BiliVLA: Scene-Aware Vision-Language-Action Model with Reinforcement Learning for Autonomous Biliary Endoscopic Navigation
Pith reviewed 2026-07-02 21:33 UTC · model grok-4.3
The pith
BiliVLA combines scene-aware vision-language-action modeling with reinforcement learning to navigate endoscopes autonomously during ERCP procedures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
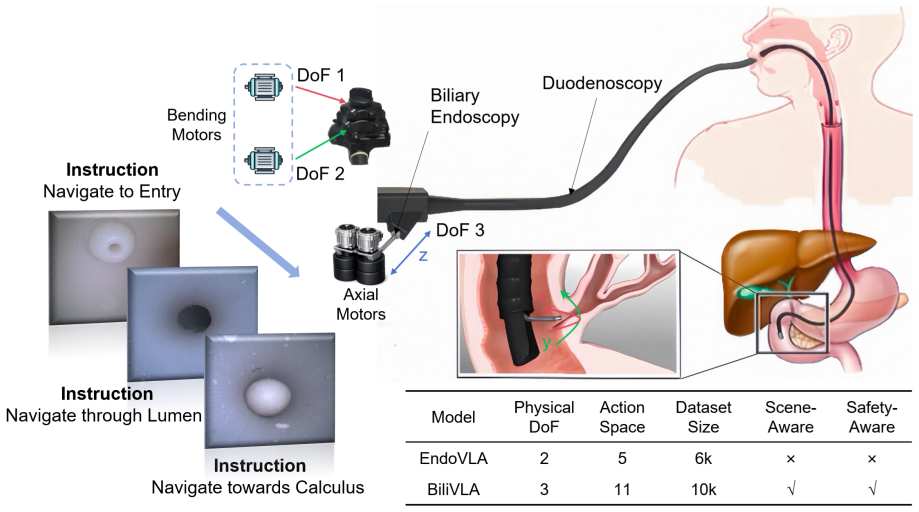
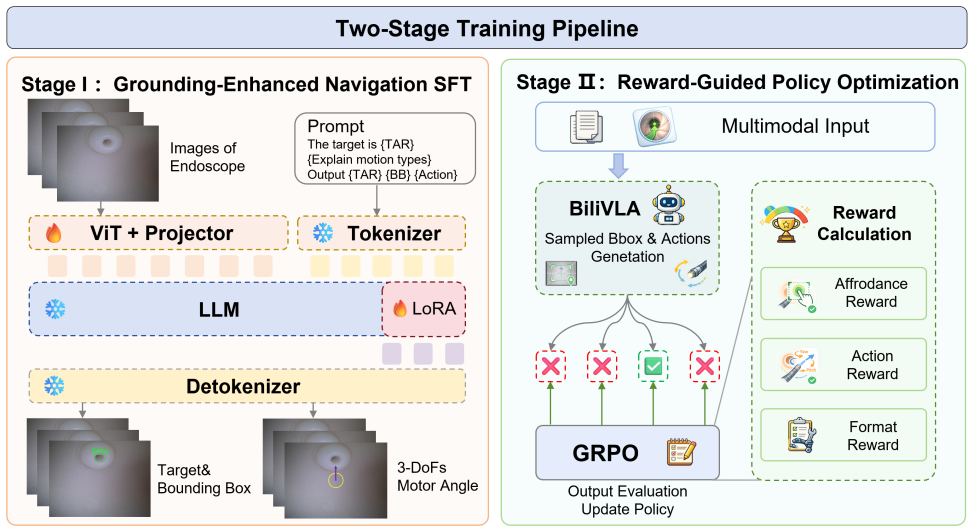
BiliVLA formulates biliary endoscopic navigation as an instruction-conditioned visuomotor learning problem. Given an endoscopic observation and a stage-specific language instruction, BiliVLA jointly predicts the target category, a grounded bounding box, and a discrete three degrees of freedom (DoF) motor command for a continuum endoscope. The proposed framework incorporates scene-aware supervision to enhance semantic target consistency and safety-aware recovery supervision to induce conservative retreat behaviors under luminal wall contact. A key component of BiliVLA is a two-stage training paradigm that combines grounding-enhanced supervised fine-tuning (SFT) with Group Relative Policy Opti
What carries the argument
The scene-aware Vision-Language-Action (VLA) framework that jointly predicts target category, grounded bounding box, and 3DoF motor commands, trained via grounding-enhanced SFT followed by GRPO.
