DRIFT: A Residual Flow Adapter for Decoding Continuous Outputs in Vision-Language Models
Pith reviewed 2026-06-28 02:58 UTC · model grok-4.3
The pith
DRIFT adapts vision-language models for continuous outputs by modeling residuals with flow matching around a base predictor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
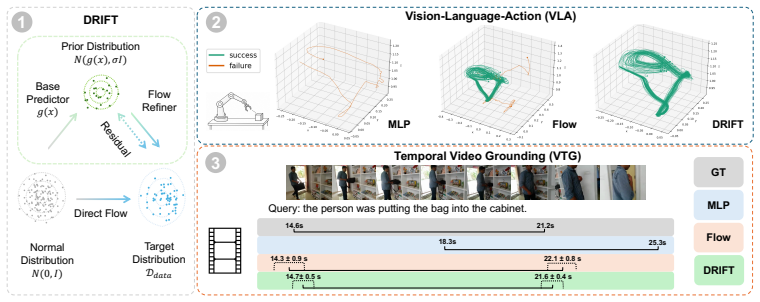
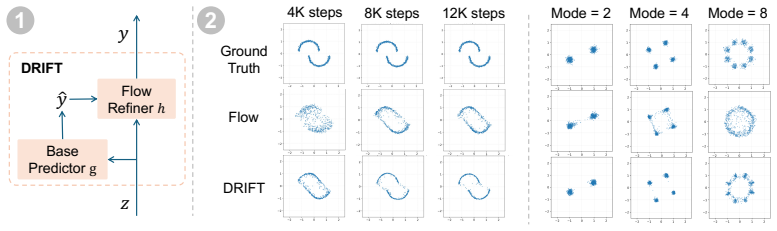
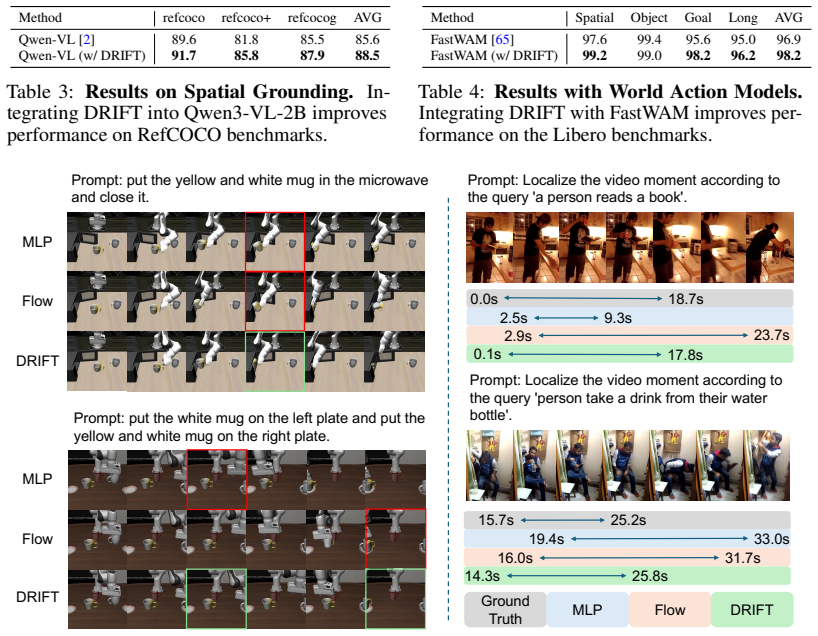
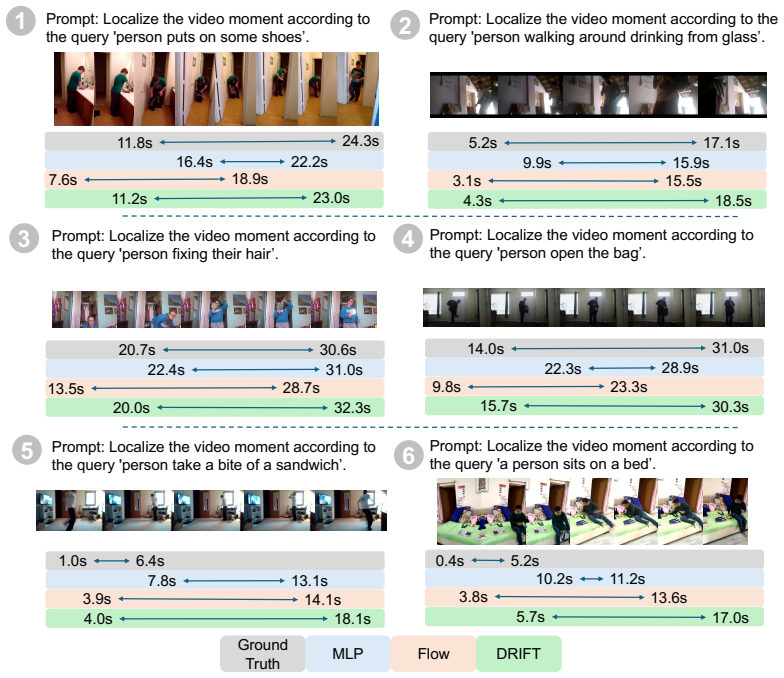
DRIFT combines a base predictor, which provides a coarse estimate of the target output, with a generative refinement module based on flow matching that iteratively improves the prediction. This residual formulation transforms the generative modeling problem from learning a global output distribution to modeling a localized residual distribution around a strong prior, substantially simplifying optimization. Across multiple tasks and architectures spanning MLLMs, VLAs, and WAMs, DRIFT consistently outperforms a strong set of regression- and generative-based solutions on perception and planning tasks including visual grounding and robotic control.
What carries the argument
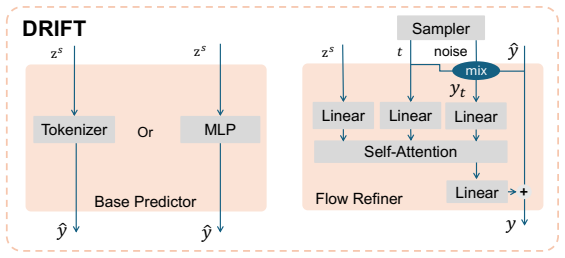
Residual flow adapter, which pairs a base predictor's coarse output with flow-matching refinement that models only the localized residual distribution.
If this is right
- DRIFT outperforms regression- and generative-based solutions on visual grounding and robotic control tasks.
- It works across MLLMs, VLAs, and WAMs without architecture-specific changes.
- The residual approach simplifies optimization by focusing on localized distributions rather than global ones.
- Continuous decoding becomes feasible in pretrained VLMs while preserving their discrete text strengths.
Where Pith is reading between the lines
- If the base predictor quality varies across domains, DRIFT performance would track that quality more closely than a non-residual generative model would.
- The same residual idea could be tested on hybrid tasks that mix discrete tokens with continuous values in a single output sequence.
- Applying DRIFT to modalities beyond vision and language, such as audio or sensor streams, would test whether the simplification holds when priors are weaker.
