to enhance contact fidelity. Experiments show PhyGenHOI generates physically consistent 4D HOI across diverse actions, humans, and objects, outperforming baselines. Project page and videos: https://omerbenishu.github.io/PhyGenHOI/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PhyGenHOI, a framework for synthesizing 4D human-object interactions from static 3D human and object Gaussian splats and text prompts. Human motion is generated via a Motion Diffusion Model (MDM) while the object is simulated with the Material Point Method (MPM); the two are coupled through a Windowed Attraction Loss for temporal synchronization, a Contact-Driven Re-simulation step for momentum transfer at impact, and a Masked Video-SDS objective for contact fidelity. The central claim is that the resulting 4D sequences are physically consistent and visually faithful, outperforming baselines across diverse actions, humans, and objects.
Significance. If the physical-consistency claims are substantiated, the work would advance generative 4D modeling by demonstrating a practical hybrid of data-driven human motion and explicit physics simulation within a differentiable 3DGS representation. The unified representation and the three coupled supervision mechanisms constitute a concrete technical contribution that could be adopted in graphics, robotics, and AR/VR pipelines.
major comments (2)
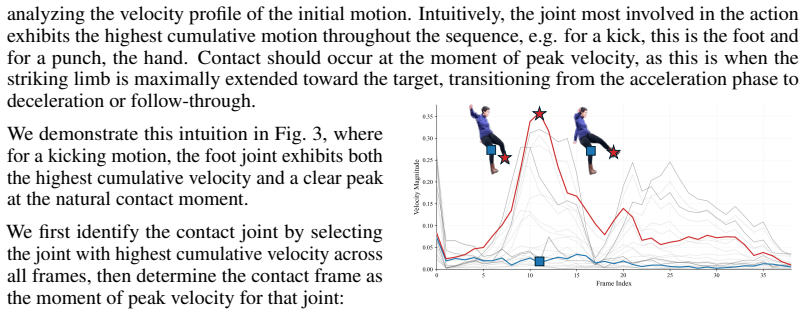
- [Method (Contact-Driven Re-simulation)] The Contact-Driven Re-simulation step (method description) asserts that momentum is transferred from the non-physical MDM human to the MPM object upon detected contact, yet no derivation, update rule, or conservation check is supplied. Without an explicit equation showing how linear and angular momentum are computed and applied while preserving conservation, or an ablation comparing trajectories to an independent physics solver, the central claim of physical accuracy rests on an unverified assumption.
- [Experiments] Experiments are summarized only at the level of qualitative superiority; no quantitative metrics (e.g., penetration depth, velocity error, or momentum residual) or ablation tables isolating the three supervision terms are referenced. This absence directly undermines the assertion that the generated interactions are “physically consistent” rather than merely visually plausible.
minor comments (2)
- [Abstract / Introduction] The abstract and method overview use “3D Gaussian Splats (3DGS)” without an initial citation to the original 3DGS paper; a reference should be added on first use.
- [Figures / Videos] Figure captions and video descriptions should explicitly state the frame rate and total duration of the generated sequences so readers can assess temporal consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of PhyGenHOI. We will revise the manuscript to provide the requested mathematical details and quantitative evaluations. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Method (Contact-Driven Re-simulation)] The Contact-Driven Re-simulation step (method description) asserts that momentum is transferred from the non-physical MDM human to the MPM object upon detected contact, yet no derivation, update rule, or conservation check is supplied. Without an explicit equation showing how linear and angular momentum are computed and applied while preserving conservation, or an ablation comparing trajectories to an independent physics solver, the central claim of physical accuracy rests on an unverified assumption.
Authors: We agree that the manuscript would benefit from an explicit formulation. In the revision we will add a dedicated subsection deriving the momentum-transfer rule: at each detected contact frame we compute the human's linear velocity at the contact Gaussians via finite differences on the MDM trajectory, convert to impulse using the effective mass at contact, and distribute the resulting linear and angular momentum increments to the affected MPM particles while enforcing local momentum conservation up to floating-point tolerance. We will also include a new ablation that replays the same contact events in an independent MPM solver (without the human motion prior) and reports trajectory deviation metrics, thereby directly substantiating the physical-consistency claim. revision: yes
-
Referee: [Experiments] Experiments are summarized only at the level of qualitative superiority; no quantitative metrics (e.g., penetration depth, velocity error, or momentum residual) or ablation tables isolating the three supervision terms are referenced. This absence directly undermines the assertion that the generated interactions are “physically consistent” rather than merely visually plausible.