If this is right
- Scene-aware supervision produces more consistent semantic targets across varying views.
- Safety-aware recovery supervision leads to conservative retreat actions on wall contact.
- The two-stage SFT then GRPO training increases action reliability and decision consistency in closed-loop use.
- The combined elements improve perception-action alignment under the visual conditions tested.
Where Pith is reading between the lines
- The same instruction-conditioned VLA structure might apply to navigation tasks in other narrow-channel endoscopic procedures.
- Extending the safety supervision to continuous rather than discrete commands could further reduce contact risks.
Load-bearing premise
Phantom experiments with controlled conditions sufficiently capture the pronounced anatomical variability, specular reflections, partial occlusions, and tissue contact present in live human ERCP procedures.
What would settle it
A substantial drop in success rate when the same model is evaluated in live human ERCP cases with natural anatomical variations and artifacts would indicate the phantom results do not generalize.
Figures


read the original abstract
Endoscopic retrograde cholangiopancreatography (ERCP) demands precise endoscopic navigation and stable biliary cannulation within a narrow monocular field characterized by specular reflections, partial occlusions, and frequent tissue contact. Although recent robotic systems and vision-based assistance techniques improve operator ergonomics and provide perceptual cues, their performance degrades under pronounced anatomical variability and safety-critical visual artifacts, which hinders reliable autonomy in cannulation-grade procedures. Here, we present BiliVLA, a scene-aware Vision-Language-Action (VLA) framework that formulates biliary endoscopic navigation as an instruction-conditioned visuomotor learning problem. Given an endoscopic observation and a stage-specific language instruction, BiliVLA jointly predicts the target category, a grounded bounding box, and a discrete three degrees of freedom (DoF) motor command for a continuum endoscope. The proposed framework incorporates scene-aware supervision to enhance semantic target consistency and safety-aware recovery supervision to induce conservative retreat behaviors under luminal wall contact. A key component of BiliVLA is a two-stage training paradigm that combines grounding-enhanced supervised fine-tuning (SFT) with Group Relative Policy Optimization (GRPO), which significantly improves action reliability and decision consistency during closed-loop navigation. Across three ERCP subtasks, BiliVLA achieves an average action precision of 91.96\% and an overall success rate (SR) of 84.85\% in real-world phantom experiments. These results indicate that integrating semantic grounding, scene-aware learning, and reward-guided optimization improves perception-action alignment and enables robust autonomous endoscopic navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BiliVLA, a scene-aware Vision-Language-Action (VLA) framework for autonomous biliary endoscopic navigation during ERCP. It casts navigation as an instruction-conditioned visuomotor problem that jointly predicts target category, grounded bounding box, and discrete 3-DoF motor commands from monocular endoscopic images. The method adds scene-aware supervision for semantic consistency and safety-aware recovery supervision for conservative retreat under wall contact, trained via a two-stage pipeline of grounding-enhanced supervised fine-tuning followed by Group Relative Policy Optimization (GRPO). In real-world phantom experiments across three ERCP subtasks, the system reports 91.96% average action precision and 84.85% overall success rate.
Significance. If the reported metrics are shown to be statistically reliable and the phantom conditions are demonstrated to capture the cited visual and anatomical challenges, the work would constitute a concrete advance in applying VLA models with RL to safety-critical continuum-robot navigation. The explicit design of safety-aware recovery supervision and the use of GRPO to improve decision consistency are strengths that directly address closed-loop reliability in visually degraded environments.
major comments (2)
- [Abstract] Abstract: The headline metrics (91.96% action precision, 84.85% SR) are presented as aggregate values with no trial counts, baseline comparisons, statistical tests, error bars, or exclusion criteria supplied. Without these details it is impossible to judge whether the numbers support the claims of improved action reliability and decision consistency.
