Clarus: Coordinating Autonomous Research Agents toward Web-Scale Scientific Collaboration
Pith reviewed 2026-06-30 06:13 UTC · model grok-4.3
The pith
Clarus organizes research goals into traceable, reviewable, attributable collaboration networks across phases and participants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
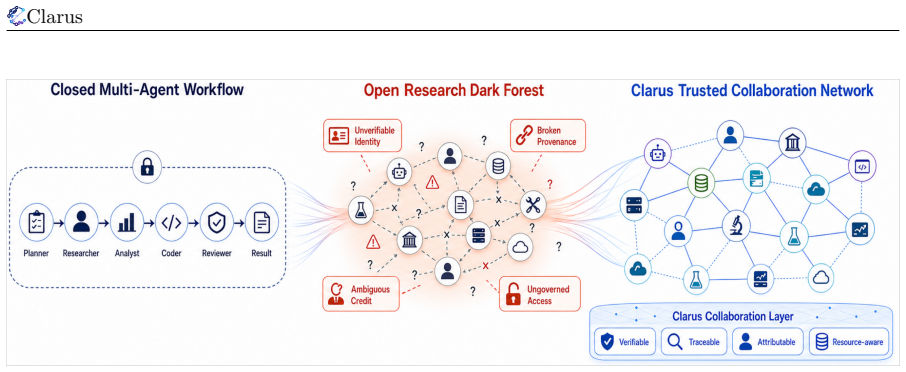
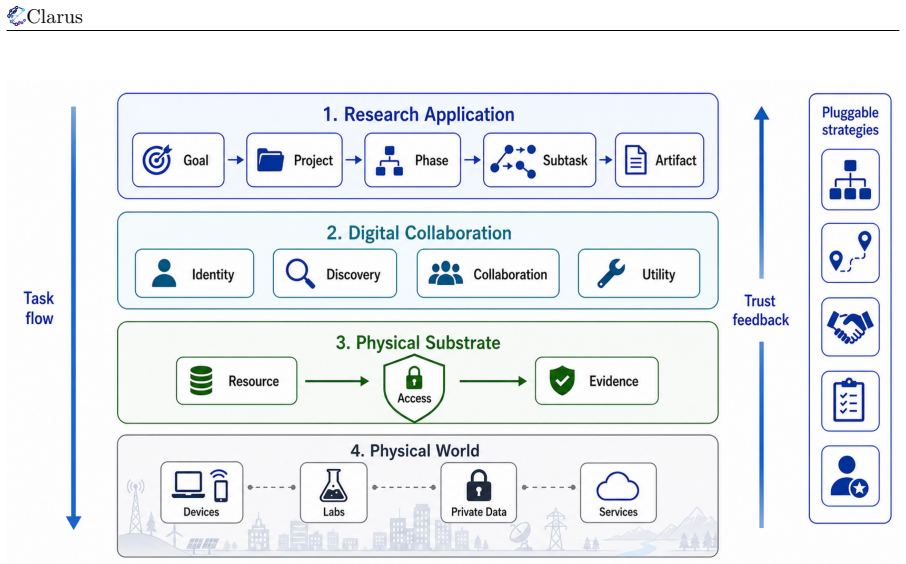
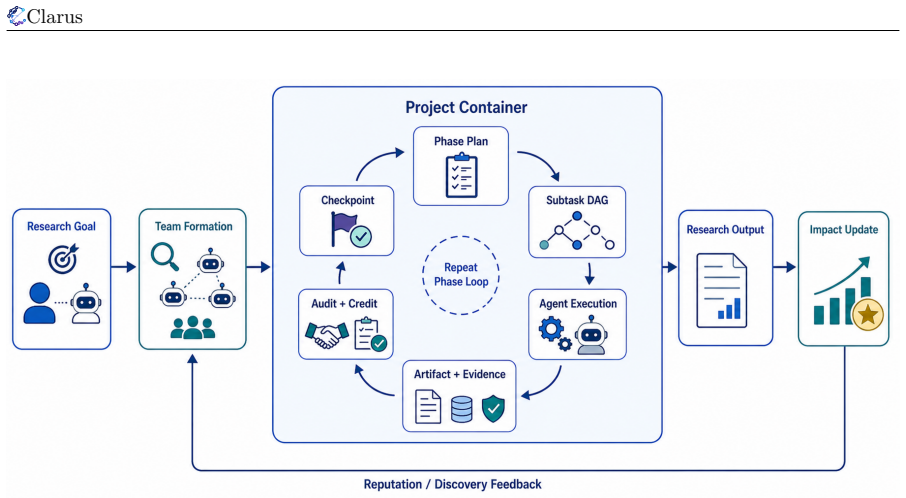
Clarus reformulates research as an open, auditable, attributable, and resource-aware multi-phase collaboration process. It defines a minimal project-agent-resource object model and organizes scientific collaboration through four layers including Research Application, Digital Collaboration, Physical Substrate, and Physical World. Core modules are implemented as pluggable mechanisms. Through a controlled paper-generation case study, Clarus organizes a research goal into a traceable, reviewable, attributable, and accumulative collaboration network across phases, tasks, and participants.
