WarpHammer: Densifying Scene Warps with 3D Object Priors for Extreme View Synthesis
Pith reviewed 2026-07-01 06:17 UTC · model grok-4.3
The pith
Augmenting sparse scene warps with explicit 3D object reconstructions from generative priors restores stable novel views under large orbital motion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
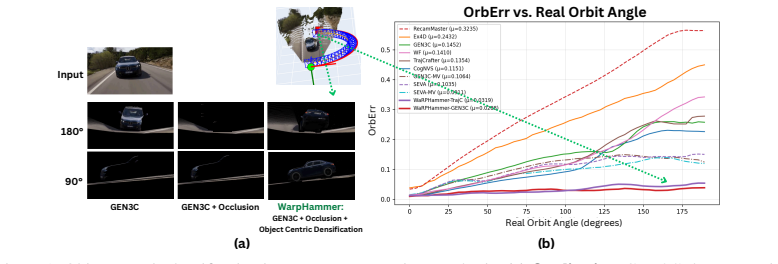
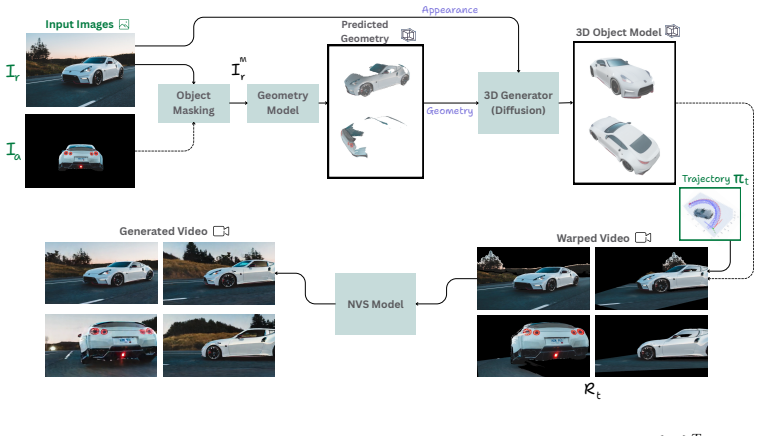
WarpHammer is a training-free framework that resolves the failure mode of sparse warps under large orbital motion by augmenting the warped scene with an explicit 3D reconstruction of the object obtained from a native 3D generative prior. The reconstructed object adds missing foreground surfaces and occludes background points that should no longer be visible, restoring both appearance and camera cues. The same explicit object representation further unlocks incorporating auxiliary views of the object from sources outside the target scene by processing reference and auxiliary images jointly with a pretrained multi-view geometry foundation model to predict a unified point cloud that is fused int
What carries the argument
Explicit 3D object reconstruction from a native 3D generative prior, fused with a unified point cloud from auxiliary views, that densifies the scene warp and supplies correct occlusion and geometry.
If this is right
- Novel views remain stable at viewpoint deviations where strong baselines collapse.
- No fine-tuning of the base NVS model is needed.
- Auxiliary object views from external sources can be incorporated without user-provided camera poses.
- Multi-view fusion yields substantially more faithful geometry than single-image reconstruction alone.
Where Pith is reading between the lines
- The method could be applied to any warp-based NVS pipeline that currently degrades under large motion.
- If the 3D prior is replaced with a faster model, the approach might support interactive view synthesis.
- Fusing multiple external views might reduce dependence on the quality of any single generative prior.
Load-bearing premise
The 3D generative prior and pretrained multi-view geometry model produce accurate enough object reconstructions and point clouds that can be fused into the warp without new artifacts.
What would settle it
Run WarpHammer on a test scene with known large orbital motion and ground-truth novel views; if the output still shows mirror-like artifacts or incorrect occlusion of background elements, the claim does not hold.