- [Abstract] Abstract: All quantitative results derive exclusively from real-world phantom experiments. The text itself identifies pronounced anatomical variability, specular reflections, partial occlusions, and tissue contact as the core challenges that degrade prior methods in live human ERCP, yet no evidence is given that the phantom reproduces patient-to-patient duct geometry, dynamic deformation, or lighting variation. This gap is load-bearing for the central claim that BiliVLA enables robust autonomous endoscopic navigation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's significance. We address each major comment below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline metrics (91.96% action precision, 84.85% SR) are presented as aggregate values with no trial counts, baseline comparisons, statistical tests, error bars, or exclusion criteria supplied. Without these details it is impossible to judge whether the numbers support the claims of improved action reliability and decision consistency.
Authors: We agree that the abstract would be strengthened by including supporting experimental details. The full manuscript reports the underlying trial counts (multiple runs across the three subtasks), baseline comparisons, and evaluation protocol in the Experiments section. We will revise the abstract to incorporate the total number of trials, a reference to the statistical reliability of the results, and a brief note on the evaluation criteria. revision: yes
-
Referee: [Abstract] Abstract: All quantitative results derive exclusively from real-world phantom experiments. The text itself identifies pronounced anatomical variability, specular reflections, partial occlusions, and tissue contact as the core challenges that degrade prior methods in live human ERCP, yet no evidence is given that the phantom reproduces patient-to-patient duct geometry, dynamic deformation, or lighting variation. This gap is load-bearing for the central claim that BiliVLA enables robust autonomous endoscopic navigation.
Authors: The reported results are from phantom experiments constructed to replicate the visual artifacts and contact conditions highlighted in the introduction. We acknowledge that the current phantom does not fully capture patient-to-patient duct geometry or dynamic deformation. We will revise the manuscript to add an explicit limitations paragraph clarifying the scope of the phantom validation, the specific challenges it does reproduce, and the need for future clinical studies. revision: partial
Circularity Check
No significant circularity; performance metrics are direct experimental outcomes.
full rationale
The paper presents BiliVLA as a VLA framework trained with grounding-enhanced SFT followed by GRPO, then reports action precision and success rate as measured results from phantom experiments. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described pipeline. The central claims reduce to empirical measurements rather than any self-referential construction, satisfying the default expectation of no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prophylaxis of post-ERCP pancreatitis: European society of gastrointestinal endoscopy (ESGE) guideline–updated june 2014,
J.-M. Dumonceau, A. Andriulli, B. J. Elmunzer, A. Mariani, T. Meis- ter, J. Deviere, T. Marek, T. H. Baron, C. Hassan, P. A. Testoni et al., “Prophylaxis of post-ERCP pancreatitis: European society of gastrointestinal endoscopy (ESGE) guideline–updated june 2014,” Endoscopy, vol. 46, no. 09, pp. 799–815, 2014
2014
-
[2]
Papillary cannulation and sphincterotomy techniques at ERCP: European society of gastrointestinal endoscopy (ESGE) clinical guideline,