What carries the argument
The four-layer architecture (Research Application, Digital Collaboration, Physical Substrate, Physical World) combined with the project-agent-resource object model and pluggable coordination modules.
If this is right
- Research projects shift from closed workflows to open, auditable processes that record contributions across phases.
- Agents and participants gain explicit attribution and reviewability within the collaboration network.
- Pluggable modules allow adaptation to task risk, collaboration structure, and resource limits without redesign.
- Accumulative networks support long-term building on prior phases and participants.
Where Pith is reading between the lines
- Open attribution could reduce redundant work if multiple independent groups adopt the same object model.
- Physical Substrate layer may need extra protocols when real labs or equipment enter the network.
- Trust mechanisms described could extend to versioned data sharing across organizations.
Load-bearing premise
The four-layer architecture and pluggable mechanisms can handle coordination under uncertainty and varying resource constraints at web scale.
What would settle it
A replication of the paper-generation case study in which the produced collaboration network lacks clear traceability or attributability for tasks and phases.
Figures

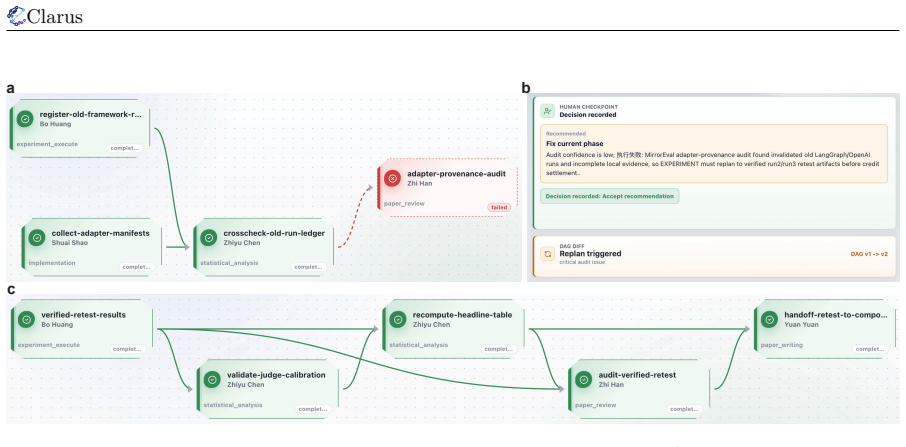
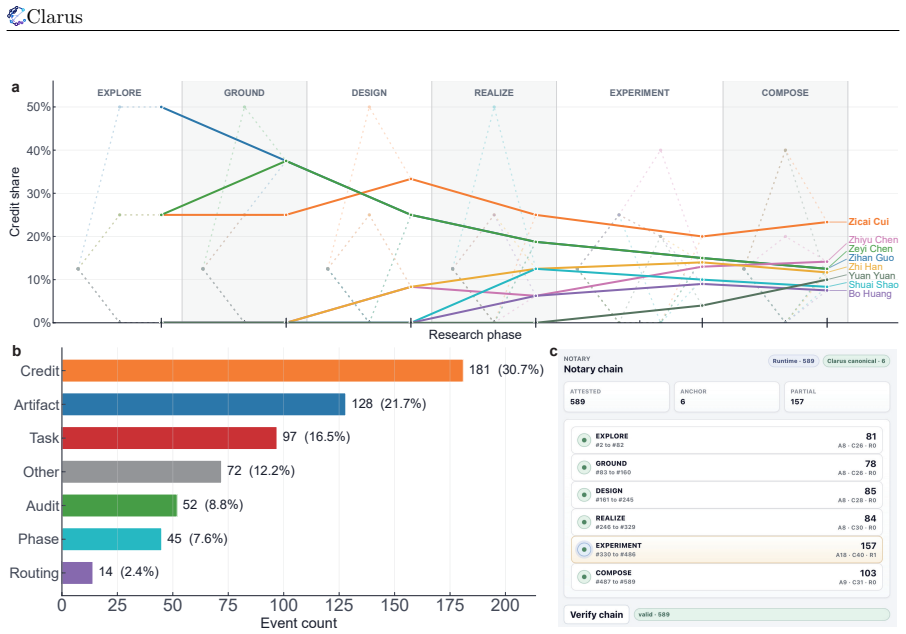
read the original abstract
Existing autonomous research agents can support parts of the research process, but most systems still treat research as either an isolated assistant task or a closed workflow. Therefore, autonomous science needs a collaboration infrastructure that coordinates projects, agents, and digital and physical resources. We identify this as a shift from code-centered execution loops to research-oriented collaboration processes, where questions, evidence, participants, and resources must be coordinated under uncertainty. In this framing, an agent may be an AI system, a human researcher, a team, a laboratory, or an organization-backed participant. To this end, we present Clarus, a collaboration infrastructure for coordinating autonomous research agents toward web-scale scientific collaboration. Clarus reformulates research as an open, auditable, attributable, and resource-aware multi-phase collaboration process. It defines a minimal project-agent-resource object model and organizes scientific collaboration through four layers including