Figures


read the original abstract
Projection-conditioned novel view synthesis (NVS) warps an explicit 3D reconstruction of the input view into the target camera and conditions a generator on the warped rendering. This works well for small viewpoint changes but degrades sharply under large orbital motion: the warp becomes sparse around the orbited object, where hidden surfaces dominate the new view and mirror-like artifacts emerge, causing the generator to lose both pixel content and the implicit camera cue carried by the warp. We introduce WarpHammer, a training-free framework that resolves this failure mode by augmenting the warped scene with an explicit 3D reconstruction of the object obtained from a native 3D generative prior (e.g., SAM3D). The reconstructed object adds missing foreground surfaces and occludes background points that should no longer be visible, restoring both appearance and camera cues without fine-tuning the base model. The same explicit object representation further unlocks a capability current NVS pipelines do not support: incorporating auxiliary views of the object from sources outside the target scene, for example, a casual snapshot of a car paired with a manufacturer studio shot of the same model. We process the reference and auxiliary images jointly with a pretrained multi-view geometry foundation model, which predicts a unified point cloud that we fuse into the 3D object reconstruction. This yields substantially more faithful geometry than single-image reconstruction, without requiring user-provided camera poses for the auxiliary views. On five benchmarks, WarpHammer produces stable novel views at viewpoint deviations where strong baselines collapse, and is the first scene-level NVS method that can naturally fuse auxiliary, pose-unknown object views from an external source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WarpHammer, a training-free framework for projection-conditioned novel view synthesis (NVS) that augments sparse scene warps with explicit 3D object reconstructions from native generative priors (e.g., SAM3D) to handle large orbital viewpoint changes. It restores missing foreground surfaces and correct occlusions, and extends to fusing auxiliary object views from external sources via a pretrained multi-view geometry foundation model that produces a unified point cloud without requiring poses. Claims include stable results on five benchmarks where baselines fail.
Significance. If the central claims hold, the work would meaningfully advance training-free NVS by addressing the sparse-warp failure mode under extreme motion and enabling practical use of casual external images, both of which are currently unsupported. The explicit use of off-the-shelf 3D priors and multi-view foundation models without fine-tuning is a notable strength, as is the unified point-cloud fusion mechanism.
major comments (3)
- [Experiments / §4] The central claim that the generative prior (SAM3D or equivalent) produces instance-specific hidden-surface geometry that is both metrically accurate and correctly scaled/aligned to the input camera is load-bearing for the entire framework, yet the manuscript provides no quantitative evaluation of reconstruction fidelity on back-facing surfaces (e.g., Chamfer distance or normal error against ground-truth hidden geometry) in the experiments.
- [Method / §3.2 and Experiments / §4] The auxiliary-view fusion capability relies on the multi-view geometry foundation model implicitly solving relative pose and scale without drift or surface conflicts; however, no ablation or error analysis of fusion accuracy (e.g., alignment error before/after fusion or artifact introduction rate) is reported, leaving the claim that it yields "substantially more faithful geometry" unsupported by numbers.
- [Abstract and Experiments / §4] Table or figure results on the five benchmarks are referenced in the abstract but the manuscript supplies no numerical metrics, baseline comparisons, or ablation tables; this absence prevents verification that WarpHammer outperforms strong baselines at the claimed viewpoint deviations.
minor comments (2)
- [Method] Notation for the unified point cloud and fusion step could be clarified with an explicit equation or diagram showing coordinate-frame transformations.
- [Discussion] The manuscript would benefit from a limitations paragraph discussing failure cases when the generative prior hallucinates implausible geometry.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional quantitative support would strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Experiments / §4] The central claim that the generative prior (SAM3D or equivalent) produces instance-specific hidden-surface geometry that is both metrically accurate and correctly scaled/aligned to the input camera is load-bearing for the entire framework, yet the manuscript provides no quantitative evaluation of reconstruction fidelity on back-facing surfaces (e.g., Chamfer distance or normal error against ground-truth hidden geometry) in the experiments.