Load-bearing premise
A sufficiently accurate base predictor must exist to supply a strong prior whose residual is localized and therefore simpler to model than the full target distribution.
What would settle it
Train and evaluate DRIFT on a task where the base predictor is replaced by a deliberately weak or random estimator, then compare performance against direct generative baselines to check whether gains disappear.
Figures
read the original abstract
Many modern vision-language models (VLMs) build on autoregressive decoding of discrete tokens. While text-based output interfaces enable scalable pretraining and strong zero-shot generalization across diverse tasks, they are poorly suited for problems that require precise continuous outputs, such as localizing temporal boundaries of events or generating robotic control actions. To address this challenge, we propose DRIFT, a general framework for adapting pretrained VLMs to continuous decoding tasks. DRIFT combines a base predictor, which provides a coarse estimate of the target output, with a generative refinement module based on flow matching that iteratively improves the prediction. This residual formulation transforms the generative modeling problem from learning a global output distribution to modeling a localized residual distribution around a strong prior, substantially simplifying optimization. We evaluate DRIFT on both perception and planning tasks, including visual grounding and robotic control. Across multiple tasks and architectures spanning MLLMs, VLAs, and WAMs, DRIFT consistently outperforms a strong set of regression- and generative-based solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DRIFT, a framework for adapting pretrained vision-language models (VLMs) to continuous-output tasks. It combines a base predictor providing a coarse estimate with a flow-matching generative module that models residuals around this prior. The central claim is that this residual formulation simplifies the generative modeling problem relative to direct global distribution learning, yielding consistent outperformance over regression- and generative-based baselines on perception (e.g., visual grounding) and planning (e.g., robotic control) tasks across MLLMs, VLAs, and WAMs.
