PIXELRAG: Web Screenshots Beat Text for Retrieval-Augmented Generation
Pith reviewed 2026-06-30 11:29 UTC · model grok-4.3
The pith
PixelRAG shows that retrieving and reading web pages as screenshots outperforms text extraction for retrieval-augmented generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
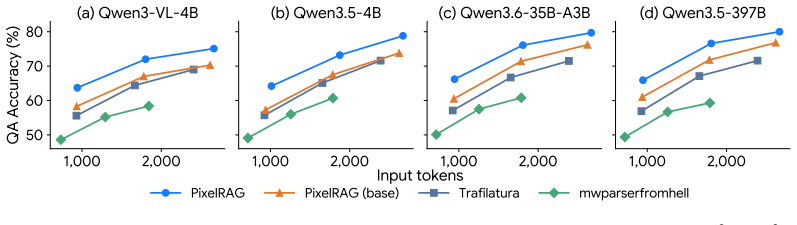
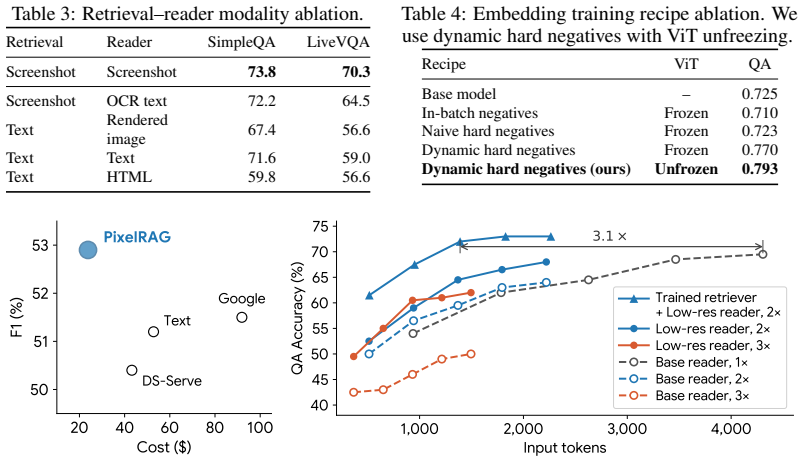
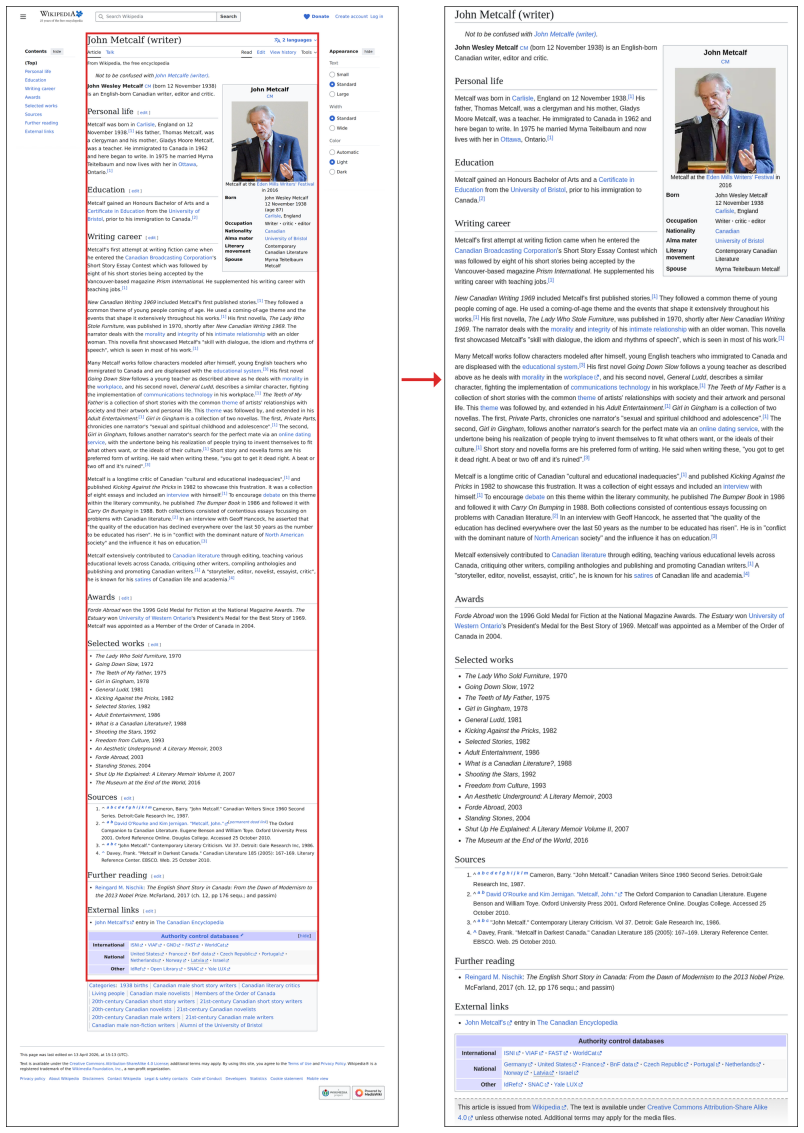
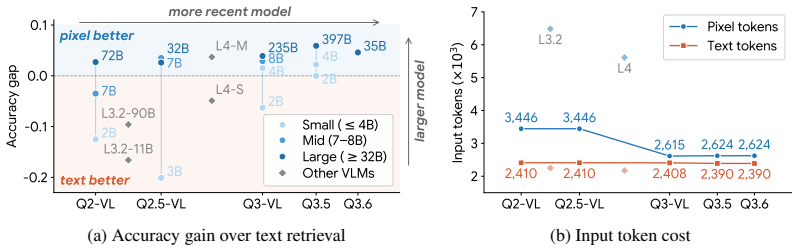
PixelRAG is a retrieval-augmented generation pipeline that represents websites as their native screenshot images rather than extracted text. It scales a visual embedding index to a full 30-million-image Wikipedia datastore, fine-tunes the embedding model on curated contrastive screenshot pairs, and supplies the retrieved pixels directly to a vision-language model. This end-to-end visual pipeline improves accuracy over text-based RAG by up to 18.1 percent on tasks ranging from open-domain QA to noisy news and agentic benchmarks, while also enabling up to 3x token reduction via lower-resolution compression.
What carries the argument
A visual retrieval index over full-page screenshot images, fine-tuned on contrastive pairs and fed directly as pixels to a vision-language model without any text conversion step.
If this is right
- RAG systems can preserve page layout and visual structure without complex HTML parsing pipelines.
- Image compression offers a practical way to cut token usage while holding accuracy steady.
- Performance advantages appear even on tasks that have historically been treated as purely textual.
- The same visual index supports both text-centric and multimodal question answering.
Where Pith is reading between the lines
- Similar visual pipelines could be tested on other document collections where layout carries meaning, such as scientific papers or product pages.
- Hybrid systems that retrieve both text and pixels might combine the strengths of each representation.
- The result invites direct measurement of how much information vision-language models extract from screenshots versus parsed text on identical questions.
Load-bearing premise
That any accuracy gains come from the pixel representation of pages rather than from differences in model capacity or training data between the visual and text retrieval pipelines.
What would settle it
A controlled comparison in which a text RAG system is given the same downstream vision-language model and equivalent contrastive training data on the same corpus, yet matches or exceeds PixelRAG accuracy on NQ and SimpleQA.