Authors: We agree that quantitative metrics on hidden-surface reconstruction fidelity are needed to support the central claim. In the revised manuscript we will add Chamfer distance and normal error evaluations against available ground-truth hidden geometry from the benchmarks. revision: yes
-
Referee: [Method / §3.2 and Experiments / §4] The auxiliary-view fusion capability relies on the multi-view geometry foundation model implicitly solving relative pose and scale without drift or surface conflicts; however, no ablation or error analysis of fusion accuracy (e.g., alignment error before/after fusion or artifact introduction rate) is reported, leaving the claim that it yields "substantially more faithful geometry" unsupported by numbers.
Authors: We acknowledge that explicit error analysis of the fusion process is required to substantiate the claims. The revision will include ablations reporting alignment error before/after fusion and rates of introduced artifacts. revision: yes
-
Referee: [Abstract and Experiments / §4] Table or figure results on the five benchmarks are referenced in the abstract but the manuscript supplies no numerical metrics, baseline comparisons, or ablation tables; this absence prevents verification that WarpHammer outperforms strong baselines at the claimed viewpoint deviations.
Authors: We agree that the absence of explicit numerical tables prevents full verification. The revised experiments section will include comprehensive metric tables, baseline comparisons, and ablations for the five benchmarks. revision: yes
Circularity Check
No significant circularity; method relies on external pretrained models
full rationale
The paper presents a training-free framework that augments warped scenes with 3D object reconstructions from external generative priors (e.g., SAM3D) and fuses auxiliary views via a pretrained multi-view geometry foundation model. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claims depend on the independent accuracy of these cited external models rather than deriving results from quantities internal to the paper. This is the common case of a self-contained method against external benchmarks, warranting score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Native 3D generative priors such as SAM3D produce explicit object reconstructions accurate enough to augment scene warps without artifacts or fine-tuning
- domain assumption A pretrained multi-view geometry foundation model can produce a unified point cloud from reference and auxiliary images without camera poses that fuses to yield substantially more faithful geometry
Reference graph
Works this paper leans on
-
[1]
Objectron: A large scale dataset of object-centric videos in the wild with pose annotations
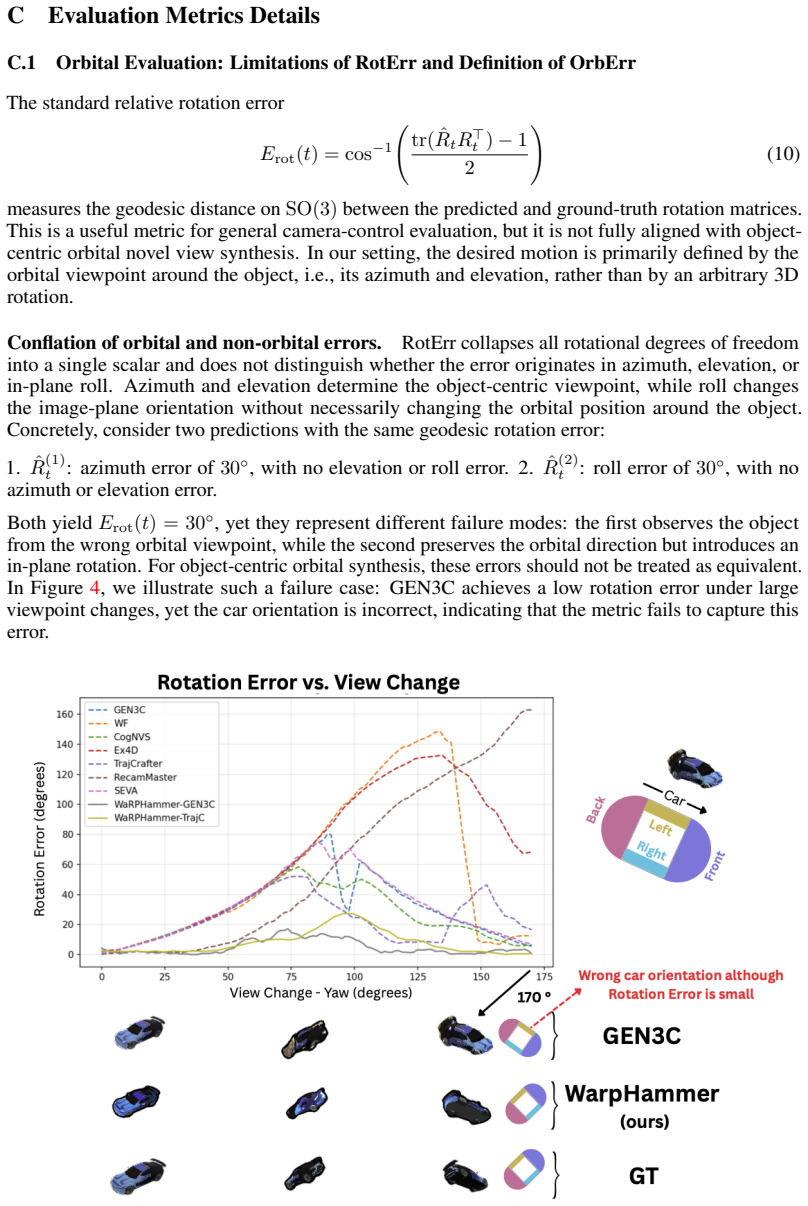
Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. Objectron: A large scale dataset of object-centric videos in the wild with pose annotations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7822–7831, 2021. 6, 16
2021
-
[2]
Lindell, and Sergey Tulyakov
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B. Lindell, and Sergey Tulyakov. AC3D: Analyzing and improving 3d camera control in video diffusion transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 3
2025
-
[3]
Lindell, and Sergey Tulyakov
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, David B. Lindell, and Sergey Tulyakov. VD3D: Taming large video diffusion transformers for 3d camera control. InInternational Conference on Learning Representations, 2025. 3
2025
-
[4]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14834–14844, 2025. 6, 7
2025
-
[5]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5470–5479, 2022. 3, 6, 16
2022
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
