RoboGaze: Evaluating Robot World Models via Structured Vision-Language Analysis
Pith reviewed 2026-06-30 10:46 UTC · model grok-4.3
The pith
A training-free multi-agent VLM framework diagnoses glitches in robot manipulation videos via a robotics-specific taxonomy and critic verification, closing most of the gap to human evaluators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
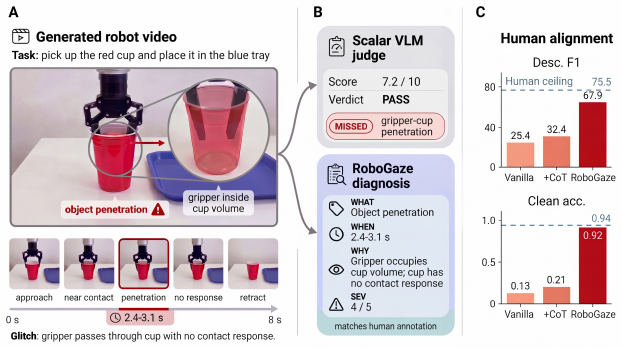
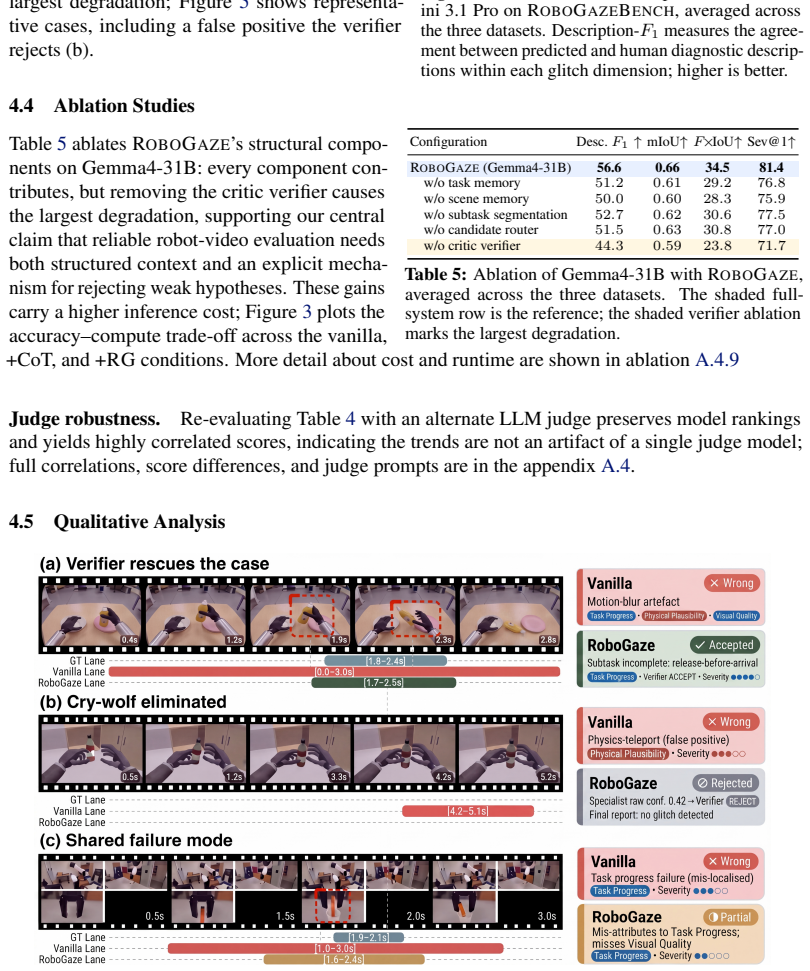
RoboGaze is a training-free, multi-agent VLM framework that evaluates generated robot-manipulation videos via task-scene grounding, dimension-specific specialist routing, and critic-based verification. It produces temporally localized glitch reports under a novel 6-dimension, 30-type robotics-specific taxonomy. Tested on eight VLM backbones against a human-validated dataset of 382 clips from simulated and real multi-view manipulation, it improves description-F1 by up to 43 points and temporal alignment (F1 x IoU) by up to 37 points while closing approximately 85 percent of the gap to human performance; its critic verifier also lifts clean-clip accuracy from under 25 percent to over 80 percen
What carries the argument
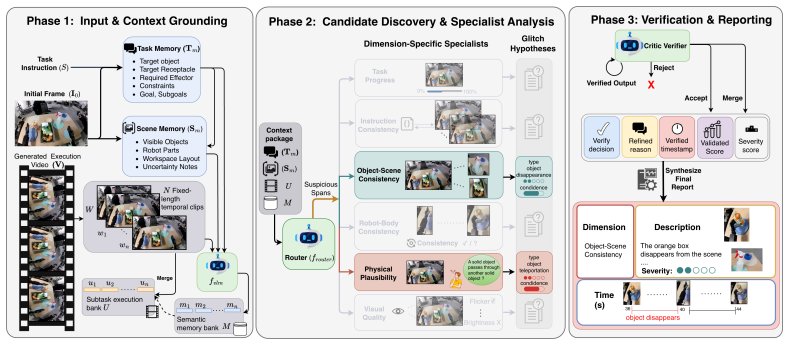
The three-stage pipeline of task-scene grounding, dimension-specific specialist routing, and critic-based verification, together with the 6-dimension 30-type robotics-specific taxonomy that classifies errors in manipulation videos.
If this is right
- RoboGaze supplies temporally aligned, category-specific reports that allow precise identification of failures in physical consistency, temporal order, and task logic.
- The critic verifier reduces false-positive detections of errors on clean clips from over 75 percent to under 20 percent across tested backbones.
- Performance gains hold across both open-source and proprietary VLM backbones on a dataset spanning simulated and real-world multi-view manipulation.
- The framework delivers interpretable outputs that can support iterative development of robot world models for prediction and planning.
- A human-validated benchmark dataset of 382 clips is released to enable standardized comparison of future evaluation methods.
Where Pith is reading between the lines
- World-model developers could feed the taxonomy categories back into training objectives to target specific failure modes such as object permanence or grasp stability.
- The routing-plus-critic structure might transfer to video evaluation in adjacent areas like autonomous navigation if analogous dimension taxonomies are created.
- Embedding RoboGaze outputs into closed-loop planning could let an agent avoid actions predicted to produce the detected glitch types.
- The dataset and taxonomy together provide a starting point for measuring progress on embodied prediction benchmarks beyond overall video quality scores.