Authors: We concur that quantitative evidence is necessary to support the physical-consistency claim. The revised manuscript will report three new metrics averaged over 50 generated sequences: (i) mean penetration depth between human and object Gaussians, (ii) velocity error at contact points relative to an MPM ground-truth rollout, and (iii) momentum residual (change in total system momentum). We will also add an ablation table that isolates each of the three supervision terms (Windowed Attraction Loss, Contact-Driven Re-simulation, Masked Video-SDS) by successively removing them and measuring the same metrics, together with qualitative examples. These additions will be placed in a new “Quantitative Evaluation” subsection. revision: yes
Circularity Check
Hybrid MDM-MPM pipeline exhibits no load-bearing circularity; physical consistency derives from explicit simulation rather than generative inputs.
full rationale
The paper couples an external Motion Diffusion Model (MDM) for human motion with Material Point Method (MPM) simulation for the object, using three explicit supervision mechanisms (Windowed Attraction Loss, Contact-Driven Re-simulation, Masked Video-SDS). No step reduces a claimed physical prediction to a fitted parameter or self-citation by construction; the re-simulation step invokes standard MPM momentum transfer outside the generative model. Central claims rest on experimental comparison to baselines rather than internal redefinition. This qualifies as minor (score 2) only due to the hybrid nature, but the derivation chain remains independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[2]
4d-fy: Text-to-4d generation using hybrid score distillation sampling
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B Lindell. 4d-fy: Text-to-4d generation using hybrid score distillation sampling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7996–8006, 2024
2024
-
[3]
An- imate124: Animating one image to 4d dynamic scene.arXiv preprint arXiv:2311.14603, 2023
Yuyang Zhao, Zhiwen Yan, Enze Xie, Lanqing Hong, Zhenguo Li, and Gim Hee Lee. An- imate124: Animating one image to 4d dynamic scene.arXiv preprint arXiv:2311.14603, 2023
-
[4]
Dreamgaussian4d: Generative 4d gaussian splatting.arXiv preprint arXiv:2312.17142, 2023
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. Dreamgaussian4d: Generative 4d gaussian splatting.arXiv preprint arXiv:2312.17142, 2023
-
[5]
Yukang Cao, Liang Pan, Kai Han, Kwan-Yee K Wong, and Ziwei Liu. Avatargo: Zero-shot 4d human-object interaction generation and animation.arXiv preprint arXiv:2410.07164, 2024
-
[6]
Interdreamer: Zero-shot text to 3d dynamic human-object interaction.Advances in Neural Information Processing Systems, 37:52858– 52890, 2024
Sirui Xu, Yu-Xiong Wang, Liangyan Gui, et al. Interdreamer: Zero-shot text to 3d dynamic human-object interaction.Advances in Neural Information Processing Systems, 37:52858– 52890, 2024
2024
-
[7]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
2023
-
[8]
Zijie Wu, Chaohui Yu, Fan Wang, and Xiang Bai. Animateanymesh: A feed-forward 4d foundation model for text-driven universal mesh animation.arXiv preprint arXiv:2506.09982, 2025
-
[9]
Animus3d: Text-driven 3d animation via motion score distillation
Qi Sun, Can Wang, Jiaxiang Shang, Wensen Feng, and Jing Liao. Animus3d: Text-driven 3d animation via motion score distillation. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[10]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation.arXiv preprint arXiv:2309.16653, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, and Xinggang Wang. Gaussiandreamer: Fast generation from text to 3d gaussians by bridging 2d and 3d diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6796–6807, 2024
2024
-
[13]
Yanqin Jiang, Li Zhang, Jin Gao, Weimin Hu, and Yao Yao. Consistent4d: Consistent 360 {\deg} dynamic object generation from monocular video.arXiv preprint arXiv:2311.02848, 2023
-
[14]
Choreographing a world of dynamic objects, 2026
Yanzhe Lyu, Chen Geng, Karthik Dharmarajan, Yunzhi Zhang, Hadi AlZayer, Shangzhe Wu, and Jiajun Wu. Choreographing a world of dynamic objects, 2026. URL https://arxiv. org/abs/2601.04194
-
[15]
Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023
Jiaman Li, Jiajun Wu, and C Karen Liu. Object motion guided human motion synthesis.ACM Transactions on Graphics (TOG), 42(6):1–11, 2023