MV- GenMaster: Scaling multi-view generation from any image via 3D priors enhanced diffusion model
Chenjie Cao, Chaohui Yu, Shang Liu, Fan Wang, Xiangyang Xue, and Yanwei Fu. MV- GenMaster: Scaling multi-view generation from any image via 3D priors enhanced diffusion model. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2411.16157. 2
-
[8]
Freeorbit4d: Training-free arbitrary camera redirection for monocular videos via geometry-complete 4d reconstruction
Wei Cao, Hao Zhang, Fengrui Tian, Yulun Wu, Yingying Li, Shenlong Wang, Ning Yu, and Yaoyao Liu. Freeorbit4d: Training-free arbitrary camera redirection for monocular videos via geometry-complete 4d reconstruction. 2026. 4
2026
-
[9]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015. 6, 16
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. VideoCrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Reconstruct, inpaint, test-time finetune: Dynamic novel-view synthesis from monocular videos
Kaihua Chen, Tarasha Khurana, and Deva Ramanan. Reconstruct, inpaint, test-time finetune: Dynamic novel-view synthesis from monocular videos. InAdvances in Neural Information Processing Systems, 2025. 4, 6
2025
-
[12]
Luxi Chen, Zihan Zhou, Min Zhao, Yikai Wang, Ge Zhang, Wenhao Huang, Hao Sun, Ji-Rong Wen, and Chongxuan Li. FlexWorld: Progressively expanding 3D scenes for flexible-view synthesis.arXiv preprint arXiv:2503.13265, 2025. 2
-
[13]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025. 5 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023. 6, 16
2023
-
[15]
Google scanned objects: A high-quality dataset of 3d scanned household items
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kinman, Ryan Hickman, Krista Rey- mann, Thomas B McHugh, and Vincent Vanhoucke. Google scanned objects: A high-quality dataset of 3d scanned household items. In2022 International Conference on Robotics and Automation (ICRA), pages 2553–2560. Ieee, 2022. 6, 16
2022
-
[16]
Barron, and Ben Poole
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T. Barron, and Ben Poole. CAT3D: Create anything in 3D with multi-view diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[17]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. CameraCtrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
CameraCtrl II: Dynamic scene exploration via camera- controlled video diffusion models
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. CameraCtrl II: Dynamic scene exploration via camera- controlled video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 3
2025
-
[19]
Tao Hu, Haoyang Peng, Xiao Liu, and Yuewen Ma. EX-4D: Extreme viewpoint 4D video synthesis via depth watertight mesh.arXiv preprint arXiv:2506.05554, 2025. 2, 4, 6
-
[20]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 7, 19
2024
-
[21]
RayZer: A self-supervised large view synthesis model.arXiv preprint arXiv:2505.00702, 2025
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, and Georgios Pavlakos. RayZer: A self-supervised large view synthesis model.arXiv preprint arXiv:2505.00702, 2025. 1
-
[22]
Vace: All-in- one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in- one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17191–17202, 2025. 4
2025
-
[23]
Lvsm: A large view synthesis model with minimal 3d inductive bias
Haian Jin, Hanwen Jiang, Hao Tan, Kai Zhang, Sai Bi, Tianyuan Zhang, Fujun Luan, Noah Snavely, and Zexiang Xu. LVSM: A large view synthesis model with minimal 3D inductive bias. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2410.17242. 1
-
[24]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):1–14,
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk"uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):1–14,
-
[25]