Load-bearing premise
The novel 6-dimension 30-type taxonomy together with the three-stage specialist routing and critic verification produces reliable diagnostics without introducing systematic biases from VLM routing or the post-hoc category definitions.
What would settle it
A new collection of robot videos where human annotators and RoboGaze disagree on the location, type, or presence of glitches on a large fraction of clips, or where clean-clip accuracy drops back below 50 percent.
Figures



read the original abstract
Recent advances in robot world models enable synthetic video generation for embodied prediction and planning. However, evaluating these videos is challenging: visually realistic outputs often violate physical laws, temporal consistency, or task logic, while conventional metrics and monolithic Vision-Language Model (VLM) judges fail to generalize or provide precise diagnostic value. We present RoboGaze, a training-free, multi-agent VLM framework that provides structured, interpretable evaluation for generated robot-manipulation videos. Given a task instruction and video, RoboGaze operates via a three-stage pipeline: task-scene grounding, dimension-specific specialist routing, and critic-based verification. It outputs temporally localized glitch reports categorized under a novel 6-dimension, 30-type robotics-specific taxonomy. To benchmark RoboGaze, we introduce a human-validated dataset of 382 clips spanning simulated and real-world multi-view manipulation. Evaluating eight open-source and proprietary VLM backbones, RoboGaze dramatically outperforms zero-shot baselines, improving description-F1 by up to +43 points and temporal alignment (F1 x IoU) by up to +37 points, closing approximately 85% of the gap to the human ceiling. Furthermore, its critic verifier mitigates the "cry-wolf" false-positive flaw of standard VLMs, lifting clean-clip accuracy from under 25% to over 80%. RoboGaze offers a scalable, highly interpretable diagnostic tool for the rigorous evaluation of robot world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RoboGaze, a training-free multi-agent VLM framework for structured, interpretable evaluation of synthetic robot-manipulation videos from world models. It employs a three-stage pipeline (task-scene grounding, dimension-specific specialist routing, critic verification) that outputs temporally localized glitch reports under a novel 6-dimension 30-type robotics-specific taxonomy. On a newly introduced human-validated dataset of 382 clips, RoboGaze reports large gains over zero-shot VLM baselines (+43 description-F1, +37 temporal F1×IoU, closing ~85% of the gap to human ceiling) and lifts clean-clip accuracy from <25% to >80% via its critic verifier.
