Your Data Manifold is Secretly a Reward Model: Shell-LCC for Text-to-Video Generation
Pith reviewed 2026-06-30 06:05 UTC · model grok-4.3
The pith
The manifold of high-quality SFT data can serve as a dense, cost-free reward model for text-to-video diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By explicitly modeling the manifold structure of high-quality SFT data and encouraging video latents to lie on this manifold, we derive dense, differentiable, and nearly cost-free reward signals that significantly improve video quality, particularly in mitigating low-level distortions. The modeling builds upon Local Coordinate Coding but extends it to Shell-LCC, which represents the manifold surface as an isotropic shell to avoid mean regression and preserve high-frequency details.
What carries the argument
Shell-LCC, an extension of Local Coordinate Coding that models the manifold as an isotropic shell surface to supply differentiable alignment signals from existing SFT data.
If this is right
- Generated videos exhibit improved realism, sharper high-frequency details, and reduced over-smoothing and motion blur.
- Alignment occurs without training separate reward models or incurring annotation costs.
- The reward signals integrate directly into existing diffusion pipelines as an auxiliary loss term.
- The approach targets low-level distortions that standard reward models often miss.
Where Pith is reading between the lines
- Similar manifold modeling could supply alignment signals for text-to-image or audio generation tasks that also rely on SFT data.
- Iteratively updating the fitted shell with newly generated high-quality samples might create a self-improving loop.
- The shell-surface representation may combine with other latent-space regularizers already used in diffusion training.
Load-bearing premise
The geometric manifold fitted to SFT data points aligns with human aesthetic preferences so that pulling latents onto its surface improves fine details without new artifacts.
What would settle it
Blind human preference tests or perceptual metrics on videos generated with versus without Shell-LCC guidance show no gain in realism or detail sharpness, or show introduced artifacts.
Figures
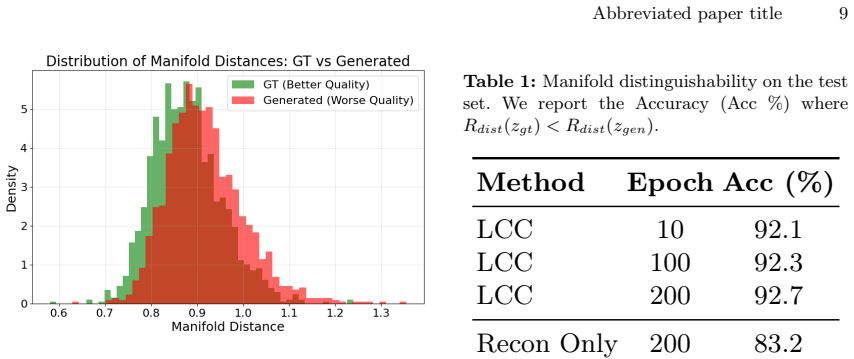




read the original abstract
Recent text-to-video (T2V) diffusion models rely heavily on auxiliary reward signals (e.g., via reward models or DPO) to align generated content with human aesthetics and improve realism. These signals, however, incur substantial computational overhead, require costly human annotations, and often yield limited improvement in fine-grained local details. In this paper, we argue that your data manifold is secretly a reward model. By explicitly modeling the manifold structure of high-quality Supervised Fine-Tuning (SFT) data and encouraging video latents to lie on this manifold, we derive dense, differentiable, and nearly cost-free reward signals that significantly improve video quality, particularly in mitigating low-level distortions. Our modeling builds upon Local Coordinate Coding (LCC), which captures the `skeleton' of the manifold. However, directly applying LCC suffers from mean regression, pulling latents toward the geometric mean and losing high-frequency details. We therefore extend it to Shell Local Coordinate Coding (Shell-LCC), which models the manifold `surface' as an isotropic shell to align with the true high-density region. Experiments demonstrate that our approach improves realism, enhances high-frequency details, reduces over-smoothing artifacts, and alleviates motion blur.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the manifold structure of high-quality SFT data can be used as a proxy reward model for text-to-video diffusion models. It extends Local Coordinate Coding to Shell-LCC by modeling an isotropic shell around the manifold surface (rather than the geometric mean) to derive dense, differentiable, nearly cost-free reward signals that encourage generated video latents to lie on this surface, thereby improving realism, high-frequency details, and reducing artifacts such as over-smoothing and motion blur.