Significance. If the empirical gains are robust and the residual simplification is substantiated, the work could provide a practical route for extending discrete-token VLMs to precise continuous decoding without full retraining, with potential impact on robotics and temporal localization.
major comments (2)
- [Abstract] Abstract: the central claim that the residual formulation 'substantially simplifying optimization' by transforming the problem to a 'localized residual distribution around a strong prior' is asserted without any supporting analysis (variance reduction, modality count, support size, or training-curve comparison) of the base predictor's error distribution. This is load-bearing for the claimed advantage over direct generative modeling.
- [Abstract] Abstract and evaluation sections: the statement of 'consistent outperformance' across tasks and architectures supplies no quantitative results, error bars, dataset sizes, or ablation evidence in the provided abstract; the full manuscript must include these to substantiate the cross-architecture claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the abstract claims. We address each major comment below and will make targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the residual formulation 'substantially simplifying optimization' by transforming the problem to a 'localized residual distribution around a strong prior' is asserted without any supporting analysis (variance reduction, modality count, support size, or training-curve comparison) of the base predictor's error distribution. This is load-bearing for the claimed advantage over direct generative modeling.
Authors: We agree the abstract would be strengthened by direct supporting analysis for this claim. The full manuscript provides indirect support via consistent empirical gains over direct generative baselines, but does not include explicit variance reduction or training-curve comparisons of the base predictor error distribution. We will revise by adding a short analysis (e.g., error distribution statistics or training dynamics) in the methods/experiments section and referencing it from the abstract. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: the statement of 'consistent outperformance' across tasks and architectures supplies no quantitative results, error bars, dataset sizes, or ablation evidence in the provided abstract; the full manuscript must include these to substantiate the cross-architecture claim.
Authors: The full manuscript already reports quantitative results with error bars, dataset sizes, and ablations across MLLMs, VLAs, and WAMs in the evaluation sections. To address the abstract specifically, we will revise it to include key quantitative highlights (e.g., average improvements with error bars) while keeping it concise, thereby substantiating the cross-architecture claim. revision: yes
Circularity Check
No circularity; empirical framework with no self-referential derivations or fitted predictions
full rationale
The paper presents DRIFT as an empirical framework that pairs a base predictor with a flow-matching residual module. The abstract's claim that the residual formulation simplifies optimization is a modeling hypothesis, not a mathematical derivation that reduces to its own inputs by construction. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. Evaluation rests on comparative experiments across tasks and architectures rather than any closed loop where outputs are defined by or forced from the method's own definitions. This is the common case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DRIFT residual flow adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikoł aj Bi´nk...
2022
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
2025
-
[6]
π0: A vision-language-action flow model for general robot control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
2025
-
[7]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, et al. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[9]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding.arXiv preprint arXiv:2601.10611, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
2025
-
[11]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[12]
TALL: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. TALL: Temporal activity localization via language query. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 5267–5275, 2017
2017
-
[13]
Localizing moments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017
2017
-
[14]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020
2020
-
[15]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[16]
VTimeLLM: Empower LLM to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. VTimeLLM: Empower LLM to grasp video moments. InCVPR, 2024
2024
-
[17]
Prismatic vlms: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[18]
Referitgame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014
2014
-
[19]
Language-free training for zero-shot video grounding
Dahye Kim, Jungin Park, Jiyoung Lee, Seongheon Park, and Kwanghoon Sohn. Language-free training for zero-shot video grounding. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2539–2548, January 2023
2023
-
[20]
OpenVLA: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model. InCoRL, 2024
2024
-
[21]
Dense- captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense- captioning events in videos. InProceedings of the IEEE international conference on computer vision, pages 706–715, 2017
2017
-
[22]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19730–19742. PMLR, 23–29 Jul 2023
2023
-
[23]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[24]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. In Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of M...