Figures









read the original abstract
Augmenting large language models (LLMs) with retrieved web text has become a dominant paradigm, yet the web is not natively textual: existing systems depend on complex parsing pipelines that linearize HTML and discard layout, visual structure, and formatting. We introduce PixelRAG, a new retrieval-augmented method that represents websites in their native visual form and performs retrieval and reading entirely in pixel space, enabling an end-to-end architecture that eliminates text abstraction. PixelRAG is, to our knowledge, the first pipeline to operate over a full Wikipedia corpus in this form, scaling to a datastore of 30 million screenshot images with an efficient visual retrieval index. Built on an existing visual embedding model (i.e., Qwen3-VL-Embedding), PixelRAG further fine-tunes this model on screenshot data with carefully curated contrastive training data. Retrieved screenshots are then fed directly as pixel inputs to a VLM, without intermediate text conversion. PixelRAG consistently outperforms both no-retrieval and text-based RAG baselines, most surprisingly on widely studied text-centric tasks such as NQ and SimpleQA. It also achieves strong gains on multimodal open-domain QA (e.g., MMSearch), benchmarks over noisy news corpora (e.g., LiveVQA), and agentic benchmarks (e.g., MoNaCo), improving accuracy by up to 18.1% over text-based baselines. Finally, pixel representations enable a new efficiency lever for RAG through image compression, achieving up to 3x token cost reduction at lower resolutions while maintaining accuracy. Our results challenge the necessity of text representations in web retrieval, suggesting that web RAG can operate directly in the web's native visual form while improving both performance and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PixelRAG, a RAG pipeline that indexes and retrieves web content as native screenshots (pixels) rather than parsed text. It fine-tunes Qwen3-VL-Embedding on curated contrastive screenshot pairs, scales the index to 30 million Wikipedia screenshots, feeds retrieved images directly to a VLM, and reports consistent accuracy gains over no-retrieval and text-based RAG baselines (up to 18.1 %) on text-centric tasks (NQ, SimpleQA), multimodal QA (MMSearch), noisy news (LiveVQA), and agentic benchmarks (MoNaCo). It also claims efficiency gains via image compression that reduce token cost by up to 3x.