Significance. If the central claims hold after addressing verification gaps, RoboGaze would supply a scalable diagnostic tool that moves beyond monolithic VLM judges or conventional metrics, offering precise, temporally aligned feedback on physical, temporal, and task violations in robot videos. The reported performance lift and the critic's mitigation of false positives represent a concrete advance for embodied prediction and planning research.
major comments (2)
- [Abstract / pipeline description] Abstract and pipeline description: the headline gains (+43 description-F1, +37 temporal alignment, 85% gap closure, critic lift to >80%) rest on the claim that the 6-dimension 30-type taxonomy plus three-stage specialist routing and critic verification are free of post-hoc bias. The manuscript must explicitly document the a-priori definition process for the 30 types and show that routing decisions and category boundaries were fixed before observing VLM outputs on the 382-clip set; otherwise the metrics risk partial circularity.
- [Dataset construction and evaluation protocol] Dataset and evaluation protocol (presumably §4–5): the human-validated 382-clip benchmark is load-bearing for all quantitative claims, yet no details are supplied on clip selection criteria, inter-annotator agreement, or the exact protocol used to label ground-truth glitches under the new taxonomy. Without these, it is impossible to determine whether the taxonomy introduces systematic bias relative to human judgment.
minor comments (2)
- [Abstract] The abstract states that eight VLM backbones were evaluated but does not list them or report per-backbone variance; a table summarizing backbone-specific results would improve clarity.
- [Evaluation metrics] Notation for the temporal alignment metric (F1 × IoU) should be defined explicitly when first introduced, including how IoU is computed over glitch intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important requirements for transparency in our taxonomy development and dataset protocol. We will revise the manuscript to address both points directly.
read point-by-point responses
-
Referee: [Abstract / pipeline description] Abstract and pipeline description: the headline gains (+43 description-F1, +37 temporal alignment, 85% gap closure, critic lift to >80%) rest on the claim that the 6-dimension 30-type taxonomy plus three-stage specialist routing and critic verification are free of post-hoc bias. The manuscript must explicitly document the a-priori definition process for the 30 types and show that routing decisions and category boundaries were fixed before observing VLM outputs on the 382-clip set; otherwise the metrics risk partial circularity.
Authors: We agree that explicit documentation of the a-priori process is required to eliminate any perception of circularity. The taxonomy dimensions and 30 types were defined in advance based on robotics literature covering physical violations, temporal inconsistencies, and task failures, with routing logic and boundaries established prior to VLM runs on the 382-clip benchmark. We will add a new subsection in the methods section that details the literature sources, the independent pilot validation step, and a clear statement confirming that no post-observation adjustments occurred. This will be included in the revision. revision: yes
-
Referee: [Dataset construction and evaluation protocol] Dataset and evaluation protocol (presumably §4–5): the human-validated 382-clip benchmark is load-bearing for all quantitative claims, yet no details are supplied on clip selection criteria, inter-annotator agreement, or the exact protocol used to label ground-truth glitches under the new taxonomy. Without these, it is impossible to determine whether the taxonomy introduces systematic bias relative to human judgment.
