Memory-Managed Long-Context Attention: A Preliminary Study of Editable Request-Local Memory
Pith reviewed 2026-06-30 09:43 UTC · model grok-4.3
The pith
Separating explicit editable memory slots from a sparse backbone lets models handle overwrite and protection cases that pure compression or attention methods miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a hybrid architecture with editable request-local memory slots and sparse fallback covers memory-management cases missed by pure fixed-state or pure sparse methods; controlled slot lifecycle proves feasible in structured tasks, sparse fallback proves necessary when writes lack future-query signals, and learned open-domain selection without oracle metadata remains the main architectural bottleneck.
What carries the argument
explicit editable request-local memory slots together with query-time sparse fallback, which handle writing, overwriting, protecting from distractors, and discarding facts independently of the backbone
If this is right
- Controlled slot lifecycle is feasible under structured conditions.
- Sparse fallback becomes necessary precisely when writes lack future-query signals.
- Learned open-domain selection without metadata is the primary remaining architectural limit.
- Hybrid designs succeed on overwrite, version, and anti-pollution cases where pure methods fail.
Where Pith is reading between the lines
- Training open-domain selection mechanisms without oracle metadata would be a direct next target.
- The same slot-plus-fallback split could be tested on other sequence domains that require selective retention.
- Scaling the minimal causal model beyond 2.74M parameters might reveal whether the observed trainability holds at larger sizes.
Load-bearing premise
The structured synthetic tasks, token bridges, and oracle-metadata probes used here represent the memory-management problems that appear in open natural-language long-context settings.
What would settle it
An experiment measuring whether the hybrid approach keeps high accuracy on open-text entity resolution tasks that supply no generator-provided integer key IDs or separately encoded canonical strings.
Figures

read the original abstract
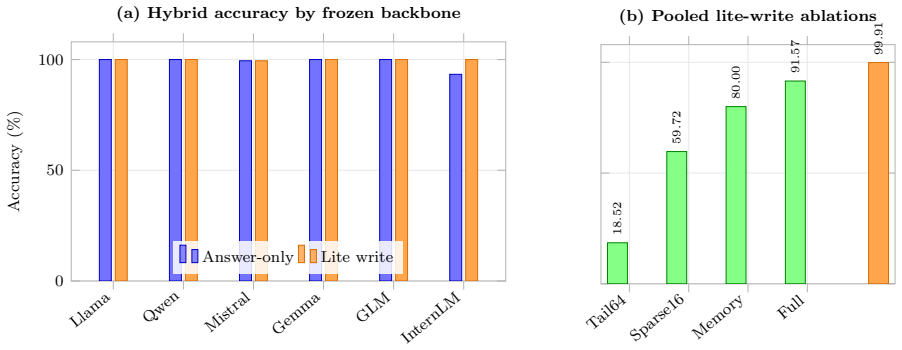
Long-context language models often conflate two different goals: compressing history into an efficient state, and maintaining reliable long-term memory. Linear, recurrent, and sparse attention reduce the cost of processing long sequences, but they do not by themselves specify when a fact should be written, overwritten, protected from distractors, or discarded. We study memory-managed long-context attention, a research route that separates a fast recurrent or sparse backbone from explicit editable request-local memory slots and query-time sparse fallback. Across structured synthetic tasks, token/chunk/sequence bridges, generated natural language, and local frozen-model diagnostics, pure fixed-state or pure sparse methods fail some overwrite, version, anti-pollution, or no-write-signal cases, while a hybrid covers both routes. A small 2,097,152-token mechanism stress test reaches 50/50 pooled accuracy with 2-132 active chunks. A 2.74M-parameter minimal causal event-token model reaches 595/600 with lite write supervision, supporting proof of trainability rather than scale. A six-family frozen-hidden-state bridge reaches 1079/1080 controlled pointer accuracy, but it uses generator-provided integer key IDs and separately encoded canonical key strings; it is an oracle-metadata probe, not open-text entity resolution. Local non-leaderboard RULER 4K diagnostics remain close to full context, whereas a 33-record LongBench v1 16K subset shows that naive lexical selection is not general. The evidence separates three claims: controlled slot lifecycle is feasible, sparse fallback is needed when writes lack future-query signals, and learned open-domain selection remains the main architectural bottleneck. We do not claim a final generative architecture, global slot-trajectory convergence, or systems superiority.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes memory-managed long-context attention that decouples a fast recurrent/sparse backbone from explicit editable request-local memory slots plus query-time sparse fallback. Across structured synthetic tasks, token/chunk/sequence bridges, generated natural language, and frozen-model diagnostics, it reports that pure fixed-state or pure sparse methods fail overwrite/version/anti-pollution/no-write-signal cases while a hybrid succeeds. Concrete results include 50/50 pooled accuracy on a 2,097,152-token stress test (2-132 active chunks), 595/600 on a 2.74M-parameter minimal causal model with lite supervision, and 1079/1080 on a six-family oracle-metadata bridge; local RULER diagnostics stay close to full context while a 33-record LongBench subset shows naive lexical selection is insufficient. The evidence is presented as separating three claims: controlled slot lifecycle is feasible, sparse fallback is required when writes lack future-query signals, and learned open-domain selection remains the primary architectural bottleneck. The work explicitly disclaims a final generative architecture or systems superiority.