Significance. If the central empirical claim survives controls that isolate the pixel representation from model-capacity and fine-tuning differences, the result would be significant: it would challenge the long-standing assumption that text linearization is necessary or optimal for web RAG and would demonstrate that a purely visual pipeline can improve both accuracy and efficiency at web scale. The reported scaling to a 30-million-image datastore and the compression-based token reduction are concrete strengths that would be of immediate practical interest.
major comments (2)
- [Abstract / PixelRAG construction paragraph] Abstract (paragraph describing PixelRAG construction and fine-tuning) and the baseline description: the headline claim that screenshot retrieval outperforms text RAG 'because of the native visual representation' is not isolated. PixelRAG fine-tunes Qwen3-VL-Embedding on contrastive screenshot pairs and uses a VLM reader, while the text baselines are described only as 'standard text-embedding pipelines' without any indication that they employ the same base model or equivalent contrastive fine-tuning. Consequently the observed lifts (including the 18.1 % figure on NQ/SimpleQA) cannot yet be attributed to the pixel format rather than to differences in model capacity, pre-training, or training data.
- [Experimental section] Experimental section (where baselines and ablations are presented): no ablation is described that holds the embedding model and fine-tuning procedure fixed while varying only the input representation (pixels vs. text). Without such a controlled comparison the central causal claim remains under-supported.
minor comments (1)
- The abstract states that PixelRAG is 'the first pipeline to operate over a full Wikipedia corpus in this form'; a brief related-work paragraph clarifying how prior visual-retrieval or screenshot-based systems differ would strengthen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the current experiments do not fully isolate the contribution of the pixel representation. We respond point-by-point below and indicate planned changes to the manuscript.
read point-by-point responses
-
Referee: [Abstract / PixelRAG construction paragraph] Abstract (paragraph describing PixelRAG construction and fine-tuning) and the baseline description: the headline claim that screenshot retrieval outperforms text RAG 'because of the native visual representation' is not isolated. PixelRAG fine-tunes Qwen3-VL-Embedding on contrastive screenshot pairs and uses a VLM reader, while the text baselines are described only as 'standard text-embedding pipelines' without any indication that they employ the same base model or equivalent contrastive fine-tuning. Consequently the observed lifts (including the 18.1 % figure on NQ/SimpleQA) cannot yet be attributed to the pixel format rather than to differences in model capacity, pre-training, or training data.
Authors: We agree that the manuscript does not isolate the pixel representation from model capacity and fine-tuning differences. The text baselines follow common practice in the RAG literature but are not matched to the same base model or contrastive procedure. In the revision we will (1) explicitly name the text embedding models used, (2) add a limitations paragraph discussing this confound, and (3) tone down causal language attributing gains solely to pixels. We cannot retroactively change the existing experiments without new runs. revision: yes
-
Referee: [Experimental section] Experimental section (where baselines and ablations are presented): no ablation is described that holds the embedding model and fine-tuning procedure fixed while varying only the input representation (pixels vs. text). Without such a controlled comparison the central causal claim remains under-supported.