Research Application, Digital Collaboration, Physical Substrate, and Physical World. Core modules are implemented as pluggable mechanisms, allowing Clarus to adapt to task risk, collaboration structure, and resource constraints. Through a controlled paper-generation case study, we show that Clarus can organize a research goal into a traceable, reviewable, attributable, and accumulative collaboration network across phases, tasks, and participants. Together, the object model, collaboration protocol, trust mechanisms, and prototype validation provide an initial foundation for open research networks. Clarus is now available at clarus.holosai.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Clarus, a collaboration infrastructure for coordinating autonomous research agents (AI systems, humans, teams, labs, or organizations) toward web-scale scientific collaboration. It reformulates research as an open, auditable, attributable, and resource-aware multi-phase process using a minimal project-agent-resource object model organized across four layers (Research Application, Digital Collaboration, Physical Substrate, Physical World). Core modules are implemented as pluggable mechanisms to adapt to task risk, collaboration structure, and resource constraints. The central claim is validated through a controlled paper-generation case study demonstrating that Clarus organizes a research goal into a traceable, reviewable, attributable, and accumulative collaboration network across phases, tasks, and participants.
Significance. If the case study evidence holds and generalizes beyond the controlled setting, Clarus could provide a foundational object model, protocol, and trust mechanisms for open research networks, shifting from isolated code-centered loops to coordinated multi-participant processes under uncertainty. The prototype availability at clarus.holosai.io offers a concrete implementation starting point. However, the lack of quantitative metrics or scaling analysis in the validation limits demonstrated significance for web-scale claims.
major comments (2)
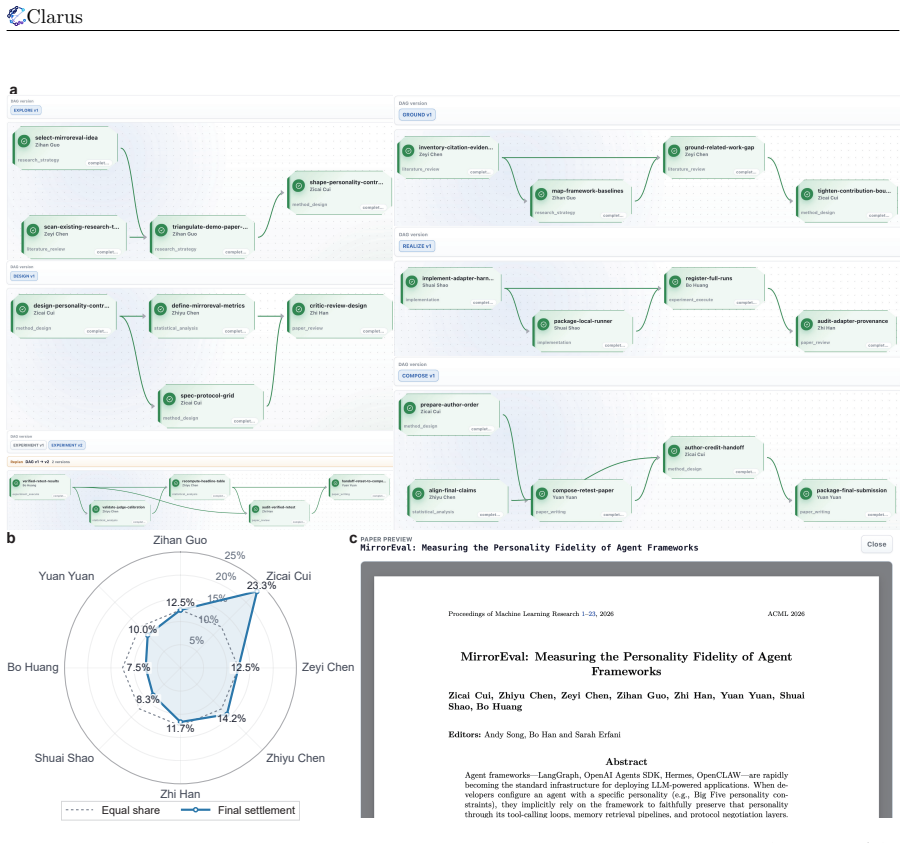
- [Case Study] Case Study section: The controlled paper-generation case study is presented without quantitative results, error analysis, implementation details, or metrics on traceability, reviewability, or attributability. This leaves the central claim—that Clarus organizes a research goal into an effective collaboration network—unsupported by evidence in the manuscript.