RealCam-I2V: Real-world image-to-video generation with interactive complex camera control
Teng Li, Guangcong Zheng, Rui Jiang, Shuigen Zhan, Tao Wu, Yehao Lu, Yining Lin, and Xi Li. RealCam-I2V: Real-world image-to-video generation with interactive complex camera control. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 28785–28796, 2025. 3
2025
-
[26]
Jinglin Liang, Zijian Zhou, Rui Huang, Shuangping Huang, and Yichen Gong. Orbitnvs: Harnessing video diffusion priors for novel view synthesis.arXiv preprint arXiv:2603.19613,
-
[27]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9298–9309, 2023. 1, 3 11
2023
-
[29]
3DGS-enhancer: Enhancing unbounded 3D gaus- sian splatting with view-consistent 2D diffusion priors
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3DGS-enhancer: Enhancing unbounded 3D gaus- sian splatting with view-consistent 2D diffusion priors. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2410.16266. 2
-
[30]
SyncDreamer: Generating multiview-consistent images from a single-view image
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. SyncDreamer: Generating multiview-consistent images from a single-view image. In International Conference on Learning Representations, 2024. 1, 3
2024
-
[31]
Wonder3D: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, and Wenping Wang. Wonder3D: Single image to 3d using cross-domain diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. 1, 3
2024
-
[32]
Yawen Luo, Jianhong Bai, Xiaoyu Shi, Menghan Xia, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, and Tianfan Xue. CamCloneMaster: Enabling reference-based camera control for video generation.arXiv preprint arXiv:2506.03140, 2025. 3
-
[33]
arXiv preprint arXiv:2412.06699 (2024) 18 J
Baorui Ma, Huachen Gao, Haoge Deng, Zhengxiong Luo, Tiejun Huang, Lulu Tang, and Xinlong Wang. You see it, you got it: Learning 3D creation on pose-free videos at scale. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2412.06699. 2
-
[34]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision, pages 405–421. Springer, 2020. 3
2020
-
[35]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 7, 18
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InInternational Conference on Learning Representations (ICLR), 2024. 1
2024
-
[37]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021. 6, 16
2021
-
[39]
Gen3c: 3d-informed world- consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world- consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6121–6132, 2025. 2, 3, 4, 6
2025
-
[40]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 1
2022
-
[41]
Zero-to-hero: Enhancing zero-shot novel view synthesis via attention map filtering.Advances in Neural Information Processing Systems, 37: 30522–30553, 2024
Ido Sobol, Chenfeng Xu, and Or Litany. Zero-to-hero: Enhancing zero-shot novel view synthesis via attention map filtering.Advances in Neural Information Processing Systems, 37: 30522–30553, 2024. 3
2024
-
[42]
Chenxi Song, Yanming Yang, Tong Zhao, Ruibo Li, and Chi Zhang. WorldForge: Unlocking emergent 3d/4d generation in video diffusion model via training-free guidance.arXiv preprint arXiv:2509.15130, 2025. 3, 6
-
[43]
SV3D: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. SV3D: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion. InEuropean Conference on Computer Vision, 2024. 3 12
2024
-
[44]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 6
2025
-
[45]
Srinivasan, Howard Zhou, Jonathan T
Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P. Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. IBRNet: Learning multi-view image-based rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2021. 3
2021
-
[46]
MotionCtrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. MotionCtrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH Conference Papers, 2024. 3