Authors: We acknowledge the absence of this controlled ablation. The contrastive fine-tuning data is constructed from screenshot pairs, making an exactly parallel text-only fine-tuning non-trivial to construct. In the revised manuscript we will add an ablation that re-uses the Qwen3-VL backbone (which accepts both modalities) with text-only inputs derived from the same pages, holding the fine-tuning objective and data scale as close as possible. If resource constraints prevent a full re-run, we will report the best feasible comparison and note the remaining gap. revision: partial
Circularity Check
No circularity: empirical claims rest on external baselines, not self-referential definitions or fits.
full rationale
The paper contains no equations, derivations, or fitted parameters that are renamed as predictions. All performance claims are presented as direct empirical comparisons against external text-RAG baselines on public benchmarks (NQ, SimpleQA, MMSearch, etc.). The fine-tuning step on contrastive screenshot pairs is described as a construction choice, not a quantity that is then 'predicted' from itself. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim therefore does not reduce to its own inputs by construction and remains falsifiable against independent text pipelines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuning a visual embedding model on curated contrastive screenshot pairs yields retrieval quality superior to text-based methods for web QA tasks.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[2]
REALM: Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. REALM: Retrieval-augmented language model pre-training. InInternational Conference on Machine Learning, pages 3929–3938, 2020
2020
-
[3]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, 2020
2020
-
[4]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, pages 874–880, 2021
2021
-
[5]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Xinxi Lyu, Michael Duan, Rulin Shao, Pang Wei Koh, and Sewon Min. Frustratingly simple re- trieval improves challenging, reasoning-intensive benchmarks.arXiv preprint arXiv:2507.01297, 2025
-
[7]
Scaling retrieval-based language models with a trillion-token datastore
Rulin Shao, Jacqueline He, Akari Asai, Weijia Shi, Tim Dettmers, Sewon Min, Luke Zettle- moyer, and Pang W Koh. Scaling retrieval-based language models with a trillion-token datastore. Advances in Neural Information Processing Systems, 37:91260–91299, 2024
2024
-
[8]
Alex Fang, Thomas V oice, Ruoming Pang, Ludwig Schmidt, and Tom Gunter. Reusing pre- training data at test time is a compute multiplier.arXiv preprint arXiv:2511.04234, 2025. 11
-
[9]
WebSailor: Navigating Super-human Reasoning for Web Agent
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, et al. Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Beyond a single extractor: Re-thinking html-to-text extraction for llm pre-training
Jeffrey Li, Joshua P Gardner, Doug Kang, Fangping Shi, Karanjeet Singh, Chun-Liang Li, Herumb Shandilya, David Leo Wright Hall, Oncel Tuzel, Percy Liang, et al. Beyond a single extractor: Re-thinking html-to-text extraction for llm pre-training. InFindings of the Association for Computational Linguistics: EACL 2026, pages 5836–5861, 2026
2026
-
[11]
The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
2024
-
[12]
Html- RAG: HTML is better than plain text for modeling retrieved knowledge in RAG systems
Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, and Ji-Rong Wen. Html- RAG: HTML is better than plain text for modeling retrieved knowledge in RAG systems. In Proceedings of the ACM Web Conference 2025 (WWW), 2025
2025
-
[13]
Trafilatura: A web scraping library and command-line tool for text discovery and extraction
Adrien Barbaresi. Trafilatura: A web scraping library and command-line tool for text discovery and extraction. In Heng Ji, Jong C. Park, and Rui Xia, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, pages 122–13...