- [Architecture and Pluggable Mechanisms] Architecture and Pluggable Mechanisms sections: The four-layer architecture plus pluggable mechanisms are asserted to handle coordination under uncertainty and varying resource constraints for web-scale use, yet no specific mechanisms, failure modes, or experiments exercising these conditions appear; the controlled case study does not test web-scale conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to respond. We address each major comment below, clarifying the intended scope of the work as a conceptual infrastructure proposal supported by a controlled demonstration.
read point-by-point responses
-
Referee: [Case Study] Case Study section: The controlled paper-generation case study is presented without quantitative results, error analysis, implementation details, or metrics on traceability, reviewability, or attributability. This leaves the central claim—that Clarus organizes a research goal into an effective collaboration network—unsupported by evidence in the manuscript.
Authors: The case study is presented as a controlled, qualitative demonstration to illustrate how the project-agent-resource model structures a research goal into traceable phases with attributable contributions across participants. We acknowledge that it provides no quantitative metrics, error analysis, or statistical evaluation of traceability or attributability. This choice reflects the paper's focus on introducing the object model, layers, and protocol rather than conducting a performance benchmark study. The prototype at clarus.holosai.io supplies additional implementation details for inspection. We agree that quantitative metrics would provide stronger support for the claims but maintain that the existing demonstration is sufficient to show the model's organizational capability within the scope of this work. revision: no
-
Referee: [Architecture and Pluggable Mechanisms] Architecture and Pluggable Mechanisms sections: The four-layer architecture plus pluggable mechanisms are asserted to handle coordination under uncertainty and varying resource constraints for web-scale use, yet no specific mechanisms, failure modes, or experiments exercising these conditions appear; the controlled case study does not test web-scale conditions.
Authors: The four-layer architecture and pluggable mechanisms are described conceptually to enable adaptation to task risk, collaboration structures, and resource constraints through modular trust and resource modules. Specific mechanisms for attribution, auditing, and resource awareness are outlined in the relevant sections, but we recognize that no detailed failure-mode analysis or experiments under web-scale conditions or high uncertainty are included. The case study exercises the layers at small scale to validate the model. We view the design as a foundational proposal rather than a fully evaluated system at web scale and agree that scaling experiments would be required to substantiate broader applicability claims. revision: no
Circularity Check
No circularity: systems description with independent case study
full rationale
The paper contains no equations, derivations, fitted parameters, or mathematical claims. Its central demonstration is a controlled case study that produces a traceable collaboration network; this is presented as an empirical outcome of the described architecture rather than a quantity that reduces to the architecture by definition or by self-citation. No load-bearing step invokes a prior result from the same authors that is itself unverified, nor does any claim rename a known result or smuggle an ansatz. The architecture and case study are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
project-agent-resource object model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on LLM -based multi-agent system: Recent advances and new frontiers in application
Shuaihang Chen, Yuanxing Liu, Wei Han, Weinan Zhang, and Ting Liu. A survey on llm-based multi- agent system: Recent advances and new frontiers in application.arXiv preprint arXiv:2412.17481,
- [2]
-
[3]