2025
-
[26]
UniVTG: Towards unified video-language temporal grounding
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jin- peng Wang, Rui Yan, and Mike Zheng Shou. UniVTG: Towards unified video-language temporal grounding. InICCV, 2023
2023
-
[27]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[28]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[29]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[30]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Unitime: A language-empowered unified model for cross-domain time series forecasting
Xu Liu, Junfeng Hu, Yuan Li, Shizhe Diao, Yuxuan Liang, Bryan Hooi, and Roger Zimmermann. Unitime: A language-empowered unified model for cross-domain time series forecasting. In Proceedings of the ACM Web Conference 2024, WWW ’24, page 4095–4106, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400701719. doi: 10.1145/ 3589334.3645434
-
[32]
Ye Liu, Zongyang Ma, Zhongang Qi, Yang Wu, Ying Shan, and Chang Wen Chen. E.t. bench: Towards open-ended event-level video-language understanding. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[33]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations
-
[34]
Valley: Video assistant with large language model enhanced ability
Ruipu Luo, Ziwang Zhao, Min Yang, Zheming Yang, Minghui Qiu, Zhongyu Wei, Yanhao Wang, and Cen Chen. Valley: Video assistant with large language model enhanced ability. ACM Trans. Multimedia Comput. Commun. Appl., February 2026. ISSN 1551-6857. doi: 10.1145/3796716
-
[35]
Video-ChatGPT: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-ChatGPT: Towards detailed video understanding via large vision and language models. InProceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[36]
Yuille, and Kevin Murphy
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L. Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[37]
Trespassing the boundaries: Labeling temporal bounds for object interactions in egocentric video
Davide Moltisanti, Michael Wray, Walterio Mayol-Cuevas, and Dima Damen. Trespassing the boundaries: Labeling temporal bounds for object interactions in egocentric video. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017
2017
-
[38]
Snag: Scalable and accurate video grounding
Fangzhou Mu, Sicheng Mo, and Yin Li. Snag: Scalable and accurate video grounding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18930–18940, 2024
2024
-
[39]
Zero-shot natural language video localization
Jinwoo Nam, Daechul Ahn, Dongyeop Kang, Seong Jong Ha, and Jonghyun Choi. Zero-shot natural language video localization. InICCV, 2021. 12
2021
-
[40]
Henriques, Yang Liu, Andrew Zisserman, and Samuel Albanie
Andreea-Maria Oncescu, João F. Henriques, Yang Liu, Andrew Zisserman, and Samuel Albanie. QuerYD: A video dataset with high-quality text and audio narrations. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021
2021
-
[41]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[43]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Enrich and detect: Video temporal grounding with multimodal LLMs
Shraman Pramanick, Effrosyni Mavroudi, Yale Song, Rama Chellappa, Lorenzo Torresani, and Triantafyllos Afouras. Enrich and detect: Video temporal grounding with multimodal LLMs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[45]
Momentor: Advancing video large language model with fine-grained temporal reasoning
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat-Seng Chua, Yueting Zhuang, and Siliang Tang. Momentor: Advancing video large language model with fine-grained temporal reasoning. InICML, 2024
2024
-
[46]
Chatvtg: Video temporal grounding via chat with video dialogue large language models
Mengxue Qu, Xiaodong Chen, Wu Liu, Alicia Li, and Yao Zhao. Chatvtg: Video temporal grounding via chat with video dialogue large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 1847–1856, June 2024
2024
-
[47]
TimeChat: A time-sensitive multimodal large language model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. TimeChat: A time-sensitive multimodal large language model for long video understanding. InCVPR, 2024