Authors: We agree that these details are necessary for reproducibility and bias assessment. The manuscript will be revised to expand the dataset section with explicit clip selection criteria, the inter-annotator agreement metrics obtained during human validation, and a step-by-step description of the labeling protocol used to apply the taxonomy. These additions will allow readers to evaluate alignment between the taxonomy and human judgment. revision: yes
Circularity Check
No significant circularity; framework and metrics are independent of evaluated models.
full rationale
The paper presents RoboGaze as a training-free VLM framework with a novel taxonomy and three-stage pipeline. Performance metrics (description-F1, temporal F1×IoU) are computed against a separately human-validated dataset of 382 clips. No equations, fitted parameters, or self-referential reductions appear in the abstract or described pipeline. The taxonomy is introduced as part of the method rather than derived from the evaluation outputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
6-dimension 30-type robotics-specific taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[4]
Z. Yang, Y . Chen, J. Wang, S. Manivasagam, W.-C. Ma, A. J. Yang, and R. Urtasun. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1389–1399, 2023
2023
-
[5]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text- to-video generation via transformers. InThe Eleventh International Conference on Learning Representations
-
[6]
D. M. Nguyen, N. T. Diep, B. G. Nguyen, T.-B. Ho, D. Le, T. Nguyen, T.-L. Ha, T. Nhiem, B. Thach, N. Tran, T. A. Tran, A. Habuda, P. L. Moeller, T. N. Le, D. Sonntag, M. Niepert, K. Doan, V . Doan, V . Duong, H. Ngo, M. Vu, D. M. Nguyen, A. T. Le, and V . Ngo. FOCA: Future-oriented conditioning for data-efficient vision-language-action adaptation. InProce...
2026
-
[7]
Cosmos 3: Omnimodal World Models for Physical AI
N. Agarwal, A. Ali, J. Allen, M. Antolini, A. Aubame, J. Azzolini, J. Bai, M. Bala, Y . Bal- aji, J. Bapst, et al. Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026. doi:10.48550/arXiv.2606.02800. URL https://arxiv.org/abs/ 2606.02800
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.02800 2026
-
[8]
Huang, Y
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[9]
H. Wu, E. Zhang, L. Liao, C. Chen, J. Hou, A. Wang, W. Sun, Q. Yan, and W. Lin. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. In 9 Proceedings of the IEEE/CVF international conference on computer vision, pages 20144–20154, 2023
2023
-
[10]
X. He, D. Jiang, G. Zhang, M. Ku, A. Soni, S. Siu, H. Chen, A. Chandra, Z. Jiang, A. Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2105–2123, 2024
2024
- [11]
- [12]
-
[13]
Z. Mou, B. Xia, Z. Huang, W. Yang, and J. Jia. Gradeo: Towards human-like evaluation for text-to-video generation via multi-step reasoning. InInternational Conference on Machine Learning, pages 44971–44996. PMLR, 2025
2025
-
[14]
WorldJen: An End-to-End Multi-Dimensional Benchmark for Generative Video Models
K. Inbasekar, G. Rom, and O. Shlomovits. Worldjen: An end-to-end multi-dimensional benchmark for generative video models.arXiv preprint arXiv:2605.03475, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
D. Zheng, Z. Huang, H. Liu, K. Zou, Y . He, F. Zhang, L. Gu, Y . Zhang, J. He, W.-S. Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Evaluating Newtonian Mechanics in Video Generative Models with Real Physical Systems
C. Zhang, D. Cherniavskii, A. Tragoudaras, A. V ozikis, T. Nijdam, D. W. Prinzhorn, M. Bodrac- ska, N. Sebe, A. Zadaianchuk, and E. Gavves. Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments.arXiv preprint arXiv:2504.02918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
RoboWM-Bench: A Benchmark for Evaluating World Models in Robotic Manipulation
F. Jiang, Y . Chen, K. Xu, Y . Liu, H. Wang, Z. Shen, J. Lu, S. Huang, Y . Wang, C. Xie, et al. Robowm-bench: A benchmark for evaluating world models in robotic manipulation.arXiv preprint arXiv:2604.19092, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
- [19]
-
[20]