Significance. If the empirical separation holds, the work supplies a preliminary but concrete demonstration that hybrid memory management can address specific failure modes of pure compression or attention methods in long-context settings. The reported accuracies (50/50, 595/600, 1079/1080) across task families, the explicit stress-test scale, and the minimal-model trainability result provide measurable support for feasibility of lifecycle control and the necessity of fallback. The paper's own labeling of the highest-accuracy result as an oracle-metadata probe is a strength in transparency.
major comments (1)
- [Abstract] Abstract (and the section presenting the 1079/1080 result): the controlled pointer accuracy relies on generator-provided integer key IDs plus separately encoded canonical key strings and is explicitly labeled an oracle-metadata probe rather than open-text entity resolution. Because claim (3) identifies learned open-domain selection as the remaining bottleneck, this setup removes the hardest sub-problem; the high accuracy therefore does not demonstrate that controlled slot lifecycle (claim 1) is solved in the regime the paper itself flags as unsolved, weakening the claimed clean separation of the three claims.
minor comments (1)
- [Abstract] The abstract states 'local non-leaderboard RULER 4K diagnostics remain close to full context' without specifying the exact metric or baseline comparison; a table or sentence citing the precise scores would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for recognizing the empirical distinctions drawn in the work. Below we provide a point-by-point response to the single major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the section presenting the 1079/1080 result): the controlled pointer accuracy relies on generator-provided integer key IDs plus separately encoded canonical key strings and is explicitly labeled an oracle-metadata probe rather than open-text entity resolution. Because claim (3) identifies learned open-domain selection as the remaining bottleneck, this setup removes the hardest sub-problem; the high accuracy therefore does not demonstrate that controlled slot lifecycle (claim 1) is solved in the regime the paper itself flags as unsolved, weakening the claimed clean separation of the three claims.
Authors: We agree that the 1079/1080 result is obtained under oracle-metadata conditions (generator-provided integer key IDs and separately encoded canonical strings) and does not constitute open-text entity resolution, as the manuscript already states both in the abstract and in the relevant section. The experiment is deliberately constructed to isolate claim (1)—feasibility of controlled slot lifecycle—from claim (3)—learned open-domain selection as the primary bottleneck. By supplying oracle metadata we show that the editable memory slots, write/overwrite logic, and protection mechanisms can reach near-perfect accuracy once the selection sub-problem is removed; this supports the architectural viability of the lifecycle component itself. The same manuscript reports that naive lexical selection fails on the 33-record LongBench subset, thereby locating the difficulty in open-domain selection rather than in the memory-management primitives. We therefore view the oracle result as reinforcing, rather than weakening, the separation of the three claims: lifecycle control is feasible when selection is solved externally, yet learned selection remains unsolved. Because the qualification is already explicit, we see no need to alter the abstract or the reported result. revision: no
Circularity Check
No significant circularity; empirical feasibility study with direct measurements
full rationale
The paper is an empirical feasibility study reporting measured accuracies on synthetic tasks, token/chunk bridges, and oracle-metadata probes (explicitly labeled as such in the abstract for the 1079/1080 result). No mathematical derivation chain, equations, or fitted parameters exist that reduce reported results to quantities defined by the authors' own prior equations or self-citations. The three separated claims rest on direct experimental outcomes rather than any self-definitional, fitted-input, or uniqueness-imported reduction. Self-citations, if present, are not load-bearing for any central premise.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Gradient-based optimization can train small causal models to perform the required write/overwrite behaviors under lite supervision
- domain assumption The structured synthetic tasks and oracle-metadata bridges are representative of the memory lifecycle challenges that matter for long-context language models
invented entities (1)
-
Editable request-local memory slots
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Angelos Katharopoulos et al. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention.https://arxiv.org/abs/2006.16236, 2020. arXiv:2006.16236
-
[2]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun et al. Retentive Network: A Successor to Transformer for Large Language Models. https://arxiv.org/abs/2307.08621, 2023. arXiv:2307.08621
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. https://arxiv.org/abs/2312.00752, 2023. arXiv:2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated Delta Networks: Improving Mamba2 with Delta Rule.https://arxiv.org/abs/2412.06464, 2024. arXiv:2412.06464
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Big Bird: Transformers for Longer Sequences