2021
-
[14]
Feng Wang, Zesheng Shi, Bo Wang, Nan Wang, and Han Xiao. ReaderLM-v2: Small language model for HTML to markdown and JSON.arXiv preprint arXiv:2503.01151, 2025
-
[15]
Mengjie Liu, Jiahui Peng, Wenchang Ning, et al. Dripper: Token-efficient main HTML extraction with a lightweight LM.arXiv preprint arXiv:2511.23119, 2025
-
[16]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
The Claude 3 model family: Opus, Sonnet, Haiku
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku. Technical report, 2024. Technical Report
2024
-
[20]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural Information Processing Systems, 37:113569–113697, 2024
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, et al. Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural Information Processing Systems, 37:113569–113697, 2024
2024
-
[22]
Colpali: Efficient document retrieval with vision language models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models. In International Conference on Learning Representations, 2025
2025
-
[23]
Unifying multi- modal retrieval via document screenshot embedding
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. Unifying multi- modal retrieval via document screenshot embedding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6492–6505, 2024
2024
-
[24]
VisRAG: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. VisRAG: Vision-based retrieval-augmented generation on multi-modality documents. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025. 12
2025
-
[25]
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi- modal retrieval is what you need for multi-page multi-document understanding.arXiv preprint arXiv:2411.04952, 2024
-
[26]
Yibo Yan, Jiahao Huo, Guanbo Feng, Mingdong Ou, Yi Cao, Xin Zou, Shuliang Liu, Yuanhuiyi Lyu, Yu Huang, Jungang Li, et al. Unlocking multimodal document intelligence: From current triumphs to future frontiers of visual document retrieval.arXiv preprint arXiv:2602.19961, 2026
-
[27]
CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
Jiahao Huo, Yu Huang, Yibo Yan, Ye Pan, Kening Zheng, Wei-Chieh Huang, Yi Cao, Mingdong Ou, Philip S. Yu, and Xuming Hu. CausalEmbed: Auto-regressive multi-vector generation in latent space for visual document embedding.arXiv preprint arXiv:2601.21262, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Bennett, Junaid Ahmed, and Arnold Overwijk
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval. InInternational Conference on Learning Representations, 2021
2021
-
[30]
Natural questions: A benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: A benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[31]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Mingyang Fu, Yuyang Peng, Dongping Chen, Zetong Zhou, Benlin Liu, Yao Wan, Zhou Zhao, Philip S. Yu, and Ranjay Krishna. Seeking and updating with live visual knowledge.arXiv preprint arXiv:2504.05288, 2025
-
[33]
Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Chaoyou Fu, Guanglu Song, Peng Gao, Yu Liu, Chunyuan Li, and Hongsheng Li. MMSearch: Benchmarking the potential of large models as multi-modal search engines.arXiv preprint arXiv:2409.12959, 2024
-
[34]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Glyph: Scaling context windows via visual-text compression
Jiale Cheng, Yusen Liu, Xinyu Zhang, Yulin Fei, Wenyi Hong, Ruiliang Lyu, Weihan Wang, Zhe Su, Xiaotao Gu, Xiao Liu, et al. Glyph: Scaling context windows via visual-text compression. arXiv preprint arXiv:2510.17800, 2025
-
[36]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Tongyi DeepResearch Technical Report
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
2024
-
[39]
Elastic ChatNoir: Search Engine for the ClueWeb and the Common Crawl
Janek Bevendorff, Benno Stein, Matthias Hagen, and Martin Potthast. Elastic ChatNoir: Search Engine for the ClueWeb and the Common Crawl. In Leif Azzopardi, Allan Hanbury, Gabriella Pasi, and Benjamin Piwowarski, editors,Advances in Information Retrieval. 40th European Conference on IR Research (ECIR 2018), Lecture Notes in Computer Science, Berlin Heidel...
2018
-
[40]
mwparserfromhell: A python parser for mediawiki wikicode
Ben Kurtovic and contributors. mwparserfromhell: A python parser for mediawiki wikicode. https://github.com/earwig/mwparserfromhell, 2026
2026
-
[41]
Yujie Lu, Xiujun Li, Tsu-Jui Fu, Miguel Eckstein, and William Yang Wang. From text to pixel: Advancing long-context understanding in mllms.arXiv preprint arXiv:2405.14213, 2024
-
[42]
Kaiser Sun, Xiaochuang Yuan, Hongjun Liu, Chen Zhao, Cheng Zhang, Mark Dredze, and Fan Bai. Reading, not thinking: Understanding and bridging the modality gap when text becomes pixels in multimodal llms.arXiv preprint arXiv:2603.09095, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Zhiheng Lyu, Xueguang Ma, and Wenhu Chen. Pixelworld: How far are we from perceiving everything as pixels?arXiv preprint arXiv:2501.19339, 2025
-
[44]
Nemotron colembed v2: Top-performing late interaction embedding models for visual document retrieval