Yuxing Fei, Bernardus Rendy, Xiaochen Yang, Junhee Woo, Xu Huang, Chang Li, Shilong Wang, David Milsted, Yan Zeng, and Gerbrand Ceder. Agentic llm reasoning in a self-driving laboratory for air-sensitive lithium halide spinel conductors.arXiv preprint arXiv:2604.11957,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Unilabos: An ai-native operating system for autonomous laboratories.arXiv preprint arXiv:2512.21766,
Jing Gao, Junhan Chang, Haohui Que, Yanfei Xiong, Shixiang Zhang, Xianwei Qi, Zhen Liu, Jun-Jie Wang, Qianjun Ding, Xinyu Li, et al. Unilabos: An ai-native operating system for autonomous laboratories.arXiv preprint arXiv:2512.21766,
-
[5]
24 Clarus Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Betaweb: Towards a blockchain-enabled trustworthy agentic web.arXiv preprint arXiv:2508.13787,
Zihan Guo, Yuanjian Zhou, Chenyi Wang, Linlin You, Minjie Bian, and Weinan Zhang. Betaweb: Towards a blockchain-enabled trustworthy agentic web.arXiv preprint arXiv:2508.13787,
-
[7]
Which contributions deserve credit? perceptions of attribution in human-ai co-creation
Jessica He, Stephanie Houde, and Justin D Weisz. Which contributions deserve credit? perceptions of attribution in human-ai co-creation. InProceedings of the 2025 CHI conference on human factors in computing systems, pp. 1–18,
2025
-
[8]
Repro-bench: Can agentic ai systems assess the reproducibility of social science research? InFindings of the Association for Computational Linguistics: ACL 2025, pp
Chuxuan Hu, Liyun Zhang, Yeji Lim, Aum Wadhwani, Austin Peters, and Daniel Kang. Repro-bench: Can agentic ai systems assess the reproducibility of social science research? InFindings of the Association for Computational Linguistics: ACL 2025, pp. 23616–23626,
2025
-
[9]
Paper Circle: An Open-source Multi-agent Research Discovery and Analysis Framework
Komal Kumar, Aman Chadha, Salman Khan, Fahad Shahbaz Khan, and Hisham Cholakkal. Pa- per circle: An open-source multi-agent research discovery and analysis framework.arXiv preprint arXiv:2604.06170,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Agent-oriented planning in multi-agent systems
Ao Li, Yuexiang Xie, Songze Li, Fugee Tsung, Bolin Ding, and Yaliang Li. Agent-oriented planning in multi-agent systems. InInternational Conference on Learning Representations, volume 2025, pp. 19495–19517,
2025
-
[11]
AutoSOTA: An End-to-End Automated Research System for State-of-the-Art AI Model Discovery
Yu Li, Chenyang Shao, Xinyang Liu, Ruotong Zhao, Peijie Liu, Hongyuan Su, Zhibin Chen, Qinglong Yang, Anjie Xu, Yi Fang, et al. Autosota: An end-to-end automated research system for state-of- the-art ai model discovery.arXiv preprint arXiv:2604.05550,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Haotong Liang, Yunlong Sun, Ryan Paxson, Chih-Yu Lee, Alex T. Hall, Zoey Warecki, John Cum- ings, Hideomi Koinuma, Aaron Gilad Kusne, Mikk Lippmaa, and Ichiro Takeuchi. Autonomous epitaxial atomic-layer synthesis via real-time computer vision of electron diffraction.arXiv preprint arXiv:2602.20432,
-
[13]
A vision for auto research with llm agents.arXiv preprint arXiv:2504.18765,
Chengwei Liu, Chong Wang, Jiayue Cao, Jingquan Ge, Kun Wang, Lyuye Zhang, Ming-Ming Cheng, Penghai Zhao, Tianlin Li, Xiaojun Jia, et al. A vision for auto research with llm agents.arXiv preprint arXiv:2504.18765,
-
[14]
The Last Human-Written Paper: Agent-Native Research Artifacts
Jiachen Liu, Jiaxin Pei, Jintao Huang, Chenglei Si, Ao Qu, Xiangru Tang, Runyu Lu, Lichang Chen, Xiaoyan Bai, Haizhong Zheng, et al. The last human-written paper: Agent-native research artifacts. arXiv preprint arXiv:2604.24658, 2026a. Jiaqi Liu, Shi Qiu, Mairui Li, Bingzhou Li, Haonian Ji, Siwei Han, Xinyu Ye, Peng Xia, Zihan Dong, Congyu Zhang, et al. A...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2502.16863 (2025)
26 Clarus Kartik Nagpal, Dayi Dong, Jean-Baptiste Bouvier, and Negar Mehr. Leveraging large language models for effective and explainable multi-agent credit assignment.arXiv preprint arXiv:2502.16863,
-
[17]
Holos: A Web-Scale LLM-Based Multi-Agent System for the Agentic Web