Significance. If the central claim holds with supporting evidence, the approach would provide a low-overhead alternative to annotation-based reward models or DPO for T2V alignment, leveraging existing SFT data geometry to mitigate low-level distortions without additional compute or human labels.
major comments (3)
- [Abstract] Abstract: the central claim of 'significantly improve video quality' and 'mitigating low-level distortions' is stated without any quantitative metrics, ablation studies, baseline comparisons, or human preference evaluations, rendering the claim impossible to assess.
- [Modeling section] The modeling section (Shell-LCC derivation): the interpretation of the derived signal as a 'reward model' rather than a manifold regularizer rests on the untested assumption that the isotropic shell fitted to SFT latents coincides with regions preferred by humans; no human preference data, comparison against standard reward models, or ablation on the shell prior versus geometric mean is supplied to support this alignment.
- [Experiments] Experiments section: the abstract asserts improvements in realism, detail, and artifact reduction, yet the provided text contains no tables, figures, or numerical results demonstrating these effects or ruling out mode collapse/new artifacts from the shell constraint.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our contributions. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'significantly improve video quality' and 'mitigating low-level distortions' is stated without any quantitative metrics, ablation studies, baseline comparisons, or human preference evaluations, rendering the claim impossible to assess.
Authors: We agree that the abstract's claims would benefit from direct reference to supporting evidence. In the revised manuscript we will expand the experiments section to include quantitative metrics, ablation studies, baseline comparisons, and human preference evaluations, and we will update the abstract to cite specific results from those evaluations. revision: yes
-
Referee: [Modeling section] The modeling section (Shell-LCC derivation): the interpretation of the derived signal as a 'reward model' rather than a manifold regularizer rests on the untested assumption that the isotropic shell fitted to SFT latents coincides with regions preferred by humans; no human preference data, comparison against standard reward models, or ablation on the shell prior versus geometric mean is supplied to support this alignment.
Authors: The modeling section derives the signal from the geometry of high-quality SFT data as a proxy. We acknowledge that the current version lacks direct human-preference validation and explicit comparisons. In revision we will add an ablation of the isotropic shell versus the geometric mean and comparisons to standard reward models to better substantiate the alignment claim. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts improvements in realism, detail, and artifact reduction, yet the provided text contains no tables, figures, or numerical results demonstrating these effects or ruling out mode collapse/new artifacts from the shell constraint.
Authors: We agree that the experiments section must supply tables, figures, and numerical results to demonstrate the claimed effects and to address potential new artifacts. The revised manuscript will include these elements along with ablations that rule out mode collapse or introduced distortions. revision: yes
Circularity Check
No circularity detected; reward signal defined from external SFT manifold without reduction to fitted inputs or self-citations
full rationale
The provided abstract and context contain no equations or derivation steps that reduce a claimed prediction or result to its own inputs by construction. The core argument—that modeling the SFT data manifold yields a reward signal—is presented as an interpretive claim supported by experiments on quality metrics, not as a mathematical identity or fitted parameter renamed as prediction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via prior work are quoted. The method extends LCC to Shell-LCC on the manifold surface, but this is an independent modeling choice evaluated against external benchmarks rather than tautological. Per rules, absent explicit quotes showing reduction (e.g., Eq. X = Eq. Y by fit), the finding is no significant circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-quality SFT data lies on a low-dimensional manifold whose local geometry can be captured by coordinate coding.