Gabriel de Souza P Moreira, Ronay Ak, Mengyao Xu, Oliver Holworthy, Benedikt Schifferer, Zhiding Yu, Yauhen Babakhin, Radek Osmulski, Jiarui Cai, Ryan Chesler, et al. Nemotron colembed v2: Top-performing late interaction embedding models for visual document retrieval. arXiv preprint arXiv:2602.03992, 2026
-
[45]
Vidore benchmark v2: Raising the bar for visual retrieval.arXiv preprint arXiv:2505.17166, 2025
Quentin Macé, António Loison, and Manuel Faysse. Vidore benchmark v2: Raising the bar for visual retrieval.arXiv preprint arXiv:2505.17166, 2025
-
[46]
Fengbin Zhu, Ziyang Liu, Xiang Yao Ng, Haohui Wu, Wenjie Wang, Fuli Feng, Chao Wang, Huanbo Luan, and Tat Seng Chua. Mmdocbench: Benchmarking large vision-language models for fine-grained visual document understanding.arXiv preprint arXiv:2410.21311, 2024
-
[47]
Connor Shorten, Augustas Skaburskas, Daniel M Jones, Charles Pierse, Roberto Esposito, John Trengrove, Etienne Dilocker, and Bob van Luijt. Irpapers: A visual document benchmark for scientific retrieval and question answering.arXiv preprint arXiv:2602.17687, 2026
-
[48]
Billion-Scale Similarity Search with GPUs
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-Scale Similarity Search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[49]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
Swift:a scalable lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Hong Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024
2024
-
[51]
Open domain question answering over tables via dense retrieval
Jonathan Herzig, Thomas Müller, Syrine Krichene, and Julian Martin Eisenschlos. Open domain question answering over tables via dense retrieval. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, pages 512–519, 2021
2021
-
[52]
Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories
Thomas Mensink, Jasper Uijlings, Lluis Castrejon, Arushi Goel, Felipe Cadar, Howard Zhou, Fei Sha, André Araujo, and Vittorio Ferrari. Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3082–3092, 2023
2023
-
[53]
Online language modelling data pipeline.https://github.com/huggingface/olm-datasets, 2022
Tristan Thrush, Helen Ngo, Nathan Lambert, and Douwe Kiela. Online language modelling data pipeline.https://github.com/huggingface/olm-datasets, 2022
2022
-
[54]
Neuml/wikipedia: Wikipedia text dataset
NeuML. Neuml/wikipedia: Wikipedia text dataset. https://huggingface.co/ datasets/NeuML/wikipedia, 2024. Text extracted from Wikipedia XML dumps via mwparserfromhell
2024
-
[55]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id= qwen3.5, 2026
2026
-
[56]
MoNaCo: More natural and complex questions for reasoning across dozens of documents.Transactions of the Association for Computational Linguistics, 2025
Tomer Wolfson, Harsh Trivedi, Mor Geva, Yoav Goldberg, Dan Roth, Tushar Khot, Ashish Sabharwal, and Reut Tsarfaty. MoNaCo: More natural and complex questions for reasoning across dozens of documents.Transactions of the Association for Computational Linguistics, 2025. 14
2025
-
[57]
SerpApi: Google search api.https://serpapi.com, 2025
SerpApi. SerpApi: Google search api.https://serpapi.com, 2025
2025
-
[58]
Gonzalez, Matei Zaharia, and Sewon Min
Jinjian Liu, Yichuan Wang, Xinxi Lyu, Rulin Shao, Joseph E. Gonzalez, Matei Zaharia, and Sewon Min. DS SERVE: A framework for efficient and scalable neural retrieval. InFortieth AAAI Conference on Artificial Intelligence (AAAI), pages 41631–41633, 2026
2026
-
[59]
Lanczos resampling
Wikipedia contributors. Lanczos resampling. https://en.wikipedia.org/wiki/ Lanczos_resampling, 2025. Accessed: 2026-04-29
2025
-
[60]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.arXiv preprint arXiv:2310.03744, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Llama 3.2: Lightweight text and multimodal models
Meta AI. Llama 3.2: Lightweight text and multimodal models. https://ai.meta.com/ blog/llama-3-2-connect-2024-vision-edge-mobile-devices/, 2024
2024
-
[62]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Meta AI. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence/, 2026. Blog post
2026
-
[63]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Qwen3.6: Towards real world agents
Qwen Team. Qwen3.6: Towards real world agents. https://qwen.ai/blog?id=qwen3.6/, 2026
2026
-
[66]
Leann: A low-storage vector index.arXiv preprint arXiv:2506.08276, 2025
Yichuan Wang, Zhifei Li, Shu Liu, Yongji Wu, Ziming Mao, Yilong Zhao, Xiao Yan, Zhiy- ing Xu, Yang Zhou, Ion Stoica, et al. Leann: A low-storage vector index.arXiv preprint arXiv:2506.08276, 2025
-
[67]
Google Landmarks Dataset v2 — a large-scale benchmark for instance-level recognition and retrieval
Tobias Weyand, André Araujo, Bingyi Cao, and Jack Sim. Google Landmarks Dataset v2 — a large-scale benchmark for instance-level recognition and retrieval. InCVPR, 2020
2020
-
[68]
Introducing GPT-4.1 in the API, April 2025
OpenAI. Introducing GPT-4.1 in the API, April 2025. Blog post
2025
-
[69]
See also
Kiwix Association. Kiwix — offline reader for web content. https://kiwix.org, 2007. Open-source offline browser using the ZIM archive format. 15 Technical appendices and supplementary material Contents A System & Implementation Details A.1 Rendering Pipeline 16 A.2 Datastore Fetching 16 A.3 Embedding Training: Data Recipe Details and Prompts 18 A.4 Reader...