2024
-
[48]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022
2022
-
[49]
Hollywood in homes: Crowdsourcing data collection for activity understanding
Gunnar A Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. InEuropean Conference on Computer Vision, pages 510–526. Springer, 2016
2016
-
[50]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021
2021
-
[51]
Moment quantization for video temporal grounding
Xiaolong Sun et al. Moment quantization for video temporal grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025
2025
-
[52]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[53]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
arXiv preprint arXiv:2401.00849 , year=
Alex Jinpeng Wang, Linjie Li, Kevin Qinghong Lin, Jianfeng Wang, Kevin Lin, Zhengyuan Yang, Lijuan Wang, and Mike Zheng Shou. COSMO: COntrastive streamlined MultimOdal model with interleaved pre-training.arXiv preprint arXiv:2401.00849, 2024
-
[55]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
InternVid: A large-scale video-text dataset for multimodal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. InternVid: A large-scale video-text dataset for multimodal understanding and generation. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[57]
Vla-adapter: An effective paradigm for tiny-scale vision-language-action model
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, et al. Vla-adapter: An effective paradigm for tiny-scale vision-language-action model. InProceedings of the AAAI conference on artificial intelligence, volume 40, pages 18638–18646, 2026
2026
-
[58]
Hawkeye: Training video-text llms for grounding text in videos,
Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. HawkEye: Training video-text LLMs for grounding text in videos.arXiv:2403.10228, 2024
-
[59]
Towards visual grounding: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Linhui Xiao, Xiaoshan Yang, Xiangyuan Lan, Yaowei Wang, and Changsheng Xu. Towards visual grounding: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[60]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv e-prints, pages arXiv–2412, 2024
2024
-
[61]
Vlaser: Vision-language-action model with synergistic embodied reasoning
Ganlin Yang, Tianyi Zhang, Haoran Hao, Weiyun Wang, Yibin Liu, Dehui Wang, Guanzhou Chen, Zijian Cai, Junting Chen, Weijie Su, Wengang Zhou, Yu Qiao, Jifeng Dai, Jiangmiao Pang, Gen Luo, Wenhai Wang, Yao Mu, and Zhi Hou. Vlaser: Vision-language-action model with synergistic embodied reasoning. InThe Fourteenth International Conference on Learning Represen...
2026
-
[62]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
2016
-
[64]
Self-chained image-language model for video localization and question answering
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering. InNeurIPS, 2023
2023
-
[65]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[67]
Hierarchical video-moment retrieval and step-captioning
Abhay Zala, Jaemin Cho, Satwik Kottur, Xilun Chen, Barlas O ˘guz, Yashar Mehdad, and Mohit Bansal. Hierarchical video-moment retrieval and step-captioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[68]
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. InEMNLP (Demo), 2023
2023
-
[69]
VLM4VLA: Revis- iting vision-language-models in vision-language-action models
Jianke Zhang, Xiaoyu Chen, Yanjiang Guo, Yucheng Hu, and Jianyu Chen. VLM4VLA: Revis- iting vision-language-models in vision-language-action models. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[70]
Timelens: Rethinking video temporal grounding with multi- modal llms,
Jun Zhang, Teng Wang, Yuying Ge, Yixiao Ge, Xinhao Li, Ying Shan, and Limin Wang. Timelens: Rethinking video temporal grounding with multimodal llms.arXiv preprint arXiv:2512.14698, 2025
-
[71]
(Br +B h)Rn(H) + (Br +B h)2 r log(2/δ) n # . (13) Furthermore, sincew(t)≥1, R(0)− R( ˆh)≥E ∥m(X)∥ 2 2 −App H −Cτ −2
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 14 A A Statistical Perspective on Residual Refinement A.1 Notation and Setup Let z∈ Z ...