2023
-
[16]
Syncdiff: Synchronized motion diffusion for multi-body human-object interaction synthesis
Wenkun He, Yun Liu, Ruitao Liu, and Li Yi. Syncdiff: Synchronized motion diffusion for multi-body human-object interaction synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11731–11743, 2025
2025
-
[17]
Roey Ron, Guy Tevet, Haim Sawdayee, and Amit H Bermano. Hoidini: Human-object interaction through diffusion noise optimization.arXiv preprint arXiv:2506.15625, 2025. 10
-
[18]
Animate3d: Animating any 3d model with multi-view video diffusion.Advances in Neural Information Processing Systems, 37:125879–125906, 2024
Yanqin Jiang, Chaohui Yu, Chenjie Cao, Fan Wang, Weiming Hu, and Jin Gao. Animate3d: Animating any 3d model with multi-view video diffusion.Advances in Neural Information Processing Systems, 37:125879–125906, 2024
2024
-
[19]
Articulated kinematics distillation from video diffusion models
Xuan Li, Qianli Ma, Tsung-Yi Lin, Yongxin Chen, Chenfanfu Jiang, Ming-Yu Liu, and Donglai Xiang. Articulated kinematics distillation from video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17571–17581, 2025
2025
-
[20]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics-integrated 3d gaussians for generative dynamics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4389–4398, 2024
2024
-
[21]
Dreamphysics: Learning physics-based 3d dynamics with video diffusion priors
Tianyu Huang, Haoze Zhang, Yihan Zeng, Zhilu Zhang, Hui Li, Wangmeng Zuo, and Ryn- son WH Lau. Dreamphysics: Learning physics-based 3d dynamics with video diffusion priors. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3733–3741, 2025
2025
-
[22]
Haoyu Zhao, Hao Wang, Xingyue Zhao, Hao Fei, Hongqiu Wang, Chengjiang Long, and Hua Zou. Efficient physics simulation for 3d scenes via mllm-guided gaussian splatting.arXiv preprint arXiv:2411.12789, 2024
-
[23]
Hugs: Human gaussian splats
Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. Hugs: Human gaussian splats. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 505–515, 2024
2024
-
[24]
A material point method for snow simulation.ACM Transactions on Graphics (TOG), 32(4):1–10, 2013
Alexey Stomakhin, Craig Schroeder, Lawrence Chai, Joseph Teran, and Andrew Selle. A material point method for snow simulation.ACM Transactions on Graphics (TOG), 32(4):1–10, 2013
2013
-
[25]
The material point method for simulating continuum materials
Chenfanfu Jiang, Craig Schroeder, Joseph Teran, Alexey Stomakhin, and Andrew Selle. The material point method for simulating continuum materials. InAcm siggraph 2016 courses, pages 1–52. 2016
2016
-
[26]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model.arXiv preprint arXiv:2209.14916, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[29]
Structured 3D Latents for Scalable and Versatile 3D Generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Black, Gül Varol, Xue Bin Peng, and Davis Rempe
Mathis Petrovich, Or Litany, Umar Iqbal, Michael J. Black, Gül Varol, Xue Bin Peng, and Davis Rempe. Multi-track timeline control for text-driven 3d human motion generation. InCVPR Workshop on Human Motion Generation, 2024
2024
-
[31]
Taichi: a language for high-performance computation on spatially sparse data structures.ACM Transac- tions on Graphics (TOG), 38(6):1–16, 2019
Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan-Kelley, and Frédo Durand. Taichi: a language for high-performance computation on spatially sparse data structures.ACM Transac- tions on Graphics (TOG), 38(6):1–16, 2019
2019
-
[32]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 11 A Interactive Visualizations We refer readers to the interactive visualizations on our project page at https...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
The axis-aligned bounding boxes overlap:B jc(tc)∩ B obj(tc)̸=∅
-
[34]
A man punches the ball with his left hand
At least τcontact = 0.05 fraction of joint jc’s Gaussians lie within distancedcontact = 0.01 of the nearest object Gaussian. V elocity Update.Upon detecting contact, we compute the momentum transfer as follows. The human velocityV human is estimated from the contact joint’s displacement: Vhuman = pjc(tc)−p jc(tc −1) ∆t ,(7) 12 where ∆t= 1 . The contact no...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.