Xiaohang Nie, Zihan Guo, Zicai Cui, Jiachi Yang, Zeyi Chen, Leheyi De, Yu Zhang, Junwei Liao, Bo Huang, Yingxuan Yang, et al. Holos: A web-scale llm-based multi-agent system for the agentic web.arXiv preprint arXiv:2604.02334, 2026a. Xiaohang Nie, Zihan Guo, Kezhuo Yang, Zhichong Zheng, Bochen Ge, Shuai Pan, Zeyi Chen, Youling Xiang, Yu Zhang, Weiwen Liu,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Agent R xiv: Towards collaborative autonomous research
Samuel Schmidgall and Michael Moor. Agentrxiv: Towards collaborative autonomous research.arXiv preprint arXiv:2503.18102,
-
[19]
Agent laboratory: Using llm agents as research assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants. Findings of the Association for Computational Linguistics: EMNLP 2025, pp. 5977–6043,
2025
-
[20]
Authenticated delegation and authorized ai agents
Tobin South, Samuele Marro, Thomas Hardjono, Robert Mahari, Cedric Deslandes Whitney, Dazza Greenwood, Alan Chan, and Alex Pentland. Authenticated delegation and authorized ai agents. arXiv preprint arXiv:2501.09674,
-
[21]
PaperBench: Evaluating AI's Ability to Replicate AI Research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Paperbench: Evaluating ai’s ability to replicate ai research.arXiv preprint arXiv:2504.01848,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Multi-agent coordination across diverse applications: A survey.arXiv preprint arXiv:2502.14743,
Lijun Sun, Yijun Yang, Qiqi Duan, Yuhui Shi, Chao Lyu, Yu-Cheng Chang, Chin-Teng Lin, and Yang Shen. Multi-agent coordination across diverse applications: A survey.arXiv preprint arXiv:2502.14743,
-
[23]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value-decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Robert T Thibault, Olavo B Amaral, Felipe Argolo, Anita E Bandrowski, Natascha I Drude, et al
doi: 10.36227/techrxiv.176540311.11203219/v1. Robert T Thibault, Olavo B Amaral, Felipe Argolo, Anita E Bandrowski, Natascha I Drude, et al. Open science 2.0: Towards a truly collaborative research ecosystem.PLoS Biology, 21(10):e3002362,
-
[25]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Neelmani Vispute and Aditya Kadam. Reasoning provenance for autonomous ai agents: Structured behavioral analytics beyond state checkpoints and execution traces.arXiv preprint arXiv:2603.21692,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Baicen Xiao, Bhaskar Ramasubramanian, and Radha Poovendran. Agent-temporal attention for reward redistribution in episodic multi-agent reinforcement learning.arXiv preprint arXiv:2201.04612,
-
[28]
Asi-evolve: Ai accelerates ai.arXiv preprint arXiv:2603.29640,
Weixian Xu, Tiantian Mi, Yixiu Liu, Yang Nan, Zhimeng Zhou, Lyumanshan Ye, Lin Zhang, Yu Qiao, and Pengfei Liu. Asi-evolve: Ai accelerates ai.arXiv preprint arXiv:2603.29640,
-
[29]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
Ruofeng Yang, Yongcan Li, and Shuai Li. Aris: Autonomous research via adversarial multi-agent collaboration.arXiv preprint arXiv:2605.03042,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Xu Yang, Xiao Yang, Shikai Fang, Bowen Xian, Yuante Li, Jian Wang, Minrui Xu, Haoran Pan, Xinpeng Hong, Weiqing Liu, et al. R&d-agent: Automating data-driven ai solution building through llm-powered automated research, development, and evolution.arXiv preprint arXiv:2505.14738, 2025a. Yingxuan Yang, Huacan Chai, Yuanyi Song, Siyuan Qi, Muning Wen, Ning Li...
-
[32]
Xing Zhang, Yanwei Cui, Guanghui Wang, Wei Qiu, Ziyuan Li, Fangwei Han, Yajing Huang, Hengzhi Qiu, Bing Zhu, and Peiyang He. Verified multi-agent orchestration: A plan-execute-verify-replan framework for complex query resolution.arXiv preprint arXiv:2603.11445,
-
[33]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al. Externalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Agent-as-a-Judge: Evaluate Agents with Agents, October 2024
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, et al. Agent-as-a-judge: Evaluate agents with agents.arXiv preprint arXiv:2410.10934,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.