- ad hoc to paper An isotropic shell around the manifold surface aligns with the true high-density region better than the geometric mean.
invented entities (1)
-
Shell Local Coordinate Coding (Shell-LCC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1710.11379 (2017)
Arvanitidis, G., Hansen, L.K., Hauberg, S.: Latent space oddity: on the curvature of deep generative models. arXiv preprint arXiv:1710.11379 (2017)
-
[2]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Bansal, H., Lin, Z., Xie, T., Zong, Z., Yarom, M., Bitton, Y., Jiang, C., Sun, Y., Chang, K.W., Grover, A.: Videophy: Evaluating physical commonsense for video generation. arXiv preprint arXiv:2406.03520 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
In: SIGGRAPH Asia 2024 Conference Papers
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[4]
Neural computation15(6), 1373–1396 (2003)
Belkin, M., Niyogi, P.: Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation15(6), 1373–1396 (2003)
2003
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
OpenAI Blog1(8), 1 (2024)
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., et al.: Video generation models as world simulators. OpenAI Blog1(8), 1 (2024)
2024
-
[7]
Advances in neural information processing systems30(2017)
Christiano, P.F., Leike, J., Brown, T., Martic, M., Legg, S., Amodei, D.: Deep reinforcement learning from human preferences. Advances in neural information processing systems30(2017)
2017
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Dai, M., Hang, H.: Manifold matching via deep metric learning for generative modeling. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6587–6597 (2021)
2021
-
[9]
Advances in neural information processing systems35, 2406–2422 (2022)
De Bortoli, V., Mathieu, E., Hutchinson, M., Thornton, J., Teh, Y.W., Doucet, A.: Riemannian score- based generative modelling. Advances in neural information processing systems35, 2406–2422 (2022)
2022
-
[10]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[11]
Advances in Neural Information Processing Systems36, 79858–79885 (2023)
Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Systems36, 79858–79885 (2023)
2023
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Han, H., Li, S., Chen, J., Yuan, Y., Wu, Y., Deng, Y., Leong, C.T., Du, H., Fu, J., Li, Y., et al.: Video-bench: Human-aligned video generation benchmark. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18858–18868 (2025)
2025
-
[13]
Ad- vances in neural information processing systems35, 8633–8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Ad- vances in neural information processing systems35, 8633–8646 (2022)
2022
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[15]
In: ICML 2024 Workshop on Geometry-grounded Representation Learning and Generative Modeling (2024)
Humayun, A.I., Amara, I., Schumann, C., Farnadi, G., Rostamzadeh, N., Havaei, M.: On the local ge- ometry of deep generative manifolds. In: ICML 2024 Workshop on Geometry-grounded Representation Learning and Generative Modeling (2024)
2024
-
[16]
arXiv preprint arXiv:2408.08307 (2024)
Humayun, A.I., Amara, I., Vasconcelos, C., Ramachandran, D., Schumann, C., He, J., Heller, K., Farnadi, G., Rostamzadeh, N., Havaei, M.: What secrets do your manifolds hold? understanding the local geometry of generative models. arXiv preprint arXiv:2408.08307 (2024)
-
[17]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Kondratyuk, D., Yu, L., Gu, X., Lezama, J., Huang, J., Schindler, G., Hornung, R., Birodkar, V., Yan, J., Chiu, M.C., et al.: Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Aligning Text-to-Image Models using Human Feedback
Lee, K., Liu, H., Ryu, M., Watkins, O., Du, Y., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Gu, S.S.: Aligning text-to-image models using human feedback. arXiv preprint arXiv:2302.12192 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) Abbreviated paper title 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Improving Video Generation with Human Feedback
Liu, J., Liu, G., Liang, J., Yuan, Z., Liu, X., Zheng, M., Wu, X., Wang, Q., Qin, W., Xia, M., Wang, X., Liu, X., Yang, F., Wan, P., Zhang, D., Gai, K., Yang, Y., Ouyang, W.: Improving video generation with human feedback. arXiv preprint arXiv:2501.13918 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, R., Wu, H., Zheng, Z., Wei, C., He, Y., Pi, R., Chen, Q.: Videodpo: Omni-preference alignment for video diffusion generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8009–8019 (2025)