2024
-
[47]
Barron, and Aleksander Holynski
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T. Barron, and Aleksander Holynski. CAT4D: Create anything in 4D with multi-view video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2411.18613. 1
-
[48]
Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation
Tong Wu, Jiarui Zhang, Xiao Fu, Yuxin Wang, Jiawei Ren, Liang Pan, Wayne Wu, Lei Yang, Jiaqi Wang, Chen Qian, et al. Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 803–814, 2023. 6, 16
2023
-
[49]
Zirui Wu, Zeren Jiang, Martin R. Oswald, and Jie Song. From rays to projections: Better inputs for feed-forward view synthesis.arXiv preprint arXiv:2601.05116, 2026. 2
-
[50]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21469–21480, 2025. 5
2025
-
[51]
SV4D: Dynamic 3d content generation with multi-frame and multi-view consistency
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. SV4D: Dynamic 3d content generation with multi-frame and multi-view consistency. InInternational Conference on Learning Representations, 2025. 3
2025
-
[52]
StreetCrafter: Street view synthesis with controllable video diffusion models
Yunzhi Yan, Zhen Xu, Haotong Lin, Haian Jin, Haoyu Guo, Yida Wang, Kun Zhan, Xianpeng Lang, Hujun Bao, Xiaowei Zhou, and Sida Peng. StreetCrafter: Street view synthesis with controllable video diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2412.13188. 2
-
[53]
pixelNeRF: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelNeRF: Neural radiance fields from one or few images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4578–4587, 2021. 3
2021
-
[54]
Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 100–111, 2025. 2, 3, 4, 6
2025
-
[55]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. ViewCrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
SpatialCrafter: Unleashing the imagination of video diffusion models for scene reconstruction from limited observations
Songchun Zhang, Huiyao Xu, Sitong Guo, Zhongwei Xie, Pengwei Liu, Hujun Bao, Weiwei Xu, and Changqing Zou. SpatialCrafter: Unleashing the imagination of video diffusion models for scene reconstruction from limited observations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27794–27805, 2025. 3
2025
-
[57]
Xiang Zhang, Yang Zhang, Lukas Mehl, Markus Gross, and Christopher Schroers. High-fidelity novel view synthesis via splatting-guided diffusion.arXiv preprint arXiv:2502.12752, 2025. 2
-
[58]
Yuqi Zhang, Guanying Chen, Jiaxing Chen, Chuanyu Fu, Chuan Huang, and Shuguang Cui. CloseUpShot: Close-up novel view synthesis from sparse-views via point-conditioned diffusion model.arXiv preprint arXiv:2511.13121, 2025. 2 13
-
[59]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Stable virtual camera: Generative view synthesis with diffusion models
Jensen Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12405–12414, 2025. 1, 3, 6
2025
-
[61]
SparseFusion: Distilling view-conditioned diffusion for 3d reconstruction
Zhizhuo Zhou and Shubham Tulsiani. SparseFusion: Distilling view-conditioned diffusion for 3d reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. 3 14 Supplementary Material: WarpHammer In this supplementary material, we provide additional details on implementation, datasets, evaluation metrics, and f...
2023
-
[62]
ˆR(1) t : azimuth error of 30◦, with no elevation or roll error. 2. ˆR(2) t : roll error of 30◦, with no azimuth or elevation error. Both yield Erot(t) = 30 ◦, yet they represent different failure modes: the first observes the object from the wrong orbital viewpoint, while the second preserves the orbital direction but introduces an in-plane rotation. For...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.