Manzil Zaheer et al. Big Bird: Transformers for Longer Sequences.https://arxiv.org/abs/ 2007.14062, 2020. arXiv:2007.14062
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[6]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y. X. Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng Liang, and Wangding Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention.https://arxiv.org/abs/2502.11089, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI et al. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models. https://arxiv.org/abs/2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
Ali Hatamizadeh, Yejin Choi, and Jan Kautz. Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention.https://arxiv.org/abs/2605.22791, 2026. arXiv:2605.22791
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi Team et al. Kimi Linear: An Expressive, Efficient Attention Architecture.https: //arxiv.org/abs/2510.26692, 2025. arXiv:2510.26692
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
Yu Chen, Runkai Chen, Sheng Yi, Xinda Zhao, Xiaohong Li, Jianjin Zhang, Jun Sun, Chuanrui Hu, Yunyun Han, Lidong Bing, Yafeng Deng, and Tianqiao Chen. MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens.https://arxiv. org/abs/2603.23516, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Aaron Grattafiori et al. The Llama 3 Herd of Models.https://arxiv.org/abs/2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Qwen et al. Qwen2.5 Technical Report.https://arxiv.org/abs/2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention.https://arxiv.org/abs/2309.06180, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh et al. RULER: What’s the Real Context Size of Your Long-Context Lan- guage Models?https://arxiv.org/abs/2404.06654, 2024. arXiv:2404.06654. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai et al. LongBench: A Bilingual, Multitask Benchmark for Long Context Understand- ing.https://arxiv.org/abs/2308.14508, 2023. arXiv:2308.14508
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Mistral NeMo.https://mistral.ai/news/mistral-nemo/,
Mistral AI Team and NVIDIA. Mistral NeMo.https://mistral.ai/news/mistral-nemo/,
-
[17]
Official model release
-
[18]
Gemma Team et al. Gemma 3 Technical Report.https://arxiv.org/abs/2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM et al. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools.https://arxiv.org/abs/2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Zheng Cai et al. InternLM2 Technical Report.https://arxiv.org/abs/2403.17297, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
RACE Attention: A Strictly Linear-Time Attention Layer for Training on Outrageously Large Contexts
Sahil Joshi, Agniva Chowdhury, Amar Kanakamedala, Ekam Singh, Evan Tu, and Anshu- mali Shrivastava. RACE Attention: A Strictly Linear-Time Attention Layer for Training on Outrageously Large Contexts.https://arxiv.org/abs/2510.04008, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to Memorize at Test Time. https://arxiv.org/abs/2501.00663, 2025. arXiv:2501.00663
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention.https://arxiv.org/abs/2404. 07143, 2024. arXiv:2404.07143
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Variational Linear Attention: Stable Associative Memory for Long-Context Transformers
Vishal Pandey and Gopal Singh. Variational Linear Attention: Stable Associative Memory for Long-Context Transformers.https://arxiv.org/abs/2605.11196, 2026. arXiv:2605.11196
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Rethinking Attention with Performers
Krzysztof Choromanski et al. Rethinking Attention with Performers.https://arxiv.org/ abs/2009.14794, 2020. arXiv:2009.14794
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[26]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized Models and Efficient Algo- rithms Through Structured State Space Duality.https://arxiv.org/abs/2405.21060, 2024. arXiv:2405.21060
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Zihang Dai et al. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Con- text.https://arxiv.org/abs/1901.02860, 2019. arXiv:1901.02860
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[28]
Compressive Transformers for Long-Range Sequence Modelling
Jack W. Rae et al. Compressive Transformers for Long-Range Sequence Modelling.https: //arxiv.org/abs/1911.05507, 2019. arXiv:1911.05507
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[29]
Rabe, DeLesley Hutchins, and Christian Szegedy
Yuhuai Wu, Markus N. Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing Trans- formers.https://arxiv.org/abs/2203.08913, 2022. arXiv:2203.08913
-
[30]
Augmenting Language Models with Long-Term Memory.https://arxiv
Weizhi Wang et al. Augmenting Language Models with Long-Term Memory.https://arxiv. org/abs/2306.07174, 2023. arXiv:2306.07174
-
[31]
Memory Layers at Scale.https://arxiv.org/abs/2412.09764,
Vincent-Pierre Berges et al. Memory Layers at Scale.https://arxiv.org/abs/2412.09764,
-
[32]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://arxiv.org/abs/2005.11401, 2020. arXiv:2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[33]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud et al. Improving Language Models by Retrieving from Trillions of Tokens. https://arxiv.org/abs/2112.04426, 2021. arXiv:2112.04426. 13
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Urvashi Khandelwal et al. Generalization through Memorization: Nearest Neighbor Language Models.https://arxiv.org/abs/1911.00172, 2019. arXiv:1911.00172. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.