2025
-
[23]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Y., Cun, X., Liu, X., Wang, X., Zhang, Y., Chen, H., Liu, Y., Zeng, T., Chan, R., Shan, Y.: Eval- crafter: Benchmarking and evaluating large video generation models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22139–22149 (2024)
2024
-
[25]
Latte: Latent Diffusion Transformer for Video Generation
Ma, X., Wang, Y., Chen, X., Jia, G., Liu, Z., Li, Y.F., Chen, C., Qiao, Y.: Latte: Latent diffusion transformer for video generation. arXiv preprint arXiv:2401.03048 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
In: Forty-first International Conference on Machine Learning (2024)
Munos, R., Valko, M., Calandriello, D., Azar, M.G., Rowland, M., Guo, Z.D., Tang, Y., Geist, M., Mes- nard, T., Fiegel, C., et al.: Nash learning from human feedback. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ni, Y., Koniusz, P., Hartley, R., Nock, R.: Manifold learning benefits gans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11265–11274 (2022)
2022
-
[28]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[29]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference opti- mization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[30]
science 290(5500), 2323–2326 (2000)
Roweis, S.T., Saul, L.K.: Nonlinear dimensionality reduction by locally linear embedding. science 290(5500), 2323–2326 (2000)
2000
-
[31]
Journal of machine learning research4(Jun), 119–155 (2003)
Saul, L.K., Roweis, S.T.: Think globally, fit locally: unsupervised learning of low dimensional manifolds. Journal of machine learning research4(Jun), 119–155 (2003)
2003
-
[32]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sun, K., Huang, K., Liu, X., Wu, Y., Xu, Z., Li, Z., Liu, X.: T2v-compbench: A comprehensive bench- mark for compositional text-to-video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8406–8416 (2025)
2025
-
[35]
science290(5500), 2319–2323 (2000)
Tenenbaum,J.B.,Silva,V.d.,Langford,J.C.:Aglobalgeometricframeworkfornonlineardimensionality reduction. science290(5500), 2319–2323 (2000)
2000
-
[36]
Vershynin, R.: High-dimensional probability: An introduction with applications in data science, vol. 47. Cambridge university press (2018)
2018
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8228–8238 (2024)
2024
-
[38]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Wang, B., Yue, Z., Zhang, F., Chen, S., Bi, L., Zhang, J., Song, X., Chan, K.Y., Pan, J., Wu, W., Zhou, M., Lin, W., Pan, K., Zhang, S., Jia, L., Hu, W., Zhao, W., Zhang, H.: Discrete visual tokens of autoregression, by diffusion, and for reasoning (2025),https://arxiv.org/abs/2505.07538
-
[40]
International Journal of Computer Vision133(5), 3059–3078 (2025)
Wang, Y., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y., Yang, C., He, Y., Yu, J., Yang, P., et al.: Lavie: High-quality video generation with cascaded latent diffusion models. International Journal of Computer Vision133(5), 3059–3078 (2025)
2025
-
[41]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
arXiv preprint arXiv:2506.13691 (2025)
Xue, Z., Zhang, J., Hu, T., He, H., Chen, Y., Cai, Y., Wang, Y., Wang, C., Liu, Y., Li, X., Tao, D.: Ul- travideo: High-quality uhd video dataset with comprehensive captions. arXiv preprint arXiv:2506.13691 (2025)
-
[43]
VideoGPT: Video Generation using VQ-VAE and Transformers
Yan, W., Zhang, Y., Abbeel, P., Srinivas, A.: Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Advances in neural information processing systems22(2009)
Yu, K., Zhang, T., Gong, Y.: Nonlinear learning using local coordinate coding. Advances in neural information processing systems22(2009)
2009
-
[45]
In: Interna- tional Conference on Machine Learning (ICML) (2024)
Zhang, S., Kawaguchi, K., Yao, A.: Deep regression representation learning with topology. In: Interna- tional Conference on Machine Learning (ICML) (2024)
2024
-
[46]
ICLR (2025)
Zhang, S., Yan, Y., Yao, A.: Improving deep regression with tightness. ICLR (2025)
2025
-
[47]
ICLR (2023)
Zhang, S., Yang, L., Mi, M.B., Zheng, X., Yao, A.: Improving deep regression with ordinal entropy. ICLR (2023)
2023
-
[48]
arXiv preprint arXiv:2305.10425 (2023)
Zhao, Y., Joshi, R., Liu, T., Khalman, M., Saleh, M., Liu, P.J.: Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425 (2023)
-
[49]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democ- ratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.