P. A. Testoni, A. Mariani, L. Aabakken, M. Arvanitakis, E. Bories, G. Costamagna, J. Devi `ere, M. Dinis-Ribeiro, J.-M. Dumonceau, M. Giovanniniet al., “Papillary cannulation and sphincterotomy techniques at ERCP: European society of gastrointestinal endoscopy (ESGE) clinical guideline,”Endoscopy, vol. 48, no. 07, pp. 657–683, 2016
2016
-
[3]
Post-ERCP pan- creatitis: prevention, diagnosis and management,
O. Cahyadi, N. Tehami, E. de Madaria, and K. Siau, “Post-ERCP pan- creatitis: prevention, diagnosis and management,”Medicina, vol. 58, no. 9, p. 1261, 2022
2022
-
[4]
Robot-assisted endoscopic retrograde cholangiopan- creatography: A pilot study,
X. Chen, Z. Wang, H. Wu, Q. Lou, W. Gu, W. Ma, J.-F. Yang, H.-b. Jin, and X. Zhang, “Robot-assisted endoscopic retrograde cholangiopan- creatography: A pilot study,”Endoscopy, 2026
2026
-
[5]
Artificial intelligence- assisted analysis of endoscopic retrograde cholangiopancreatography image for identifying ampulla and difficulty of selective cannulation,
T. Kim, J. Kim, H. S. Choi, E. S. Kim, B. Keum, Y . T. Jeen, H. S. Lee, H. J. Chun, S. Y . Han, D. U. Kimet al., “Artificial intelligence- assisted analysis of endoscopic retrograde cholangiopancreatography image for identifying ampulla and difficulty of selective cannulation,” Scientific Reports, vol. 11, no. 1, p. 8381, 2021
2021
-
[6]
DD-VNB: A depth-based dual-loop framework for real- time visually navigated bronchoscopy,
Q. Tian, H. Liao, X. Huang, J. Chen, Z. Zhang, B. Yang, S. Ourselin, and H. Liu, “DD-VNB: A depth-based dual-loop framework for real- time visually navigated bronchoscopy,” in2024 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 979–12 986
2024
-
[7]
Robotic endoscope control via autonomous instrument tracking,
C. Gruijthuijsen, L. C. Garcia-Peraza-Herrera, G. Borghesan, D. Rey- naerts, J. Deprest, S. Ourselin, T. Vercauteren, and E. Vander Poorten, “Robotic endoscope control via autonomous instrument tracking,” Frontiers in Robotics and AI, vol. 9, p. 832208, 2022
2022
-
[8]
Enabling autonomous colonoscopy intervention using a robotic endoscope platform,
Q. Zhang, J. M. Prendergast, G. A. Formosa, M. J. Fulton, and M. E. Rentschler, “Enabling autonomous colonoscopy intervention using a robotic endoscope platform,”IEEE Transactions on Biomedical Engineering, vol. 68, no. 6, pp. 1957–1968, 2020
1957
-
[9]
Navigation of tendon- driven flexible robotic endoscope through deep reinforcement learn- ing,
C. Ng, H. Gao, T.-A. Ren, J. Lai, and H. Ren, “Navigation of tendon- driven flexible robotic endoscope through deep reinforcement learn- ing,” in2024 IEEE International Conference on Advanced Robotics and Its Social Impacts (ARSO). IEEE, 2024, pp. 134–139
2024
-
[10]
C. K. Ng, H. Gao, T.-A. Ren, J. Lai, and H. Ren, “Contact-aided navigation of flexible robotic endoscope using deep reinforcement learning in dynamic stomach,”arXiv preprint arXiv:2509.00319, 2025
-
[11]
Jacobian exploratory dual-phase rein- forcement learning for dynamic endoluminal navigation of deformable continuum robots,
Y . Tian, C. K. Ng, and H. Ren, “Jacobian exploratory dual-phase rein- forcement learning for dynamic endoluminal navigation of deformable continuum robots,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 21 559– 21 565
2025
-
[12]
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Y . Zhong, F. Bai, S. Cai, X. Huang, Z. Chen, X. Zhang, Y . Wang, S. Guo, T. Guan, K. N. Luiet al., “A survey on Vision-Language- Action models: An action tokenization perspective,”arXiv preprint arXiv:2507.01925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
R. Sapkota, Y . Cao, K. I. Roumeliotis, and M. Karkee, “Vision- Language-Action (VLA) models: Concepts, progress, applications and challenges,”arXiv preprint arXiv:2505.04769, 2025
-
[14]
EndoVLA: Dual-phase Vision-Language-Action for precise autonomous tracking in endoscopy,
C. K. Ng, L. Bai, G. Wang, Y . Wang, H. Gao, C. Jin, T. Zeng, H. Renet al., “EndoVLA: Dual-phase Vision-Language-Action for precise autonomous tracking in endoscopy,” in9th Annual Conference on Robot Learning, 2025