2023
-
[72]
16 For fixed (r, t), the map u7→ϕ r,t(u) =w(t)∥u−r∥ 2 2 is Lipschitz in u with constant at most 2τ −2(Bh +B r)
By A1andA2,1≤w(t)≤τ −2 and∥h(X)−r∥ 2 ≤B h +B r, so0≤ℓ h ≤τ −2(Bh +B r)2. 16 For fixed (r, t), the map u7→ϕ r,t(u) =w(t)∥u−r∥ 2 2 is Lipschitz in u with constant at most 2τ −2(Bh +B r). By the vector-valued Rademacher contraction inequality, Rn {ℓh :h∈ H} ≤C 1τ −2(Bh +B r)Rn(H), where C1 is an absolute constant. The standard Rademacher generalization bound...
-
[73]
Decomposing the right-hand side: L(ˆh)− L(m) = L(ˆh)− L(h ⋆ H) + L(h⋆ H)− L(m) = L(ˆh)− L(h ⋆ H) + AppH
Sincew(t)≥1, E ∥ˆh(X)−m(X)∥ 2 2 ≤E w(t)∥ˆh(X)−m(X)∥ 2 2 =L( ˆh)− L(m). Decomposing the right-hand side: L(ˆh)− L(m) = L(ˆh)− L(h ⋆ H) + L(h⋆ H)− L(m) = L(ˆh)− L(h ⋆ H) + AppH. HenceR( ˆh)− R(m)≤App H + (RHS of Eq. (13)). From Theorem 3,R(0)− R(m) =E[∥m(X)∥ 2 2]. Therefore R(0)− R(ˆh) = R(0)− R(m) − R(ˆh)− R(m) ≥E ∥m(X)∥ 2 2 −App H −(RHS of Eq. (13)), whic...
-
[74]
17 Conversely, for any full-target predictor H, define hH(X)≜H( ˜X)−g(z) , where ˜X= (y t −(1− t)g(z), t, z)
Multiplying by w(t) and taking expectations gives LFM(Hh) = L(h). 17 Conversely, for any full-target predictor H, define hH(X)≜H( ˜X)−g(z) , where ˜X= (y t −(1− t)g(z), t, z). Then hH(X)−r=H( ˜X)−g(z)−(y−g(z)) =H( ˜X)−y, soL(h H) =L FM(H). This loss-preserving bijection implies Eq. (17). Interpretation.Since the unrestricted population optima coincide, DR...
-
[75]
(19) The corresponding velocity targets satisfy E∥v ⋆ dir∥2 2 =E∥y∥ 2 2 +E∥σϵ∥ 2 2,(20) E∥v ⋆ res∥2 2 =E∥r∥ 2 2 +E∥σϵ∥ 2
-
[76]
(21) Consequently, E∥v ⋆ dir∥2 2 −E∥v ⋆ res∥2 2 =E∥y∥ 2 2 −E∥r∥ 2 2 =E∥µ(z)∥ 2 2 −E∥µ(z)−g(z)∥ 2
-
[77]
(22) Thus, whenever the base predictor explains more conditional-mean energy than the zero predictor, E∥µ(z)−g(z)∥ 2 2 <E∥µ(z)∥ 2 2, (23) the residual correction target and the residual velocity target have smaller second moment than their direct-FM counterparts. Moreover, Cov(r|z) = Cov(y|z), (24) so residualization does not remove the irreducible condit...
-
[78]
(26) Therefore, ifE∥r∥ 2 2 ≤ηE∥y∥ 2 2 for someη <1, then ρres(t)≤ρ dir(t)−t 2(1−η)E∥y∥ 2
-
[79]
LinearLinearLinear noise𝑡z! Self-Attention+𝑦Linear Sampler 𝑦!mix Base Predictor MLPTokenizerOr z! z! 𝑦
(27) Moreover, for any radiusa >0, P ∥yt −g(z)∥ 2 > a ≤ (1−t) 2 E∥σϵ∥ 2 2 +t 2 E∥r∥ 2 2 a2 . (28) Proof.Using the DRIFT bridge, yt −g(z) = (1−t)σϵ+t(y−g(z)) = (1−t)σϵ+tr. Expanding the squared norm and using the independence and zero mean ofϵgives E∥y t −g(z)∥ 2 2 = (1−t) 2 E∥σϵ∥ 2 2 +t 2 E∥r∥ 2 2, which proves Eq. (25). Similarly, the direct FM bridge sa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.