2007
-
[70]
Fetch HTML.The article HTML is served from a local Kiwix ZIM archive [69] viakiwix-serve, eliminating network latency
-
[71]
The first line (article title) is skipped to avoid matching the <h1> heading
Extract search keys.Distinctive phrases are extracted from the text chunk: table cell values (e.g., codes likeB01AC06, numbers with units) for table-heavy chunks, mid-line prose fragments for paragraph-heavy chunks. The first line (article title) is skipped to avoid matching the <h1> heading
-
[72]
Locate in DOM.Each key is searched within the text_content() of every element under the article’smw-parser-output container. Both the key and element text are normalized (non- breaking spaces, dash variants, and diacritics are collapsed) to handle encoding mismatches between Trafilatura output and raw HTML. The tightest-matching element is selected
-
[73]
Resolve to contiguous span.Each matched element is walked up to its nearest direct-child ancestor ofmw-parser-output. The final result is the contiguous range of direct children from the first matched child to the last—preserving all intermediate elements (tables, paragraphs, lists) that the original text chunk spanned. 29
-
[74]
query":
Clean and return.Inline <style>, <script>, and navigation-box ( navbox) elements are stripped. The serialized HTML is returned to the reader. If no key matches in the DOM, the original flat text is used as fallback. The reader (Qwen3-VL-4B,max_model_len=65536) receives the concatenated HTML of allk=3 retrieved passages, separated by<hr>delimiters. Results...
1922
-
[75]
Who composed the music for the film?
SELF-CONTAINED. The question must be understandable on its own; every entity must be named explicitly. BAD: "Who composed the music for the film?" (missing film name) BAD: "On what date was Lerew awarded the DFC?" (surname only + acronym) BAD: "Which cyclist placed second in the Tempo race?" (missing event/year) BAD: "Which mission is shown in the screens...
-
[76]
The answer must be fully visible in this chunk
EVIDENCE COMPLETE. The answer must be fully visible in this chunk. The source span (S:) must be a complete, untruncated sentence
-
[77]
Include enough specifics (names, dates, locations, titles) to distinguish this chunk from similar pages
DISTINCTIVE. Include enough specifics (names, dates, locations, titles) to distinguish this chunk from similar pages. ANSWER: prefer a single concise entity -- name, date, place, number, title, or short phrase. SKIP (write exactly: SKIP) if any of the following holds: - Content is a raw vote count, track listing, census table, or episode list. - The answe...
-
[78]
What was the final score of the basketball game between THE TEAM and Marquette?
The subject is a vague pronoun or generic noun without a proper name: NO: "What was the final score of the basketball game between THE TEAM and Marquette?" ("the team" unnamed) NO: "Who directed the episode of THE TELEVISION SERIES titled'X'?" ("the television series" unnamed) NO: "In what year did THE SUBJECT OF THE ARTICLE move to Tokyo?" ("the subject"...
-
[79]
Which item IS LISTED IN THE TABLE as X?
The question explicitly references document structure: NO: "Which item IS LISTED IN THE TABLE as X?" NO: "What is shown IN THE INFOBOX?" NO: "According to THE PROVIDED TABLE, which..."
-
[80]
Who was THE CAPTAIN of HMS Defence?
A role/position question where no year or identifying event is given and the role has had many holders: NO: "Who was THE CAPTAIN of HMS Defence?" (no year, hundreds of captains over centuries)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.