2025
-
[15]
SRT-H: A hierarchical framework for autonomous surgery via language-conditioned imitation learning,
J. W. Kim, J.-T. Chen, P. Hansen, L. X. Shi, A. Goldenberg, S. Schmidgall, P. M. Scheikl, A. Deguet, B. M. White, D. R. Tsai et al., “SRT-H: A hierarchical framework for autonomous surgery via language-conditioned imitation learning,”Science Robotics, vol. 10, no. 104, p. eadt5254, 2025
2025
-
[16]
The gastrointestinal tract,
C. Van Ginneken, “The gastrointestinal tract,”The Minipig in Biomed- ical Research, pp. 218–237, 2025
2025
-
[17]
Specular reflections removal of gastrointestinal polyps based on endoscopic image,
K. Qian, C. Xu, B. Feng, and Z. An, “Specular reflections removal of gastrointestinal polyps based on endoscopic image,” in2022 7th International Conference on Signal and Image Processing (ICSIP). IEEE, 2022, pp. 627–631
2022
-
[18]
American society for gastrointestinal endoscopy guideline on post-ERCP pancreatitis prevention strategies: summary and recommendations,
J. L. Buxbaum, M. Freeman, S. K. Amateau, J. M. Chalhoub, N. Coelho-Prabhu, M. Desai, S. E. Elhanafi, N. Forbes, L. L. Fujii-Lau, D. R. Kohliet al., “American society for gastrointestinal endoscopy guideline on post-ERCP pancreatitis prevention strategies: summary and recommendations,”Gastrointestinal Endoscopy, vol. 97, no. 2, pp. 153–162, 2023
2023
-
[19]
Difficult biliary cannulation during ERCP: how to facilitate biliary access and minimize the risk of post-ERCP pancreatitis,
P. A. Testoni, S. Testoni, and A. Giussani, “Difficult biliary cannulation during ERCP: how to facilitate biliary access and minimize the risk of post-ERCP pancreatitis,”Digestive and Liver Disease, vol. 43, no. 8, pp. 596–603, 2011
2011
-
[20]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “RT-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
RT-2: Vision-Language-Action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “RT-2: Vision-Language-Action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[22]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A Vision- Language-Action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusaiet al., “π 0.5: a Vision-Language-Action model with open-world generalization,” arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, “RDT-1B: a diffusion foundation model for bimanual manipulation,”arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
N. Nelson, J.-T. Chen, J. Haworth, X. Chen, L. Zbinden, D. Huang, A. E. Abdelaal, A. Arezzo, A. Acar, F. Alambeigiet al., “Open-h- embodiment: A large-scale dataset for enabling foundation models in medical robotics,”arXiv preprint arXiv:2604.21017, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
YOLOv11: An Overview of the Key Architectural Enhancements
R. Khanam and M. Hussain, “YOLOv11: An overview of the key architectural enhancements,”arXiv preprint arXiv:2410.17725, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “LoRA: Low-rank adaptation of large language models,”ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “DeepSeek-R1: Incentivizing reason- ing capability in LLMs via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Unsloth: Fast language model fine-tuning,
U. Team, “Unsloth: Fast language model fine-tuning,” GitHub repos- itory, 2024, https://github.com/unslothai/unsloth
2024
-
[30]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-VL technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
TRL: Transformer reinforcement learning,
L. von Werra, J. Beeching, Y . Belkada, N. Carper, M. Cointepas, L. Gatti, C. Harris, Q. Lhoest, T. Thrush, L. Tunstallet al., “TRL: Transformer reinforcement learning,” GitHub repository, 2024, https: //github.com/huggingface/trl
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.