Z. Li, X. Wu, G. Shi, Y . Qin, H. Du, T. Zhou, D. Manocha, and J. Boyd-Graber. Video- hallu: Evaluating and mitigating multi-modal hallucinations on synthetic video understanding. Advances in Neural Information Processing Systems, 38:76046–76078, 2026
2026
-
[21]
M. R. Taesiri, T. Feng, C.-P. Bezemer, and A. Nguyen. Glitchbench: Can large multimodal models detect video game glitches? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22444–22455, 2024
2024
-
[22]
Open-Ended Video Game Glitch Detection with Agentic Reasoning and Temporal Grounding
M. Zheng, T. Zhou, G. Wu, Z. Lin, H. Wang, and L. Huang. Open-ended video game glitch detection with agentic reasoning and temporal grounding.arXiv preprint arXiv:2604.07818, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [23]
- [24]
-
[25]
Y . Wang, X. Liu, W. Pang, L. Ma, S. Yuan, P. Debevec, and N. Yu. Survey of video diffusion models: Foundations, implementations, and applications.Transactions on Machine Learning Research
-
[26]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. In Conference on Robot Learning, pages 5170–5194. PMLR, 2025
2025
-
[27]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
M. J. Kim, K. Huang, H. Gu, A. Shah, R. Torne, A. Sharma, K. Keetha, F. Ebert, S. Levine, and C. Finn. OpenVLA: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2024. URLhttps://openvla.github.io
2024
-
[29]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Danny, A. Fu, S. Guadarrama, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control.Conference on Robot Learning (CoRL), 2023. URL https://arxiv.org/ abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Chung, T
N. Chung, T. Hanyu, T. Nguyen, H. Le, F. Bumgarner, D. M. Nguyen, K. V o, K. l. Yamazaki, C. Rainwater, T. Kieu, A. Nguyen, and N. Le. Rethinking progression of memory state in robotic manipulation: An object-centric perspective. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[31]
Hanyu, N
T. Hanyu, N. Chung, H. Le, T. Nguyen, Y . Ikebe, A. Gunderman, D. M. H. Nguyen, K. V o, T. Kieu, K. Yamazaki, C. Rainwater, A. Nguyen, and N. Le. SlotVLA: Towards modeling of object-relation representations in robotic manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[32]
K. V o, T. Hanyu, Y . Ikebe, T. T. Pham, N. Chung, M. N. Vu, D. M. H. Nguyen, A. Nguyen, A. Gunderman, C. Rainwater, and N. Le. Clutter-resistant vision–language–action models through object-centric and geometry grounding.arXiv preprint arXiv:2512.22519, 2026. URL https://arxiv.org/abs/2512.22519
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
D. M. Nguyen, B.-N. Dao, T. M. Luu, B. G. Nguyen, V . Tong, A. Liu, V . N. Duong, D. D. Le, D. Sonntag, T. Le, N. Le, J. Peter, A. T. Le, M. N. Vu, M. Niepert, K. D. Doan, D. M. H. Nguyen, and V . A. Ngo. Self-improving VLA policies: Selected diffusion noise for spurious-robust action smoothing.arXiv preprint arXiv:2606.14084, 2026. URL https://arxiv.org/...
-
[34]
A. Authors. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025. URLhttps://arxiv.org/abs/2510.10125
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
A. Authors. Closed-loop learning of video world model and VLA policy.arXiv preprint arXiv:2602.06508, 2026. URLhttps://arxiv.org/abs/2602.06508
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[37]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[38]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. Van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018. 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
H. Han, S. Li, J. Chen, Y . Yuan, Y . Wu, Y . Deng, C. T. Leong, H. Du, J. Fu, Y . Li, et al. Video-bench: Human-aligned video generation benchmark. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18858–18868, 2025
2025
- [40]
-
[41]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivi`ere, M. S. Kale, J. Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
H. W. Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97, 1955
1955
-
[49]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024. 12 AAppendix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 A.1Glitch Taxonomy . ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.